爬虫实战| python绘制全国鸿星尔克门店分布图,你的城市是最多的那个吗?
最近鸿星尔克频频上热搜
今天我们就使用python爬虫看看全国到底有多少家鸿星尔克门店
首先我们打开地图搜索 ‘鸿星尔克’

F12打开浏览器开发者模式,找到如下链接。
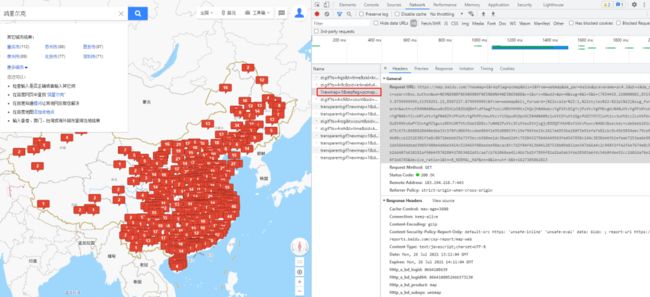
复制该链接到浏览器,发现这是一个json格式的数据集。我们所需要的省份和对应数量还有各个城市对应的数量都在其中。


发送请求
我们首先模拟浏览器来发送请求获取到这个json数据集,然后获取各个城市鸿星尔克门店及其对应数量
url = 'https://map.baidu.com/?newmap=1&reqflag=pcmap&biz=1&from=webmap&da_par=baidu&pcevaname=pc4.1&qt=s&da_src=searchBox.button&wd=%E9%B8%BF%E6%98%9F%E5%B0%94%E5%85%8B&c=1&src=0&wd2=&pn=0&sug=0&l=5&b=(7854419.220000001,831323.8799999999;15358291.22,8507227.879999999)&from=webmap&biz_forward={%22scaler%22:1,%22styles%22:%22pl%22}&sug_forward=&auth=yER4N%40Rwcw0cBSVCeS%3DdQBAfLdF6agFfuxLzNBVHVHRtxZhQxjh%40wWvvYgP1PcGCgYvjPuVtvYgPMGvgWv%40uVtvYgPPxRYuVtvYgP%40vYZcvWPCuVtvYgP%40ZPcPPuVtvYgPhPPyheuVtcvY1SGpuRtDpnSCE%40%40By1uVtCGYuVt1GgvPUDZYOYIZuVt1cv3uVtGccZcuVtPWv3GuBtR9KxXwPYIUvhgMZSguxzBEHLNRTVtcEWe1GD8zv7u%40ZPuVtc3CuVteuEthjzgjyBODQEYHUHBxfiKKvMuxcc%40AJ&seckey=cde6ebb241c3d75c675c8688828640edba33c570fc006f6ccdee864f2e95d88033fc19e794fee19c2417a6953ba260f3e91efa7e82cbc9c45b5854aec79ce924b08cce22526301f3a8c80710ebb635e73f5eccb560ee1dc38add2dfc793843279646449563fa4547850c144c3838de6fb1efaab7253aa6e99c1de56b4ddbad3905f480e4d46e5414c519465f08bedee98acac8fc7d2f84f413b041287538b09a811ee347b66a4c2c948f2ffa2f6e7674e0c5cb2b6407b610181af9064f870280fd7053482a91caa7cb762068ea41c4bb7bd2f7899f81a2ba5ab3fde28503a6fdc54b0fdee52cc2d02da76e1a4f1b4745&device_ratio=1&tn=B_NORMAL_MAP&nn=0&ie=utf-8&t=1627305062813'
headers = {
'Cookie': 'BIDUPSID=5FDDBE7E96E9CA6D71998093E123403A; PSTM=1627225875; BAIDUID=F934E08738623DF508F108DEF391CFB9:FG=1; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BCLID_BFESS=8512773460870798959; BDSFRCVID_BFESS=5UPOJeC62l07libepqHRKmSPxe5rbsOTH6aoyt6boQjiS8lguPwkEG0PHf8g0Ku-S2EqogKKy2OTH9DF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF_BFESS=tJk8_DPbJK-3fP36q4cBb-4WhmT22-us3g7W2hcH0b61EnR_XRQcbJ8LQ-Qi2lJTMITiaKJjBMb1DbRMLfjN5TODKf-DKb3pWDTm_q5TtUJMeCnTDMRh-l04XNbyKMnitIv9-pPKWhQrh459XP68bTkA5bjZKxtq3mkjbPbDfn028DKuDj-WDjJ0DGRf-b-X-I6b0nRH-njfebRNq4nKbICShG4tLlO9WDTm_DostI3SjJoNKbQ10xPD0n3OK6QHKj79-pPKKR7BfKQPhpQ8MqJbhMJtQnbW3mkjbpnDfn02OPKz0T5pKt4syPR8JfRnWn5RKfA-b4ncjRcTehoM3xI8LNj405OTbIFO0KJzJCcjqR8ZDTuBj55P; __yjs_duid=1_695635cb727c238e28cd4254a28a7a0e1627258379781; BAIDUID_BFESS=F934E08738623DF508F108DEF391CFB9:FG=1; __yjs_st=2_NDRiODllYWQzMjBiMzFhYTlmYWVjZTE4NjFkZTM5MmMwODhlZDE0MjVkYWVmMjIzMzc3MWI2Y2RlOTNkMWJkNDBhNmE2YTIyMTJlZjg0ODJiNzk0NDY2NTYxY2NkOGY5YjM5ODViMDAyZjAwY2E0MThjODUyMGM0N2JiMmEyZGEyMTA4ODdkNjViYjcwNDEwODhjNDkzNDg4YjQyMWNjYTI4ZjAzZDllYTg3YjE3ZDRiYWNlMmJkMzc3YjE1OGU5NWU4NjM3YWQxMjkwNDVkMmMyZTM1YTQ5ODgxNTA4ZjE3MDk2YTYwODg5MmY5ZTZlMmYxZGQ5ZTU1OTdkZGYxZV83X2VhYjhlOWZi; H_PS_PSSID=34300_34100_33969_34272_31254_33848_34282_26350_22158; delPer=0; PSINO=3; BA_HECTOR=002h218g2ka58g0lhq1gftcs10r; ab_sr=1.0.1_ZWRlNDJiMzk0ZWQ3YzZmYzgxMmQzOTIyZDBlN2FjZTIxNjIzODliZWE4MzZjZGEwZTBiMTIzNGRmNDhiYmM2NTJhZjI0ZjBkNTFlMjg4MWYxYmY3ZDMzMGVkNmQ1NTNhMDVkN2I1ZGViMDY2ZjBlNWJmOTk4NTBhZGIwOGU4OTg5YzNiM2QwZjVhMTFkYmQ0ODU2NTJkYzNkZmI0ZjI1MA==; PMS_JT=%28%7B%22s%22%3A1627305057015%2C%22r%22%3A%22https%3A//map.baidu.com/@11606355.22%2C4669275.88%2C5.4z%22%7D%29',
'Referer': 'https://map.baidu.com/search/%E9%B8%BF%E6%98%9F%E5%B0%94%E5%85%8B/@11606355.22,4669275.88,5z?querytype=s&da_src=shareurl&wd=%E9%B8%BF%E6%98%9F%E5%B0%94%E5%85%8B&c=1&src=0&pn=0&sug=0&l=5&b=(6569474.192744261,1360353.0162781863;12256345.744431017,7177600.4441499)&from=webmap&biz_forward=%7B%22scaler%22:1,%22styles%22:%22pl%22%7D&seckey=cde6ebb241c3d75c675c8688828640edba33c570fc006f6ccdee864f2e95d88033fc19e794fee19c2417a6953ba260f3e91efa7e82cbc9c45b5854aec79ce924b08cce22526301f3a8c80710ebb635e73f5eccb560ee1dc38add2dfc793843279646449563fa4547850c144c3838de6fb1efaab7253aa6e99c1de56b4ddbad3905f480e4d46e5414c519465f08bedee98acac8fc7d2f84f413b041287538b09a811ee347b66a4c2c948f2ffa2f6e7674e0c5cb2b6407b610181af9064f870280fd7053482a91caa7cb762068ea41c4bb7bd2f7899f81a2ba5ab3fde28503a6fdc54b0fdee52cc2d02da76e1a4f1b4745&device_ratio=1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4573.0 Safari/537.36'
}
resp = requests.get(url, headers = headers)
if resp.status_code == requests.codes.ok:
print(resp.json())获取相应信息如下:

接下来我们先来获取各个省份和对应的数量,因为咱们国家除了23个省还有直辖市等,所以我们要分步获取
中国共计34个省级行政区,包括23个省、5个自治区、4个直辖市、2个特别行政区。
23个省分别为:河北省、山西省、辽宁省、吉林省、黑龙江省、江苏省、浙江省、安徽省、福建省、江西省、山东省、河南省、湖北省、湖南省、广东省、海南省、四川省、贵州省、云南省、陕西省、甘肃省、青海省、台湾省。
5个自治区分别为:内蒙古自治区、广西壮族自治区、西藏自治区、宁夏回族自治区、新疆维吾尔自治区。
4个直辖市分别为:北京市、天津市、上海市、重庆市。
2个特别行政区分别为:香港特别行政区、澳门特别行政区。
![]()
四个直辖市所在的位置是不同于其它城市的,分布如下:


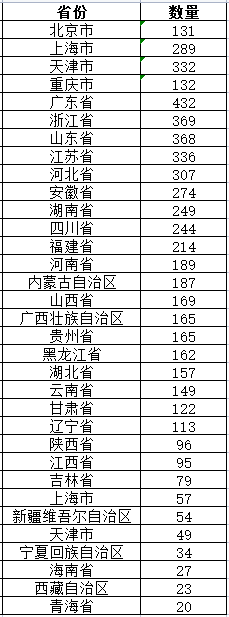
我们将获取到的信息使用熊猫保存在省份的excel中,代码如下:
熊猫教程:
让人无法拒绝的pandas技巧,简单却好用到爆!
prov = []
value = []
# 获取四个直辖市
hot_city = datas.json()['hot_city']
for i in hot_city:
pv = i.split('|')
if '北京市' in pv[0]:
prov.append(pv[0])
value.append(pv[1])
if '上海市' in pv[0]:
prov.append(pv[0])
value.append(pv[1])
if '天津市' in pv[0]:
prov.append(pv[0])
value.append(pv[1])
if '重庆市' in pv[0]:
prov.append(pv[0])
value.append(pv[1])
# 打印出所有省份信息
city_list = datas.json()['more_city']
for item in city_list:
# 获取鸿星尔克所在省份
province = item['province']
prov.append(province)
# 获取鸿星尔克所在省份的数量
prov_num = item['num']
value.append(prov_num)
pd_data = pd.DataFrame({
'省份': prov,
'数量': value,
})
pd_data.to_excel('省份.xlsx')
ic('省份信息打印完成!')excel存储省份数据如下:
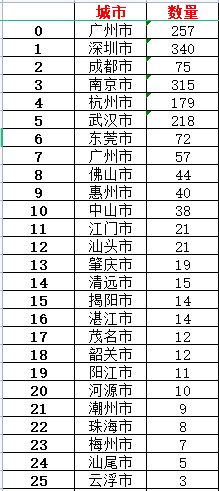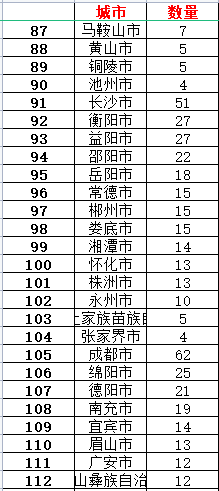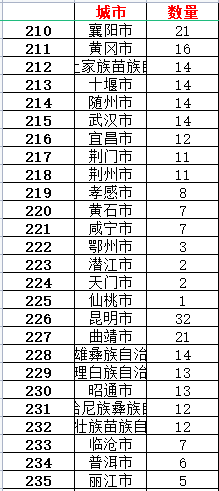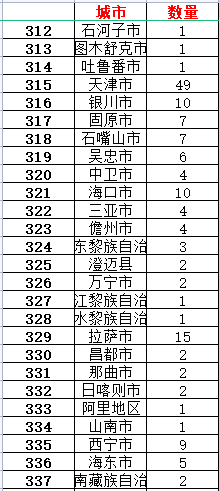
同样的我们可以获取各个省份内具体城市的红鸿星尔克门店数量

所有城市信息包括
热门城市+更多城市 两部分组成
city = []
value = []
# 获取四个直辖市
hot_city = datas.json()['hot_city']
for i in hot_city:
pv = i.split('|')
if '广州市' in pv[0]:
city.append(pv[0])
value.append(pv[1])
if '成都市' in pv[0]:
city.append(pv[0])
value.append(pv[1])
if '南京市' in pv[0]:
city.append(pv[0])
value.append(pv[1])
if '杭州市' in pv[0]:
city.append(pv[0])
value.append(pv[1])
if '武汉市' in pv[0]:
city.append(pv[0])
value.append(pv[1])
if '深圳市' in pv[0]:
city.append(pv[0])
value.append(pv[1])
# 打印出所有城市信息
city_list = datas.json()['more_city']
for item in city_list:
cities = item['city']
for i in cities:
# 获取鸿星尔克所在省份的市区
cit = i['name']
city.append(cit)
# 获取鸿星尔克所在省份的市区对应的数量
city_num = i['num']
value.append(city_num)
pd_data = pd.DataFrame({
'城市': city,
'数量': value,
})
pd_data.to_excel('城市.xlsx')
ic('城市信息打印完成!')excel存储城市数据如下:
我们先要使用熊猫来读取并且清洗数据
主要就是去掉省份后面的'省'字和‘自治区’等
# 读取文件
pd_data = pd.read_excel('省份.xlsx')
prov = pd_data['省份'].tolist()
prov_num = pd_data['数量'].tolist()
name = []
for i in prov:
if "省" in i:
name.append(i.replace('省', ''))
elif '内蒙古自治区' in i:
name.append(i.replace('自治区', ''))
else:
name.append(i[:2])
ic(name)
ic(prov)
'''
2021-07-27 20:50:50.752477|name: ['北京',
'上海',
'天津',
'重庆',
'广东',
'浙江',
'山东',
'江苏',
'河北',
'安徽',
'湖南',
'四川',
'福建',
'河南',
'内蒙古',
'山西',
'广西',
'贵州',
'黑龙江',
'湖北',
'云南',
'甘肃',
'辽宁',
'陕西',
'江西',
'吉林',
'上海',
'新疆',
'天津',
'宁夏',
'海南',
'西藏',
'青海']
2021-07-27 20:50:50.752477|prov: ['北京市',
'上海市',
'天津市',
'重庆市',
'广东省',
'浙江省',
'山东省',
'江苏省',
'河北省',
'安徽省',
'湖南省',
'四川省',
'福建省',
'河南省',
'内蒙古自治区',
'山西省',
'广西壮族自治区',
'贵州省',
'黑龙江省',
'湖北省',
'云南省',
'甘肃省',
'辽宁省',
'陕西省',
'江西省',
'吉林省',
'上海市',
'新疆维吾尔自治区',
'天津市',
'宁夏回族自治区',
'海南省',
'西藏自治区',
'青海省']
'''
接下来我们使用pyecharts来可视化我们清洗过后的数据
map = (
Map()
.add("数量分布", [list(z) for z in zip(prov, prov_num)], "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="鸿星尔克全国门店分布图"),
visualmap_opts=opts.VisualMapOpts(max_=500, is_piecewise=True),
)
)
map.render('省份.shtml')
ic('省份分布图绘制完毕!')效果图如下:
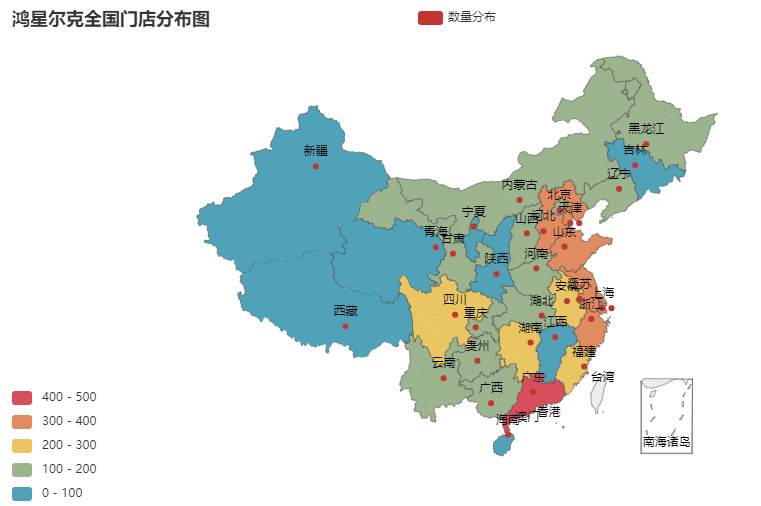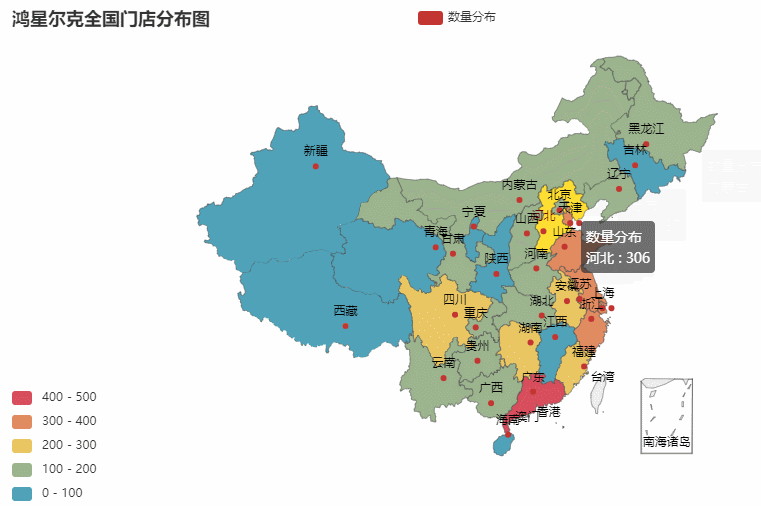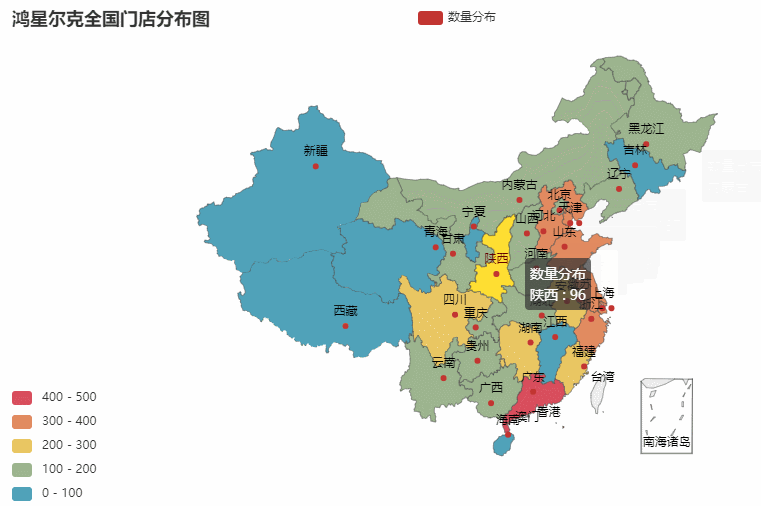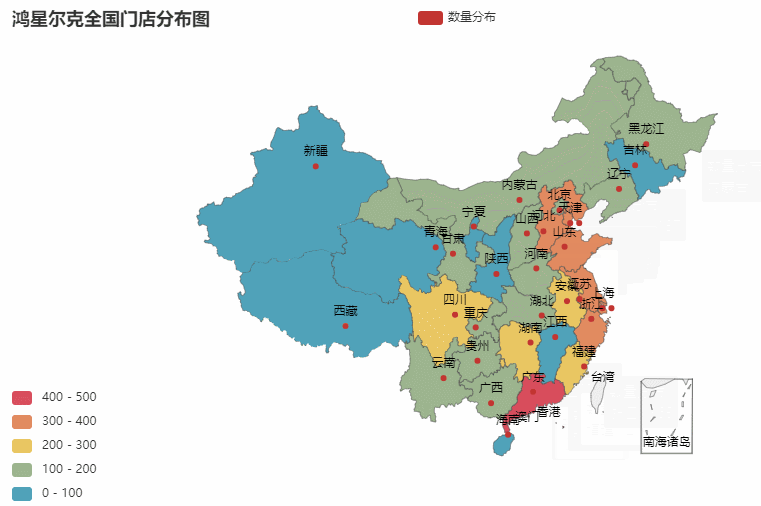
省份所在的各个城市图也是同理。我们就以门店最多的广东作为案例,你也可以选择任意省份哈
抓取数据->存储数据->处理数据->可视化数据
最终效果如下:
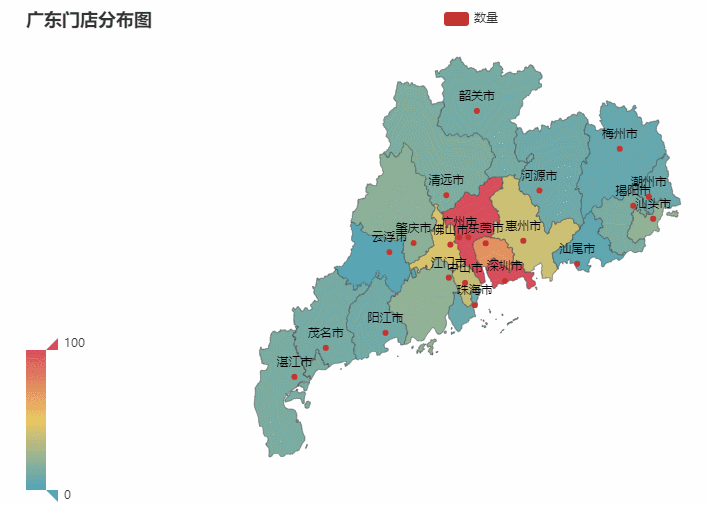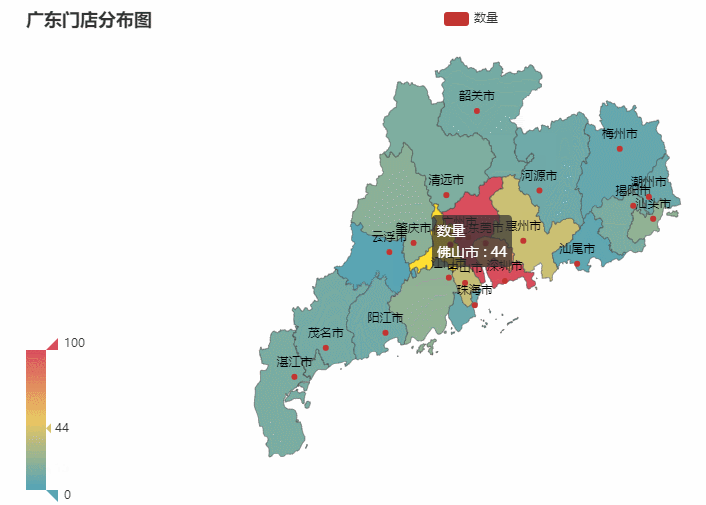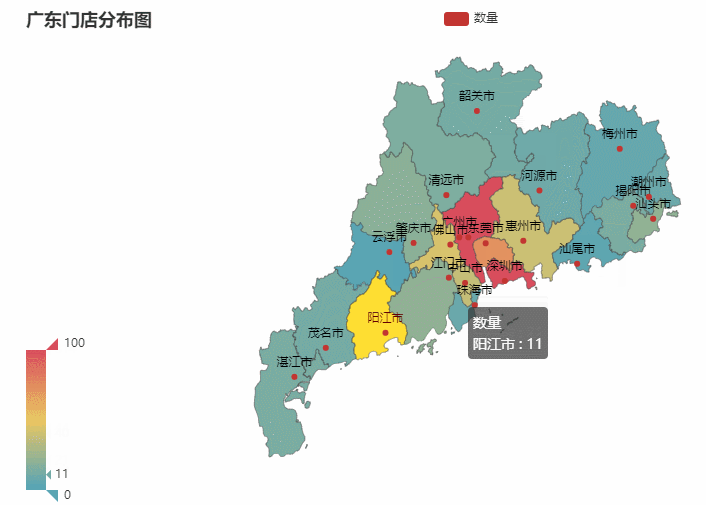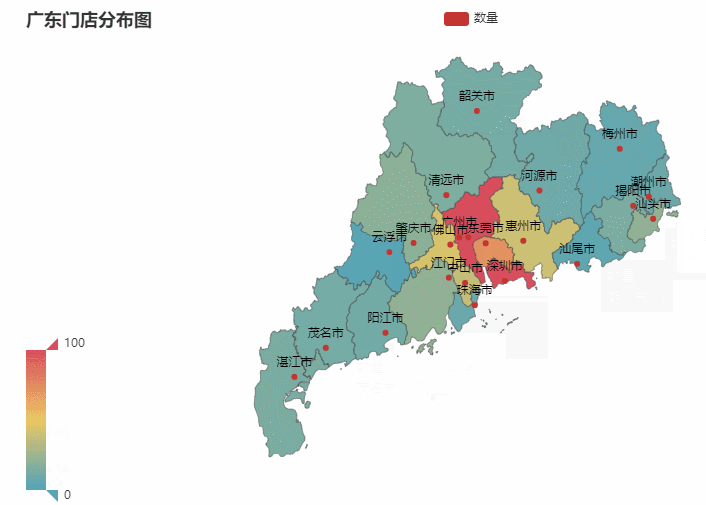
数据可视化之后一目了然,比起看excel更加赏心悦目。并且事半功倍。