论文阅读笔记 | 分类网络——ConvMixer
如有错误,恳请指出。
文章目录
- 1. Introduction
- 2. ConvMixer Model
- 3. Result
paper:Patches Are All You Need
code:https://github.com/tmp-iclr/convmixer

(目前文章还处理盲审阶段)
摘要:
多年来卷积网络一直是视觉任务的主要架构,但最近的实验表明,基于Transformer的模型,尤其是vision Transformer (ViT),在某些设置下可能会超过它们的性能。然而,为了将 Transformer 应用于图像领域,信息的表示方法必须改变:因为如果在每像素级别上应用 Transformer 中的自注意力层,它的计算成本将与每张图像的像素数成二次方扩展,所以折衷的方法是首先将图像分成多个 patch,再将这些 patch 线性嵌入 ,最后将 transformer 直接应用于此 patch 集合。
随后,作者便提出了一个问题:ViT的性能是由于固有的更强大的Transformer架构,还是因为使用patch作为输入来进行表示?
基于这个想法,作者提出了ConvMixer为后者提供了一些证据。ConvMixer类似于ViT和更基本的MLP-Mixer,它直接对作为输入的patch操作,分离空间和通道维度的混合,并在整个网络中保持相同的大小和分辨率。相比之下,ConvMixer只使用标准的卷积来实现混合步骤。
ConvMixer在类似参数计数和数据集大小的情况下优于ViT、MLP-Mixer及其一些变体,此外还优于ResNet等经典视觉模型。
1. Introduction
Vision Transformer架构在许多计算机视觉任务中展示了令人信服的性能,通常优于经典的卷积架构,特别是对于大型数据集。一个可以理解的假设是,Transformer成为视觉领域的主导架构只是时间问题,就像它们成为语言处理领域(NLP)的主导架构一样。
然而,为了将 Transformer 应用于图像领域,信息的表示方法必须改变:因为如果在每像素级别上应用 Transformer 中的自注意力层,它的计算成本将与每张图像的像素数成二次方扩展,所以折衷的方法是首先将图像分成多个 patch,再将这些 patch 线性嵌入 ,最后将 transformer 直接应用于此 patch 集合。
作者提出了一个探讨:Vit的强大性能可能更多的来自与基于patch的表示方法,而不是Transformer架构的本身。为此,作者开发了一个非常简单的卷积架构,命名为:ConvMixer。
ConvMixer直接在patch上操作,它在所有层中保持相同分辨率和大小的表示。其不对连续层的表示进行下采样操作,分离空间和通道维度的混合。但与Vision Transformer和MLP-Mixer不同的是,ConvMixer架构只通过标准的卷积来完成所有这些操作。
ConvMixer架构极其简单(它可以在约6行密集的PyTorch代码中实现),但它优于一些标准的计算机视觉模型,如类似参数数的ResNets和一些相应的vision Transformer和MLP-Mixer变体。实验结果表明,patch表示本身可能会是Vision transformer这样的新架构卓越性能的最关键组件。
2. ConvMixer Model
ConvMixer由一个patch embedding层和一个简单的全卷积块的重复应用组成,并保持着patch embedding的空间结构。ConvMixer结构如图所示:
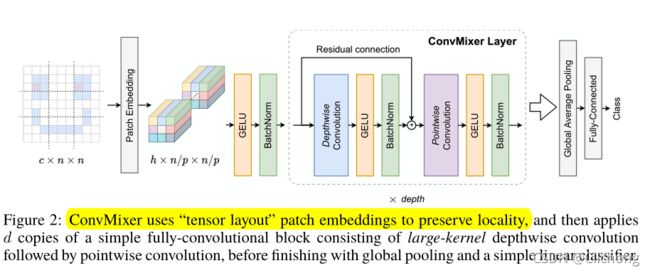
(整体结构一目了然,确实比较简单)
Patch size为 p p p,embedding dimension为 h h h的Patch embeddings操作,可以通过input channels为 c i n c_{in} cin,output channels为 h h h,kernel size为 p p p, stride为 p p p的卷积操作实现,数学表示为:
z 0 = B N ( σ { C o n v c i n → h ( X , s t r i d e = p , k e r n e l s i z e = p ) } ) (1) z_{0} = BN(σ\{Conv_{c_{in}→h}(X,stride=p,kernel_size=p)\}) \tag{1} z0=BN(σ{ Convcin→h(X,stride=p,kernelsize=p)})(1)
ConvMixer block中包含了 depthwise卷积,这个是在MobileNet中提出来的,相关内容可以查看文章:轻量级网络——MobileNetV1中的相关内容。其实也就是分组卷积(这里分组为h)+ 1x1卷积的联合操作。
对于深度卷积,convmixer在异常大的内核尺寸下工作得最好。每个卷积之后都有一个激活和激活后的BatchNorm。数学表示为:
z l ′ = B N ( σ { C o n v D e p t h w i s e ( z l − 1 ) } ) + z l − 1 z l + 1 = B N ( σ { C o n v P o i n t w i s e ( z l ′ ) } ) (2) \begin{aligned} z'_{l} &= BN(σ\{ConvDepthwise(z_{l-1})\}) +z_{l-1} \tag{2} \\ z_{l+1} &= BN(σ\{ConvPointwise(z'_{l})\}) \end{aligned} zl′zl+1=BN(σ{ ConvDepthwise(zl−1)})+zl−1=BN(σ{ ConvPointwise(zl′)})(2)
应用多次convmixer layer之后,执行全局池化操作以得到一个size为 h h h的特征向量,并将其传递给softmax分类器。(也就是将h个patch变成了一个h维的特征向量,再进行全连接分类)
- 维度变化过程:
现在以一个3x224x224图像处理为例,设置p为7也就是设置patch_size大小为7,所以会得到32x32个patch,每个patch多携带的信息维度channels为h(设置dim=512,既h=512),那么经过了Patch Embedding卷积操作后会有3x224x224变成512x32x32的大小(在Patch Embedding这一步中,kernel_size = stride = patch_size = 7)。通过了Patch Embedding之后,就是堆叠一系列的DW+PW卷积(这里的kernel_size会认为设置得大一点,来混合较远的空间位置),这些步骤中的channels是保持不变的,最后32x32会被池化为1x1,也就是512x1x1再通过一个全连接进行分类,得到最后的结果。
- 设计参数:ConvMixer 的实例化取决于四个参数:
(1)宽度或隐藏维度 h(即 patch 嵌入的维度)
(2)深度 d,或 ConvMixer 层的重复次数
(3)控制模型内部分辨率的 patch 大小 p
(4)深度卷积层的内核大小 k
研究者根据它们的隐藏维度和深度命名 ConvMixers,如 ConvMixer-h/d。他们将原始输入大小 n 除以 patch 大小 p 作为内部分辨率,所以一个patch的shape为 ( h × n p × n p ) (h \times \frac{n}{p} \times \frac{n}{p}) (h×pn×pn);但是请注意,ConvMixers 支持可变大小的输入。
- 动机:ConvMixer 架构基于混合思想
该研究选择了 depthwise 卷积来混合空间位置,选择 pointwise 卷积来混合通道位置。先前工作的一个关键思想是 MLP 和自注意力可以混合较远的空间位置,即它们可以具有任意大的感受野。因此,该研究使用较大的内核卷积来混合较远的空间位置。
- pytorch代码实现
代码可以所是比较简单了
import torch.nn as nn
import torch
class Residual(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x):
return self.fn(x) + x
def ConvMixer(dim, depth, kernel_size=9, patch_size=7, n_classes=1000):
return nn.Sequential(
nn.Conv2d(3, dim, kernel_size=patch_size, stride=patch_size),
nn.GELU(),
nn.BatchNorm2d(dim),
*[nn.Sequential(
Residual(nn.Sequential(
nn.Conv2d(dim, dim, kernel_size, groups=dim, padding="same"),
nn.GELU(),
nn.BatchNorm2d(dim)
)),
nn.Conv2d(dim, dim, kernel_size=1),
nn.GELU(),
nn.BatchNorm2d(dim)
) for i in range(depth)],
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(dim, n_classes)
)
另外一个更加简化的版本为:
def ConvMixr(h,d,k,p,n):
S,C,A=Sequential,Conv2d,lambdax:S(x,GELU(),BatchNorm2d(h))
R=type('',(S,),{
'forward':lambdas,x:s[0](x)+x})
return S(A(C(3,h,p,p)),*[S(R(A(C(h,h,k,groups=h,padding=k//2))),A(C(h,h,1))) for i
in range(d)],AdaptiveAvgPool2d((1,1)),Flatten(),Linear(h,n))
3. Result
- 与DeiT与ResMLP的比较:

- 与其他模型的比较(全面):
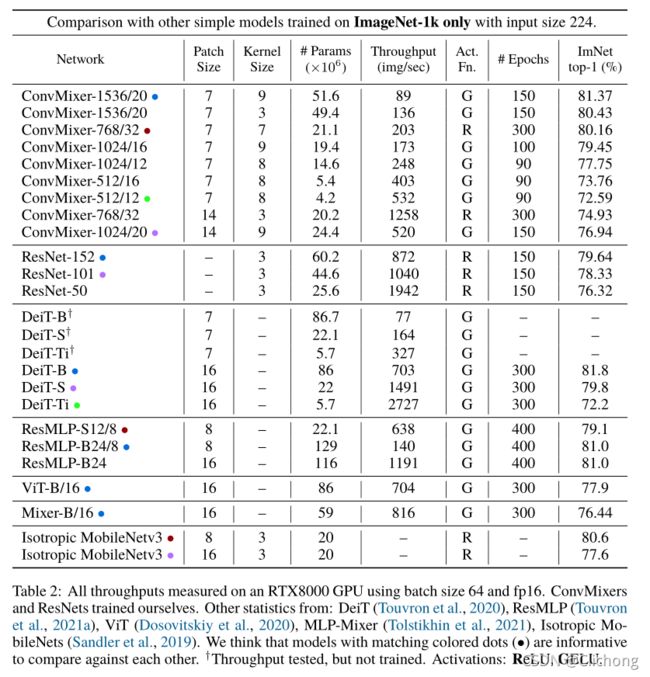
ConvMixers 的推理速度较竞品模型慢得多,这可能因为它们的 patch 更小。超参数调整和优化可以缩小这一差距。从图中也可以看见一个大Kernel_Size卷积操作所带来的效果提升。
小结:
作者提出了ConvMixer,仅仅使用标准卷积就能独立地混合patch embeddings的空间和通道位置。尽管达不到SOTA,但是优于Vision Transformer和MLPMixer,并可以与ResNets、DeiTs和ResMLPs竞争。
实验证明,越来越常见的“各向同性”架构与一个简单的Patch embeddings就可以构建出一个强大的网络结构。Patch embeddings允许所有的下采样同时发生,立即降低了内部分辨率,从而增加了有效的感受野大小,使其更容易混合遥远的空间信息。
标题主要想表达的意思是,attention并不是全部,token与Patch embeddings同样是一个重要的因素。
作者认为,经过更长的训练和更多的正则化和超参数调优,带有更大patch的更深层次的ConvMixer可以在精度、参数和吞吐量之间达成理想的折衷。大核深度卷积的低级优化可以大幅提高吞吐量。类似地,对体系结构进行小的改进,如添加bottlenecks或更具有表达能力的分类器,可以以简单换取性能。
整片文章主要内容只有4页,最后的结尾作者还补充了一点:

总结:
作者提出了Patch可能是Vit结构中另外一个比较重要的因素,而不仅仅是attention。通过搭建了一个比较简单的模型结构ConvMixer,结合了Patch Embedding同样可以与诸多先进模型比较,说明Patch在网络结构的重要性。