基于kaggle欧洲国家太阳能发电数据集进行聚类分析
文章目录
-
- 简介
- 1、聚类
-
- 1.1 数据获取
- 1.2 簇数确定
- 1.3 聚类结果
- 2、 分析每个集群
简介
该数据集由两部分组成,一个是各国数据,一个是各国各太阳能站点数据。确定簇数时,两个数据集都使用!簇数确定后,仅适用国家数据集进行聚类,并对每个集群中的国家代表进行统计分析。
1、聚类
1.1 数据获取
path = "dataset"
df_solar_co = pd.read_csv(path + "\solar_generation_by_country.csv")
df_solar_st = pd.read_csv(path + "\solar_generation_by_station.csv")
df_solar_st = df_solar_st.drop(columns=['time_step'])#删去时间戳列
1.2 簇数确定
以近1年的数据计算轮廓系数和肘图,从而确定簇数k。
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
def plot_elbow_scores(df_, cluster_nb):#轮廓系数+肘方法
km_inertias, km_scores = [], []
for k in range(2, cluster_nb):
km = KMeans(n_clusters=k).fit(df_)
km_inertias.append(km.inertia_)#所有簇平方和
km_scores.append(silhouette_score(df_, km.labels_))#轮廓系数
sns.lineplot(range(2, cluster_nb), km_inertias)
plt.title('elbow graph / inertia depending on k')
plt.show()
sns.lineplot(range(2, cluster_nb), km_scores)
plt.title('scores depending on k')
plt.show()
#太阳能站点
df_solar_transposed = df_solar_st[-24*365:].T
plot_elbow_scores(df_solar_transposed, 20)
#对太阳能发电国家
df_solar_transposed = df_solar_co[-24 * 365:].T
plot_elbow_scores(df_solar_transposed, 20)
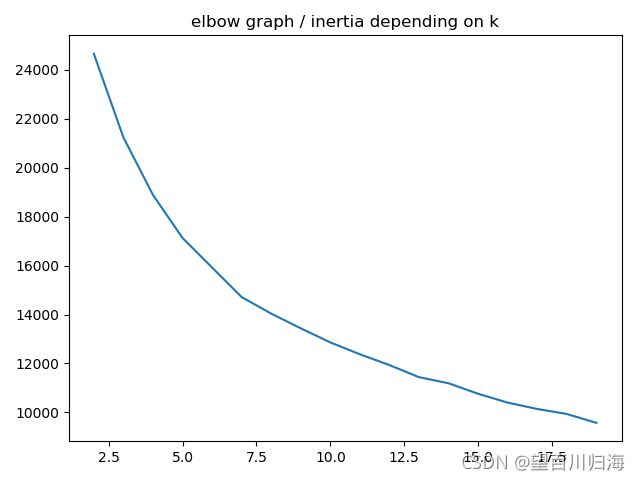
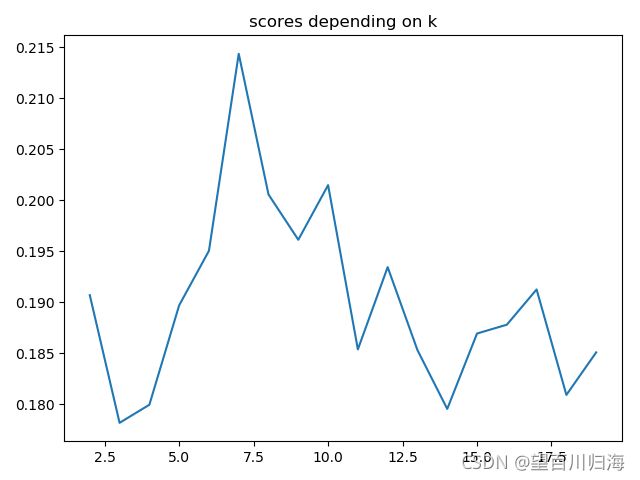
对于站点
如果第一个图上没有任何真正的肘部,那么最好的 k 似乎是 7。
肘图
轮廓系数
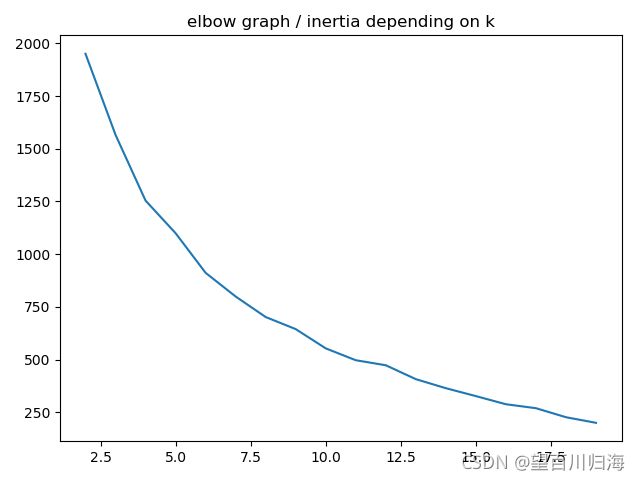
对于国家
如果第一个图上没有任何真正的肘部,那么最好的 k 似乎是 6。
肘图
轮廓系数

最优簇数k确定:站点和国家的结果相差不大,表示簇数为6可信度较好,因此取k=6。
1.3 聚类结果
km = KMeans(n_clusters=6).fit(X)
X['label'] = km.labels_
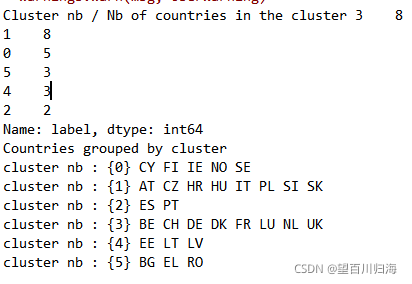
print("Cluster nb / Nb of countries in the cluster", X.label.value_counts())
print("Countries grouped by cluster")
for k in range(6):
print('cluster nb : {k}', " ".join(list(X[X.label == k].index)))
聚类结果如图所示:
2、 分析每个集群
每个集群都用一个国家来代表
24小时内每个国家太阳能发电站的效率
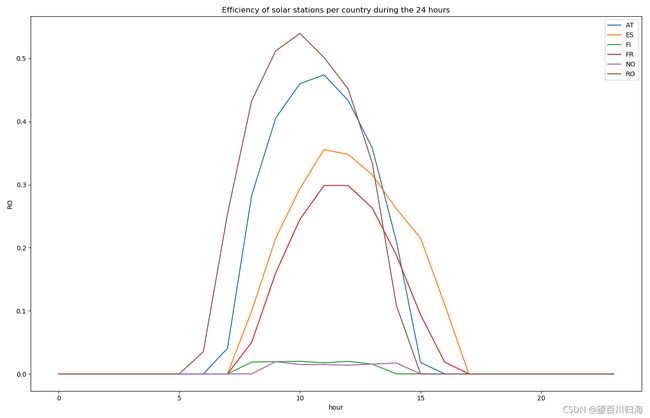
特定某天各国太阳能发电站的效率

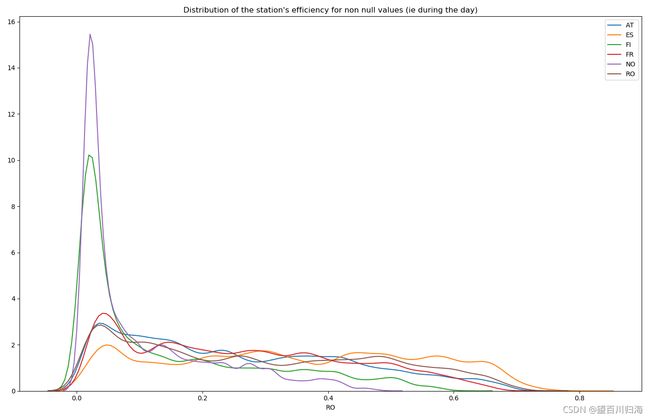
非空值的站点效率分布(即白天)
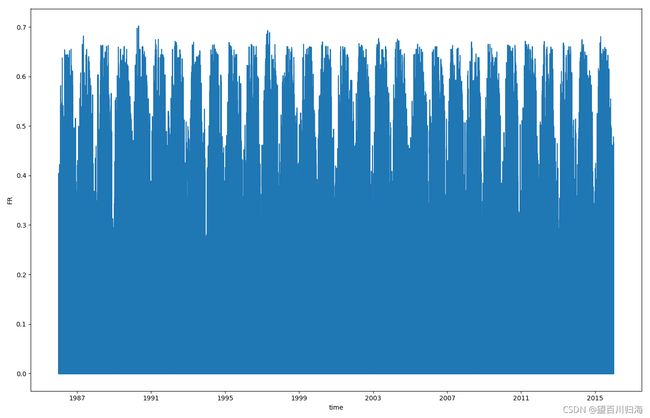
法国1985到2015的效率分布
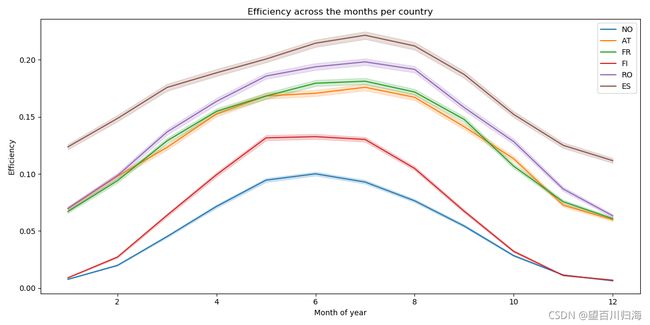
各国月效率
各国周效率

各国年效率
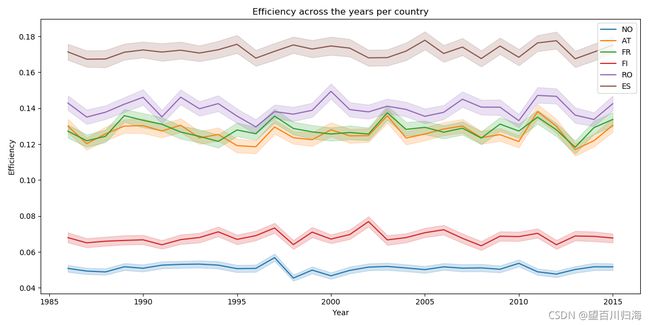
只考虑上午5点到下午10点
各国第三4分位数
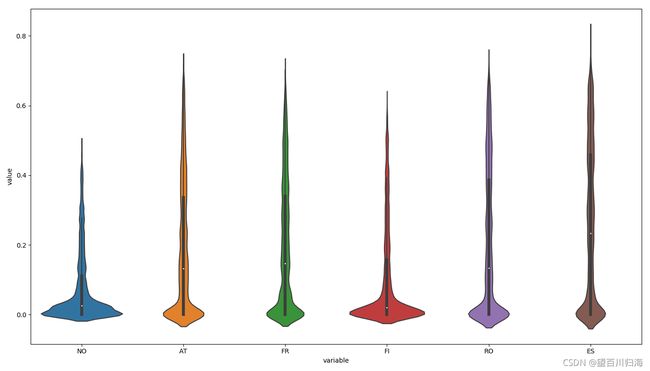
 小提琴图了解密度
小提琴图了解密度
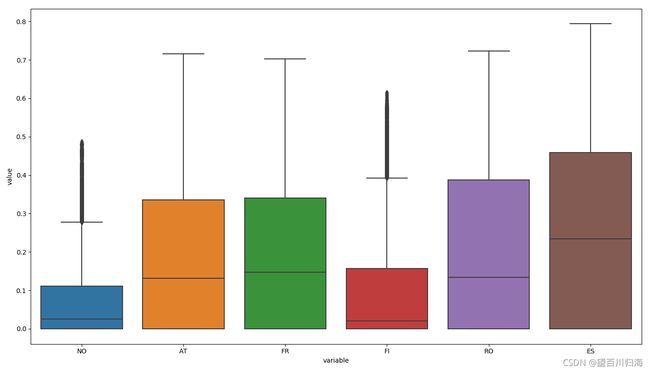
箱线图
相关图
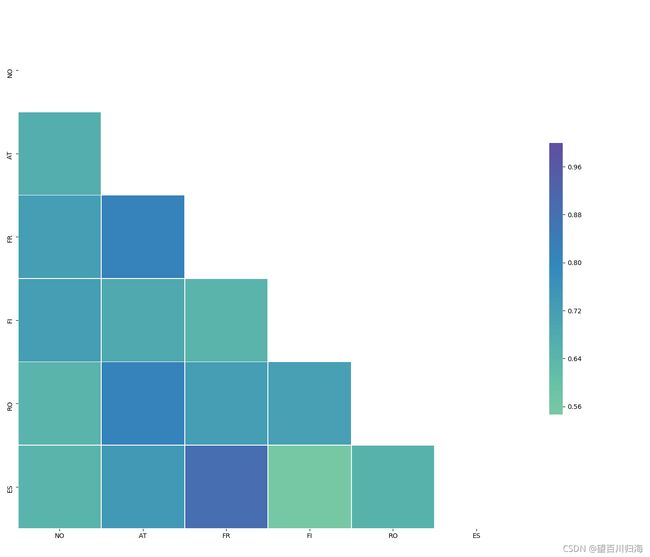
热力图
