Scrapy框架实战(二):详解 Scrapy 下载器中间件
目录
- 1. 下载器中间件
-
- 1.1 核心方法
- 1.2 内建下载器中间件
- 1.3 案例:设置随机请求头
- 1.4 设置代理 IP
-
- 1.4.1 随机代理 IP 中间件实现网络请求
- 1.5 设置 Cookies
-
- 1.5.1 案例:通过 Cookies 模拟自动登录
- 2. 项目文件目录总结
1. 下载器中间件
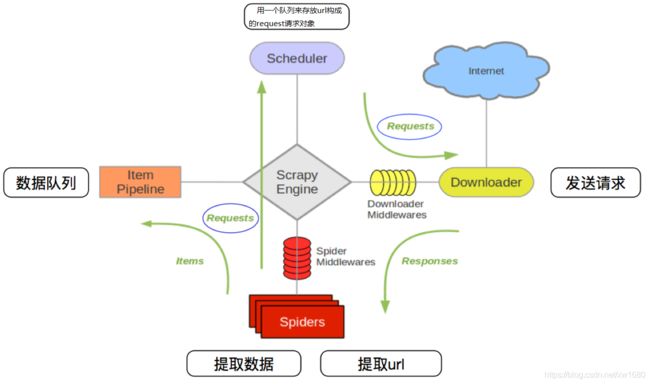
Scrapy 允许使用中间件干预数据的抓取过程,以及完成其他数据处理工作。其中一类非常重要的中间件就是 下载器中间件。下载器中间件 可以对数据的下载和处理过程进行拦截。在 Scrapy 爬虫中,数据下载和处理分为如下两步完成。
- 指定
Web资源的URL,并向服务端发送请求。这一步需要依赖爬虫类的start_urls变量或start_requests方法。 - 当服务端响应
Scrapy爬虫的请求后,就会返回响应数据,这时系统会将响应数据再交由Scrapy爬虫处理,也就是调用爬虫类的请求回调方法,如parse。
1.1 核心方法
下载中间件可以对上面两步进行拦截。当爬虫向服务端发送请求之前,会通过下载器中间件类的 process_request 方法进行拦截,当爬虫处理服务端响应数据之前,会通过下载器中间件类的 process_response 方法进行拦截。除了这两个方法之外,下载器中间件类还有一个 process_exception 方法,用于处理抓取数据过程中的异常。
这 3个 下载器中间件方法的完整描述如下:
(1) process_request(request, spider):

process_request 方法返回值类型不同,产生的效果也不同。下面看一下不同类型返回值的效果:
(1) None:Scrapy 会继续处理该 Request,然后接着执行其他下载器中间件的 process_request 方法,直到下载器向服务端发送请求后,得到响应结果才结束。不同下载器中间件的 process_request 方法会按照优先级顺序依次执行,当所有的下载器中间件的 process_request 都执行完,就会将 Request 送到下载器开始下载数据。
(2) Response 对象:优先级更低的下载器中间件的 process _request 方法不会再继续调用,转而开始调用每个下载器中间件的 process_response 方法。
(3) Request 对象:优先级更低的下载器中间件的 process_request 方法不会再继续调用,并将这个 Request 对象放到调度队列里,其实这就是一个全新的 Request 对象,等待被调度。如果这个 Request 被调度器调度了,那么所有的下载器中间件的 process_request 方法会重新按照顺序执行。
(4) IgnoreRequest 异常:如果 IgnoreRequest 异常抛出,则所有的 Downloader Middleware 的 process_exception 方法会依次执行。如果没有一个方法处理这个异常,那么 Request 的 errorback 方法就会回调。
(2) process_response(request, response, spider):

process_response 方法返回值类型不同,产生的效果也不同。下面看一下不同类型返回值的效果:
(1) Request 对象:优先级更低的下载器中间件的 process_response 方法不会再继续调用,该 Request 对象会重新放到调度队列中等待被调度,相当于一个全新的 Request。然后,该 Request 会被 process_request 方法顺序处理。
(2) Response 对象:更低优先级的下载器中间的 process_response 方法会继续调用,继续对该 Response 对象进行处理。
(3) IgnoreRequest 异常:Request 的 errorback 方法会回调。如果该异常未被处理,会被忽略。
(3) process_exception(request, exception, spider):

process_exception 方法返回值类型不同,产生的效果也不同。下面看一下不同类型返回值的效果:
(1) None:更低优先级的下载器中间件的 process_exception 方法不再被继续调用,每个下载器中间件。
(2) Response 对象:更低优先级的下载器中间件的 process_exception 方法不再被继续调用,每个下载器中间件的 process_response 方法转而被依次调用。
(3) Request 对象:更低优先级的下载器中间件的 process_exception 方法不再被继续调用,该 Request 对象会重新放到调度队列里面等待被调度,相当于一个全新的 Request。然后,该 Request 会被 process_request 方法按优先级顺序处理。
1.2 内建下载器中间件
Scrapy 提供了很多内建的下载器中间件,例如下载超时、自动重定向、设置默认 HTTP 请求头等,这些中间件都在 DOWNLOADER_MIDDLEWARES_BASE 变量中定义,该变量是字典类型,key 表示中间件的名字,value 表示中间件的优先等级。该变量的内容如下:

其他内置中间件写法类似。优先等级是一个数字,数字小的中间件会被优先调用,所以 Scrapy 内建的下载器中间件中,RobotsTxtMiddleware 中间件会被第一个调用,因为该中间件的优先级是100。如果要禁止某个内建的中间件,需要将优先级设置为 None,代码如下:
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None
1.3 案例:设置随机请求头
设置请求头是爬虫程序中必不可少的一项设置,大多数网站都会根据请求头内容指定一些反爬策略,在 Scrapy 框架中如果只是简单地设置一个请求头的话,可以在当前的爬虫文件中以参数的形式添加在网络请求当中。
(1) 使用下面的命令创建一个新的 Scrapy 工程以及爬虫文件。
scrapy startproject middlePro
cd middlePro
scrapy genspider DownloaderSpider www.xxx.com
工程的目录结构如下图所示:
示例代码如下:
import scrapy # 导入框架
class DownloaderspiderSpider(scrapy.Spider):
name = 'DownloaderSpider' # 定义爬虫名称
# allowed_domains = ['www.xxx.com']
def start_requests(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.88 Safari/537.36'
}
return [scrapy.Request('http://httpbin.org/get', headers=self.headers, callback=self.parse)]
def parse(self, response):
print(response.text) # 打印返回的响应信息
在 settings.py 中做如下的设置:

程序运行结果如图所示:
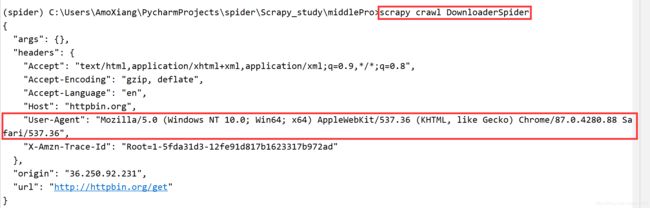
在没有使用指定的请求头时,发送网络请求将使用 Scrapy 默认的请求头信息,信息内容如下:

对于实现多个网络请求时,最好每发送一次请求就更换一个请求头,这样就可以避免请求头的反爬策略。对于这样的需求可以使用自定义中间件的方式实现一个设置随机请求头的中间件。具体实现步骤如下:
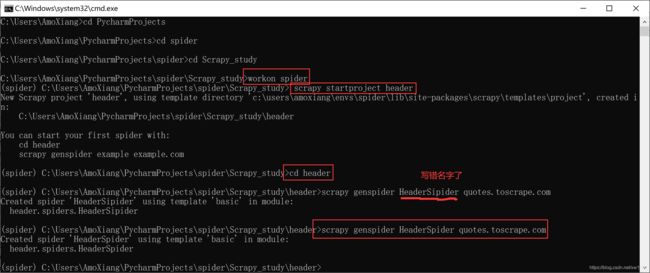
(1) 打开命令窗口,进入到虚拟环境(根据读者实际情况决定),首先通过 scrapy startproject header 创建一个名称为 header 的项目,然后通过 cd header 命令打开项目最外层的文件夹,最后通过 scrapy genspider HeaderSpider quotes.toscrape.com 命令创建名称为 HeaderSpider 的爬虫文件。命令操作如下图所示:
(2) 打开 HeaderSpider 文件,配置测试网络请求的爬虫代码。代码如下:
import scrapy
class HeaderspiderSpider(scrapy.Spider):
name = 'HeaderSpider'
allowed_domains = ['quotes.toscrape.com']
# start_urls = ['http://quotes.toscrape.com/']
def start_requests(self):
# 设置爬取目标的地址
urls = ['http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/']
# 获取所有地址,有几个地址则发送几次请求
for url in urls:
# 发送网络请求
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
# 打印每次网络请求的请求头信息
print(f"请求头信息为: {response.request.headers.get('User-Agent')}")
(3) 安装 fake-useragent 模块,打开 middlewares.py 文件,在该文件中首先导入 fake-useragent 模块中的 User-Agent 类,然后创建 RandomHeaderMiddleware 类并通过 init() 函数进行类的初始化工作。代码如下:
from fake_useragent import UserAgent # 导入请求头类
# 自定义随机请求头的中间件
class RandomHeaderMiddleware(object):
def __init__(self, crawler):
self.ua = UserAgent() # 随机请求头对象
# 如果配置文件中不存在就使用默认的 Google Chrome请求头
self.type = crawler.settings.get('RANDOM_UA_TYPE', 'chrome')
(4) 重写 from_crawler() 方法,在该方法中将 cls() 实例对象返回,代码如下:
@classmethod
def from_crawler(cls, crawler):
return cls(crawler) # 返回 cls() 实例对象
(5) 重写 process_request() 方法,在该方法中实现设置随机生成的请求头信息。代码如下:
# 发送网络请求时调用该方法
def process_request(self, request, spider):
# 设置随机生成的请求头 getattr()函数:获取对象属性的值
request.headers.setdefault('User-Agent', getattr(self.ua, self.type))
(6) 打开 settings.py 文件,在该文件中找到 DOWNLOADER_MIDDLEWARES 配置信息,然后配置自定义的请求头中间件,并把默认生成的下载中间件禁用,最后在配置信息的下面添加请求头类型。代码如下:
ROBOTSTXT_OBEY = False
DOWNLOADER_MIDDLEWARES = {
# 'header.middlewares.HeaderDownloaderMiddleware': 543,
# 启动自定义随机请求头中间件
'header.middlewares.RandomHeaderMiddleware': 400,
# 设为None,禁用默认创建的下载中间件
'header.middlewares.HeaderDownloaderMiddleware': None
}
# 配置请求头类型为随机,此处还设置为ie,firefox以及chrome
RANDOM_UA_TYPE = "random"
LOG_LEVEL = "ERROR"
(7) 启动 HeaderSpider 爬虫,控制台输出两次请求,并分别使用不同的请求信息,如下图所示:

1.4 设置代理 IP
使用代理 IP 实现网络爬虫是有效解决反爬虫的一种方法,如果只是想在 Scrapy 中简单地应用一次代理 IP 时可以使用以下代码:
import scrapy
class HeaderspiderSpider(scrapy.Spider):
name = 'HeaderSpider'
def start_requests(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.88 Safari/537.36'
}
return [
scrapy.Request('http://httpbin.org/get', callback=self.parse,
meta={
'proxy': 'http://123.73.63.178:32223'}, headers=self.headers)]
# 响应信息
def parse(self, response):
print(response.text) # 打印返回的响应信息
程序运行结果如下图所示:

在使用代理 IP 发送网络请求时,需要确保代理 IP 是一个有效的 IP,否则会出现错误。关于 IP 的获取,可以查看博主的 Python每日一练(24)-requests 模块获取免费的代理并检测代理 IP 是否有效 一文。
1.4.1 随机代理 IP 中间件实现网络请求
如果需要发送多个网络请求时,可以自定义一个代理 IP 的中间件,在这个中间件中使用随机的方式从代理 IP 列表内随机抽取一个有效的代理 IP,并通过这个有效的代理 IP 实现网络请求。实现的具体步骤如下:
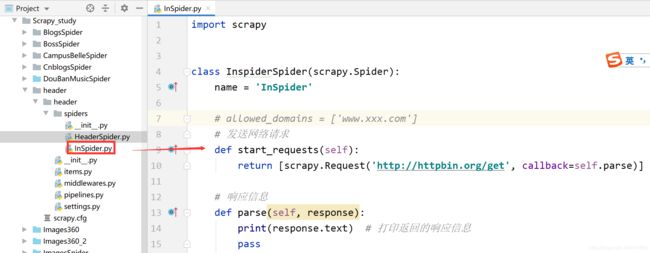
(1) 在 InSpider.py 文件中编写爬虫代码。代码如下:
(2) 打开 middlewares.py 文件,在该文件中创建 IpdemoProxyMiddleware 类,然后定义保存代理 IP 的列表,最后重写 process_request() 方法在该方法中实现发送网络请求时随机抽取有效的代理 IP,代码如下:
import random
class IpdemoProxyMiddleware(object):
# 定义有效的代理IP列表
PROXIES = [
'223.156.165.56:18541',
'183.150.159.146:28803',
'182.38.125.139:42642',
'123.73.209.86:32223',
'123.73.209.34:32223'
]
# 发送网络请求时调用
def process_request(self, request, spider):
proxy = random.choice(self.PROXIES) # 随机抽取代理IP
request.meta['proxy'] = 'http://' + proxy # 设置网络请求所用的代理IP
(3) 在 settings.py 文件中修改 DOWNLOADER_MIDDLEWARES 配置信息,激活自定义随机获取代理 IP 的中间件。如下:

执行两次爬虫文件,程序运行结果如下图所示:
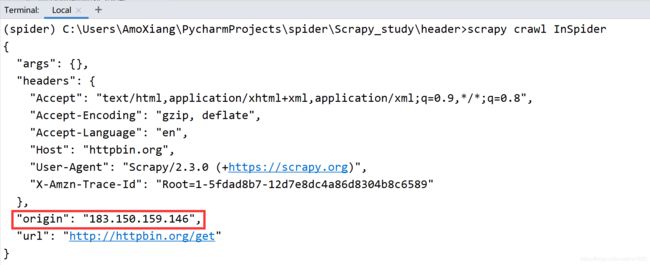
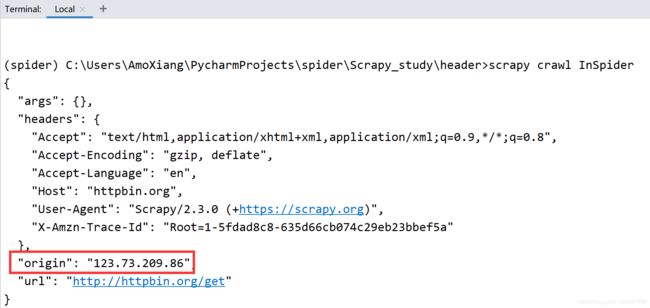
由于上面示例中的代理 IP 均为免费的代理 IP,所以读者在运行示例代码时需要将其替换为最新可用的代理 IP。
1.5 设置 Cookies
熟练使用 Cookies 在编写爬虫程序时是非常重要的,Cookies 代表着用户信息,如果需要爬取登录后网页的信息时,就可以将 Cookies 信息保存,然后在第二次获取登录后的信息时就不需要再次登录了,直接使用 Cookies 进行登录即可。在 Scrapy 中,如果想在 Spider(爬虫) 文件中直接定义并设置 Cookies 参数时,可以参考以下示例代码:
import scrapy
class CookiespiderSpider(scrapy.Spider):
name = 'CookieSpider'
allowed_domains = ['httpbin.org/get'] # 域名列表
start_urls = ['http://httpbin.org/get']
cookies = {
"CookiesDemo": "python"} # 模拟Cookies信息
def start_requests(self):
# 发送网络请求,请求地址为 start_urls 列表中的第一个地址
yield scrapy.Request(url=self.start_urls[0], cookies=self.cookies,
callback=self.parse)
# 响应信息
def parse(self, response):
# 打印结果
print(response.text)
pass
程序运行结果如下图所示:
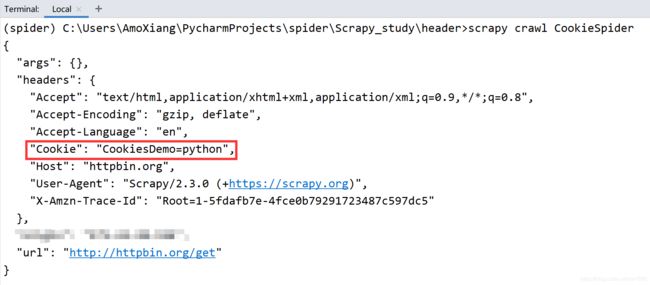
以上示例代码中的 Cookies 是一个模拟测试所使用的信息,并不是一个真实有效的 Cookies 信息,所以在使用时需要将 Cookies 信息设置为爬取网站对应的真实 Cookies。
1.5.1 案例:通过 Cookies 模拟自动登录
在 Scrapy 中除了使用以上示例代码中的方法设置 Cookies 意外,也可以使用自定义中间件的方式设置 Cookies。以爬取某网站登录后的用户名信息为例,具体实现步骤如下:
(1) 在 CookieSpider.py 文件中编写爬虫代码。代码如下:
import scrapy
class CookiespiderSpider(scrapy.Spider):
name = 'CookieSpider'
allowed_domains = ['douban.com'] # 域名列表
start_urls = ['https://www.douban.com/'] # 请求初始化列表
# cookies = {"CookiesDemo": "python"} # 模拟Cookies信息
def start_requests(self):
# 发送网络请求,请求地址为 start_urls 列表中的第一个地址
yield scrapy.Request(url=self.start_urls[0], callback=self.parse)
# 响应信息
def parse(self, response):
# 打印登录后的用户信息名
print(response.xpath('//*[@id="db-global-nav"]/div/div[1]/ul/li[2]/a/span[1]/text()').extract_first())
pass
(2) 在 middlewares.py 文件中,定义用于格式化与设置 Cookies 的中间件,代码如下:
# 自定义Cookies中间件
class CookiesdemoMiddleware(object):
# 初始化
def __init__(self, cookies_str):
self.cookies_str = cookies_str
@classmethod
def from_crawler(cls, crawler):
return cls(
# 获取配置文件中的Cookies信息
cookies_str=crawler.settings.get('COOKIES_DEMO')
)
cookies = {
}
def process_request(self, request, spider):
for cookie in self.cookies_str.split(";"): # 通过;分割Cookies字符串
key, value = cookie.split("=", 1) # 将key与值进行分割
self.cookies.__setitem__(key, value) # 将分割后的数据保存至字典中
request.cookies = self.cookies # 设置格式化以后的Cookies
(4) 在 middlewares.py 文件中,定义随机设置请求头的中间件。代码如下:
from fake_useragent import UserAgent # 导入请求头类
# 自定义随机请求头的中间件
class RandomHeaderMiddleware(object):
def __init__(self, crawler):
self.ua = UserAgent() # 随机请求头对象
# 如果配置文件中不存在就使用默认的 Google Chrome请求头
self.type = crawler.settings.get('RANDOM_UA_TYPE', 'chrome')
@classmethod
def from_crawler(cls, crawler):
return cls(crawler) # 返回 cls() 实例对象
# 发送网络请求时调用该方法
def process_request(self, request, spider):
# 设置随机生成的请求头 getattr()函数:获取对象属性的值
request.headers.setdefault('User-Agent', getattr(self.ua, self.type))
(4) 打开 settings.py 文件,在该文件中首先将 DOWNLOADER_MIDDLEWARES 配置信息中的默认配置信息禁用,然后添加用于处理 Cookies 与随机请求头的配置信息并激活,最后定义从浏览器中获取的 Cookies 信息。代码如下:

程序运行结果如下:
![]()
2. 项目文件目录总结
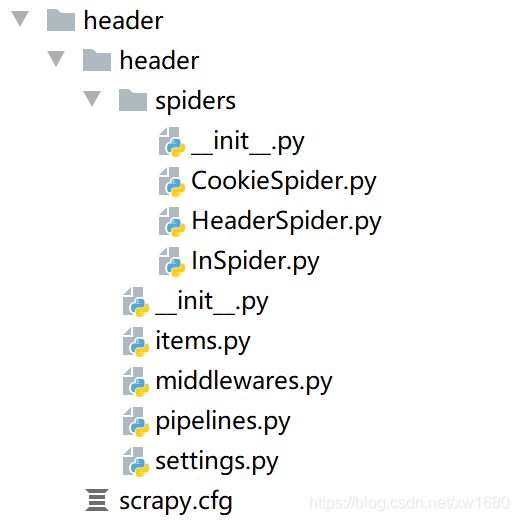
目录结构中的文件说明如下:
- spiders(文件夹):用于创建爬虫文件,编写爬虫规则。
- __init__.py 文件:初始化文件。
- items.py 文件:用于数据的定义,可以寄存处理后的数据。
- middlewares.py:定义爬取时的中间件,其中包括 SpiderMiddleware(爬虫中间件)、DownloaderMiddleware(下载中间件)。
- pipelines.py 文件:用于实现清洗数据、验证数据、保存数据。
- settings.py 文件:整个框架的配置文件,主要包含配置爬虫信息,请求头、中间件等。
- scrapy.cfg 文件:项目部署文件,其中定义了项目的配置文件路径等相关信息。
scrapy.Spider 类中的常用属性与方法含义如下:
- name:用于定义一个爬虫名称的字符串。Scrapy 通过这个爬虫名称进行爬虫的查找,所以这个名称必须是唯一的,不过我们可以生成多个相同的爬虫实例。如果爬取单个网站一般会用这个网站的名称作为爬虫的名称。
- allowed_domains:包含了爬虫允许爬取的域名列表,当OffsiteMiddleware 启用时,域名不在列表中的 URL 不会被爬取。
- start_urls:URL 的初始列表,如果没有指定特定的 URL,爬虫将从该列表中进行爬取。
- custom_settings:这是一个专属于当前爬虫的配置,是一个字典类型的数据,设置该属性会覆盖整个项目的全局,所以在设置该属性时必须在实例化前更新,必须定义为类变量。
- settings:这是一个 settings 对象,通过它,我们可以获取项目的全局设置变量。
- logger:使用 Spider 创建的 Python 日志器。
- start_requests():该方法用于生成网络请求,它必须返回一个可迭代对象。该方法默认使用 start_urls 中的 URL 来生成request,而 request 的请求方式为 GET,如果我们想通过 POST 方式请求网页时,可以使用 FormRequest() 重写该方法。
- parse():如果 response 没有指定回调函数时,该方法是 Scrapy 处理 response 的默认方法。该方法负责处理 response 并返回处理的数据和下一步请求,然后返回一个包含 request 或 Item 的可迭代对象。
- closed():当爬虫关闭时,该函数会被调用。该方法用于代替监听工作,可以定义释放资源或是收尾操作。