Python—— 文件和数据格式化(模块6: wordcloud库的使用)(实例:自动轨迹绘制&政府工作报告词云)
前言
本篇主要介绍文件和数据格式化,以自动轨迹绘制为例,介绍自动化的程序设计方法。以政府工作报告词云为例,介绍wordcloud库的使用。
数据格式化:将一组数据按照一定规格和式样进行规范:表示、存储、运算等
读完本篇,你将了解:
1.方法论:
从Python角度理解的文件和数据表示
2.实践能力:
学会编写带有文件输入输出的程序,并且能够实践对数据的表示和操作
本篇将系统介绍:
1.文件的使用(对文件的读、写等操作的相关能力)
2.实例11:自动轨迹绘制(了解自动化的程序设计方法)
3.一维数据的格式化和处理(介绍数据组织的维度、一维数据的存储、处理等)
4.二维数据的格式化和处理(介绍CSV数据存储格式)
5.模块6: wordcloud库的使用(基本介绍+使用说明+用例)
6.实例12:政府工作报告词云(基本分析+代码实现+改进版五角星词云)
一、文件的使用
1.文件的类型
(1)文件
文件是数据的抽象和集合
①文件是存储在辅助存储器上的数据序列
②文件是数据存储的一种形式
③文件展现形态:文本文件和二进制文件
(2)文本文件vs.二进制文件
①文件文件和二进制文件只是文件的展示方式
②本质上,所有文件都是二进制形式存储
③形式上,所有文件采用两种方式展示
(3)文本文件
①由单一特定编码组成的文件,如UTF-8编码
②由于存在编码,也被看成是存储着的长字符串
③适用于例如∶.txt文件、.py文件
(4)二进制文件
①直接由比特0和1组成,没有统一字符编码般
②存在二进制0和1的组织结构,即文件格式
③适用于例如: .png文件、.avi文件等
注意:无论什么类型的文件都可以用二进制形式打开
(5)使用情况
①文本文件需要对它里边的字符进行理解,以文本形式打开
②仅仅需要使用它的存储形态,以二进制打开
2.文件的打开和关闭
(1)文件处理的步骤:打开-操作-关闭

①存储状态:此时文件在计算机的硬盘中存储
②占用状态:一个程序可以唯一的、排它的对文件进行相关处理
③打开之后可进行,数据读入和数据输出,简称为读文件和写文件
④3个常用读文件函数:
a.read( size)
a.readline(size)
a.readlines(hint)
⑤3个常用写文件函数:
a.write(s)
a.writelines ( lines)
a.seek(offset)
(2)文件的打开
1)<变量名> = open(<文件名>,<打开模式>)
①第一个参数:文件路径和名称,指当前要打开的文件与当前程序所对应的位置之间的关系
②第二个参数:文本 or 二进制形式打开,读信息还是写信息
③打开之后用一个抽象变量——文件句柄表示
2)文件路径
①文件路径和名称可以是文件绝对路径和名称
②举例:某文件在Windows平台上存储于保存在D盘PYE目录下,文件名称为f.txt
打开文件时需要指定路径
1)直接给出路径
注意:在Windows下,文件的路径使用的是\方式,但在Python中表示转义符
所以写成:“D:/ PYE/f.txt"或"D:\PYE\f.txt"
2)相对路径:打开文件与当前程序之间的路径
指定目录为./PYE/f.txt,指从可执行程序的当前目录起找它的PYE目录,以及这个目录下的f.txt文件
若二者在相同目录里,直接吏用文件名称f.txt
③最终目的:让程序在它运行的当前目录下,能够很好的或者有效的找到这个文件。找到这个文件,并且指定正确的文件名称
3)打开模式

①r:可用try except 捕捉异常并处理
②r、w、x、a是四种与读写相关的模式
③与打开文件方式相关的模式b、t
④默认情况下以t打开,也就是文本方式来打开文件
⑤+:形成r+、w+、x+和a+
(3)文件的关闭
<变量名>.close()
①它使用打开之后赋予的文件句柄
②若打开后,没有调用f.close去关闭这个文件,那么这个文件始终是被打开状态
③但是当程序退出,Python的解释器会自动的将这个文件关闭
3.文件内容的读取
(1)相关函数
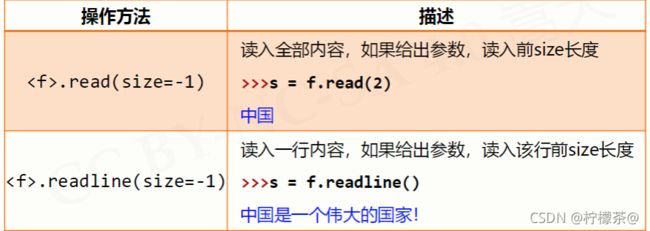

(2)文件的全文本操作:遍历文件的全部信息
①方法一
fname = input("请输入要打开的文件名称:") # 用户输入文件名称,包含路径
fo = open(fname, "r") # 以只读模式打开,句柄为fo
txt = fo.read() # read函数一次性读取文件
# 对全文txt进行处理
fo.close()
1)特点:一次读入,统一处理。
2)弊端:如果这样的文本文件体量特别大,一次性将文件读入内存会耗费很多时间和资源
②方法二(按数量读入逐步处理)
fname = input("请输入要打开的文件名称:") # 用户输入文件名称,包含路径
fo = open(fname, "r") # 以只读模式打开,句柄为fo
txt = fo.read(2) # 参数赋为2,指的是从文件中读入两个字节
while txt != "":
# 对全文txt进行处理
txt = fo.read(2) # 只要信息不为空,持续处理
fo.close()
1)特点:按数量读入,逐步处理
2)适用:处理大文件更可行有效
(3)文件的逐行操作(逐行遍历文件)
①方法一(一次读入,分行处理)
fname = input("请输入要打开的文件名称:") # 用户输入文件名称,包含路径
fo = open(fname, "r") # 以只读模式打开,句柄为fo
for line in fo.readlines(): # 此函数将fo中所有的信息文本以行的方式生成一个列表,每行是列表的一个元素
print(line)
fo.close()
②方法二(对大文件,逐行将信息读出)
fname = input("请输入要打开的文件名称:") # 用户输入文件名称,包含路径
fo = open(fname, "r") # 以只读模式打开,句柄为fo
for line in fo: # 直接使用
print(line)
fo.close()
4.数据的文件写入
(1)相关函数


①writelines写入后,它们之间没有换行,也没有空格。仅仅是将各个元素直接拼接写入
②seek函数:改变写入信息的位置
(2)举例
fo = open( "output.txt" , "w+")
ls =["中国","法国",“美国"]
fo.writelines(ls) # 写入一个字符串列表
for line in fo:
print(line)
fo.close()
①执行之后发现,程序无任何输出
②对代码进行修改
fo = open( "output.txt" , "w+")
ls =["中国","法国",“美国"]
fo.writelines(ls) # 写入一个字符串列表
fo.seek(0)
for line in fo:
print(line)
fo.close()
思考:①当我们将信息写入到文件的时候,当前文件处理的指针在文件的最后面,指向下一次可能写入信息的位置
②此时用for in去遍历一行并且打印输出的时候,它指的是从当前位置向文件的结尾处,取出其中的每一行并且打印出来
③已经写过的信息它在指针的上方并不在指针的下方,故之前的代码它并不能输出我们已经写过的信息
④需要调整当前写入后的指针,回到初始位置
⑤从初始位置开始再进行逐行遍历即可输出
二、实例:自动轨迹绘制
1.问题分析
(1)需求:根据脚本来绘制图形
(2)不是写代码而是写数据绘制轨迹
(3)数据脚本是自动化最重要的第一步
(4)预期结果:
①给出文件,其中列出一些数据参数
②经过程序加载运行,自动绘制出我们期望的轨迹

2.实例讲解
(1)基本思路
①步骤1:定义数据文件格式(接口)(程序和数据之间的一种规范)
②步骤2∶编写程序,根据文件接口解析参数,绘制图形
③步骤3∶编制数据文件
(2)数据接口定义
①具有个性色彩,没有既定规范
②举例:(一行表示一次操作)
1)第一个数据:表示当前位置开始向前行进的一个距离
2)第二个数据:表示转向判断。如果数据是0让当前的画笔向左转,反之为1向右转
3)第三个数据:表示向左转或者向右转的绝对转向角度
4)后三个参数:分别对应画这一段曲线或直线过程中,所使用的RGB三个通道的颜色。取值范围:0-1之间的浮点数
③需要写一段程序与接口对应,能够读取这样的文件并且解析它。进而绘制相关图形
(3)自动轨迹绘制
import turtle as t # 使用别名方式将turtle别名为t
# 基础准备工作(生成绘画环境)
t.title('自动轨迹绘制') # 设置绘制窗口的标题栏的信息
t.setup(800, 600, 0, 0) # 设置绘制窗口的大小
t.pencolor("red") # 设置初始绘制画笔颜色
t.pensize(5) # 绘制画笔的粗细
# 数据读取(打开文件,解析数据文件中每一行的信息并做相关处理)
# 可能的绘制数据预估不是很大,读入所有信息后保存为列表
datals = [] # 建立空列表
f = open("data.txt")
for line in f: # 从文件中读取遍历每一行
line = line.replace("\n", "") # 将文件最后的换行符转换为空字符,去掉换行的信息。此时line存储的是我们定义的每一行的数据接口的值
# 需将数据接口的值进行分割、处理并且提取其中的信息。
# 拿到一行6个参数,中间用逗号分隔。我们希望每一个解析的元素都是真实的数字
datals.append(list(map(eval, line.split(",")))) # 使用split且指定“,”为分隔符,将其分割成若干个字符串。能生成一个列表,每一个元素就是由”,分割的一段字符串
# map是Python提供的内嵌函数(无需import),可将第一个参数的功能作用于第二个参数的每一个元素。即对一个列表或者一个集合这样的组合数据类型的每一个元素都执行一次第一个参数所对应的函数
# 列表中的每一个元素都去掉了引号,变成数字。之后使用append将这一个字符串放到我们预先定义的datals列表中
f.close()
# 经过以上处理,我们将接口信息读入到了内部的一个列表变量中,列表变量的每一个元素是一行的信息
# 自动绘制
for i in range(len(datals)): # 返回datals长度(元素个数),指逐一的获取其中的遍历整数
t.pencolor(datals[i][3], datals[i][4], datals[i][5]) # 获得当前datals的一个元素,并且找到元素的第三个参数为RGB中R值,第四个元素是G值,第五个元素是B值
t.fd(datals[i][0]) # 我们定义的数据接口中第一个元素是行进距离
if datals[i][1]: # 第二个参数等于1向右转,0向左转
t.right(datals[i][2])
else:
t.left(datals[i][2])
(4)编制数据文件
①每一行指的是画笔的一次根据接口的规定动作
②保存文件data.txt
300,0,144,1,0,0
300,0,144,0,1,0
300,0,144,0,0,1
300,0,144,1,1,0
300,0,108,0,1,1
184,0,72,1,0,1
184,0,72,0,0,0
184,0,72,0,0,0
184,0,72,0,0,0
184,1,72,1,0,1
184,1,72,0,0,0
184,1,72,0,0,0
184,1,72,0,0,0
184,1,72,0,0,0
184,1,720,0,0,0
③用写的程序调用文件,绘制想要的图形
3.举一反三
(1)理解方法思维
①自动化思维:数据和功能分离,数据驱动的自动运行
②接口化设计:格式化设计接口,清晰明了
③二维数据应用(简化了程序与接口之间的操作关系):应用维度组织数据,二维数据最常用
(2)应用问题的扩展
①扩展接口设计,增加更多控制接口
②扩展功能设计,增加弧形等更多功能
③扩展应用需求,发展自动轨迹绘制到动画绘制
三、一维数据的格式化和处理
1.数据组织的维度
——从一个数据到一组数据
(1)维度:一组数据的组织形式
(2)一维数据
由对等关系的有序或无序数据构成,采用线性方式组织
对应列表、数组和集合等概念
(3)二维数据
由多个一维数据构成,是一维数据的组合形式
①表格是典型的二维数据
②其中,表头是二维数据的一部分
(4)多维数据
由一维或二维数据在新维度上扩展形成(如时间扩展)
(5)高维数据
仅利用最基本的三元关系来展示数据间的复杂结构
如:字典类型中用键值对表示值和它属性之间的关系,键值对之间可以进行有效组织,表达更复杂的逻辑关系
(6)数据的操作周期
存储<->表示<->操作
①数据存储:数据在磁盘中的存储状态,重点在于数据存储所使用的格式
②数据表示:指程序表达数据的方式,重点在于数据类型
③数据操作:相关操作方式和算法的体现
2.一维数据的表示
(1)讨论如何用程序的类型来表达一维数据
(2)如果数据间有序:使用列表类型
①列表类型可以表达一维有序数据
②for循环可以遍历数据,进而对每个数据进行处理
(3)如果数据间无序∶使用集合类型
①集合类型可以表达一维无序数据
②for循环可以遍历数据,进而对每个数据进行处理
3.一维数据的存储
(1)存储方式一∶空格分隔
①使用一个或多个空格分隔进行存储,不换行
②缺点:数据中不能存在空格(否则无法区分)
(2)存储方式二∶逗号分隔
①使用英文半角逗号分隔数据进行存储,不换行
②缺点:数据中不能有英文逗号
(3)存储方式三∶其他方式(视情况而定)
①使用其他符号或符号组合分隔,建议采用特殊符号
②缺点︰需要根据数据特点定义,通用性较差
③根据数据的特点来去定义选择一个不会出现特殊符号
(4)共性:数据中都不能出现用于分割的字符
4.一维数据的处理
(1)数据的处理:存储<->表示
①将存储的数据读入程序
②将程序表示的数据写入文件
③举例:从空格分隔的文件中读入数据,表示成列表形式
中国 美国 日本 德国 法国 英国 意大利
txt = open(fname).read()
ls = txt.split()
f.close()
④举例二:从特殊符号分隔的文件中读入数据
中国 美 国 美国 美国日本 德 国 德国 德国法国 英 国 英国 英国意大利
txt = open(fname).read()
ls =txt.split("$")
f.c1ose()
(2)一维数据的写入处理
①采用空格分隔方式将数据写入文件
ls = ['中国",‘美国,'日本']
f = open(fname, 'w ')
f.write( ''.join(ls)) # 将join前面的字符串分割放置到后边的oin参数中的各个元素之间
f.close()
②采用特殊分隔方式将数据写入文件
ls = ['中国",‘美国,'日本']
f = open(fname, 'w ')
f.write( '$'.join(ls)) # 将将ls中的元素之间增加$形成一个大字符串并把它写入文件
f.close()
四、二维数据的格式化和处理
1.二维数据的表示
(1)使用列表类型
①由于每一行具有相同的格式特点,一般我们采用列表类型来表达三维数据
②使用二维列表:本身是一个列表,而列表中每一个元素又是一个列表,可以代表二维数据的一行或者一列
③若干行和若干列组织起来形成的外围列表构成二维列表
(2)遍历
①使用两层for循环遍历每个元素
②外层列表中每个元素可以对应一行,也可以对应一列
(3)一二维数据的Python表示
数据维度是数据的组织形式
①—维数据:列表和集合类型(数据间有序用列表类型,无序用集合类型)
②二维数据:统一使用列表类型
2.CSV格式与二维数据存储
(1)CSV数据存储格式
①CSV: Comma-Separated Values
②指由逗号分隔的值,即用逗号来分割值的一种存储方式
③国际通用的一二维数据存储格式,一般.csv扩展名
④每行一个一维数据,采用逗号分隔,无空行
⑤Excel和一般编辑软件都可以读入或另存为csv文件
⑥CSV是数据转换之间的通用的标准格式
(2)举例

①二维数据转换为CSV格式之后,会变成由逗号分隔的形式
②原表格中的一行对应为CSV数据格式中的一行
③原表格中的每一列跟每一列之间,在CSV格式中使用逗号来分割
(3)一些约定
①如果某个元素缺失,逗号仍要保留
②二维数据的表头可以作为数据存储,也可以另行存储
③逗号为英文半角逗号,逗号与数据之间无额外空格
④如果数据中包含逗号,不同的CSV软件会有一些约定
1)在数据两侧增加一些引号来表达这个逗号不是分割元素的逗号
2)增加转义符
注意:我们此时不考虑出现逗号的情况
(4)二维数据的存储
①按行存或者按列存都可以,具体由程序决定
②一般索引习惯:ls[row][column],先行后列
③根据一般习惯,外层列表每个元素是一行,按行存
④好处:可以达到一般的一个调用习惯
3.二维数据的处理
(1)从CSV格式的文件中读入数据,写入二维列表
fo = open(fname)
ls = []
for line in fo:
line = line.replace("\n","")
ls.append(line,split(","))
fo.close()
①replace方法将最后的回车替换为空字符串
②split:按逗号分隔,将每行中的元素按逗号分隔开形成列表,增加到ls列表中,作为其中的一个元素
③操作之后的ls是包含二维数据的一个二维列表信息
(2)保存在列表中的二维数据写入CSV格式的文件中
ls = [[],[],[]] # 二维列表
f = open(fname,'w ')
for item in ls: # 读取其中的每一行元素写入
f.write( " , '.join(item) + "\n ') # 对item中的元素之间增加逗号,最后增加\n作为这一行的结尾
f.close()
(3)二维数据的逐一处理
采用二层循环
ls = [[1,2],[3,4],[5,6]] # 二维列表
for row in ls:
for column in row :
print(column)
五、模块6: wordcloud库的使用
1.基本介绍
(1)概述
①wordcloud是优秀的词云展示第三方库
②词云就是将词语通过图形可视化的方式直观和艺术的展示出来
(2)wordcloud库安装
(cmd命令行) pip install wordcloud
2.wordcloud库使用说明
(1)基本使用
①wordcloud库把词云当作一个WordCloud对象
注意:使用库时,库名是全小写,但库中的具体词云有大写有小写
②wordcloud.WordCloud()代表一个文本对应的词云,一个词云就是一个WordCloud对象
③可以根据文本中词语出现的频率等参数绘制词云
④绘制词云的形状、尺寸和颜色都可以设定
(2)常规方法
w=wordcloud.WordCloud()
生成一个词云对象,进一步向w赋予特定的文本参数以及操作,将词云输出成文件
①以WordCloud对象为基础
②配置参数、加载文本、输出文件
③2个函数

(3)词云绘制步骤介绍
①步骤1∶配置对象参数
②步骤2∶加载词云文本
③步骤3∶输出词云文件
举例
import wordcloud
c = wordcloud.wordcloud()
c.generate( "wordcloud by Python")
c.to_file("pywordcloud.png")

(4)由文本变为词云,wordcloud库处理流程
①分隔:以空格分隔单词
②统计:单词出现次数并过滤(次数多显示的词云效果的字体会变得很大,反之则小;很短的单词(比如只有1到2个字母和字符的单词)过滤掉)
③字体:根据统计出现的次数,为不同的单词配置显示的字号
④布局:颜色环境尺寸(布局单词效果,最终形成词云)
故我们只需给wordcloud库一个由空格分隔的大字符串
(5)配置对象参数
①图片大小

②修改字体

三者结合可控制字体出现的最小最大字号以及中间的步进间隔
③指定文字字体格式,如:微软雅黑

④与词云对象相关的参数

⑤一个常用有趣的参数mask(指定词云形状)&背景颜色

(6)应用实例
①英文词云
import wordcloud
txt = "life is short, you need python"
w = wordcloud.WordCloud(background_color = "white")
w.generate(txt)
w.fo_file("pywcloud.png")

②中文词云 (中文含有逗号,先用jieba库分词)
import jieba
import wordcloud
txt ="程序设计语言是计算机能够理解和识别用户操作意图的一种交互体系,它按照特定规则组织计算机指令,使计算机能够自动进行各种运算处理。"
w = wordcloud. wordCloud( width=1000, font_path="msyh.ttc",height=700)
w.generate( " ".join(jieba.lcut(txt)))
w.to_file("pywcloud.png")

1)将这段文本通过jieba.lcut函数变成一个列表
2)进一步用join方法将列表中的元素用join前面的空格字符串来分隔,构成一个长字符串
3)赋给wordcloud对象
六、实例12:政府工作词云报告
1.问题分析
(1)直观理解政策文件
①需求:对于政府工作报告等政策文件,如何直观理解?
②体会直观的价值:生成词云&优化词云
(2)两份文件
①《决胜全面建成小康社会夺取新时代中国特色社会主义伟大胜利》
https://python123.io/resources/pye/新时代中国特色社会主义.txt
②《中共中央国务院关于实施乡村振兴战略的意见》
https://python123.io/resources/pye/关于实施乡村振兴战略的意见.txt
2.实例解析
(1)基本思路
①步骤1∶读取文件、分词整理
②步骤2∶设置并输出词云
③步骤3∶观察结果,优化迭代
(2)代码实现
①附码
import jieba # 中文文本需分词
import wordcloud
from scipy.misc import imread
mask = imread("fivestart.png") # 能读取文件并且变成一个图片文件表达的内部变量
f = open("新时代中国特色社会主义.txt", "r", encoding="utf-8")
t = f.read() # 文本内容一次性读入变量t
f.close()
ls = jieba.lcut(t) # 进行分词,结果保存为列表类型ls
txt = "".join(ls) # 用空格来将列表的每一个元素连接起来,形成一个由空格分隔的长字符串txt
w = wordcloud.WordCloud(font_path = "msyh.ttc",mask = mask,width = 1000,height = 700, background_color = "white")
w.generate(txt) # 加载文本
w.to_file("grwordcloud.png") # 生成词云文件
②效果

③更换另一份文件

④限制输出词语数量
增加:max_words = 15
import jieba # 中文文本需分词
import wordcloud
f = open("新时代中国特色社会主义.txt", "r", encoding="utf-8")
t = f.read() # 文本内容一次性读入变量t
f.close()
ls = jieba.lcut(t) # 进行分词,结果保存为列表类型ls
txt = "".join(ls) # 用空格来将列表的每一个元素连接起来,形成一个由空格分隔的长字符串txt
w = wordcloud.WordCloud(font_path = "msyh.ttc",width = 1000,height = 700, background_color = "white",max_words = 15)
w.generate(txt) # 加载文本
w.to_file("grwordcloud.png") # 生成词云文件
效果如图

(3)生成更有型的词云(五角星形状)
①wordcloud库提供mask参数,通过覆盖的方法可以生成任意形状的词云
②按需求提供背景是白色的五角星图片
③为了加载图片,需引入一个库
④生成wordcloud对象时使用mask参数,将之前的mask方法给定到mask参数中
⑤代码
import jieba # 中文文本需分词
import wordcloud
from scipy.misc import imread
mask = imread("fivestart.png") # 能读取文件并且变成一个图片文件表达的内部变量
f = open("新时代中国特色社会主义.txt", "r", encoding="utf-8")
t = f.read() # 文本内容一次性读入变量t
f.close()
ls = jieba.lcut(t) # 进行分词,结果保存为列表类型ls
txt = "".join(ls) # 用空格来将列表的每一个元素连接起来,形成一个由空格分隔的长字符串txt
w = wordcloud.WordCloud(font_path = "msyh.ttc",mask = mask,width = 1000,height = 700, background_color = "white")
w.generate(txt) # 加载文本
w.to_file("grwordcloud.png") # 生成词云文件
修改三处

⑥效果

3.举一反三
(1)扩展能力
①了解wordcloud更多参数,扩展词云能力
②特色词云:设计一款属于自己的特色词云风格
③更多文件:用更多文件练习词云生成
(2)词云:快速掌握文本信息
总结
经过本篇的学习,可以大致掌握文件类型的操作。运用一维、二维数据和wordcloud库去实现一些文本的词云实现。对于自动化程序,可以通过不同的自定义方式,进行各类接口的对比和优劣,找导不同问题对应的最适合的接口规范。
至此,已经全部讲解了Python基础语法体系
下篇将介绍拓展系列——程序设计方法学。