小白也能轻松上手selenium,无忧获取淘宝商品信息,献给手把手教的会的你
目录
- 前言
- 准备工作
-
-
- 系统要求
- 集成开发环境下载
- 配置开发环境
-
- 分析网站
-
- 首先进入的是淘宝首页
- 接着显示的是登录页面
- 登录后进入搜索结果页
- 编写程序
-
- 先做基本的配置
-
- 数据文件
- 浏览器配置
- 特殊字符去除函数
- 模拟搜索——第一个页面的操作
- 模拟登录——第二个页面的操作
-
- 短信登录
- 淘宝软件扫码登录
- 循环数据采集——商品页面的操作
- 后记
前言
快双十一了,大家一定有自己喜欢的商品想要趁机收入囊中,淘宝在10月20号就开启了预售,但低估了大家的爆发力,服务器一度崩溃,因此上了头条。接下来,我就要手把手教大家用python代码获取想要的商品的数据。
我采集的数据格式是这样的,选取标题,价格,商家名称,付款人数和地区坐标做了采集。具体的需求具体分析,大家有什么别的需要采集的,学完这篇文章,自然就会修改了

项目仓库地址是 https://codechina.csdn.net/sabian2/seleniumtotaobao.git
公开的项目,在安装git的电脑上使用以下命令即可下载到本地计算机
git clone https://codechina.csdn.net/sabian2/seleniumtotaobao.git
准备工作
系统要求
首先声明,这次程序完全在windows下运行,Windows7,Windows10都可以。
运行这段程序,先要有Python环境和python的编译器,这里的python版本是python3.7,编译器是pycharm2019,做selenium用的谷歌浏览器,驱动也是相应的版本。
集成开发环境下载
这些工具都已经打包好了,下载地址CSDN本地下载,一开始2天可能审核中;百度网盘提取码:kc97
取得这些工具后,依次安装好python和pycharm、谷歌浏览器,
如果谷歌浏览器打开后自动更新到了更新的版本,请访问此链接下载对应版本的驱动
配置开发环境
打开pycharm新建一个工程,环境选择Virtualenv
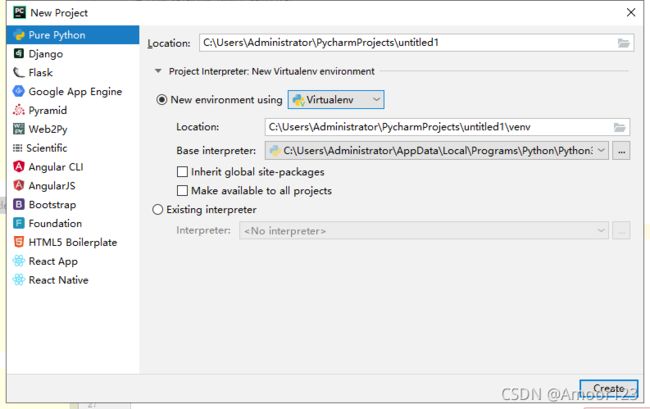
创建项目后,需要把浏览器驱动拷贝到python.exe同目录,没有驱动会报错

位置在左侧项目目录下的External Libraries下面,找一个文件夹show in explorer

在这个位置,将那个浏览器驱动压缩包解压好的exe文件放进去
打开我的电脑,全局搜索chrome.exe,找到并打开位置,把驱动文件也给那个文件夹复制一份
在pycharm的terminal中输入以下命令安装指定版本的selenium,最新的4.00版本已经不太适合3.7了,直接安装selenium可能会报错。
pip install selenium==3.141.0
安装好selenium库后,准备工作至此就已经万事俱备,等东风起了。
分析网站
首先进入的是淘宝首页
这一页上的动作目标是在搜索框输入自己要搜索的商品名称,然后单击搜索
我们完成这两个动作
接着显示的是登录页面

这一页上的动作目标是让我们能够登录进去,有5个方向,分别是:
1.密码登陆,动作步骤是在两个输入框输入用户名和密码,点击登录
2.短信登陆,动作步骤是点击短信登陆,在第一个框输入手机号,在第二个框点击获取验证码,然后等拿到验证码后输入验证码,点击登录

3.微博登录,动作步骤是点击微博登录,在新的页面上输入账号和密码,点击登录

4.支付宝登录,动作步骤是点击支付宝登录,支付宝扫码即可
5.淘宝手机软件扫码登录,动作步骤是点击登录框右上角的二维码,用相应软件扫码即可
登录后进入搜索结果页


页面前面的部分是分类,下面一个一个格子的是商品信息,商品底部有个页码栏目,可以点击下一页或者确定前往下一页

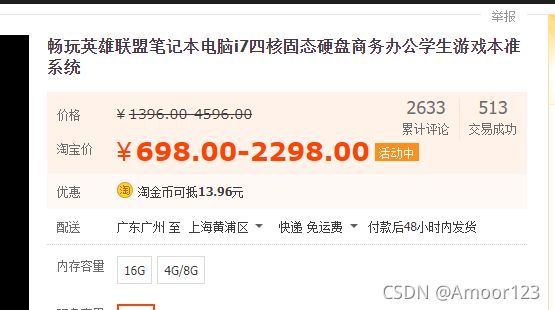
每个商品格子里面的价格,付款数,标题,商店名,地址坐标就是本次程序需要获取的,如果还想要获取更多具体的信息,可以进入商品页
此处可以获取评论信息

如果想获取交易成功率,可以提取这个信息
在网页源代码中还有属性显示30天内交易的数量和交易成功数

但这个东西不同的商家页面也不一样,需要做更多的分析才能做自动化程序
此次我们的数据采集目标是提取商品的标题、发货地、价格、店铺名、付款人数这5种信息,全部可以从搜索结果页提取
编写程序
先做基本的配置
处理数据保存和浏览器配置的问题
新建一个python文件
数据文件
建一个taobaoshuju.csv文件,以gbk编码追加方式写,w是写入的画笔,先写了一行标题
import codecs
import csv
f = codecs.open('taobaoshuju.csv','a','gbk')
w = csv.writer(f)
w.writerow(["Id",'标题','价格','商家','坐标','付款人数'])
浏览器配置
这个配置主要是屏蔽自动化测试的提示信息和相关环境变量,减少被对方服务器检测到使用了selenium的可能
### 做一些配置
options=webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 启动一个浏览器对象
browser = webdriver.Chrome(options=options)
#这里屏蔽检测
browser.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
特殊字符去除函数
虽然是写入csv文件,不是作为文件名,字符要求没这么高,但是有些字符写不进去,需要提前去除,标题和商店名都有可能遇到,在自己调试的过程中遇到停下的地方就看看是哪个字符引发的,把它加入punctuation 中排除
def validateTitle(title):
punctuation = '!,;:?"\'、,;“ ” 《 》【】? + * & / ™'
new_title = re.sub(r'[{}]+'.format(punctuation), '', title)
return new_title.strip()
模拟搜索——第一个页面的操作
用浏览器打开网站页面,在搜索框右键-》检查-》在源代码中相应位置右键-》Copy-》Copy XPath或者Copy Full XPath,即可获得这个输入框的xpath,后续的其他位置XPath也是照此法动作,不再赘述。

推荐大家安装xpath插件,可以比对是不是拿到了正确的路径,另外自己找xpath的阶段不必去Chrome中找,Google现在的插件商店可不好进去。推荐大家使用双核浏览器,可以直接搜索下载扩展。
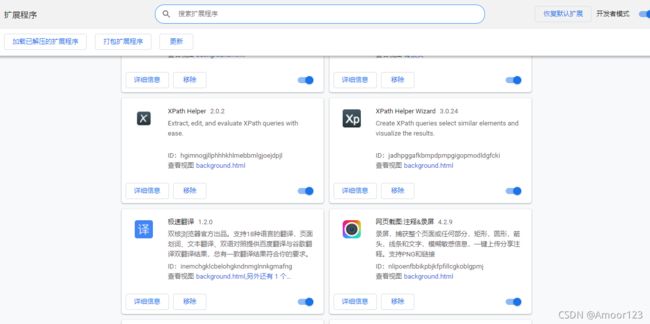
我用的是左边的xpath插件进行提取,查询结果位置会显示紫色高亮

首页上的步骤模拟代码如下
browser.get('https://www.taobao.com/')
#获得搜索框
xx=browser.find_element_by_xpath('//*[@id="q"]')
xx.send_keys('笔记本电脑')
#获得搜索按钮
search=browser.find_element_by_xpath('//*[@id="J_TSearchForm"]/div[1]/button')
search.click()
browser.get:打开了个页面
browser.find_element_by_xpath:通过xpath获取页面的元素
send_keys:往输入框输入文字
search.click():模拟点击
模拟登录——第二个页面的操作
这里演示两种登录方式,短信登录和淘宝软件扫码登录
短信登录
短信登录中间做了用户输入等待,待用户在pycharm中输入收到的短信后,再进行登录按钮的点击,短信登录一天有次数限制,测试过多就会被淘宝禁用
# 从密码登录切换到短信登录
duanxindenglu=browser.find_element_by_xpath('//*[@id="login"]/div[2]/div/div[1]/a[2]')
duanxindenglu.click()
# 手机号输入框
shoujihao=browser.find_element_by_xpath('//*[@id="fm-sms-login-id"]')
shoujihao.send_keys('18238484848')
# 获取验证码
huoquyanzhengma=browser.find_element_by_xpath('//*[@id="login-form"]/div[2]/div[3]/a')
huoquyanzhengma.click()
# 输入验证码
yanzhengma=browser.find_element_by_xpath('//*[@id="fm-smscode"]')
yanzheng=input('请输入验证')
yanzhengma.send_keys(yanzheng)
# 点击登录
dl=browser.find_element_by_xpath('//*[@id="login-form"]/div[5]/button')
dl.click()
淘宝软件扫码登录
这是个很简单的登录方式,只需要用户打开软件扫一下确认就可以了,基本上没有触发次数限制,因为需要等待扫码,所以休眠一段时间来暂停程序
#获取的右上角的扫码登录按钮
saomadenglu=browser.find_element_by_xpath('//*[@id="login"]/div[1]/i')
saomadenglu.click()
import time
time.sleep(12)
循环数据采集——商品页面的操作
提取的是每一个商品格子里的几个信息,同样是拷贝xpath过来,动态变化的位置参数可以通过比对不同的格子数据提取出来,作为循环变量,这里一共提取500条数据。
内部的异常捕获是为了让程序不间断,可以根据自身电脑的运行速度,网速调整休眠的时间。
我这休眠时间决定了一分钟大约获取4页的数据,你们可以试着快一些
# 这个变量是为了计量获取的数据量,500以上就停止
count=0
# 这个变量是为了计量在第几页了
index=0
while count <500:
index+=1
print(f'-----------开始处理第{
index}页数据------------')
#第一页的搜索 结果是48条,后面都是44条,这里没有把这个值变化获取,而是取了个较大值,也可以通过获取相关页面元素的数量来动态变化
for i in range(1,49):
# try是为了不存在的数据做跳出
try:
price=browser.find_element_by_xpath(f'//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[{
i}]/div[2]/div[1]/div[1]/strong').text
amount=browser.find_element_by_xpath(f'//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[{
i}]/div[2]/div[1]/div[2]').text
location=browser.find_element_by_xpath(f'//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[{
i}]/div[2]/div[3]/div[2]').text
shangjia=browser.find_element_by_xpath(f'//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[{
i}]/div[2]/div[3]/div[1]/a/span[2]').text
title=browser.find_element_by_xpath(f'/html/body/div[1]/div[2]/div[3]/div[1]/div[21]/div/div/div[1]/div[{
i}]/div[2]/div[2]/a').text
amount=amount.split('人')[0]
title=validateTitle(title)
if location=='':
location='官方直营'
#写入文件
if all((price,amount,shangjia,title)):
w.writerow([count+1,title,price,shangjia,location,amount])
count+=1
except:
print(f'————————第{
index}页第{
i}个数据获取出现错误,可能不存在---------')
continue
#下一页,点击的是页面底部的【确定】按钮
xiayiye=browser.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/div[2]/span[3]')
xiayiye.click()
# 休眠是为了更好的载入数据
time.sleep(15)
如果需要获取大量的信息,可以放开数据量的循环条件,做成死循环,在商品结果页的分类栏里先进行筛选和排序也是提高自己数据指向性的好方法。

后面页面的数据只有几十乃至个位数的销量了,作为商品对比的话,意义已经很小了。很少有人会去一共只出货了几台电脑的店吧

死循环后网页在100页以后就没下一页了,这应该是服务器设置好的

后记
本教程到这里就结束了,如果你有什么疑问和建议,欢迎大家在下面留言,期待您的一键三连!