前馈神经网络对mnist数据集实战
对手写数字的预测
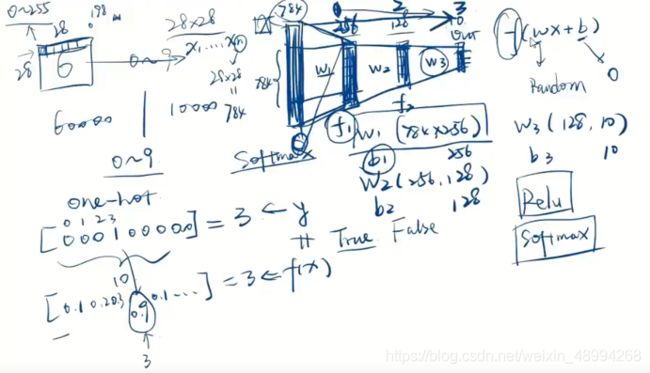
这里我们第一个激活函数一般选用Relu,最后输出的是对应的多个分类的概率值,所以最后一个激活函数选用softmax函数。中间的隐藏层的个数和大小可以改变,但最后必须是10
代码实现
import tensorflow as tf
import matplotlib.pyplot as plt
#输入层 h1 784
#隐藏层 h2 256
#隐藏层 h3 128
#输出层 h4 10#初始化参数
w1=tf.Variable(tf.random.truncated_normal([784,256],stddev=0.1))
w2=tf.Variable(tf.random.truncated_normal([256,128],stddev=0.1))
w3=tf.Variable(tf.random.truncated_normal([128,10],stddev=0.1))
b1=tf.Variable(tf.zeros([256]))
b2=tf.Variable(tf.zeros([128]))
b3=tf.Variable(tf.zeros([10]))数据下载
(x_train, y_train), (x_test, y_test)=tf.keras.datasets.mnist.load_data()
#这里把路径删掉
这里我们先看看训练集x,y的数据,发现x是0-255的数据,我们要将它变成0-1(也就是将图二值化处理),而y的值发现他是0-9的整数类型,也就是我们的最后的标签
#先将x的类型由np转为tf,然后将数据类型变为浮点型,并除以255归到0-1
x_train=tf.convert_to_tensor(x_train,dtype=tf.float32)/255
y_train=tf.convert_to_tensor(y_train,dtype=tf.int32)
#可以看出训练集的数据格式三维,我们这里将它拉成二维的(60000,784)
#转成tensor类型
x_train=tf.reshape(x_train,[-1,28*28])
print(x_train.shape)
TensorShape([60000, 784])
完成一次向前计算
x_train.shape,w1.shape,b1.shape(TensorShape([60000, 784]), TensorShape([784, 256]), TensorShape([256]))
#第一层h1:net1(z=sum(wx+b)) out1:(relu(z))
#[60000,784]@[784,256]+[256]
# net1=x_train@w1+tf.broadcast_to(b1,[x_train.shape[0],256])
#这里我们发现b1要想和他们相加必须改为(60000,256),这里我们用广播,但是在tf里可以直接广播,如下
net1=x_train@w1+b1
out1=tf.nn.relu(net1)这里的relu函数可以直接取官网查他的用法,和之前的网页一样
#h2 :net2(net1=sum(wx+b)) out2:(relu(net1))
#[60000,256]@[256,128]+[128]
net2=out1@w2+b2
out2=tf.nn.relu(net2)
#h3 :net3(net2=sum(wx+b)) out3:(softmax(net2))
#[60000,128]@[128,10]+[10]
net3=out2@w3+b3
out3=tf.nn.softmax(net3)
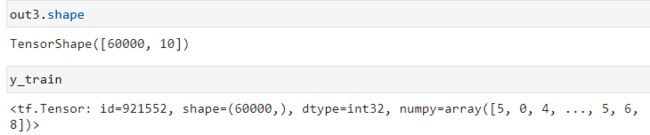
#这里的用法也是去官网查
#对训练集进行热编码
y_train=tf.one_hot(y_train,depth=10)
y_train,y_train.shape:(
[1., 0., 0., …, 0., 0., 0.],
[0., 0., 0., …, 0., 0., 0.],
…,
[0., 0., 0., …, 0., 0., 0.],
[0., 0., 0., …, 0., 0., 0.],
[0., 0., 0., …, 0., 1., 0.]], dtype=float32)>,
TensorShape([60000, 10]))

loss=tf.nn.softmax_cross_entropy_with_logits(labels=y_train, logits=out3, axis=-1)
loss
2.2942417], dtype=float32)>
#我们看看在当前模型下的损失值的大概大小
loss=tf.reduce_mean(loss)
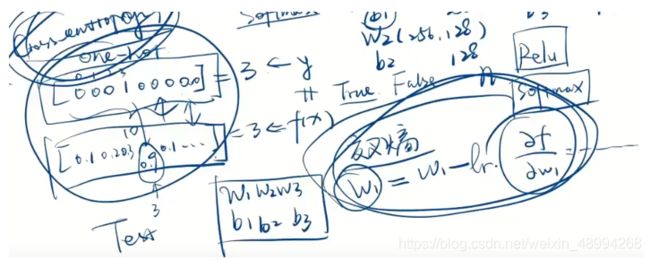
loss反向传播
这里我们先做一次的反向传播,仅仅是看下编码的步骤
with tf.GradientTape() as tape:
tape.watch([w1,b1,w2,b2,w3,b3])
out3=tf.nn.softmax(tf.nn.relu(tf.nn.relu(x_train@w1+b1)@w2+b2)@w3+b3)
loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_train, logits=out3, axis=-1))
grads=tape.gradient(loss,[w1,b1,w2,b2,w3,b3])lr=0.01
num=5001更新参数(这里就是对之前的那一次进行重复的迭代了)
w=w-lrgrads
w-=lrgrads
tf.assign_sub
all_loss=[]
for step in range(num):
with tf.GradientTape() as tape:
tape.watch([w1,b1,w2,b2,w3,b3])
out3=tf.nn.softmax(tf.nn.relu(tf.nn.relu(x_train@w1+b1)@w2+b2)@w3+b3)
loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_train, logits=out3, axis=-1))
all_loss.append(loss)
grads=tape.gradient(loss,[w1,b1,w2,b2,w3,b3])
#更新参数
w1.assign_sub(lr*grads[0])
b1.assign_sub(lr*grads[1])
w2.assign_sub(lr*grads[2])
b2.assign_sub(lr*grads[3])
w3.assign_sub(lr*grads[4])
b3.assign_sub(lr*grads[5])
#输出
if step%100==0:
print(step,'loss:',float(loss))
plt.plot(all_loss)
测试模型
x_test=tf.convert_to_tensor(x_test,dtype=tf.float32)/255
y_test=tf.convert_to_tensor(y_test,dtype=tf.int32)
x_test=tf.reshape(x_test,[-1,28*28])
x_test.shapeTensorShape([10000, 784])
out3=tf.nn.softmax(tf.nn.relu(tf.nn.relu(x_test@w1+b1)@w2+b2)@w3+b3)
out3
这里我们要对out3预测出来的概率结果取最大值
#用argmax函数
y_predict=tf.math.argmax(out3,axis=-1)
y_predict,y_test
#这里看到预测值与真实值的数据类型不一样,所以后面一定会报错,所以强制改的一样了
y_test=tf.cast(y_test,tf.int64)
y_c=tf.math.equal(y_predict,y_test)
y_c=tf.cast(y_c,tf.int64)
y_cacc=tf.math.reduce_sum(y_c)/len(y_test)
acc.numpy()0.8277
这里我们用的是所有的进行更新,每次使用60000张,速度太慢,我们可以使用小批量随机梯度下降法来改变
#利用batch size
batchDataset=tf.data.Dataset.from_tensor_slices((x_train,y_train)).batch(128)
#构造一个训练集的迭代器
train_iter=iter(batchDataset)
sample=next(train_iter)
sample[0].shape,sample[1].shape