并发编程(五)python实现生产者消费者模式多线程爬虫
并发编程专栏系列博客
并发编程(一)python并发编程简介
并发编程(二)怎样选择多线程多进程和多协程
并发编程(三)Python编程慢的罪魁祸首。全局解释器锁GIL
并发编程(四)如何使用多线程,使用多线程对爬虫程序进行修改及比较
并发编程(五)python实现生产者消费者模式多线程爬虫
并发编程(六)线程安全问题以及lock解决方案
并发编程(七)好用的线程池ThreadPoolExecutor
并发编程(八)在web服务中使用线程池加速
并发编程(九)使用多进程multiprocessing加速程序运行
并发编程(十)在Flask服务中使用进程池加速
并发编程(十一)python异步IO实现并发编程
并发编程(十二)使用subprocess启动电脑任意程序(听歌、解压缩、自动下载等等)
文章目录
-
-
-
-
-
- 多组件的Pipeline技术架构
- 生产者消费者爬虫架构
- 多线程数据通信的queue.Queue
- 代码实现
-
-
-
-
多组件的Pipeline技术架构
-
在介绍或者使用生产者消费者模式前我们先大概了解一下Pipeline架构。
-
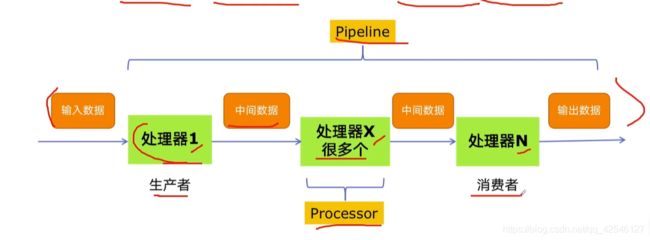
例如,对于一件复杂的事情,我们常常都不会一下子做完,而是会分成很多中间步骤一步步完成,进而简化复杂的事情。请看下图:
-
-
如图,我们现在有一个事情由输入数据得到输出数据,中间会经过很多的模块,而这些模块之间会通过中间数据进行交互。我们称这些处理模块为处理器也叫Processor,而把事情分为很多模块进行处理的架构称为Pipeline架构。
-
我们接下来所要用到的生产者消费者模式就是一个典型的Pipeline,他有两个角色,生产者和消费者。生产者利用输入数据当做原料生产的结果会通过中间数据传给消费者进行消费,而消费者则利用中间数据进行消费得到最终的输出数据。
生产者消费者爬虫架构
-
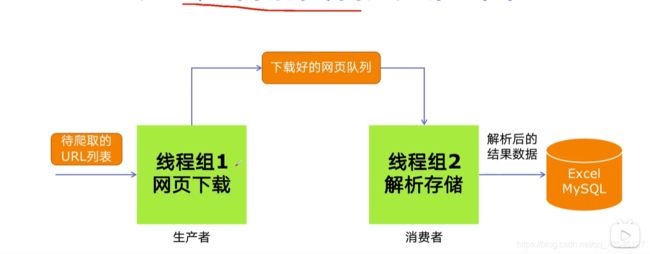
从上文我们对生产者消费者模式有了简单了解,接下来我们看一下爬虫的生产者消费者架构。如图:
-
-
从上图,我们可以看到生产者负责网页下载,而消费者负责网页的解析和存储。两者之间是互不影响且都可以使用多线程的,那如何把下载好的网页发给消费者进行处理呢?
多线程数据通信的queue.Queue
-
我们上文提到多线程的生产者和消费者之间需要数据交互进行完成爬虫。同时也遗留了一个问题,那就是多线程之间如何进行数据交互。于是,便有了queue.Queue。
-
queue.Queue可以用于多线程之间的、线程安全的数据通信。
-
基本语法规则:
# 1.导入类库 import queue # 2.创建Queue q = queue.Queue() # 3.添加元素(如果队列已满,则进行阻塞,等待队列不满时添加) q.put(item) # 4.获取元素(如果队列为空,则进行阻塞,等待队列不空时获取) item = q.get() # 5.查询状态 # 查看元素的多少 q.qsize() # 判断是否为空 q.empty() # 判断是否已满 q.full()
代码实现
-
首先先创建一个下载和解析分开的爬虫代码
# 导包 import requests from bs4 import BeautifulSoup # 爬取链接列表 urls = [ f"https://w.cnblogs.com/#p{page}" for page in range(1, 51) ] # 获取下载网页函数 def craw(url): r = requests.get(url) return r.text # 获取网页中的每个博客的链接和标题 def parse(html): soup = BeautifulSoup(html, "html.parser") links = soup.find_all("a", class_="post-item-title") return [(link["href"], link.get_text()) for link in links] # 调用函数测试 if __name__ == '__main__': for rst in parse(craw(urls[2])): print(rst) ''' output: ('https://www.cnblogs.com/TomDwan/p/14550984.html', '文件上传漏洞全面渗透姿势总结') ('https://www.cnblogs.com/ice-image/p/14554250.html', 'RPC 框架设计') ('https://www.cnblogs.com/huaweiyun/p/14554253.html', '都在讲Redis主从复制原理,我来讲实践总结') ('https://www.cnblogs.com/JulianHuang/p/14554245.html', 'Ingress-nginx工作原理和实践') ('https://www.cnblogs.com/tencent-cloud-native/p/14554124.html', '一文读懂SuperEdge拓扑算法') ('https://www.cnblogs.com/root429/p/14554028.html', '阿里一面CyclicBarrier和CountDownLatch的区别是啥') ('https://www.cnblogs.com/light0011/p/14554003.html', '图的最短路径之杨贵妃荔枝自由') ('https://www.cnblogs.com/chiaki/p/14551882.html', '浅析MyBatis(三):聊一聊MyBatis的实用插件与自定义插件') ('https://www.cnblogs.com/technology-blog/p/14544096.html', 'Spring源码之ApplicationContext') ('https://www.cnblogs.com/zgrey/p/14553606.html', 'KVM虚拟化配置') ('https://www.cnblogs.com/xiyuanMore/p/14553598.html', '聊聊自驱团队的构建(四)') ('https://www.cnblogs.com/pengdai/p/14553561.html', 'Tomcat详解系列(2) - 理解Tomcat架构设计') ('https://www.cnblogs.com/onlyblues/p/14550828.html', '遍历二叉树的递归与非递归代码实现') ('https://www.cnblogs.com/xueweihan/p/14553532.html', '详解 ZooKeeper 数据持久化') ('https://www.cnblogs.com/charlieroro/p/14439895.html', '混合云中的事件驱动架构') ('https://www.cnblogs.com/vchar/p/14347260.html', 'Docker上安装Redis') ('https://www.cnblogs.com/danvic712/p/simplify-abp-generated-template-structure.html', 'ABP 适用性改造 - 精简 ABP CLI 生成的项目结构') ('https://www.cnblogs.com/flydean/p/14553206.html', '密码学系列之:csrf跨站点请求伪造') ('https://www.cnblogs.com/cmt/p/14553189.html', '网站整改公告') ('https://www.cnblogs.com/pingguo-softwaretesting/p/14535112.html', '【小白学算法】5.链表(linked list),链表的插入、读取') ''' -
接下来使用多线程实现生产者消费者模式。
# -*- coding: utf-8 -*- # @Time : 2021-03-20 16:02:55 # @Author : wlq # @FileName: blog_spider1.py # @Email :[email protected] # 导包 import requests from bs4 import BeautifulSoup import queue import time import random import threading # 爬取链接列表 urls = [ f"https://w.cnblogs.com/#p{page}" for page in range(1, 51) ] # 获取下载网页函数 def craw(url): r = requests.get(url) return r.text # 解析网页函数 def parse(html): soup = BeautifulSoup(html, "html.parser") links = soup.find_all("a", class_="post-item-title") return [(link["href"], link.get_text()) for link in links] # 生产者 def do_craw(url_queue: queue.Queue, html_queue: queue.Queue): while True: url = url_queue.get() html = craw(url) html_queue.put(html) print(threading.current_thread().name, f"craw{url}", "url_queue.size=", url_queue.qsize()) time.sleep(random.randint(1, 2)) # 消费者 def do_parse(html_queue: queue.Queue, file): while True: html = html_queue.get() rst = parse(html) for x in rst: file.write(str(x) + "\n") print(threading.current_thread().name, "rst.size", len(rst), "html_queue.size=", html_queue.qsize()) time.sleep(random.randint(1, 2)) if __name__ == '__main__': # 创建输入数据队列 url_queue = queue.Queue() # 创建中间数据队列 html_queue = queue.Queue() # 将需要爬取的链接添加到输入数据队列 for url in urls: url_queue.put(url) # 创建三个生产者进行生产 for idx in range(3): t = threading.Thread(target=do_craw, args=(url_queue, html_queue), name=f"craw{idx}") t.start() file = open('spider.txt', 'w') # 创建两个消费者消费 for idx in range(2): t = threading.Thread(target=do_parse, args=(html_queue, file), name=f"parse{idx}") t.start() ''' output: craw2 crawhttps://w.cnblogs.com/#p3 url_queue.size= 47 craw0 crawhttps://w.cnblogs.com/#p1 url_queue.size= 47 parse0 rst.size 20 html_queue.size= 0 parse1 rst.size 20 html_queue.size= 0 craw1 crawhttps://w.cnblogs.com/#p2 url_queue.size= 47 parse0 rst.size 20 html_queue.size= 0 craw2 crawhttps://w.cnblogs.com/#p4 url_queue.size= 46 parse1 rst.size 20 html_queue.size= 0 craw0 crawhttps://w.cnblogs.com/#p5 url_queue.size= 44 parse0 rst.size 20 html_queue.size= 0 craw1 crawhttps://w.cnblogs.com/#p6 url_queue.size= 44 parse1 rst.size 20 html_queue.size= 0 craw0 crawhttps://w.cnblogs.com/#p7 url_queue.size= 42 craw2 crawhttps://w.cnblogs.com/#p8 url_queue.size= 42 parse0 rst.size 20 html_queue.size= 1 parse1 rst.size 20 html_queue.size= 0 craw1 crawhttps://w.cnblogs.com/#p9 url_queue.size= 41 parse1 rst.size 20 html_queue.size= 0 craw0 crawhttps://w.cnblogs.com/#p10 url_queue.size= 38 craw2 crawhttps://w.cnblogs.com/#p11 url_queue.size= 38 craw1 crawhttps://w.cnblogs.com/#p12 url_queue.size= 38 parse0 rst.size 20 html_queue.size= 2 parse1 rst.size 20 html_queue.size= 1 craw0 crawhttps://w.cnblogs.com/#p13 url_queue.size= 35 craw2 crawhttps://w.cnblogs.com/#p14 url_queue.size= 35 craw1 crawhttps://w.cnblogs.com/#p15 url_queue.size= 35 parse0 rst.size 20 html_queue.size= 3 parse1 rst.size 20 html_queue.size= 2 craw0 crawhttps://w.cnblogs.com/#p16 url_queue.size= 32 craw2 crawhttps://w.cnblogs.com/#p17 url_queue.size= 32 craw1 crawhttps://w.cnblogs.com/#p18 url_queue.size= 32 craw0 crawhttps://w.cnblogs.com/#p19 url_queue.size= 30 craw2 crawhttps://w.cnblogs.com/#p20 url_queue.size= 30 parse0 rst.size 20 html_queue.size= 6 parse1 rst.size 20 html_queue.size= 5 craw1 crawhttps://w.cnblogs.com/#p21 url_queue.size= 28 craw0 crawhttps://w.cnblogs.com/#p22 url_queue.size= 28 parse0 rst.size 20 html_queue.size= 6 parse1 rst.size 20 html_queue.size= 5 craw2 crawhttps://w.cnblogs.com/#p23 url_queue.size= 27 parse1 rst.size 20 html_queue.size= 5 craw1 crawhttps://w.cnblogs.com/#p24 url_queue.size= 25 craw0 crawhttps://w.cnblogs.com/#p25 url_queue.size= 25 parse0 rst.size 20 html_queue.size= 6 craw2 crawhttps://w.cnblogs.com/#p26 url_queue.size= 23 parse1 rst.size 20 html_queue.size= 6 craw0 crawhttps://w.cnblogs.com/#p27 url_queue.size= 23 parse0 rst.size 20 html_queue.size= 6 craw1 crawhttps://w.cnblogs.com/#p28 url_queue.size= 21 craw2 crawhttps://w.cnblogs.com/#p29 url_queue.size= 21 craw0 crawhttps://w.cnblogs.com/#p30 url_queue.size= 20 parse1 rst.size 20 html_queue.size= 8 craw0 crawhttps://w.cnblogs.com/#p31 url_queue.size= 19 parse0 rst.size 20 html_queue.size= 8 craw1 crawhttps://w.cnblogs.com/#p32 url_queue.size= 17 craw2 crawhttps://w.cnblogs.com/#p33 url_queue.size= 17 craw0 crawhttps://w.cnblogs.com/#p34 url_queue.size= 16 parse0 rst.size 20 html_queue.size= 10 parse1 rst.size 20 html_queue.size= 9 craw1 crawhttps://w.cnblogs.com/#p35 url_queue.size= 15 craw0 crawhttps://w.cnblogs.com/#p36 url_queue.size= 14 parse1 rst.size 20 html_queue.size= 10 craw2 crawhttps://w.cnblogs.com/#p37 url_queue.size= 13 parse0 rst.size 20 html_queue.size= 10 craw1 crawhttps://w.cnblogs.com/#p38 url_queue.size= 12 craw0 crawhttps://w.cnblogs.com/#p39 url_queue.size= 11 parse1 rst.size 20 html_queue.size= 11 craw2 crawhttps://w.cnblogs.com/#p40 url_queue.size= 9 craw1 crawhttps://w.cnblogs.com/#p41 url_queue.size= 9 parse0 rst.size 20 html_queue.size= 12 craw0 crawhttps://w.cnblogs.com/#p42 url_queue.size= 8 parse0 rst.size 20 html_queue.size= 12 parse1 rst.size 20 html_queue.size= 11 craw2 crawhttps://w.cnblogs.com/#p43 url_queue.size= 6 craw1 crawhttps://w.cnblogs.com/#p44 url_queue.size= 6 parse1 rst.size 20 html_queue.size= 12 craw0 crawhttps://w.cnblogs.com/#p45 url_queue.size= 5 craw2 crawhttps://w.cnblogs.com/#p46 url_queue.size= 4 parse0 rst.size 20 html_queue.size= 13 parse1 rst.size 20 html_queue.size= 12 craw0 crawhttps://w.cnblogs.com/#p47 url_queue.size= 3 craw1 crawhttps://w.cnblogs.com/#p48 url_queue.size= 1 craw2 crawhttps://w.cnblogs.com/#p49 url_queue.size= 1 craw0 crawhttps://w.cnblogs.com/#p50 url_queue.size= 0 parse0 rst.size 20 html_queue.size= 15 parse1 rst.size 20 html_queue.size= 14 parse0 rst.size 20 html_queue.size= 13 parse1 rst.size 20 html_queue.size= 12 parse0 rst.size 20 html_queue.size= 11 parse1 rst.size 20 html_queue.size= 10 parse0 rst.size 20 html_queue.size= 9 parse1 rst.size 20 html_queue.size= 8 parse1 rst.size 20 html_queue.size= 7 parse0 rst.size 20 html_queue.size= 6 parse1 rst.size 20 html_queue.size= 5 parse0 rst.size 20 html_queue.size= 4 parse0 rst.size 20 html_queue.size= 3 parse1 rst.size 20 html_queue.size= 2 parse0 rst.size 20 html_queue.size= 1 parse0 rst.size 20 html_queue.size= 0 '''通过输出可以看出,最开始url_queue为47,是因为一开始三个生产者已经拿走三个。接着用过生产者的不断生产,输入数据队列逐渐变小。而中间数据队列html_queue在一会儿变大一会儿变小,最后一部分也是逐渐变小。这是因为刚开始中间队列为空,生产者生产完成后会将数据存入中间队列,导致中间队列变大,消费者在监测到中间队列不为空时,取出中间数据进行消费导致队列变小,两者同时进行导致中间队列大小的波动。最后,生产者队列所有数据取完,生产者不再生产数据,中间队列不再变大。同时,消费者继续消费,导致中间队列持续变小,直至为空。
注:最后程序一直没有结束是因为生产者和消费者一直监测生产队列和消费队列是否有新的数据出现。