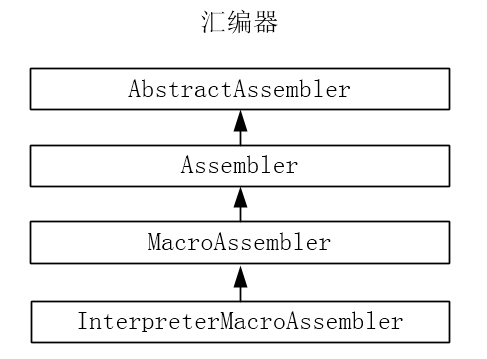
汇编器的继承体系如下:
为解析器提供的相关汇编接口,所以每个字节码指令都会关联一个生成器函数,而生成器函数会调用汇编器生成机器指令片段,例如为iload字节码指令生成例程时,调用的生成函数为TemplateTable::iload(int n),此函数的实现如下:
源代码位置:hotspot/src/cpu/x86/vm/templateTable_x86_64.cpp
void TemplateTable::iload() {
transition(vtos, itos);
...
// Get the local value into tos
locals_index(rbx);
__ movl(rax, iaddress(rbx)); // iaddress(rb)为源操作数,rax为目地操作数
}
函数调用了__ movl(rax,iaddress(rbx))函数生成对应的机器指令,所生成的机器指令为mov reg,operand,其中__为宏,定义如下:
源代码位置:hotspot/src/cpu/x86/vm/templateTable_x86_64.cpp #define __ _masm->
_masm变量的定义如下:
源代码位置:hotspot/src/share/vm/interpreter/abstractInterpreter.hpp
class AbstractInterpreterGenerator: public StackObj {
protected:
InterpreterMacroAssembler* _masm;
...
}
最终_masm会被实例化为InterprterMacroAssembler类型。
在x86的64位平台上调用movl()函数的实现如下:
源代码位置:hotspot/src/cpu/x86/vm/assembler_86.cpp
void Assembler::movl(Register dst, Address src) {
InstructionMark im(this);
prefix(src, dst);
emit_int8((unsigned char)0x8B);
emit_operand(dst, src);
}
调用prefix()、emit_int8()等定义在汇编器中的函数时,这些函数会通过AbstractAssembler::_code_section属性向InterpreterCodelet实例中写入机器指令,这个内容在之前已经介绍过,这里不再介绍。
1、AbstractAssembler类
AbstractAssembler类中定义了生成汇编代码的抽象公共基础函数,如获取关联CodeBuffer的当前内存位置的pc()函数,将机器指令全部刷新到InterpreterCodelet实例中的flush()函数,绑定跳转标签的bind()函数等。AbstractAssembler类的定义如下:
源代码位置:hotspot/src/share/vm/asm/assembler.hpp
// The Abstract Assembler: Pure assembler doing NO optimizations on the
// instruction level; i.e., what you write is what you get.
// The Assembler is generating code into a CodeBuffer.
class AbstractAssembler : public ResourceObj {
friend class Label;
protected:
CodeSection* _code_section; // section within the code buffer
OopRecorder* _oop_recorder; // support for relocInfo::oop_type
...
void emit_int8(int8_t x) {
code_section()->emit_int8(x);
}
void emit_int16(int16_t x) {
code_section()->emit_int16(x);
}
void emit_int32(int32_t x) {
code_section()->emit_int32(x);
}
void emit_int64(int64_t x) {
code_section()->emit_int64(x);
}
void emit_float( jfloat x) {
code_section()->emit_float(x);
}
void emit_double( jdouble x) {
code_section()->emit_double(x);
}
void emit_address(address x) {
code_section()->emit_address(x);
}
...
}
汇编器会生成机器指令序列,并且将生成的指令序列存储到缓存中,而_code_begin指向缓存区首地址,_code_pos指向缓存区的当前可写入的位置。
这个汇编器提供了写机器指令的基础函数,通过这些函数可方便地写入8位、16位、32位和64位等的数据或指令。这个汇编器中处理的业务不会依赖于特定平台。
2、Assembler类
assembler.hpp文件中除定义AbstractAssembler类外,还定义了jmp跳转指令用到的标签Lable类,调用bind()函数后就会将当前Lable实例绑定到指令流中一个特定的位置,比如jmp指令接收Lable参数,就会跳转到对应的位置处开始执行,可用于实现循环或者条件判断等控制流操作。
Assembler的定义跟CPU架构有关,通过assembler.hpp文件中的宏包含特定CPU下的Assembler实现,如下:
源代码位置:hotspot/src/share/vm/asm/assembler.hpp #ifdef TARGET_ARCH_x86 # include "assembler_x86.hpp" #endif
Assembler类添加了特定于CPU架构的指令实现和指令操作相关的枚举。 定义如下:
源代码位置:hotspot/src/cpu/x86/vm/assembler_x86.hpp
// The Intel x86/Amd64 Assembler: Pure assembler doing NO optimizations on the instruction
// level (e.g. mov rax, 0 is not translated into xor rax, rax!); i.e., what you write
// is what you get. The Assembler is generating code into a CodeBuffer.
class Assembler : public AbstractAssembler {
...
}
提供的许多函数基本是对单个机器指令的实现,例如某个movl()函数的实现如下:
void Assembler::movl(Register dst, Address src) {
InstructionMark im(this);
prefix(src, dst);
emit_int8((unsigned char)0x8B);
emit_operand(dst, src);
}
subq()函数的实现如下:
void Assembler::subq(Register dst, int32_t imm32) {
(void) prefixq_and_encode(dst->encoding());
emit_arith(0x81, 0xE8, dst, imm32);
}
如上函数将会调用emit_arith()函数,如下:
void Assembler::emit_arith(int op1, int op2, Register dst, int32_t imm32) {
assert(isByte(op1) && isByte(op2), "wrong opcode");
assert((op1 & 0x01) == 1, "should be 32bit operation");
assert((op1 & 0x02) == 0, "sign-extension bit should not be set");
if (is8bit(imm32)) {
emit_int8(op1 | 0x02); // set sign bit
emit_int8(op2 | encode(dst));
emit_int8(imm32 & 0xFF);
} else {
emit_int8(op1);
emit_int8(op2 | encode(dst));
emit_int32(imm32);
}
}
调用emit_int8()或emit_int32()等函数写入机器指令。最后写入的指令如下:
83 EC 08
由于8可由8位有符号数表示,第一个字节为0x81 | 0x02,即0x83,rsp的寄存器号为4,第二个字节为0xE8 | 0x04,即0xEC,第三个字节为0x08 & 0xFF,即0x08,该指令即AT&T风格的sub $0x8,%rsp。
我在这里并不会详细解读汇编器中emit_arith()等函数的实现逻辑,这些函数如果在不理解机器指令编码的情况下很难理解其实现过程。后面我们根据Intel手册介绍了机器指令编码格式后会选几个典型的实现进行解读。
3、MacroAssembler类
MacroAssembler类继承自Assembler类,主要是添加了一些常用的汇编指令支持。类的定义如下:
源代码位置:hotspot/src/cpu/x86/vm/macroAssembler_x86.hpp
// MacroAssembler extends Assembler by frequently used macros.
//
// Instructions for which a 'better' code sequence exists depending
// on arguments should also go in here.
class MacroAssembler: public Assembler {
...
}
这个类中的函数通过调用MacroAssembler类或Assembler类中定义的一些函数来完成,可以看作是通过对机器指令的组合来完成一些便于业务代码操作的函数。
根据一些方法传递的参数可知,能够支持JVM内部数据类型级别的操作。
例如机器指令在做加法操作时,不允许两个操作数同时都是存储器操作数,或者一个来自内存,另外一个来自立即数,但是MacroAssembler汇编器中却提供了这样的函数。
4、InterpreterMacroAssembler类
在templateTable.hpp文件中已经根据平台判断要引入的文件了,如下:
#ifdef TARGET_ARCH_x86 # include "interp_masm_x86.hpp" #endif
在interp_masm_x86.hpp文件中定义了InterpreterMacroAssembler类,如下:
源代码位置:hotspot/src/cpu/x86/vm/interp_masm_x86.hpp
// This file specializes the assember with interpreter-specific macros
class InterpreterMacroAssembler: public MacroAssembler {
...
#ifdef TARGET_ARCH_MODEL_x86_64
# include "interp_masm_x86_64.hpp"
#endif
...
}
对于64位平台来说,引入了interp_masm_x86_64.hpp文件。
在interp_masm_x86_64.cpp文件中定义了如下几个函数:
(1)InterpreterMacroAssembler::lock_object()
(2)InterpreterMacroAssembler::unlock_object()
(3)InterpreterMacroAssembler::remove_activation()
(4)InterpreterMacroAssembler::dispatch_next()
其中的dispatch_next()函数大家应该不陌生,这个函数在之前介绍过,是为分发字节码指令生成例程;lock_object()和unlock_object()是在解释执行的情况下,为加载和释放锁操作生成对应的例程,在后面介绍锁相关的知识时会详细介绍;remove_activation()函数表示移除对应的栈帧,例如在遇到异常时,如果当前的方法不能处理此异常,那就需要对栈进行破坏性展开,在展开过程中需要移除对应的栈帧。
推荐阅读:
第1篇-关于JVM运行时,开篇说的简单些
第2篇-JVM虚拟机这样来调用Java主类的main()方法
第3篇-CallStub新栈帧的创建
第4篇-JVM终于开始调用Java主类的main()方法啦
第5篇-调用Java方法后弹出栈帧及处理返回结果
第6篇-Java方法新栈帧的创建
第7篇-为Java方法创建栈帧
第8篇-dispatch_next()函数分派字节码
第9篇-字节码指令的定义
第10篇-初始化模板表
第11篇-认识Stub与StubQueue
第12篇-认识CodeletMark
第13篇-通过InterpreterCodelet存储机器指令片段
第14篇-生成重要的例程
第15章-解释器及解释器生成器
如果有问题可直接评论留言或加作者微信mazhimazh
关注公众号,有HotSpot VM源码剖析系列文章!
