机器学习--协同过滤实验及源码(Python版)
【实验目的】
1.掌握协同过滤算法的原理。
2.掌握相似度算法。
3.掌握使用Python代码实现协同过滤算法。
【实验原理】
算法简介
协同过滤(Collaborative Filtering,简称CF),协同过滤算法的原理是汇总所有的行为对, 利用集体智慧做推荐。其原理很像朋友推荐, 比如通过对用户喜欢的item进行分析, 发现用户A和用户B很像(他们都喜欢差不多的东西), 用户B喜欢了某个item, 而用户A没有喜欢, 那么就把这个item推荐给用户A。(User-Based CF)
当然, 还有另外一个维度的协同推荐。即对比所有数据, 发现itemA和itemB很像(他们被差不多的人喜欢), 那么就把用户A喜欢的所有item, 将这些item类似的item列表拉出来, 作为被推荐候选推荐给用户A。(Item-Based CF)
如上说的都是个性化推荐, 如果是相关推荐, 就直接拿Item-Based CF的中间结果。
该算法的好处是:
(1)能起到意想不到的推荐效果, 经常能推荐出来一些惊喜结果
(2)进行有效的长尾item
(3)只依赖用户行为, 不需要对内容进行深入了解, 使用范围广
该算法的坏处是:
(1)一开始需要大量的行为数据, 即需要大量冷启动数据
(2)很难给出合理的推荐解释
算法原理
协同过滤算法的主要思想是利用的打分矩阵, 利用统计信息计算用户和用户, item和item之间的相似度。然后再利用相似度排序, 最终得出推荐结果。
常见的算法原理如下:
(1)User-Based CF
先看公式:
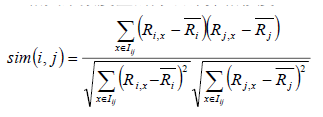
该公式要计算用户i和用户j之间的相似度, I(ij)是代表用户i和用户j共同评价过的物品, R(i,x)代表用户i对物品x的评分, R(i)头上有一杠的代表用户i所有评分的平均分, 之所以要减去平均分是因为有的用户打分严有的松, 归一化用户打分避免相互影响。
该公式没有考虑到热门商品可能会被很多用户所喜欢, 所以还可以优化加一下权重。
在实际生产环境中, 经常用到另外一个类似的算法Slope One, 该公式是计算评分偏差, 即将共同评价过的物品, 将各自的打分相减再求平均。
(2)Item-Based CF
先看公式:

该公式跟User-Based CF是类似。

相似度算法

(1)基于欧几里德距离的相似度
欧几里德距离是一个较为简单的用户关系评价方法。原理是通过计算两个用户在散点图中的距离来判断不同的用户是否有相同的偏好。它以经过人们一致评价的物品为坐标轴,然后将参与评价的人绘制到坐标系上,并计算他们彼此之间的直线距离。计算出来的欧几里德距离是一个大于0的数,为了使其更能体现用户之间的相似度,可以把它规约到(0.1]之间,最终得到如下计算公式:
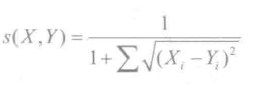
只要至少有一个共同评分项,就能用欧几里德距离计算相似度,如果没有共同评分项,那么欧几里德距离也就失去了作用。其实照常理,如果没有共同评分项,那么意味着这两个用户或物品根本不相似。
(2)皮尔逊相关系数
皮尔逊相关度是另一种计算用户间关系的方法。他比欧几里德距离评价的计算要复杂一些,但对于评分数据不规范时皮尔逊相关度评价能够给出更好的结果。皮尔逊相关系数一般用户计算两个定距变量间联系的紧密度,它的取值在[-1,1]之间。用数学公式表示,皮尔逊相关系数等于两个变量协方差除于两个变量的标准差。计算公式如下所示:
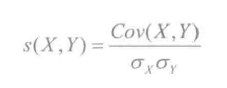

协方差是用来衡量X,Y的变化趋势是否一致。
由于皮尔逊相关系数描述的是两组数据变化移动的趋势,所以在基于用户的协同过滤系统中经常使用。描述用户购买或评分变化的趋势,若趋势相近则皮尔逊系数趋近于1,也就是我们认为相似的用户。
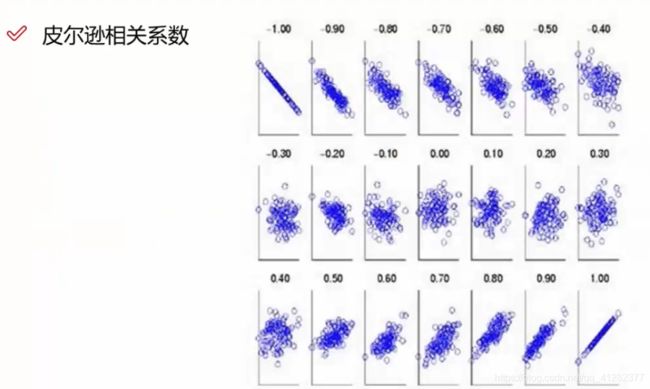
(3)余弦相似度
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。余弦相似度更加注重两个向量在方向上的差异,而非在距离或长度上,计算公式如下所示:
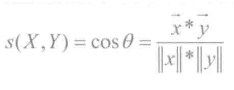
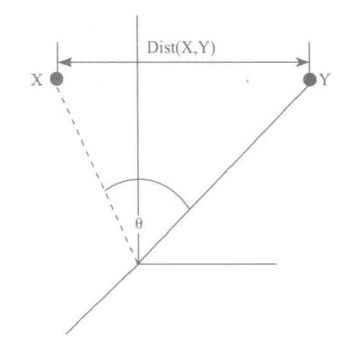
从下图可以看出距离度量衡量的是空间各点间的绝对距离,跟各点所在的位置坐标直接相关;而余弦相似度衡量的是空间向量的夹角,更加注重的是体现在方向上的差异。而不是位置。如果保持X点的位置不变,Y点朝原方向远离坐标轴原点,那么这个时候余弦相似度是保持不变的,因为夹角不变,而X、Y的距离显然在发生改变,这就是欧氏距离和余弦相似度的不同之处。
【实验环境】
Ubuntu 16.04
Anaconda 4.3
python 3.6
Pycharm(Community)
【实验内容】
本次实验任务,我们使用Python代码实现基于物品的相似度推荐代码和基于用户的相似度推荐代码。
【实验步骤】
1.打开Pycharm,新建项目,项目位置名称:/data/Test

2.在项目名Test下,创建Python File文件。

3.创建以demo1命名的py文件。
接下来我们在demo1.py中编写基于物品的相似度推荐代码。
import numpy as np
#(1)数据输入。
users = ["贝贝", "晶晶", "欢欢", "迎迎", "妮妮"]
movies = ["战狼2", "哪吒之魔童转世", "流浪地球", "红海行动", "唐人街探案2", "美人鱼", "我和我的祖国"]
UsMoList=[
[1, 1, 1, 0, 1, 0, 0],
[0, 1, 1, 0, 0, 1, 0],
[1, 0, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 0, 0],
[1, 1, 0, 1, 0, 1, 1]]
#(2)将行转为列
def RowConverCol():
return np.array(UsMoList).transpose().tolist()
#(3)使用欧氏距离计算两个电影之间的相似度。
def euc_mv_sim(movieFirst: list, movieSecond:list):
return np.sqrt(((np.array(movieFirst) - np.array(movieSecond)) ** 2).sum())
#(4)计算所有电影之间的相似度。
def allmv_sim():
resDic = {}
tempList = RowConverCol()
for i in range(0, len(tempList)):
for j in range(i+1, len(tempList)):
resDic[str(i) + '-' + str(j)] = euc_mv_sim(tempList[i], tempList[j])
return resDic
#(5)计算要推荐哪些电影。
def comput_Rec_mo(username: str) -> list:
temp = {}
mo_sim_dic = allmv_sim()
userindex = users.index(username)
TargetUsermovieList = UsMoList[userindex]
for i in range(0, len(TargetUsermovieList)):
for j in range(i+1, len(TargetUsermovieList)):
if TargetUsermovieList[i] == 1 and TargetUsermovieList[j] == 0 and (mo_sim_dic.get(str(i) + '-' + str(j)) != None or mo_sim_dic.get(str(j) + '-' + str(i)) != None):
sim = mo_sim_dic.get(str(i) + '-' + str(j)) if(mo_sim_dic.get(str(i) + '-' + str(j)) != None) else mo_sim_dic.get(str(j) + '-' + str(i))
temp[j] = sim
elif TargetUsermovieList[i] == 0 and TargetUsermovieList[j] == 1 and (mo_sim_dic.get(str(i) + '-' + str(j)) != None or mo_sim_dic.get(str(j) + '-' + str(i)) != None):
sim = mo_sim_dic.get(str(i) + '-' + str(j)) if (mo_sim_dic.get(str(i) + '-' + str(j)) != None) else mo_sim_dic.get(str(j) + '-' + str(i))
temp[i] = sim
temp = sorted(temp.items(), key=lambda d:d[1])
#temp = sorted(temp.items())
print("推荐列表:",temp)
recommendlist = [movies[i] for i,v in temp]
print("电影推荐:", recommendlist)
return recommendlist
print(allmv_sim())
comput_Rec_mo("晶晶")
comput_Rec_mo("欢欢")
右键,点击Run ‘demo1’,运行demo1.py。
运行结果如下:

用notebook运行结果为:

接下来我们在demo2.py中编写基于用户的相似度推荐代码。
demo2.py完整代码如下:
# -*- coding=utf-8 -*-
import math
from operator import *
#(1)将原始数据存储到一个用户字典dic中。
dic = {'贝贝': ('战狼2', '哪吒之魔童降世', '红海行动'), '晶晶': ('战狼2', '流浪地球'), '欢欢': ('哪吒之魔童降世', '唐人街探案2'), '迎迎': ('流浪地球', '红海行动', '唐人街探案2')}
#(2)将dic字典转成商品-用户字典。
#计算用户兴趣相似度
def userSim(dicc):
#把用户-商品字典转成商品-用户字典
item_user=dict()
for u,items in dicc.items():
for i in items:
if i not in item_user.keys():
item_user[i]=set() #i键所对应的值是一个集合(不重复)。
item_user[i].add(u)
C=dict()#真实数据集为数字编号,但这里是字符,这里还用字典。
N=dict()
for item,users in item_user.items():
for u in users:
if u not in N.keys():
N[u]=0
N[u]+=1 #每个商品下用户出现一次就加一次,就是计算每个用户一共购买的商品个数。
for v in users:
if u==v:
continue
if (u,v) not in C.keys():#同上,没有初始值不能+=
C[u,v]=0
C[u,v]+=1
#(3)到这里倒排阵就建立好了,下面是计算相似度。
W=dict()
for co_user,cuv in C.items():
W[co_user]=cuv / math.sqrt(N[co_user[0]]*N[co_user[1]])
return W
#(4)找到K个相关用户以及对应兴趣相似度,按兴趣相似度从大到小排列。
def userRec(user,dicc,W2,K):
rvi=1 #这里都是1,实际中可能每个用户就不一样了。就像每个人都喜欢beautiful girl,但有的喜欢可爱的多一些,有的喜欢御姐多一些。
rank=dict()
related_user=[]
interacted_items=dicc[user]
for co_user,item in W2.items():
if co_user[0]==user:
related_user.append((co_user[1],item))#先建立一个和待推荐用户兴趣相关的所有的用户列表。
for v,wuv in sorted(related_user,key=itemgetter(1),reverse=True)[0:K]:
for i in dicc[v]:
if i in interacted_items:
continue
if i not in rank.keys():
rank[i]=0
rank[i]+=wuv*rvi
return rank
if __name__=='__main__':
W3=userSim(dic)
Last_Rank=userRec('晶晶',dic,W3,2)
print (Last_Rank) ![]()