数字语音处理期末报告——音频信号编码与转换(MATLAB线性预测和抽样量化编码)
目录
-
- 一.实验目的
- 二.指标要求
- 三.实验步骤
- 1. 声源录音
- 2. 对声源(男声)进行预处理
- 3. 对经过预处理的声音信号进行变声处理
- 4. 对经过变声以后的序列进行PCM编码
- 5. 对接收到的比特序列进行PCM译码
- 四.实验原理
- 1.LPC分析
-
- (1)基本思想:
- (2)语音信号的LPC分析
- 2. PCM编译码
-
- (1)抽样信号的量化原理
- (2)脉冲编码调制的基本原理
- 五.实验结果
- 六.实验分析
一.实验目的
实现发送端记录声音信号,经过有限带宽信道(假设无噪)后,在接收端恢复出声音信号并变换性别。
二.指标要求
1.发送端录音长度不短于 4 秒;
2.比特率限制为 64kbps(注意是 bit per second);
3.变换后的声音尽量自然清晰。
三.实验步骤
1. 声源录音

通过Microsoft Word2019中的朗读功能进行播放男声和女声语句,同时进行录音分别得到音频信号fe.m4a和ma.m4a。
2. 对声源(男声)进行预处理
将输入的男声信号ma.m4a进行裁剪降采样,使得其与系统存放的女声序列fe.m4a在时域上基本保持一致,而后对序列进行降采样,原序列采样率为48kHz,通过等间距地抽取采样点的方法对原序列进行降采样,最终得到与处理后的结果为female.wav和male.wav。(在代码中对男女声音信号同时进行了预处理,附件中pre_process.m为预处理脚本)
3. 对经过预处理的声音信号进行变声处理
通过对预处理后的男声信号进行LPC分析,逐帧提取出其LPC系数A1(n),并且得到激励源e1(n),通过将男声的LPC系数与女声之激励源e2(n)合成得到变声处理以后的音频序列,输出音频synthesised_m2f.wav。(附件中synlpc.m为LPC分析提取系数和激励源的函数,synlpc2.m为合成音频函数)
4. 对经过变声以后的序列进行PCM编码
通过A律13折线法对变声处理后的音频信号进行编码,每个采样点编码为1byte(8bit:1位符号码,3位段落码,4位段内码),并将得到的编码存放于code.mat文件中。(PCMdecoding.m为编码函数)
5. 对接收到的比特序列进行PCM译码
加载code.mat文件,通过A律13折线法对接收到的编码序列进行译码得到传输新的音频序列,输出音频信号transmitted_m2f.wav。(PCMencoding.m为译码函数)
四.实验原理
1.LPC分析
(1)基本思想:
利用信号间相关性,用过去值预测现在或未来的值,即用过去若干个取样值的线性组合逼近一个取样值。在某种测度准则下,通过使实际的取样值与预测值之间的差别达最小,确定唯一的一组预测系数。LPC的基本原理和语音信号数字模型密切相关。
(2)语音信号的LPC分析
语音序列为缓变的随机序列,可近似用信号模型化方法分析。
信号模型化的思想建立的语音信号的产生模型。
将辐射、声道、声门激励的谱效应简化为时变数字滤波器,其稳态系统函数为:
H ( z ) = X ( z ) U ( z ) = G 1 − ∑ i = 1 p a i z − i H\left(z\right)=\frac{X\left(z\right)}{U\left(z\right)}=\frac{G}{1-\sum_{i=1}^{p}{a_iz^{-i}}} H(z)=U(z)X(z)=1−∑i=1paiz−iG
语音信号x(n)被模型化为一个过程序列。浊音激励为准周期冲激序列,清音激励为白噪声序列。H(z)称为合成滤波器。模型参数:浊/清音判决、基音周期、增益常数G、数字滤波器参数a1,a2,…,ap。
求解滤波器参数和增益常数的过程称为语音信号的LPC分析。基本问题是从语音信号序列确定一组LPC系数。预测系数的估计须在一短段(帧)语音信号的范围内进行。
激励源问题:
清音:用模型合成语音时,产生的序列与和被分析序列有相同的谱包络特性。
浊音:激励源 u(n) 的谱是一组幅度相同的谐波线谱,与模型化中的信号源假设有所不同。但激励源 u(n) 的大部分时间的值非常小(零值),由于方均预测误差最小准则使预测误差e(n)逼近于u(n),与u(n)能量很小这一事实并不矛盾。因此,为不使问题复杂化,认为模型适于清音、浊音。
2. PCM编译码
(1)抽样信号的量化原理
模拟信号抽样后变成在时间离散的信号后,必须经过量化才成为数字信号。模拟信号的量化分为均匀量化和非均匀量化两种。把输入模拟信号的取值域按等距离分割的量化称为均匀量化,每个量化区域的量化电平均取在各个区间的中点。
均匀量化的主要缺点是无论抽样值大小如何,量化噪声的均方根值都固定不变,因此,当信号m(t)较小时,则信号量化噪声功率比也很小。这样,对于弱信号时的量化信噪比就难以达到给定的要求。通常把满足信噪比要求的输入信号取值范围定义为动态范围,那么均匀量化时的信号动态范围将受到较大的限制。为了克服这个缺点,实际中往往采用非均匀量化的方法。
非均匀量化是分局信号的不同区间来确定量化间隔的。对于信号取值小的区间,其量化间隔Dv也小;反之量化间隔就大。非均匀量化与均匀量化相比,有两个突出的优点:首先,当输入量化器的信号具有非均匀分布的概率密度(实际中往往是这样)时,非均匀量化器的输出端可以得到较高的平均信号量噪比;其次,非均匀量化时,量化噪声功率的均方根值基本上与信号抽样值成比例,因此量化噪声对大、小信号的影响大致相同,即盖上了小信号时的信噪比。
非均匀量化在实际过程通常是将抽样值压缩后在进行均匀量化。现在广泛采用两种对数压缩,美国采用μ压缩律,我国和欧洲各国均采用A压缩律。本实验中PCM编码方式也是采用A压缩律。
(2)脉冲编码调制的基本原理
量化后的信号时取值离散的数字信号,下一步是将这个信号编码。通常把从模拟信号抽样、量化、编码变换成为二进制符号的基本过程,成为脉冲编码调制(Pulse Code Modulation,PCM)。
在13折线法中,无论输入信号是正是负,均采用8位折叠二进制码来表示输入信号的抽样量化值。其中,用第一位表示量化值的极性,其余七位(第二位至第八位)则表示抽样量化值的绝对大小。具体做法是:用第二至第四位表示段落码,它的8种可能状态来分别表示8个段落的起点电平。其它四位表示段内码,它的16种可能状态分别代表每一段落的16和均匀划分的量化级。这样处理的结果,使8个段落被划分成27=128个量化级。上述编码方法是把压缩、量化和编码合为一体的方法。
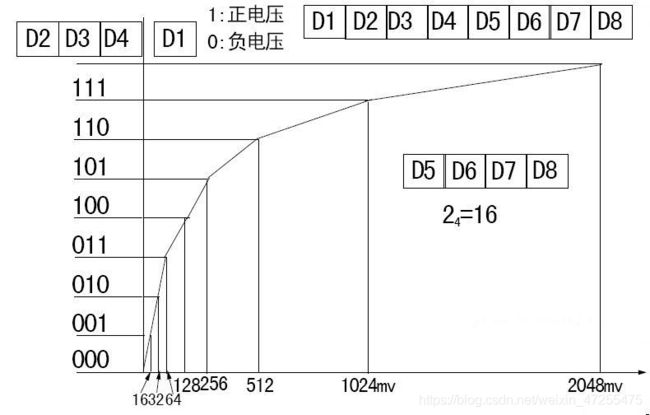
图 1 A律13折线法
五.实验结果
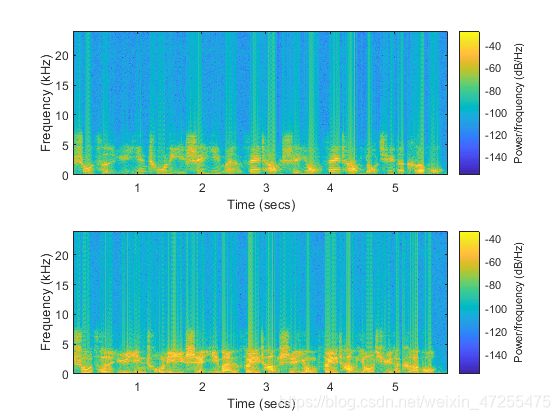
图 2 预处理后的女声和男声音谱图
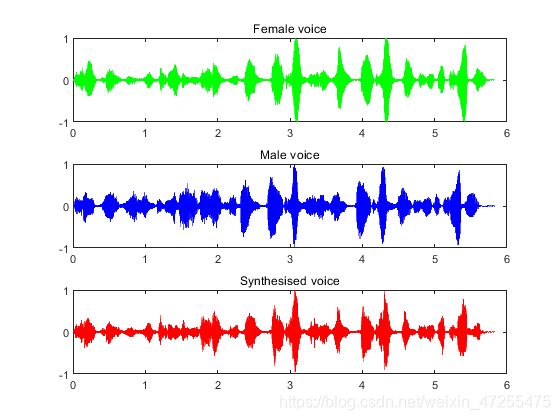
图 3 女声信号、男声信号和合成信号时域图像
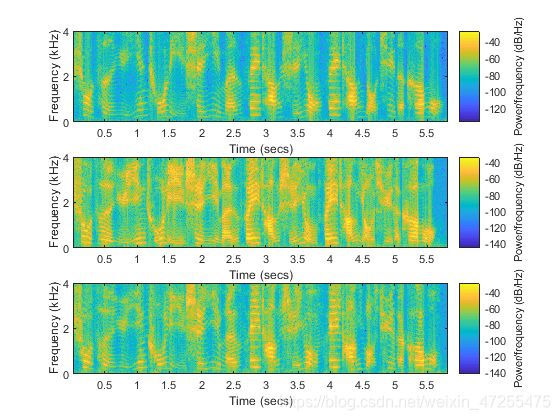
图 4 女声信号、男声信号和合成信号频域图像
由上图可见,合成后的信号无论是在时域还是在频域都更加接近女声信号,因此,男声信号变换为女声信号的要求实现。

图 5 PCM编解码前后音频信号的对比
由上图可见PCM编解码前后信号基本保持不变,少许不同是由于PCM编码自带的量化噪声造成,通过收听译码后的音频信号,信号质量良好噪音较小。
六.实验分析
通过计算编码前后的信噪比,为33.3874dB,说明该PCM编译码有较好的效果。经过计算总比特数为373120 bit,音频信号时长为5.83 s,比特率为64 kbps,满足题设要求,在此也很好理解,当采样率降为8kHz时,每秒有8000个采样点,每个采样点1byte(8bit),即为每秒64kbit。
存在的问题:在降采样时,男声信号质量变化较小,但是女声信号变化较大,在降采样以后有明显的的噪声,并且因此伴随着之后的合成音频和传输后音频都有明显的噪声。
经过分析得出的结论是女声信号有较多的高频分量,在用8kHz的采样率采样时会有比男声更多的混叠失真。
需要代码的同学点击这里。