Sharding-JDBC4.1.1分库分表实战

文章目录
- ShardingJdbc的概述
-
- 1、概述
- 2、认识shardingjdbc
- 3、认识shardingjdbc功能架构图
- 4、认识Sharding-Proxy
- 5、三个组件的比较
- 6、ShardingJdbc混合架构
- 7、ShardingShpere的功能清单
- 8、 ShardingSphere数据分片内核剖析
- ShardingJdbc操作Mysql配置读写分离,整合Spingboot项目
- ShardingJdbc分库分表实战Springboot项目
- 1、分库分表的方式
- 2、逻辑表
- 3、分库分表数据节点 - actual-data-nodes
- 4、分库分表的分片策略
-
- 实体对象
- inline 行表达时数据分片策略(核心)
-
- 完整配置
- 测试用例
- 使用总结
- 根据实时间日期 - 按照标准规则分库分表
-
- 完整配置
- 配置类
- 测试代码
- 查询
- 推荐文章
- 项目源码地址
- 觉得对您有帮助就留下个宝贵的吧
ShardingJdbc的概述
1、概述
官网:http://shardingsphere.apache.org/index_zh.html
下载地址:https://shardingsphere.apache.org/document/current/cn/downloads/
快速入门:https://shardingsphere.apache.org/document/current/cn/quick-start/shardingsphere-jdbc-quick-start/

以下来自官网的原话:
Apache ShardingSphere 是一套开源的分布式数据库解决方案组成的生态圈,它由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。 它们均提供标准化的数据水平扩展、分布式事务和分布式治理等功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
Apache ShardingSphere 旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。 关系型数据库当今依然占有巨大市场份额,是企业核心系统的基石,未来也难于撼动,我们更加注重在原有基础上提供增量,而非颠覆。
Apache ShardingSphere 5.x 版本开始致力于可插拔架构,项目的功能组件能够灵活的以可插拔的方式进行扩展。 目前,数据分片、读写分离、数据加密、影子库压测等功能,以及 MySQL、PostgreSQL、SQLServer、Oracle 等 SQL 与协议的支持,均通过插件的方式织入项目。 开发者能够像使用积木一样定制属于自己的独特系统。Apache ShardingSphere 目前已提供数十个 SPI 作为系统的扩展点,仍在不断增加中。
ShardingSphere 已于2020年4月16日成为 Apache 软件基金会的顶级项目。
2、认识shardingjdbc

定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC。
支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
支持任意实现 JDBC 规范的数据库,目前支持 MySQL,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库。
3、认识shardingjdbc功能架构图
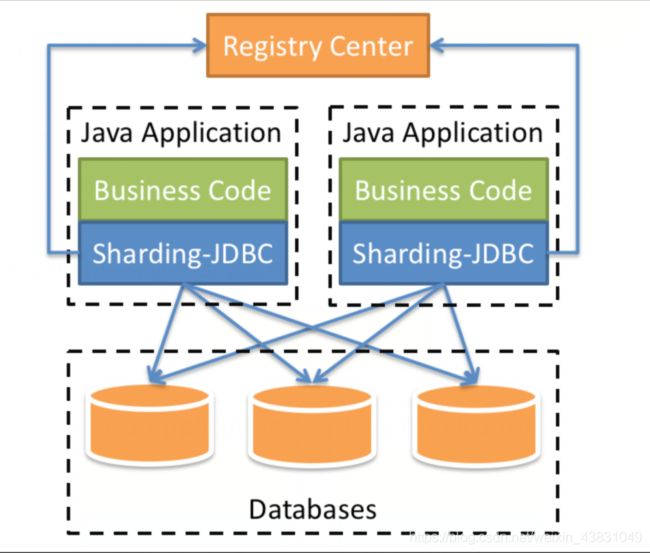
4、认识Sharding-Proxy

定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前提供 MySQL 和 PostgreSQL 版本,它可以使用任何兼容 MySQL/PostgreSQL 协议的访问客户端(如:MySQL Command Client, MySQL Workbench, Navicat 等)操作数据,对 DBA 更加友好。
- 向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用。
- 适用于任何兼容 MySQL/PostgreSQL 协议的的客户端。
5、三个组件的比较
| Sharding-Jdbc | Sharding-Proxy | Sharding-Sidecar | |
|---|---|---|---|
| 数据库 | 任意 | MYSQL | MYSQL |
| 连接消耗数 | 高 | 低 | 低 |
| 异构语言 | 仅Java | 任意 | 任意 |
| 性能 | 损耗低 | 损耗高 | 损耗低 |
| 中心化 | 是 | 否 | 是 |
| 静态入口 | 无 | 有 | 无 |
6、ShardingJdbc混合架构
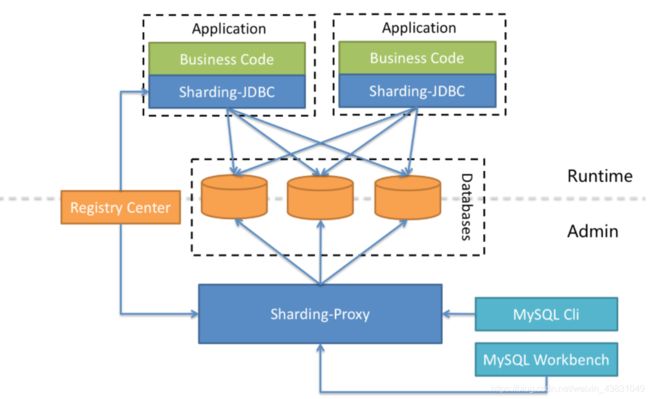
ShardingSphere-JDBC 采用无中心化架构,适用于 Java 开发的高性能的轻量级 OLTP(连接事务处理) 应用;ShardingSphere-Proxy 提供静态入口以及异构语言的支持,适用于 OLAP(连接数据分析) 应用以及对分片数据库进行管理和运维的场景。
Apache ShardingSphere 是多接入端共同组成的生态圈。 通过混合使用 ShardingSphere-JDBC 和 ShardingSphere-Proxy,并采用同一注册中心统一配置分片策略,能够灵活的搭建适用于各种场景的应用系统,使得架构师更加自由地调整适合与当前业务的最佳系统架构。
7、ShardingShpere的功能清单
- 功能列表
- 数据分片
- 分库 & 分表
- 读写分离
- 分片策略定制化
- 无中心化分布式主键
- 分布式事务
- 标准化事务接口
- XA 强一致事务
- 柔性事务
- 数据库治理
- 分布式治理
- 弹性伸缩
- 可视化链路追踪
- 数据加密
8、 ShardingSphere数据分片内核剖析
ShardingSphere 的 3 个产品的数据分片主要流程是完全一致的。 核心由 SQL 解析 => 执行器优化 => SQL 路由 => SQL 改写 => SQL 执行 => 结果归并的流程组成。

SQL 解析
分为词法解析和语法解析。 先通过词法解析器将 SQL 拆分为一个个不可再分的单词。再使用语法解析器对 SQL 进行理解,并最终提炼出解析上下文。 解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。
执行器优化
合并和优化分片条件,如 OR 等。
SQL 路由
根据解析上下文匹配用户配置的分片策略,并生成路由路径。目前支持分片路由和广播路由。
将 SQL 改写为在真实数据库中可以正确执行的语句。SQL 改写分为正确性改写和优化改写。
SQL 执行
通过多线程执行器异步执行。
结果归并
将多个执行结果集归并以便于通过统一的 JDBC 接口输出。结果归并包括流式归并、内存归并和使用装饰者模式的追加归并这几种方式。
ShardingJdbc操作Mysql配置读写分离,整合Spingboot项目
Docker-compose 安装MySql读写分离
SpringBoot项目配置ShardingJdbc读写分离
ShardingJdbc分库分表实战Springboot项目
1、分库分表的方式
水平拆分:统一个表的数据拆到不同的库不同的表中。可以根据时间、地区、或某个业务键维度,也可以通过hash进行拆分,最后通过路由访问到具体的数据。拆分后的每个表结构保持一致。
垂直拆分:就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,可以根据业务维度进行拆分,如订单表可以拆分为订单、订单支持、订单地址、订单商品、订单扩展等表;也可以,根据数据冷热程度拆分,20%的热点字段拆到一个表,80%的冷字段拆到另外一个表。
2、逻辑表
逻辑表是指:水平拆分的数据库或者数据表的相同路基和数据结构表的总称。比如用户数据根据用户id%2拆分为2个表,分别是:user0和user1。他们的逻辑表名是:user。
在shardingjdbc中的定义方式如下:
spring:
shardingsphere:
sharding:
tables:
# user 逻辑表名
user:
3、分库分表数据节点 - actual-data-nodes
tables:
# user 逻辑表名
user:
# 数据节点:多数据源$->{0..N}.逻辑表名$->{0..N} 相同表
actual-data-nodes: ds$->{
0..2}.user$->{
0..1}
# 数据节点:多数据源$->{0..N}.逻辑表名$->{0..N} 不同表
actual-data-nodes: ds0.user$->{
0..1},ds1.user$->{
2..4}
# 指定单数据源的配置方式
actual-data-nodes: ds0.user$->{
0..4}
# 全部手动指定
actual-data-nodes: db0.user0,db1.user0,db0.user1,db1.user1,
数据分片是最小单元。由数据源名称和数据表组成,比如:db0.user0。
寻找规则如下:

4、分库分表的分片策略

实体对象
package com.xinxin.shardingjdbc.entity;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import java.util.Date;
/**
* @author xinxin
* @version 1.0
* @description:
* @date 2021/8/26 21:31
*/
@TableName(value = "user")
@Data
public class User {
// 主键
@TableId
private Long id;
// 昵称
private String nickname;
// 密码
private String password;
// 性别
private Integer sex;
// 生日
private Date birthday;
//年龄
private Integer age;
}
inline 行表达时数据分片策略(核心)
完整配置
- 首先要确保db0,db1两个库存在
- 然后保证你分片的表要存在,比如你分了两张user0-user1这两张表都需要有
- 然后要注意的就是下面定义的逻辑表名,就是你要操作的表名这点一定要注意,比如你数据库分片的表是user0-user10这11张表,但是你逻辑表名在配置文件定义的是user那你操作实体的时候应该是这样写
- @TableName_(value = “user”)
#分库分表配置文件
server:
port: 8080
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# 显示sql
props:
sql:
show: true
# 配置数据源
datasource:
# 给每个数据源取别名,下面的db1,db2任意取名字
names: db0,db1
# 给master-db1每个数据源配置数据库连接信息
db0:
# 配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://114.115.218.80:3306/xinxin?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: root
#最大连接数
maxPoolSize: 100
#最小连接数
minPoolSize: 5
# 配置db2-slave
db1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://114.115.218.80:3307/xinxin?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: root
#最大连接数
maxPoolSize: 100
#最小连接数
minPoolSize: 5
# 配置默认数据源db1
sharding:
# 默认数据源,主要用于写,注意一定要配置读写分离 ,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错。
default-data-source-name: db0
# 配置分表的规则
tables:
# user 逻辑表名,操作是要操作这个逻辑表名
user:
# 数据节点:数据源$->{0..N}.逻辑表名$->{0..N}
# 指定数据源节点规则,指定数据库数据表分片,下面指定为库为db0-db1两个 ,表指定user0-user1两张,这种方式在使用的时候首先要确保有对应的数据库以及表才能进行使用
actual-data-nodes: db$->{
0..1}.user$->{
0..1}
# 拆分库策略,也就是什么样子的数据放入放到哪个数据库中。
# 指定拆分条件,性别%2 成功走的是db0库 否则走的是db1库
database-strategy:
inline:
sharding-column: sex # 分片字段(分片键)
algorithm-expression: db$->{
sex % 2} # 分片算法表达式
# 拆分表策略,也就是什么样子的数据放入放到哪个数据表中。
#拆分表条件age%2 成功走的user0表 失败走的user1表
table-strategy:
inline:
sharding-column: age # 分片字段(分片键)
algorithm-expression: user$->{
age % 2} # 分片算法表达式
# 整合mybatisplus
mybatis-plus:
mapper-locations: classpath*:/mapper/**/*.xml
logging:
level:
com.xinxin.shardingjdbc: debug
测试用例
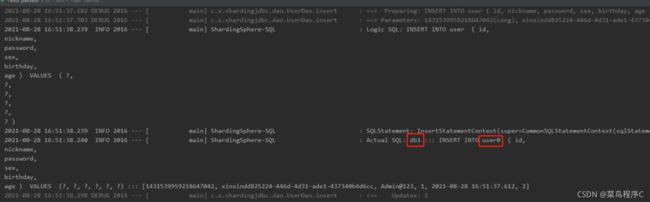
- 下方这个测试就应该是sex为1那应该走的是db1库,然后age2应该操作的是user0表
@Test
void contextLoads() {
User user = new User();
user.setNickname("xinxin" + UUID.randomUUID().toString());
user.setPassword("Admin@123");
user.setSex(1);
user.setBirthday(new Date());
user.setAge(2);
userService.save(user);
}
使用总结
数据分片,首先不管你是只针对数据库,还是固定一个数据库对数据表,要保证这表库表一定是存在的,才能在这个基础上进行操作。
数据分片,也可以单独的对数据表进行分片,或者对数据库进行单独拆分,也可以整合起来分库分表!
根据实时间日期 - 按照标准规则分库分表
完整配置
#配置按时间条件分片
server:
port: 8080
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# 显示sql
props:
sql:
show: true
# 配置数据源
datasource:
# 给每个数据源取别名,下面的db1,db2任意取名字
names: db0,db1
# 给master-db1每个数据源配置数据库连接信息
db0:
# 配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://114.115.218.80:3306/xinxin?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: root
#最大连接数
maxPoolSize: 100
#最小连接数
minPoolSize: 5
# 配置db2-slave
db1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://114.115.218.80:3307/xinxin?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: root
#最大连接数
maxPoolSize: 100
#最小连接数
minPoolSize: 5
# 配置默认数据源db1
sharding:
# 默认数据源,主要用于写,注意一定要配置读写分离 ,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错。
default-data-source-name: db0
# 配置分表的规则
tables:
# user 逻辑表名,操作是要操作这个逻辑表名要保证@TableName(value = "user")
user:
# 数据节点:数据源$->{0..N}.逻辑表名$->{0..N}
# 指定数据源节点规则,指定数据库数据表分片,下面指定为库为db0-db1两个
actual-data-nodes: db$->{
0..1}.user$->{
0..1}
#根据时间去进行拆分表
database-strategy:
standard:
#条件配置列键
shardingColumn: birthday
#配置类
preciseAlgorithmClassName: com.xinxin.shardingjdbc.config.BirthdayAlgorithmConfig
table-strategy:
inline:
sharding-column: age # 分片字段(分片键)
algorithm-expression: user$->{
age % 2} # 分片算法表达式
# 整合mybatisplus
mybatis-plus:
mapper-locations: classpath*:/mapper/**/*.xml
logging:
level:
com.xinxin.shardingjdbc: debug
配置类
package com.xinxin.shardingjdbc.config;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import org.springframework.context.annotation.Configuration;
import java.util.*;
/**
* @author xinxin
* @version 1.0
* @description:
* @date 2021/8/28 17:18
*/
public class BirthdayAlgorithmConfig implements PreciseShardingAlgorithm<Date> {
List<Date> dateList = new ArrayList<>();
{
//设置数据源的时间条件,第一个对应配置文件db0第二个对应db1一次类推,还可以设置其他时间月周日等条件
Calendar calendar1 = Calendar.getInstance();
calendar1.set(2020, 9, 1, 0, 0, 0);
Calendar calendar2 = Calendar.getInstance();
calendar2.set(2021, 1, 1, 0, 0, 0);
dateList.add(calendar1.getTime());
dateList.add(calendar2.getTime());
}
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Date> preciseShardingValue) {
// 获取属性数据库的值
Date date = preciseShardingValue.getValue();
// 获取数据源的名称信息列表
Iterator<String> iterator = collection.iterator();
String target = null;
for (Date s : dateList) {
target = iterator.next();
// 如果数据晚于指定的日期直接返回
if (date.before(s)) {
break;
}
}
return target;
}
}
测试代码
- 下方代码我设置的生日是设置的上一年的今天也就是2020年08月28号这一天,我配置类写的配置第一条是
calendar1.set(2020, 9, 1, 0, 0, 0);2020年9月刚好数据在范围内,这样我这个测试调用的就是db0库然后user1表
@GetMapping("/save")
public String insert() {
User user = new User();
user.setNickname("xinxin" + UUID.randomUUID().toString());
user.setPassword("Admin@123");
user.setSex(1);
//获取一年前的时间
Calendar calendar = Calendar.getInstance();
calendar.setTime(new Date());
calendar.add(Calendar.YEAR, -1);
Date y = calendar.getTime();
user.setBirthday(y);
user.setAge(1);
userService.save(user);
return "新增成功";
}

查询
查询的话也是按照你配置的规则,比如你配置了两个库每个库各两张表那就会把这些数据做个整合。

推荐文章
Seata1.4.2分布式事务整合nacos+SpringCloudAlibaba
Java学习路线个人总结-博客(建议收藏)
项目源码地址
https://gitee.com/cncxc/xinxin-learning/tree/master/learning-sharding-jdbc