Python实战RBF神经网络
程序员A:哥们儿,最近手头紧,借点钱? 程序员B:成啊,要多少? A:1000行不? B:咱俩谁跟谁!给你凑个整,这1024,拿去吧。

之前我们讲了神经网络,人工神经网络是受到人类大脑结构的启发而创造出来的,这也是它能拥有真智能的根本原因。在我们的大脑中,有数十亿个称为神经元的细胞,它们连接成了一个神经网络。
人工神经网络正是模仿了上面的网络结构。下面是一个人工神经网络的构造图。每一个圆代表着一个神经元,他们连接起来构成了一个网络。

人类大脑神经元细胞的树突接收来自外部的多个强度不同的刺激,并在神经元细胞体内进行处理,然后将其转化为一个输出结果。人工神经元也有相似的工作原理。

上面的x是神经元的输入,相当于树突接收的多个外部刺激。w是每个输入对应的权重,它影响着每个输入x的刺激强度。
大脑的结构越简单,那么智商就越低。单细胞生物是智商最低的了。人工神经网络也是一样的,网络越复杂它就越强大,所以我们需要深度神经网络。这里的深度是指层数多,层数越多那么构造的神经网络就越复杂。
训练深度神经网络的过程就叫做深度学习。网络构建好了后,我们只需要负责不停地将训练数据输入到神经网络中,它内部就会自己不停地发生变化不停地学习。打比方说我们想要训练一个深度神经网络来识别猫。我们只需要不停地将猫的图片输入到神经网络中去。训练成功后,我们任意拿来一张新的图片,它都能判断出里面是否有猫。但我们并不知道他的分析过程是怎样的,它是如何判断里面是否有猫的。就像当我们教小孩子认识猫时,我们拿来一些白猫,告诉他这是猫,拿来一些黑猫,告诉他这也是猫,他脑子里会自己不停地学习猫的特征。最后我们拿来一些花猫,问他,他会告诉你这也是猫。但他是怎么知道的?他脑子里的分析过程是怎么样的?我们无从知道~~
只要模型是一层一层的,并使用AD/BP算法,就能称作 BP神经网络。RBF 神经网络是其中一个特例。本文主要包括以下内容:
什么是径向基函数
RBF神经网络
RBF神经网络的学习问题
RBF神经网络与BP神经网络的区别
RBF神经网络与SVM的区别
为什么高斯核函数就是映射到高维区间
前馈网络、递归网络和反馈网络
完全内插法
一、什么是径向基函数
1985年,Powell提出了多变量插值的径向基函数(RBF)方法。径向基函数是一个取值仅仅依赖于离原点距离的实值函数,也就是Φ(x)=Φ(‖x‖),或者还可以是到任意一点c的距离,c点称为中心点,也就是Φ(x,c)=Φ(‖x-c‖)。任意一个满足Φ(x)=Φ(‖x‖)特性的函数Φ都叫做径向基函数,标准的一般使用欧氏距离(也叫做欧式径向基函数),尽管其他距离函数也是可以的。
RBF网络能够逼近任意非线性的函数。可以处理系统内难以解析的规律性,具有很好的泛化能力,并且具有较快的学习速度。当网络的一个或多个可调参数(权值或阈值)对任何一个输出都有影响时,这样的网络称为全局逼近网络。
由于对于每次输入,网络上的每一个权值都要调整,从而导致全局逼近网络的学习速度很慢,比如BP网络。如果对于输入空间的某个局部区域只有少数几个连接权值影响输出,则该网络称为局部逼近网络,比如RBF网络。接下来重点先介绍RBF网络的原理,然后给出其实现。先看如下图

最常用的径向基函数是高斯核函数 ,形式为 k(||x-xc||)=exp{- ||x-xc||2/(2*σ)2) } 其中x_c为核函数中心,σ为函数的宽度参数 , 控制了函数的径向作用范围。
二、RBF神经网络
RBF神将网络是一种三层神经网络,其包括输入层、隐层、输出层。从输入空间到隐层空间的变换是非线性的,而从隐层空间到输出层空间变换是线性的。流图如下:

RBF网络的基本思想是:用RBF作为隐单元的“基”构成隐含层空间,这样就可以将输入矢量直接映射到隐空间,而不需要通过权连接。当RBF的中心点确定以后,这种映射关系也就确定了。而隐含层空间到输出空间的映射是线性的,即网络的输出是隐单元输出的线性加权和,此处的权即为网络可调参数。其中,隐含层的作用是把向量从低维度的p映射到高维度的h,这样低维度线性不可分的情况到高维度就可以变得线性可分了,主要就是核函数的思想。这样,网络由输入到输出的映射是非线性的,而网络输出对可调参数而言却又是线性的。网络的权就可由线性方程组直接解出,从而大大加快学习速度并避免局部极小问题。
径向基神经网络的激活函数可表示为:

其中xp
径向基神经网络的结构可得到网络的输出为:
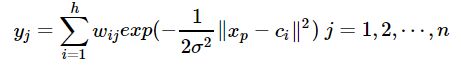
当然,采用最小二乘的损失函数表示:

三、RBF神经网络的学习问题
求解的参数有3个:基函数的中心、方差以及隐含层到输出层的权值。
(1)自组织选取中心学习方法:
第一步:无监督学习过程,求解隐含层基函数的中心与方差
第二步:有监督学习过程,求解隐含层到输出层之间的权值
首先,选取h个中心做k-means聚类,对于高斯核函数的径向基,方差由公式求解:

cmax为所选取中心点之间的最大距离。
隐含层至输出层之间的神经元的连接权值可以用最小二乘法直接计算得到,即对损失函数求解关于w的偏导数,使其等于0,可以化简得到计算公式为:

(2)直接计算法:
隐含层神经元的中心是随机地在输入样本中选取,且中心固定。一旦中心固定下来,隐含层神经元的输出便是已知的,这样的神经网络的连接权就可以通过求解线性方程组来确定。适用于样本数据的分布具有明显代表性。
(3)有监督学习算法:
通过训练样本集来获得满足监督要求的网络中心和其他权重参数,经历一个误差修正学习的过程,与BP网络的学习原理一样,同样采用梯度下降法。因此RBF同样可以被当作BP神经网络的一种。
四、RBF神经网络与BP神经网络之间的区别
1、局部逼近与全局逼近:
BP神经网络的隐节点采用输入模式与权向量的内积作为激活函数的自变量,而激活函数采用Sigmoid函数。各调参数对BP网络的输出具有同等地位的影响,因此BP神经网络是对非线性映射的全局逼近。RBF神经网络的隐节点采用输入模式与中心向量的距离(如欧式距离)作为函数的自变量,并使用径向基函数(如Gaussian函数)作为激活函数。神经元的输入离径向基函数中心越远,神经元的激活程度就越低(高斯函数)。RBF网络的输出与部分调参数有关,譬如,一个wij值只影响一个yi的输出(参考上面第二章网络输出),RBF神经网络因此具有“局部映射”特性。

所谓局部逼近是指目标函数的逼近仅仅根据查询点附近的数据。而事实上,对于径向基网络,通常使用的是高斯径向基函数,函数图象是两边衰减且径向对称的,当选取的中心与查询点(即输入数据)很接近的时候才对输入有真正的映射作用,若中心与查询点很远的时候,欧式距离太大的情况下,输出的结果趋于0,所以真正起作用的点还是与查询点很近的点,所以是局部逼近;而BP网络对目标函数的逼近跟所有数据都相关,而不仅仅来自查询点附近的数据。

2、中间层数的区别
BP神经网络可以有多个隐含层,但是RBF只有一个隐含层。
3、训练速度的区别
使用RBF的训练速度快,一方面是因为隐含层较少,另一方面,局部逼近可以简化计算量。对于一个输入x,只有部分神经元会有响应,其他的都近似为0,对应的w就不用调参了。
4、Poggio和Girosi已经证明,RBF网络是连续函数的最佳逼近,而BP网络不是。


五、RBF神经网络与SVM的区别
SVM等如果使用核函数的技巧的话,不太适应于大样本和大的特征数的情况,因此提出了RBF。另外,SVM中的高斯核函数可以看作与每一个输入点的距离,而RBF神经网络对输入点做了一个聚类。RBF神经网络用高斯核函数时,其数据中心C可以是训练样本中的抽样,此时与svm的高斯核函数是完全等价的,也可以是训练样本集的多个聚类中心,所以他们都是需要选择数据中心的,只不过SVM使用高斯核函数时,这里的数据中心都是训练样本本身而已。

最后上python代码实现:
from scipy import *
from scipy.linalg import norm, pinv
from matplotlib import pyplot as plt
class RBF:
def __init__(self, indim, numCenters, outdim):
self.indim = indim
self.outdim = outdim
self.numCenters = numCenters
self.centers = [random.uniform(-1, 1, indim) for i in xrange(numCenters)]
self.beta = 8
self.W = random.random((self.numCenters, self.outdim))
def _basisfunc(self, c, d):
assert len(d) == self.indim
return exp(-self.beta * norm(c-d)**2)
def _calcAct(self, X):
# calculate activations of RBFs
G = zeros((X.shape[0], self.numCenters), float)
for ci, c in enumerate(self.centers):
for xi, x in enumerate(X):
G[xi,ci] = self._basisfunc(c, x)
return G
def train(self, X, Y):
""" X: matrix of dimensions n x indim
y: column vector of dimension n x 1 """
# choose random center vectors from training set
rnd_idx = random.permutation(X.shape[0])[:self.numCenters]
self.centers = [X[i,:] for i in rnd_idx]
print "center", self.centers
# calculate activations of RBFs
G = self._calcAct(X)
print G
# calculate output weights (pseudoinverse)
self.W = dot(pinv(G), Y)
def test(self, X):
""" X: matrix of dimensions n x indim """
G = self._calcAct(X)
Y = dot(G, self.W)
return Y
if __name__ == '__main__':
n = 100
x = mgrid[-1:1:complex(0,n)].reshape(n, 1)
# set y and add random noise
y = sin(3*(x+0.5)**3 - 1)
# y += random.normal(0, 0.1, y.shape)
# rbf regression
rbf = RBF(1, 10, 1)
rbf.train(x, y)
z = rbf.test(x)
# plot original data
plt.figure(figsize=(12, 8))
plt.plot(x, y, 'k-')
# plot learned model
plt.plot(x, z, 'r-', linewidth=2)
# plot rbfs
plt.plot(rbf.centers, zeros(rbf.numCenters), 'gs')
for c in rbf.centers:
# RF prediction lines
cx = arange(c-0.7, c+0.7, 0.01)
cy = [rbf._basisfunc(array([cx_]), array([c])) for cx_ in cx]
plt.plot(cx, cy, '-', color='gray', linewidth=0.2)
plt.xlim(-1.2, 1.2)
plt.show()