游戏项目中如何制定资源管理与加载策略
1)游戏项目中如何制定资源管理与加载策略
2)对于热更新包体大小的最佳实践
3)URP某些Shader资源多次出现
4)关于手机发热问题如何入手
5)如何优化Delegate.Add/Remove这类堆内存的分配
这是第267篇UWA技术知识分享的推送。今天我们继续为大家精选了若干和开发、优化相关的问题,建议阅读时间10分钟,认真读完必有收获。
UWA 问答社区:answer.uwa4d.com
UWA QQ群2:793972859(原群已满员)
Addressable
Q:第一个问题:现在Addressable的使用情况怎么样?使用类似Xassets一类的插件用于资源管理怎么样?
第二个问题:游戏启动的时候,热更资源,资源文件下载是以散文件的方式一个个下载好,还是打成一个整包下载好?
第三个问题:以前我们把AssetBundle包打到安装包内,然后安装完之后第1次启动时要把AssetBundle包解压到外面文件夹。这么做的好处就是统一维护一个外部资源目录,加载资源时不需要先判断外面目录再判断里面,然后根据资源在哪个目录写两种不同的加载方式。但是如果解压到外面,安装完之后整个游戏会增大很多。听说加载包内的资源比加载包外的更快,所以想问一下有没有必要再做解压这一个步骤?
A1:回答如下:
1.现在不太建议使用原生Addressable,因为在目前看到的一些项目中,冗余问题依然存在,而且无论是加载还是内存,问题都很多。加载的效率并不高,一旦做错,还会造成更差的问题,容错率比较低。
现在的大型团队基本上都在自己写这套系统了,便于查找原因。加载这块属于一个游戏的骨架(龙骨),不出问题没人注意,一出问题就有可能是致命的。
2.Xasset没做过调研不太清楚。
3.打成一个整包的,然后做差异化包,版本跨度越大,差异包越多,大文件下载也要考虑到断点续传的问题和多线程下载。要做很多处理,可能要接一个小插件,做加速、做断点续传、做多线程等,容易出问题。
散文件、颗粒度比较小,每次更新就更新几个文件,不用生成差异包。大版本更新就会下很多文件,但是不用考虑它的断点续传,因为文件比较小。还有一个好处就是同时可以起多条链接下载,安卓目前取消了链接数量上限,但是IO会很多。
4.没有必要解压,它在包内StreamingAssets下也是非压缩的,所以加载效率没问题。
该回答由UWA提供
A2:冗余问题, 估计他们是没有用Analyze工具分析冗余,我做过实验用Analyze工具分析解决冗余后,把生成后的Bundle提交到UWA的资源检查,分析得到的结果符合预期,没有意外的冗余问题,基本检查出的冗余,只要你用工具解决了,分析后冗余就不存在了。
感谢在路上哈哈@UWA问答社区提供了回答
A3:稍微补充一下:
1.Addressable针对做分包(核心包、可选包等)支持并不好,虽然有Catalog的分别下载更新,但是制作层面却没有很好支持。异步加载流程不能被Cancel掉,一旦发起必须走完,最后说这个资源不要了。它算是一项可选的比较通用的解决方案,但还是太通用和初级,一些中小型项目还是可以用的。但是项目一旦做复杂点,需求多了就可能应付不了。当然这也是Unity团队无法面面俱到、对应齐全的。一种思路是前期使用它,然后需要安排人深入理解和掌握,到项目中后期出现需求的时候动手改,毕竟代码都有。相对自己从0开始做一套系统还是有优势的。2.下载环节还是建议考虑合包下载,毕竟不停开关N个HTTP连接消耗也是不少的,尤其当下载的粒度太细,Patch本身Size很小的情况下,会发现下载速度上不去。可以考虑客户端处理上还是小文件,但服务器端将相关Patch整理在一起合进大文件,然后利用HTTP的Range下载模式来定位下载这个大文件中一部分连续数据,这样减少HTTP连接数,提高下载效率。
3.读取在StreamingAssets内的AssetBundle文件不大,引擎自己搞定,但是读取非AssetBundle的资源,在Android平台下需要自行处理一下,无法用File.Open的形式打开,需要接入NDK的AAssetManager接口来访问。
感谢黄程@UWA问答社区提供了回答,欢迎大家转至社区交流:
Delegate.Add/Remove这类堆内存分配问题如何优化? -- UWA问答:帮助开发者找到更好的答案
AssetBundle
Q:对于热更新包体的大小,最佳实践是多少?多大以上的更新建议不采用热更新而采用全包更新?如果一次更新的内容比较大,是否建议还是全包更新比较合适?包含多个AssetBundle。
A1:基本上现在AssetBundle都已经将其每个大小控制在5~10MB以下(5.3以前是1MB),这样就可以保证IO次数和热更新内容都尽可能小。
整包更新都不太好,会有大概10~15%的用户流失,所以能热更还是热更。热更新包的大小主要是去除冗余,因为LZ4本身已经是压缩级别了。
感谢OCEAN@UWA问答社区提供了回答
A2:国内渠道商比较多,获客成本比较高,所以换包的损失比较大,能走热更新还是尽量走热更新。
然后也可以考虑一下国内的一些第三方热更公司,比如乐变,他们支持无感知边玩边下,以热更新的方式替换主包。
感谢萧小俊@UWA问答社区提供了回答,欢迎大家转至社区交流:
Delegate.Add/Remove这类堆内存分配问题如何优化? -- UWA问答:帮助开发者找到更好的答案
Shader
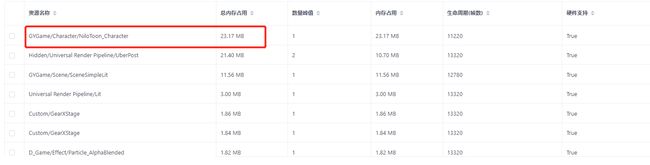
Q:如下图所示:
1.现象:这些资源出现2份是什么原因?
2.目前Shader内存占用太高了,能否给些推荐建议?
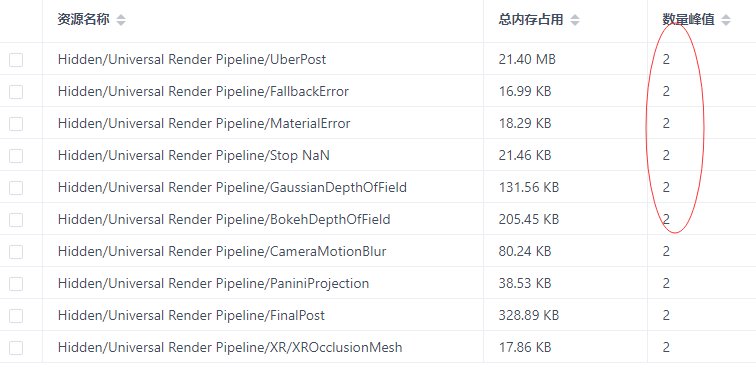
A:1.在编辑器中,当GraphicsSettings里面设置了RenderPipelineAsset之后,RenderPipelineAsset最终会引用PostProcessData,PostProcessData中引用了各种后处理相关的Shader,所以打包的时候,会将各种后处理相关的Shader打包进包体,比如UberPost、Bloom等。
而且这些资源会在RenderPipeline初始化的时候被加载进内存。这是UberPost的第一个实例的来源。
2.当我们在游戏实时运行的时候,比如涉及到切换RenderPipeline的操作,使用了AssetBundle加载RenderPipelineAsset,这样在AssetBundle中就又有了一份PostProcessData,因此这些后处理相关的Shader就又被加载了一次。总共就有2份UberPost了。
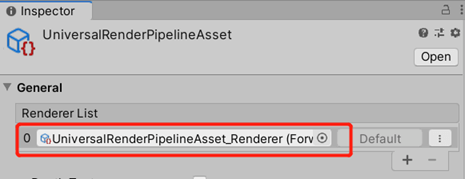
3.对此我们建议所有的RenderPipelineAsset相关的资源都由AssetBundle处理,在Editor的GraphicsSettings中将RenderPipelineAsset移除。通过脚本来动态从AssetBundle中加载并赋值。
4.可以创建一个空场景放在所有场景之前,在这个场景中动态加载RenderPipelineAsset,并赋值给GraphicsSetting.renderPipelineAsset,如下图:
之后所有的问题都只要注意AssetBundle的冗余就可以了。
优化Shader:
1.UberPost的Shader可以考虑将用不到的Keyword给注释掉。如下图:
2.对于内存占用非常多的Shader,需要优化Keyword组合数量,建议参考《Stripping scriptable shader variants》,使用后处理来优化Shader变体组合数量。




感谢一直有点困的仓鼠@UWA问答社区提供了回答,欢迎大家转至社区交流:
Delegate.Add/Remove这类堆内存分配问题如何优化? -- UWA问答:帮助开发者找到更好的答案
Performance
Q:关于手机发热问题,该从哪些方面入手?我们项目主要有大量PBR,另外模型都是高模。是不是手机性能越高,发热越明显?
A1:这个可以反推一下:
发热=耗电高
耗电高=GPU CPU高负荷
最有效的方式应该是先锁帧,然后就是想办法优化GPU和CPU了,针对这2个优化方案有很多,可以找找适合你们项目的。
感谢萧小俊@UWA问答社区提供了回答
A2:回答如下:
1.发烫的问题都是从CPU\GPU和IO入手的。
2.不是。性能越差,同样的计算力,发热才会更明显。这块个人认为是需要定位下耗时在哪里才好做判断的。没有统一说性能好发热也明显的说法。比如:你们做了分级策略,在高端设备上开的效果越大,那自然发热发烫就明显。
感谢OCEAN@UWA问答社区提供了回答
A3:发热是一定会有的,并不是说做好了之后就没有发热,而是多久能发热到多少度,达到一个预期就行:
1.首先要定好分级策略,其次再查对应分级设备上的发热问题。
2.还有就是先限制好30帧,做好30帧的发热问题,再去做高帧率的发热问题。
3.可以通过UWA的温度模块看发热的趋势,还是比较准确的,温度过高就会导致降频。
4.就我们项目解决发热的流程来看,发热与功耗是正相关的。这个功耗可能是CPU,也可能是GPU,功耗可以通过PerfDog查看,也可以参考雨松的文章《Unity3D研究院之实时获取手机电流、电压、计算功率发热(一百一十八)》,分别测试CPU和GPU哪块功耗高具体定位一下。
PBR项目可能主要是GPU,GPU主要就是带宽和计算量,带宽占大头,带宽也分为两部分Read/Write Bandwidth。Read是上传几何信息和贴图,Write主要是写回到FrameBuffer和RT的存储,关于带宽可以使用Arm MS StreamLine工具或者PerfDog辅助查看一下(只有Mali的GPU可以看),到最后可能还是让美术去优化资源。
5.CPU的就要具体模块具体看了,注意线程的使用。Profiler看不到,当时我们就是遇到线程内的问题导致的发热,查起来比较麻烦。
感谢范世青@UWA问答社区提供了回答,欢迎大家转至社区交流:
Delegate.Add/Remove这类堆内存分配问题如何优化? -- UWA问答:帮助开发者找到更好的答案
Script
Q:如何优化Delegate.Add/Remove这类堆内存分配问题?
A1:降低使用频率,尤其是不要在一个代理里加过多的函数,会导致其堆内存分配更大,因为其实现原理是复制一个List来使用的。
感谢OCEAN@UWA问答社区提供了回答
A2:其实Delegate的+= 是会有很严重的GC问题的,可以考虑用一个字典去代替。

感谢萧小俊@UWA问答社区提供了回答,欢迎大家转至社区交流:
Delegate.Add/Remove这类堆内存分配问题如何优化? -- UWA问答:帮助开发者找到更好的答案
20210913
更多精彩问题等你回答~
1.Vulkan API的性能及兼容性
2.Unity TMP字体方案如何选择
3.如何实现AAB包的增量更新
封面图来源于网络
今天的分享就到这里。当然,生有涯而知无涯。在漫漫的开发周期中,您看到的这些问题也许都只是冰山一角,我们早已在UWA问答网站上准备了更多的技术话题等你一起来探索和分享。欢迎热爱进步的你加入,也许你的方法恰能解别人的燃眉之急;而他山之“石”,也能攻你之“玉”。
官网:www.uwa4d.com
官方技术博客:blog.uwa4d.com
官方问答社区:answer.uwa4d.com
UWA学堂:edu.uwa4d.com
官方技术QQ群:793972859(原群已满员)