论文阅读《Document-level Relation Extraction as Semantic Segmentation》(2021,DocRED最新SOTA)
目录
- 0. 简介
- 1. 数据
- 2. 基线模型
- 3. DocuNet
-
- 3.1 总体介绍
- 3.2. 编码模型
- 3.3 U-net
- 3.4 分类模型
- 4. 总结
0. 简介
这篇论文提出了一种新的网络结构DocuNet,进行关系抽取,主要解决的是长文本中的关系抽取问题,并且在DocRED数据集上达到了新的SOTA结果。
本文将对这篇文章的思想进行介绍,尽可能地讲清楚其中的实现细节,但是由于这个论文比较新,代码也暂时没有开源,没办法看到一些具体的实现细节,所以这篇解读是结合了我个人的理解的部分的,其中可能与作者原意有偏差,仅供参考。如果发现我的理解有明显不正确的地方,还请在评论区指正。
后续如果论文的代码开源了的话,可能会介绍一下代码的使用(这个不确定,要看博主的时间,最近还是有点忙)。目前这个项目的代码两天前已经开源了,我会抽空去看代码。
论文地址:https://arxiv.org/abs/2106.03618
项目地址:https://github.com/zjunlp/DocuNet
1. 数据
DocRED数据集是来自维基百科的一个大规模的关系抽取数据集,其中包括人工标注和远程监督两部分数据,数据质量较高。由于其中涉及到大量的篇章级关系,以及诸多共指问题,使得常规的句子级关系抽取模型在这个数据集上很难达到很好的效果。这篇论文主要的工作就在于采用了特征图的方式,使得模型能够更好地捕捉到长距离的特征。
关于DocRED数据集的介绍,我主要参考了这篇博客。
出了DocRED数据集,这篇论文所采用的方法还在CDR和GDA两大数据集上实现了SOTA。
2. 基线模型
这里所说的基线模型是指DocRED数据集的基线模型。这部分不是本文的重点所以不做太多介绍,基线模型给出了包括LSTM在内的四种编码器,通过对样本进行词级特征、字母级特征等特征工程,将特征给入CNN或RNN模型实现编码,最后经过一个双线性层进行预测。
3. DocuNet
第一眼看到DocuNet这个模型的时候,有种让人耳目一新的感觉,因为最近接触到的信息抽取方向的论文,多数是针对标注策略,对来自多源的数据的特征进行融合,或是采用新的embedding方法来实现提升的,而这篇文章从一个我没有想过的角度提出了改进。通过引入了CV中感受野的概念,将实体与实体的关系用attention矩阵表示出来,再经过一个U型网络转化为“特征图”,巧妙地把将语义分割中的思想引入了信息抽取任务。
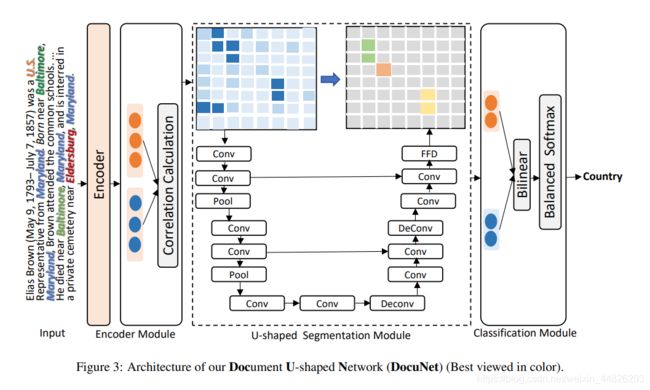
3.1 总体介绍
假设文档d中包含若干实体 ,任务是抽取其中所包含的关系(es, eo)。
为了表示实体之间的关系,定义一个N*N的矩阵Y,其中的每一项Ys,o,表征实体es与实体eo之间的关系,这个矩阵Y称作实体级(entity-level)的关系矩阵。通过相关性估计,得到一个特征图,并且将这个特征图(fig3中的左侧矩阵)看做是一个图片(image),这样一来,对于图片中的每一个位置,都可以将其看做是一个像素,来进行像素级(pix-level)的语义分割任务。直观来讲,采用这种结构的优势在于,实体级的关系矩阵,可以捕获来自全文的信息(因为实体是全文的全部实体,而非局限于某个句子),从而提升模型总体的表现。
3.2. 编码模型
给定一篇文档d = [xt], t = 1, …, L,在实体mention的开始和结束为位置分别插入特殊标记符< e >和< /e >。
编码后的结果记作:
H = [h1, h2, …, hL] = Encoder([x1, x2, …, xL])
然后采用平滑版的max pooling,logsumexp,对实体的编码结果进行计算,得到实体的编码表示,记作ei。
然后有了所有实体的编码之后,可以利用这个编码计算一个实体级的相关性关系矩阵。
采用两种策略计算实体之间的相关性度。
第一种是基于相似度的方法。
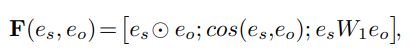
第一项是两个实体的编码结果的点乘,第二项是余弦相似度,第三项是双线性函数。然后把三项concat。
第二种方法是基于上下文的方法。
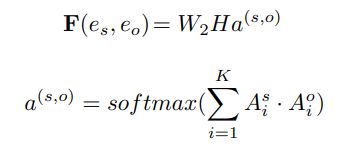 a是实体级的attention权重,Ais 表示第i个token对实体s的权重。W是可训练的权重,K是transformer的头数。
a是实体级的attention权重,Ais 表示第i个token对实体s的权重。W是可训练的权重,K是transformer的头数。
3.3 U-net
将3.2中得到的NND的矩阵F,看做是一个D通道的特征图,N是实体的数量。然后把它看做是一个语义分割的任务。
然后采用U-net做特征抽取,U-net中包含了两个下采样模块,和两个上采样模块。下采样模块包含了两个卷积和最大池化。每经过一个下采样模块,通道数会加倍。反之,每经过一个上采样模块,通道数会减半。
采用U-net的主要目的是为了提高每个像素(实体)对全局信息的捕获能力,从而解决距离较远的实体之间的关系预测的问题。
最后把全局信息和局部信息放在一起:
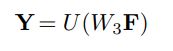
其中可训练参数W3的目的是将F的维度从D降到D’。
3.4 分类模型
给定实体s和o的编码es,eo,以及实体级的关系矩阵Y,获得它们的表示z,并且采用一个双线性函数s和o之间的关系概率P,完成预测。

4. 总结
总结就不总结了,等代码放出来之后看完代码再总结吧(也有可能因为偷懒就不总结了),总之这篇文章给我的启发还是很大的,尤其是对于全局信息的获取,提供了一种不错的思路。