optee的内存管理的详细介绍
文章目录
-
-
- 1.1、optee的内存管理
-
- 1.1.1 optee的内存layout
- 1.1.2 optee内存管理
-
- 1、 相关宏的介绍
-
- (1)、__register_memory 注册一般的内存
- (2)、register_sdp_mem 注册sdp内存
- (3)、CFG_MMAP_REGIONS
- 2、 内存Type
- 3、 内存的注册
- 4、 函数剖析
-
- (1)、init_mem_map
- (2)、core_init_mmu_tables
- (3)、core_init_mmu_regs
- 5、 TEE RAM的注册和使用
- 6、 TA RAM
- 7、malloc函数的剖析
- 1.1.3、optee中的MMU使用
-
- (1)、Optee中的TTBR0/TTBR1
- (2)、optee中的页表
- (3)、tee内核页表基地址的配置
- (4)、tee内核页表填充
- (5)、virt_to_phys转换的过程的举例
- 1.1.2、optee内存申请
- 1.1.3 总结
-
★★★ 友情链接 : 个人博客导读首页—点击此处 ★★★
1.1、optee的内存管理
1.1.1 optee的内存layout
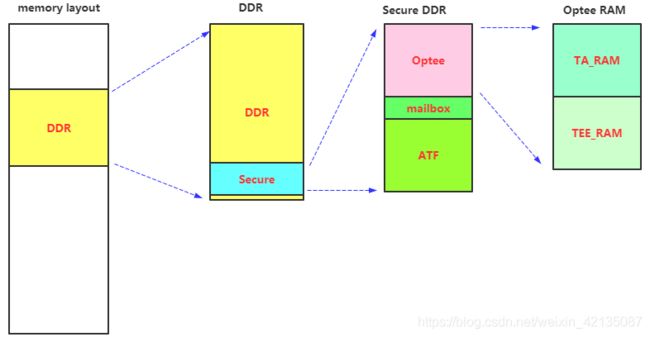
我们查看kern.ld.S文件,程序的起始地址,就是TEE_RAM_START
(core_mmu.h)
//---------------------------------------------我们没有定义TEE_LOAD_ADDR, 所以TEE_LOAD_ADDR就等于TEE_RAM_START
#ifndef TEE_LOAD_ADDR
#define TEE_LOAD_ADDR TEE_RAM_START
#endif
(kern.ld.S)
/*
* TEE_RAM_VA_START: The start virtual address of the TEE RAM
* TEE_TEXT_VA_START: The start virtual address of the OP-TEE text
*/
#define TEE_RAM_VA_START TEE_RAM_START
#define TEE_TEXT_VA_START (TEE_RAM_VA_START + \
(TEE_LOAD_ADDR - TEE_RAM_START)) //-----------------TEE_TEXT_VA_START = TEE_RAM_VA_START = TEE_RAM_START
OUTPUT_FORMAT(CFG_KERN_LINKER_FORMAT)
OUTPUT_ARCH(CFG_KERN_LINKER_ARCH)
ENTRY(_start)
SECTIONS
{
. = TEE_TEXT_VA_START;
#ifdef ARM32
ASSERT(!(TEE_TEXT_VA_START & 31), "text start should align to 32bytes")
#endif
#ifdef ARM64
ASSERT(!(TEE_TEXT_VA_START & 127), "text start should align to 128bytes")
#endif
__text_start = .;
1.1.2 optee内存管理
1、 相关宏的介绍
在TEE中,物理块都是由core_mmu_phys_mem结构体来描述的, core_mmu_phys_mem描述的是一个很大的连续的物理块
struct core_mmu_phys_mem {
const char *name;
enum teecore_memtypes type;
__extension__ union {
#if __SIZEOF_LONG__ != __SIZEOF_PADDR__
struct {
uint32_t lo_addr;
uint32_t hi_addr;
};
#endif
paddr_t addr;
};
__extension__ union {
#if __SIZEOF_LONG__ != __SIZEOF_PADDR__
struct {
uint32_t lo_size;
uint32_t hi_size;
};
#endif
paddr_size_t size;
};
};
物理块内存又分为phys_mem和sdp_mem两大类:
phys_mem物理块内存的结构体描述(core_mmu_phys_mem)放在phys_mem section段
sdp_mem物理块内存的结构体描述(core_mmu_phys_mem)放在sdp_mem section段
(1)、__register_memory 注册一般的内存
__register_memory2其实就算在section段定义了一个结构体,该结构体成员addr/size/type/name指向参数传来的
#define __register_memory2(_name, _type, _addr, _size, _section, _id) \
static const struct core_mmu_phys_mem __phys_mem_ ## _id \
__used __section(_section) = \
{
.name = _name, .type = _type, .addr = _addr, .size = _size }
#define __register_memory1(name, type, addr, size, section, id) \
__register_memory2(name, type, addr, size, #section, id)
#define register_phys_mem(type, addr, size) \
__register_memory1(#addr, (type), (addr), (size), \
phys_mem_map_section, __COUNTER__)
总结一下register_phys_mem,其实就是在section段定义了一个结构体,该结构体的type/addr/size遍历指向宏定义传来的.
(2)、register_sdp_mem 注册sdp内存
register_phys_mem,其实就是在section段定义了一个结构体,该结构体的addr/size遍历指向宏定义传来的, 而TYPE固定写死MEM_AREA_SDP_MEM
#ifdef CFG_SECURE_DATA_PATH
#define register_sdp_mem(addr, size) \
__register_memory1(#addr, MEM_AREA_SDP_MEM, (addr), (size), \
phys_sdp_mem_section, __COUNTER__)
#else
#define register_sdp_mem(addr, size) \
static int CONCAT(__register_sdp_mem_unused, __COUNTER__) \
__unused
#endif
(3)、CFG_MMAP_REGIONS
optee_os\core\arch\arm\arm.mk) : CFG_MMAP_REGIONS ?= 13 \\默认值,默认为啥是13,因为在TEE中有至少13种类内存
optee_os\core\arch\arm\plat-xxxx\conf.mk) : CFG_MMAP_REGIONS := 127 \平台的配置值
2、 内存Type
enum teecore_memtypes {
MEM_AREA_END = 0,
MEM_AREA_TEE_RAM,
MEM_AREA_TEE_RAM_RX,
MEM_AREA_TEE_RAM_RO,
MEM_AREA_TEE_RAM_RW,
MEM_AREA_TEE_COHERENT,
MEM_AREA_TEE_ASAN,
MEM_AREA_TA_RAM,
MEM_AREA_NSEC_SHM,
MEM_AREA_RAM_NSEC,
MEM_AREA_RAM_SEC,
MEM_AREA_IO_NSEC,
MEM_AREA_IO_SEC,
MEM_AREA_RES_VASPACE,
MEM_AREA_SHM_VASPACE,
MEM_AREA_TA_VASPACE,
MEM_AREA_PAGER_VASPACE,
MEM_AREA_SDP_MEM,
MEM_AREA_DDR_OVERALL,
MEM_AREA_MAXTYPE
};
3、 内存的注册
core/arch/arm/mm/core_mmu.c
#if defined(CFG_SECURE_DATA_PATH)
#ifdef CFG_TEE_SDP_MEM_BASE
register_sdp_mem(CFG_TEE_SDP_MEM_BASE, CFG_TEE_SDP_MEM_SIZE); //----------------------注册sdp RAM
#endif
#ifdef TEE_SDP_TEST_MEM_BASE
register_sdp_mem(TEE_SDP_TEST_MEM_BASE, TEE_SDP_TEST_MEM_SIZE); //----------------------注册sdp RAM
#endif
#endif
#ifdef CFG_CORE_RWDATA_NOEXEC
//----------------------------------------------------------------------------------------------------注册TEE RAM
register_phys_mem_ul(MEM_AREA_TEE_RAM_RO, TEE_RAM_START,VCORE_UNPG_RX_PA - TEE_RAM_START);
register_phys_mem_ul(MEM_AREA_TEE_RAM_RX, VCORE_UNPG_RX_PA, VCORE_UNPG_RX_SZ);
register_phys_mem_ul(MEM_AREA_TEE_RAM_RO, VCORE_UNPG_RO_PA, VCORE_UNPG_RO_SZ);
register_phys_mem_ul(MEM_AREA_TEE_RAM_RW, VCORE_UNPG_RW_PA, VCORE_UNPG_RW_SZ);
#ifdef CFG_WITH_PAGER
register_phys_mem_ul(MEM_AREA_TEE_RAM_RX, VCORE_INIT_RX_PA, VCORE_INIT_RX_SZ);
register_phys_mem_ul(MEM_AREA_TEE_RAM_RO, VCORE_INIT_RO_PA, VCORE_INIT_RO_SZ);
#endif /*CFG_WITH_PAGER*/
#else /*!CFG_CORE_RWDATA_NOEXEC*/
//----------------------------------------------------------------------------------------------------注册TEE RAM
register_phys_mem(MEM_AREA_TEE_RAM, TEE_RAM_START, TEE_RAM_PH_SIZE);
#endif /*!CFG_CORE_RWDATA_NOEXEC*/
#if defined(CFG_CORE_SANITIZE_KADDRESS) && defined(CFG_WITH_PAGER)
/* Asan ram is part of MEM_AREA_TEE_RAM_RW when pager is disabled */
register_phys_mem_ul(MEM_AREA_TEE_ASAN, ASAN_MAP_PA, ASAN_MAP_SZ);
#endif
register_phys_mem(MEM_AREA_TA_RAM, TA_RAM_START, TA_RAM_SIZE); //----------------------注册TA RAM
register_phys_mem(MEM_AREA_NSEC_SHM, TEE_SHMEM_START, TEE_SHMEM_SIZE);//----------------------注册NSEC_SHM
core/arch/arm/plat-xxx/main.c
register_sdp_mem(DRM_VPU_BASE, DRM_VPU_SIZE);//----------------------注册sdp RAM
register_sdp_mem(DRM_DPU_BASE, DRM_DPU_SIZE);//----------------------注册sdp RAM
register_phys_mem(DEVICE0_TYPE, DEVICE0_PA_BASE, DEVICE0_SIZE); //----------------------注册IO_SEC RAM
register_phys_mem(DEVICE1_TYPE, DEVICE1_PA_BASE, DEVICE1_SIZE); //----------------------注册IO_SEC RAM
register_phys_mem(DEVICE2_TYPE, DEVICE2_PA_BASE, DEVICE2_SIZE); //----------------------注册IO_SEC RAM
register_phys_mem(DEVICE3_TYPE, DEVICE3_PA_BASE, DEVICE3_SIZE); //----------------------注册IO_SEC RAM
4、 函数剖析
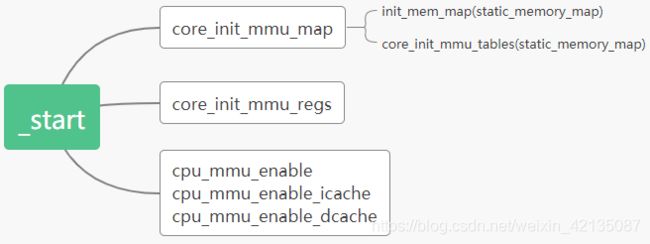
(1)、init_mem_map
init_mem_map(static_memory_map, ARRAY_SIZE(static_memory_map));
static void init_mem_map(struct tee_mmap_region *memory_map, size_t num_elems)
{
const struct core_mmu_phys_mem *mem;
struct tee_mmap_region *map;
size_t last = 0;
size_t __maybe_unused count = 0;
vaddr_t va;
vaddr_t end;
bool __maybe_unused va_is_secure = true; /* any init value fits */
for (mem = &__start_phys_mem_map_section; //--------扫描phys_mem section段中所有结构体,并将其加入到static_memory_map数组中
mem < &__end_phys_mem_map_section; mem++) {
struct core_mmu_phys_mem m = *mem;
/* Discard null size entries */
if (!m.size)
continue;
/* Only unmapped virtual range may have a null phys addr */
assert(m.addr || !core_mmu_type_to_attr(m.type));
if (m.type == MEM_AREA_IO_NSEC || m.type == MEM_AREA_IO_SEC) {
m.addr = ROUNDDOWN(m.addr, CORE_MMU_PGDIR_SIZE);
m.size = ROUNDUP(m.size + (mem->addr - m.addr),
CORE_MMU_PGDIR_SIZE);
}
add_phys_mem(memory_map, num_elems, &m, &last);
}
#ifdef CFG_SECURE_DATA_PATH
verify_special_mem_areas(memory_map, num_elems, //--------扫描sdp_mem section段中所有结构体,并将其加入到static_memory_map数组中
&__start_phys_sdp_mem_section,
&__end_phys_sdp_mem_section, "SDP");
check_sdp_intersection_with_nsec_ddr();
#endif
verify_special_mem_areas(memory_map, num_elems,
&__start_phys_nsec_ddr_section,
&__end_phys_nsec_ddr_section, "NSEC DDR");
add_va_space(memory_map, num_elems, MEM_AREA_RES_VASPACE,
CFG_RESERVED_VASPACE_SIZE, &last);
add_va_space(memory_map, num_elems, MEM_AREA_SHM_VASPACE,
SHM_VASPACE_SIZE, &last);
memory_map[last].type = MEM_AREA_END;
/*
* Assign region sizes, note that MEM_AREA_TEE_RAM always uses
* SMALL_PAGE_SIZE if paging is enabled.
*/
for (map = memory_map; !core_mmap_is_end_of_table(map); map++) {
paddr_t mask = map->pa | map->size;
if (!(mask & CORE_MMU_PGDIR_MASK))
map->region_size = CORE_MMU_PGDIR_SIZE;
else if (!(mask & SMALL_PAGE_MASK))
map->region_size = SMALL_PAGE_SIZE;
else
panic("Impossible memory alignment");
#ifdef CFG_WITH_PAGER
if (map_is_tee_ram(map))
map->region_size = SMALL_PAGE_SIZE;
#endif
}
/*
* To ease mapping and lower use of xlat tables, sort mapping
* description moving small-page regions after the pgdir regions.
*/
qsort(memory_map, last, sizeof(struct tee_mmap_region),
cmp_mmap_by_bigger_region_size);
#if !defined(CFG_WITH_LPAE)
/*
* 32bit MMU descriptors cannot mix secure and non-secure mapping in
* the same level2 table. Hence sort secure mapping from non-secure
* mapping.
*/
for (count = 0, map = memory_map; map_is_pgdir(map); count++, map++)
;
qsort(memory_map + count, last - count, sizeof(struct tee_mmap_region),
cmp_mmap_by_secure_attr);
#endif
/*
* Map flat mapped addresses first.
* 'va' (resp. 'end') will store the lower (reps. higher) address of
* the flat-mapped areas to later setup the virtual mapping of the non
* flat-mapped areas.
*/
va = (vaddr_t)~0UL;
end = 0;
for (map = memory_map; !core_mmap_is_end_of_table(map); map++) {
if (!map_is_flat_mapped(map))
continue;
map->attr = core_mmu_type_to_attr(map->type);
map->va = map->pa;
va = MIN(va, ROUNDDOWN(map->va, map->region_size));
end = MAX(end, ROUNDUP(map->va + map->size, map->region_size));
}
assert(va >= TEE_RAM_VA_START);
assert(end <= TEE_RAM_VA_START + TEE_RAM_VA_SIZE);
add_pager_vaspace(memory_map, num_elems, va, &end, &last);
assert(!((va | end) & SMALL_PAGE_MASK));
if (core_mmu_place_tee_ram_at_top(va)) {
/* Map non-flat mapped addresses below flat mapped addresses */
for (map = memory_map; !core_mmap_is_end_of_table(map); map++) {
if (map->va)
continue;
#if !defined(CFG_WITH_LPAE)
if (va_is_secure != map_is_secure(map)) {
va_is_secure = !va_is_secure;
va = ROUNDDOWN(va, CORE_MMU_PGDIR_SIZE);
}
#endif
map->attr = core_mmu_type_to_attr(map->type);
va -= map->size;
va = ROUNDDOWN(va, map->region_size);
map->va = va;
}
} else {
/* Map non-flat mapped addresses above flat mapped addresses */
va = end;
for (map = memory_map; !core_mmap_is_end_of_table(map); map++) {
if (map->va)
continue;
#if !defined(CFG_WITH_LPAE)
if (va_is_secure != map_is_secure(map)) {
va_is_secure = !va_is_secure;
va = ROUNDUP(va, CORE_MMU_PGDIR_SIZE);
}
#endif
map->attr = core_mmu_type_to_attr(map->type);
va = ROUNDUP(va, map->region_size);
map->va = va;
va += map->size;
}
}
qsort(memory_map, last, sizeof(struct tee_mmap_region),
cmp_mmap_by_lower_va);
dump_mmap_table(memory_map);
}
(2)、core_init_mmu_tables
void core_init_mmu_tables(struct tee_mmap_region *mm)
{
uint64_t max_va = 0;
size_t n;
#ifdef CFG_CORE_UNMAP_CORE_AT_EL0
COMPILE_TIME_ASSERT(CORE_MMU_L1_TBL_OFFSET ==
sizeof(l1_xlation_table) / 2);
#endif
max_pa = get_nsec_ddr_max_pa();
for (n = 0; !core_mmap_is_end_of_table(mm + n); n++) {
paddr_t pa_end;
vaddr_t va_end;
debug_print(" %010" PRIxVA " %010" PRIxPA " %10zx %x",
mm[n].va, mm[n].pa, mm[n].size, mm[n].attr);
if (!IS_PAGE_ALIGNED(mm[n].pa) || !IS_PAGE_ALIGNED(mm[n].size))
panic("unaligned region");
pa_end = mm[n].pa + mm[n].size - 1;
va_end = mm[n].va + mm[n].size - 1;
if (pa_end > max_pa)
max_pa = pa_end;
if (va_end > max_va)
max_va = va_end;
}
/* Clear table before use */
memset(l1_xlation_table, 0, sizeof(l1_xlation_table));
for (n = 0; !core_mmap_is_end_of_table(mm + n); n++)
if (!core_mmu_is_dynamic_vaspace(mm + n))
core_mmu_map_region(mm + n); //---------创建当前cpu的内存页表,保存在l1_xlation_table[0][get_core_pos()]数组中
/*
* Primary mapping table is ready at index `get_core_pos()`
* whose value may not be ZERO. Take this index as copy source.
*/
for (n = 0; n < CFG_TEE_CORE_NB_CORE; n++) {
if (n == get_core_pos())
continue;
memcpy(l1_xlation_table[0][n],
l1_xlation_table[0][get_core_pos()], //---------将当前cpu的内存页表拷贝到其它cpu页表
XLAT_ENTRY_SIZE * NUM_L1_ENTRIES);
}
for (n = 1; n < NUM_L1_ENTRIES; n++) {
if (!l1_xlation_table[0][0][n]) {
user_va_idx = n;
break;
}
}
assert(user_va_idx != -1);
COMPILE_TIME_ASSERT(CFG_LPAE_ADDR_SPACE_SIZE > 0);
assert(max_va < CFG_LPAE_ADDR_SPACE_SIZE);
}
(3)、core_init_mmu_regs
void core_init_mmu_regs(void)
{
uint64_t mair;
uint64_t tcr;
paddr_t ttbr0;
uint64_t ips = calc_physical_addr_size_bits(max_pa);
ttbr0 = virt_to_phys(l1_xlation_table[0][get_core_pos()]); //---------获取当前cpu页表基地址
mair = MAIR_ATTR_SET(ATTR_DEVICE, ATTR_DEVICE_INDEX);
mair |= MAIR_ATTR_SET(ATTR_IWBWA_OWBWA_NTR, ATTR_IWBWA_OWBWA_NTR_INDEX);
write_mair_el1(mair);
tcr = TCR_RES1;
tcr |= TCR_XRGNX_WBWA << TCR_IRGN0_SHIFT;
tcr |= TCR_XRGNX_WBWA << TCR_ORGN0_SHIFT;
tcr |= TCR_SHX_ISH << TCR_SH0_SHIFT;
tcr |= ips << TCR_EL1_IPS_SHIFT;
tcr |= 64 - __builtin_ctzl(CFG_LPAE_ADDR_SPACE_SIZE);
/* Disable the use of TTBR1 */ //------------------------------------关闭TTBR1
tcr |= TCR_EPD1;
/*
* TCR.A1 = 0 => ASID is stored in TTBR0
* TCR.AS = 0 => Same ASID size as in Aarch32/ARMv7
*/
write_tcr_el1(tcr);
write_ttbr0_el1(ttbr0); //-------将页表基地址写入到TTBR0
write_ttbr1_el1(0);
}
5、 TEE RAM的注册和使用
TEE RAM的注册 :将TEE_RAM_START地址注册为MEM_AREA_TEE_RAM内存
类型:MEM_AREA_TEE_RAM, 地址 : TEE_RAM_START
#ifdef CFG_CORE_RWDATA_NOEXEC
register_phys_mem_ul(MEM_AREA_TEE_RAM_RO, TEE_RAM_START, VCORE_UNPG_RX_PA - TEE_RAM_START);
register_phys_mem_ul(MEM_AREA_TEE_RAM_RX, VCORE_UNPG_RX_PA, VCORE_UNPG_RX_SZ);
register_phys_mem_ul(MEM_AREA_TEE_RAM_RO, VCORE_UNPG_RO_PA, VCORE_UNPG_RO_SZ);
register_phys_mem_ul(MEM_AREA_TEE_RAM_RW, VCORE_UNPG_RW_PA, VCORE_UNPG_RW_SZ);
#ifdef CFG_WITH_PAGER
register_phys_mem_ul(MEM_AREA_TEE_RAM_RX, VCORE_INIT_RX_PA, VCORE_INIT_RX_SZ);
register_phys_mem_ul(MEM_AREA_TEE_RAM_RO, VCORE_INIT_RO_PA, VCORE_INIT_RO_SZ);
#endif /*CFG_WITH_PAGER*/
#else /*!CFG_CORE_RWDATA_NOEXEC*/
register_phys_mem(MEM_AREA_TEE_RAM, TEE_RAM_START, TEE_RAM_PH_SIZE); -------TEE RAM就算TEE_RAM_START块内存
#endif /*!CFG_CORE_RWDATA_NOEXEC*/
TEE_RAM_START内存是在平台config中配置的:
core\arch\arm\plat-xxx\Platform_config.h : #define TEE_RAM_START TZDRAM_BASE
而其它RO/RW/RX的这些物理地址,都是在section段定义的
core\arch\arm\include\kernel\linker.h
#define VCORE_UNPG_RX_PA ((unsigned long)__vcore_unpg_rx_start)
#define VCORE_UNPG_RX_SZ ((size_t)__vcore_unpg_rx_size)
#define VCORE_UNPG_RO_PA ((unsigned long)__vcore_unpg_ro_start)
#define VCORE_UNPG_RO_SZ ((size_t)__vcore_unpg_ro_size)
#define VCORE_UNPG_RW_PA ((unsigned long)__vcore_unpg_rw_start)
#define VCORE_UNPG_RW_SZ ((size_t)__vcore_unpg_rw_size)
#define VCORE_INIT_RX_PA ((unsigned long)__vcore_init_rx_start)
#define VCORE_INIT_RX_SZ ((size_t)__vcore_init_rx_size)
#define VCORE_INIT_RO_PA ((unsigned long)__vcore_init_ro_start)
#define VCORE_INIT_RO_SZ ((size_t)__vcore_init_ro_size)
core\arch\arm\kernel\kern.ld.S
/* Unpaged read-only memories */
__vcore_unpg_rx_start = __flatmap_unpg_rx_start;
__vcore_unpg_ro_start = __flatmap_unpg_ro_start;
#ifdef CFG_CORE_RODATA_NOEXEC
__vcore_unpg_rx_size = __flatmap_unpg_rx_size;
__vcore_unpg_ro_size = __flatmap_unpg_ro_size;
#else
__vcore_unpg_rx_size = __flatmap_unpg_rx_size + __flatmap_unpg_ro_size;
__vcore_unpg_ro_size = 0;
#endif
/* Unpaged read-write memory */
__vcore_unpg_rw_start = __flatmap_unpg_rw_start;
__vcore_unpg_rw_size = __flatmap_unpg_rw_size;
6、 TA RAM
TA RAM的注册:
register_phys_mem(MEM_AREA_TA_RAM, TA_RAM_START, TA_RAM_SIZE);
在teecore_init_ta_ram的时候,获取TA RAM的物理地址,写入到tee_mm_sec_ddr全局遍历中
_start – >generic_boot_init_primary—>init_primary_helper()—>init_runtime()—>teecore_init_ta_ram()
void teecore_init_ta_ram(void)
{
vaddr_t s;
vaddr_t e;
paddr_t ps;
paddr_t pe;
/* get virtual addr/size of RAM where TA are loaded/executedNSec
* shared mem allcated from teecore */
core_mmu_get_mem_by_type(MEM_AREA_TA_RAM, &s, &e);
ps = virt_to_phys((void *)s);
pe = virt_to_phys((void *)(e - 1)) + 1;
if (!ps || (ps & CORE_MMU_USER_CODE_MASK) ||
!pe || (pe & CORE_MMU_USER_CODE_MASK))
panic("invalid TA RAM");
/* extra check: we could rely on core_mmu_get_mem_by_type() */
if (!tee_pbuf_is_sec(ps, pe - ps))
panic("TA RAM is not secure");
if (!tee_mm_is_empty(&tee_mm_sec_ddr))
panic("TA RAM pool is not empty");
/* remove previous config and init TA ddr memory pool */
tee_mm_final(&tee_mm_sec_ddr);
tee_mm_init(&tee_mm_sec_ddr, ps, pe, CORE_MMU_USER_CODE_SHIFT,
TEE_MM_POOL_NO_FLAGS);
}
tee_mm_sec_ddr的使用
当调用alloc_area分配内存时
(tee_pager.c)
static struct tee_pager_area *alloc_area(struct pgt *pgt,
vaddr_t base, size_t size,
uint32_t flags, const void *store,
const void *hashes)
{
......
mm_store = tee_mm_alloc(&tee_mm_sec_ddr, size);
......
}
(tee_svc.c)
static TEE_Result alloc_temp_sec_mem(size_t size, struct mobj **mobj,
uint8_t **va)
{
/* Allocate section in secure DDR */
#ifdef CFG_PAGED_USER_TA
*mobj = mobj_seccpy_shm_alloc(size);
#else
*mobj = mobj_mm_alloc(mobj_sec_ddr, size, &tee_mm_sec_ddr);
#endif
if (!*mobj)
return TEE_ERROR_GENERIC;
*va = mobj_get_va(*mobj, 0);
return TEE_SUCCESS;
}
(user_ta.c)
static struct mobj *alloc_ta_mem(size_t size)
{
#ifdef CFG_PAGED_USER_TA
return mobj_paged_alloc(size);
#else
struct mobj *mobj = mobj_mm_alloc(mobj_sec_ddr, size, &tee_mm_sec_ddr);
if (mobj)
memset(mobj_get_va(mobj, 0), 0, size);
return mobj;
#endif
}
(entry_std.c)
static TEE_Result default_mobj_init(void)
{
shm_mobj = mobj_phys_alloc(default_nsec_shm_paddr,
default_nsec_shm_size, SHM_CACHE_ATTRS,
CORE_MEM_NSEC_SHM);
if (!shm_mobj)
panic("Failed to register shared memory");
mobj_sec_ddr = mobj_phys_alloc(tee_mm_sec_ddr.lo,
tee_mm_sec_ddr.hi - tee_mm_sec_ddr.lo,
SHM_CACHE_ATTRS, CORE_MEM_TA_RAM);
if (!mobj_sec_ddr)
panic("Failed to register secure ta ram");
mobj_tee_ram = mobj_phys_alloc(TEE_RAM_START,
VCORE_UNPG_RW_PA + VCORE_UNPG_RW_SZ -
TEE_RAM_START,
TEE_MATTR_CACHE_CACHED,
CORE_MEM_TEE_RAM);
if (!mobj_tee_ram)
panic("Failed to register tee ram");
#ifdef CFG_SECURE_DATA_PATH
sdp_mem_mobjs = core_sdp_mem_create_mobjs();
if (!sdp_mem_mobjs)
panic("Failed to register SDP memory");
#endif
return TEE_SUCCESS;
}
driver_init_late(default_mobj_init);
7、malloc函数的剖析
malloc/calloc函数,其实就算在malloc_poolset全局变量中,分配内存
void *malloc(size_t size)
{
void *p;
uint32_t exceptions = malloc_lock();
p = raw_malloc(0, 0, size, &malloc_poolset);
malloc_unlock(exceptions);
return p;
}
void free(void *ptr)
{
uint32_t exceptions = malloc_lock();
raw_free(ptr, &malloc_poolset);
malloc_unlock(exceptions);
}
void *calloc(size_t nmemb, size_t size)
{
void *p;
uint32_t exceptions = malloc_lock();
p = raw_calloc(0, 0, nmemb, size, &malloc_poolset);
malloc_unlock(exceptions);
return p;
}
而malloc_poolset是从哪里来的呢? 是别人调用malloc_add_pool添加进来的
void malloc_add_pool(void *buf, size_t len)
{
void *p;
size_t l;
uint32_t exceptions;
uintptr_t start = (uintptr_t)buf;
uintptr_t end = start + len;
const size_t min_len = ((sizeof(struct malloc_pool) + (SizeQuant - 1)) &
(~(SizeQuant - 1))) +
sizeof(struct bhead) * 2;
start = ROUNDUP(start, SizeQuant);
end = ROUNDDOWN(end, SizeQuant);
assert(start < end);
if ((end - start) < min_len) {
DMSG("Skipping too small pool");
return;
}
exceptions = malloc_lock();
tag_asan_free((void *)start, end - start);
bpool((void *)start, end - start, &malloc_poolset);
l = malloc_pool_len + 1;
p = realloc_unlocked(malloc_pool, sizeof(struct malloc_pool) * l);
assert(p);
malloc_pool = p;
malloc_pool[malloc_pool_len].buf = (void *)start;
malloc_pool[malloc_pool_len].len = end - start;
#ifdef BufStats
mstats.size += malloc_pool[malloc_pool_len].len;
#endif
malloc_pool_len = l;
malloc_unlock(exceptions);
}
在init_runtime()函数中调用了malloc_add_pool,添加的内存池是给optee内核使用的
_start – >generic_boot_init_primary—>init_primary_helper()—>init_runtime()
malloc_add_pool(__heap1_start, __heap1_end - __heap1_start);
malloc_add_pool(__heap2_start, __heap2_end - __heap2_start);
而__heap1_start和__heap2_start是在kern.ld.S中,从TEE RAM内存中分的
.heap1 (NOLOAD) : {
/*
* We're keeping track of the padding added before the
* .nozi section so we can do something useful with
* this otherwise wasted memory.
*/
__heap1_start = .;
#ifndef CFG_WITH_PAGER
. += CFG_CORE_HEAP_SIZE;
#endif
. = ALIGN(16 * 1024);
__heap1_end = .;
}
/*
* Uninitialized data that shouldn't be zero initialized at
* runtime.
*
* L1 mmu table requires 16 KiB alignment
*/
.nozi (NOLOAD) : {
__nozi_start = .;
ASSERT(!(__nozi_start & (16 * 1024 - 1)), "align nozi to 16kB");
KEEP(*(.nozi .nozi.*))
. = ALIGN(16);
__nozi_end = .;
__nozi_stack_start = .;
KEEP(*(.nozi_stack))
. = ALIGN(8);
__nozi_stack_end = .;
}
#ifdef CFG_WITH_PAGER
.heap2 (NOLOAD) : {
__heap2_start = .;
/*
* Reserve additional memory for heap, the total should be
* at least CFG_CORE_HEAP_SIZE, but count what has already
* been reserved in .heap1
*/
. += CFG_CORE_HEAP_SIZE - (__heap1_end - __heap1_start);
. = ALIGN(SMALL_PAGE_SIZE);
__heap2_end = .;
}
而在user_ta_entry.c中,也调用了malloc_add_pool,此时添加的内存池是给TA使用的
static TEE_Result init_instance(void)
{
trace_set_level(tahead_get_trace_level());
__utee_gprof_init();
malloc_add_pool(ta_heap, ta_heap_size);
_TEE_MathAPI_Init();
return TA_CreateEntryPoint();
}
1.1.3、optee中的MMU使用
(1)、Optee中的TTBR0/TTBR1
我们知道,在linux中将虚拟空间划分为了userspace和kernel space:
例如:
aarch64 :
0x0000_0000_0000_0000 - 0x0000_ffff_ffff_ffff是userspace
0xffff_0000_0000_0000 - 0xffff_ffff_ffff_ffff是kernel space
aarch32 : 0-3G是userspace,3-4G是kernel space
当cpu发起读写内存时,cpu发起的是虚拟地址,如果是kernel地址,那么MMU将自动使用TTBR1做为页表基地址进行转换程物理地址,然后发送到AXI总线,完成真正物理地址的读写;
如果cpu发起的虚拟地址是userspace地址,那么MMU将使用TTBR0做为页表基地址进行转换程物理地址,然后发送到AXI总线,完成真正物理地址的读写;
那么在optee中是怎么样的呢?
在optee中,没用特别的将虚拟地址划分成kernel space和userspace,统一使用0-4G地址空间(无论是aarch32还是aarch64).
在optee初始化时,禁用了TTBR1,所有整个optee的虚拟地址的专业,都是使用TTBR0做为基地址转换成物理地址,发送到AXI总线,完成真正的物理地址读写
void core_init_mmu_regs(void)
{
uint64_t mair;
uint64_t tcr;
paddr_t ttbr0;
uint64_t ips = calc_physical_addr_size_bits(max_pa);
ttbr0 = virt_to_phys(l1_xlation_table[0][get_core_pos()]);
mair = MAIR_ATTR_SET(ATTR_DEVICE, ATTR_DEVICE_INDEX);
mair |= MAIR_ATTR_SET(ATTR_IWBWA_OWBWA_NTR, ATTR_IWBWA_OWBWA_NTR_INDEX);
write_mair_el1(mair);
tcr = TCR_RES1;
tcr |= TCR_XRGNX_WBWA << TCR_IRGN0_SHIFT;
tcr |= TCR_XRGNX_WBWA << TCR_ORGN0_SHIFT;
tcr |= TCR_SHX_ISH << TCR_SH0_SHIFT;
tcr |= ips << TCR_EL1_IPS_SHIFT;
tcr |= 64 - __builtin_ctzl(CFG_LPAE_ADDR_SPACE_SIZE);
/* Disable the use of TTBR1 */
tcr |= TCR_EPD1;
/*
* TCR.A1 = 0 => ASID is stored in TTBR0
* TCR.AS = 0 => Same ASID size as in Aarch32/ARMv7
*/
write_tcr_el1(tcr);
write_ttbr0_el1(ttbr0);
write_ttbr1_el1(0);
}
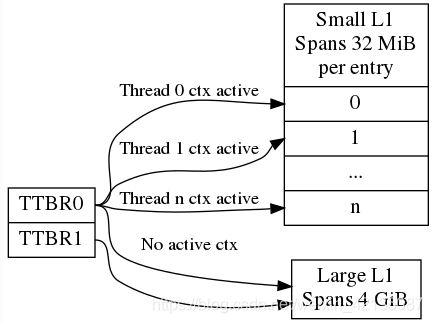
(2)、optee中的页表
optee在在内核中使用一个4GB的大页表,在user mode使用多个32M的小页表
注意下面的图来自官网,有点小问题,代码中没用使用到TTBR1,kernel和user都使用TTBR0
(3)、tee内核页表基地址的配置
将基地址写入到TTBR0
在optee的start函数和cpu_on_handler函数中,都会调用core_init_mmu_regs()
FUNC _start , :
......
bl core_init_mmu_regs
FUNC cpu_on_handler , :
......
bl core_init_mmu_regs
在core_init_mmu_regs中,获取当前cpu的页表基地址,写入到ttbr0寄存器中
void core_init_mmu_regs(void)
{
uint64_t mair;
uint64_t tcr;
paddr_t ttbr0;
uint64_t ips = calc_physical_addr_size_bits(max_pa);
ttbr0 = virt_to_phys(l1_xlation_table[0][get_core_pos()]); //获取当前cpu的页表基地址
mair = MAIR_ATTR_SET(ATTR_DEVICE, ATTR_DEVICE_INDEX);
mair |= MAIR_ATTR_SET(ATTR_IWBWA_OWBWA_NTR, ATTR_IWBWA_OWBWA_NTR_INDEX);
write_mair_el1(mair);
tcr = TCR_RES1;
tcr |= TCR_XRGNX_WBWA << TCR_IRGN0_SHIFT;
tcr |= TCR_XRGNX_WBWA << TCR_ORGN0_SHIFT;
tcr |= TCR_SHX_ISH << TCR_SH0_SHIFT;
tcr |= ips << TCR_EL1_IPS_SHIFT;
tcr |= 64 - __builtin_ctzl(CFG_LPAE_ADDR_SPACE_SIZE);
/* Disable the use of TTBR1 */
tcr |= TCR_EPD1;
/*
* TCR.A1 = 0 => ASID is stored in TTBR0
* TCR.AS = 0 => Same ASID size as in Aarch32/ARMv7
*/
write_tcr_el1(tcr);
write_ttbr0_el1(ttbr0); //将页表基地址写入到ttbr0寄存器
write_ttbr1_el1(0);
}
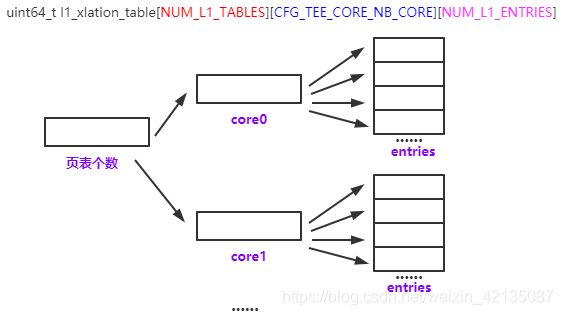
(4)、tee内核页表填充
在optee内核中,实现的是一个4G的大页表(一级页表, 32bit可表示4G空间)
在section段定义了一个三元数组,用于存放页表
uint64_t l1_xlation_table[NUM_L1_TABLES][CFG_TEE_CORE_NB_CORE][NUM_L1_ENTRIES]
__aligned(NUM_L1_ENTRIES * XLAT_ENTRY_SIZE) __section(".nozi.mmu.l1");
形态入下图所示
填充页表,那么要将哪些地址填进去呢?
在core_init_mmu_map()函数中,调用core_init_mmu_tables创建页表,参数static_memory_map是一个数组,它指向系统中向optee已注册了的所有内存区域的地址
void core_init_mmu_map(void)
{
......
core_init_mmu_tables(static_memory_map);
......
}
static struct tee_mmap_region static_memory_map[CFG_MMAP_REGIONS + 1];
#define CFG_MMAP_REGIONS 13,//表示当前optee,最多支持注册13块内存区域
调用core_init_mmu_tables()填充的页表
参数mm就是刚才的static_memory_map,小于等于13块的内存区域, 填充方法如下
void core_init_mmu_tables(struct tee_mmap_region *mm)
{
uint64_t max_va = 0;
size_t n;
#ifdef CFG_CORE_UNMAP_CORE_AT_EL0
COMPILE_TIME_ASSERT(CORE_MMU_L1_TBL_OFFSET ==
sizeof(l1_xlation_table) / 2);
#endif
max_pa = get_nsec_ddr_max_pa();
for (n = 0; !core_mmap_is_end_of_table(mm + n); n++) {
paddr_t pa_end;
vaddr_t va_end;
debug_print(" %010" PRIxVA " %010" PRIxPA " %10zx %x",
mm[n].va, mm[n].pa, mm[n].size, mm[n].attr);
if (!IS_PAGE_ALIGNED(mm[n].pa) || !IS_PAGE_ALIGNED(mm[n].size))
panic("unaligned region");
pa_end = mm[n].pa + mm[n].size - 1;
va_end = mm[n].va + mm[n].size - 1;
if (pa_end > max_pa)
max_pa = pa_end;
if (va_end > max_va)
max_va = va_end;
}
/* Clear table before use */
memset(l1_xlation_table, 0, sizeof(l1_xlation_table)); ------------------------清空页表
for (n = 0; !core_mmap_is_end_of_table(mm + n); n++)
if (!core_mmu_is_dynamic_vaspace(mm + n))
core_mmu_map_region(mm + n); ------------------------填充当前cpu的页表
/*
* Primary mapping table is ready at index `get_core_pos()`
* whose value may not be ZERO. Take this index as copy source.
*/
for (n = 0; n < CFG_TEE_CORE_NB_CORE; n++) {
if (n == get_core_pos())
continue;
memcpy(l1_xlation_table[0][n],
l1_xlation_table[0][get_core_pos()], ------------------------将当前cpu的页表,拷贝到其它cpu的页表中
XLAT_ENTRY_SIZE * NUM_L1_ENTRIES);
}
for (n = 1; n < NUM_L1_ENTRIES; n++) {
if (!l1_xlation_table[0][0][n]) {
user_va_idx = n;
break;
}
}
assert(user_va_idx != -1);
COMPILE_TIME_ASSERT(CFG_LPAE_ADDR_SPACE_SIZE > 0);
assert(max_va < CFG_LPAE_ADDR_SPACE_SIZE);
}
在下列段代码中,循环遍历mm遍历,对于每个内存区域,做core_mmu_map_region运算
for (n = 0; !core_mmap_is_end_of_table(mm + n); n++)
if (!core_mmu_is_dynamic_vaspace(mm + n))
core_mmu_map_region(mm + n);
core_mmu_map_region就是将每块内存区域,进行拆分,拆分程若干entry
void core_mmu_map_region(struct tee_mmap_region *mm)
{
struct core_mmu_table_info tbl_info;
unsigned int idx;
vaddr_t vaddr = mm->va;
paddr_t paddr = mm->pa;
ssize_t size_left = mm->size;
int level;
bool table_found;
uint32_t old_attr;
assert(!((vaddr | paddr) & SMALL_PAGE_MASK));
while (size_left > 0) {
level = 1;
while (true) {
assert(level <= CORE_MMU_PGDIR_LEVEL);
table_found = core_mmu_find_table(vaddr, level,
&tbl_info);
if (!table_found)
panic("can't find table for mapping");
idx = core_mmu_va2idx(&tbl_info, vaddr);
if (!can_map_at_level(paddr, vaddr, size_left,
1 << tbl_info.shift, mm)) {
/*
* This part of the region can't be mapped at
* this level. Need to go deeper.
*/
if (!core_mmu_entry_to_finer_grained(&tbl_info,
idx, mm->attr & TEE_MATTR_SECURE))
panic("Can't divide MMU entry");
level++;
continue;
}
/* We can map part of the region at current level */
core_mmu_get_entry(&tbl_info, idx, NULL, &old_attr);
if (old_attr)
panic("Page is already mapped");
core_mmu_set_entry(&tbl_info, idx, paddr, mm->attr);
paddr += 1 << tbl_info.shift;
vaddr += 1 << tbl_info.shift;
size_left -= 1 << tbl_info.shift;
break;
}
}
}
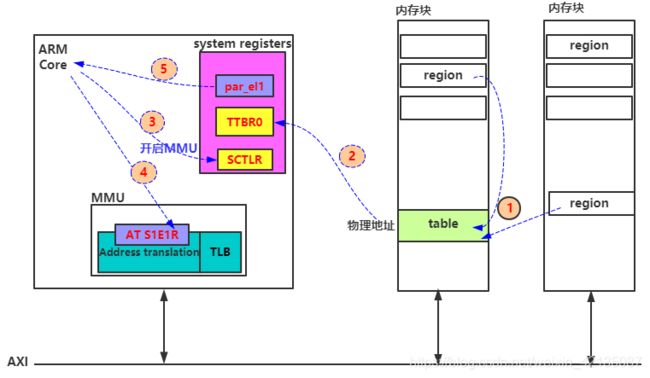
(5)、virt_to_phys转换的过程的举例
通过画图讲述了,在optee中,构建页表,然后完成一个virt_to_phys转换的过程.
- 1、系统注册了的若干块内存,划分为若干个大小为4K/8K的region,每个region的地址,写入到页表的entry中,这样就构建出了页表.
- 2、将页表物理地址写入到TTBR0中
- 3、开启MMU
- 4、调用virt_to_phys时,使用MMU的AT S1E1R指令,将虚拟地址写入到MMU的Address translation中
- 5、从par_el1中读出的物理地址,就是经过MMU转换后的
注意:
1、在optee中禁止了TTBR1,所以在optee的kernel mode中,也是使用TTBR0
2、optee中,只使用到了一级页表
1.1.2、optee内存申请
先看一个重要结构体,表示 一块连续的物理内存 : tee_mm_pool_t
struct _tee_mm_pool_t {
tee_mm_entry_t *entry;
paddr_t lo; /* low boundary of the pool */
paddr_t hi; /* high boundary of the pool */
uint32_t flags; /* Config flags for the pool */
uint8_t shift; /* size shift */
unsigned int lock;
#ifdef CFG_WITH_STATS
size_t max_allocated;
#endif
};
typedef struct _tee_mm_pool_t tee_mm_pool_t;
结构体中的entry表示一个页面,它也以链表的形式存在的. 也是上一节我们讲到,系统将若干个注册到系统内存块,划分为很多个entries, 记录在页表中. 同时,这些entries也会用链表串起来。每个entries的大小为4k/8k
在tee_mm_init(),在指定的物理内存中,申请pool结构体.
bool tee_mm_init(tee_mm_pool_t *pool, paddr_t lo, paddr_t hi, uint8_t shift,
uint32_t flags)
{
if (pool == NULL)
return false;
lo = ROUNDUP(lo, 1 << shift);
hi = ROUNDDOWN(hi, 1 << shift);
assert(((uint64_t)(hi - lo) >> shift) < (uint64_t)UINT32_MAX);
pool->lo = lo;
pool->hi = hi;
pool->shift = shift;
pool->flags = flags;
pool->entry = calloc(1, sizeof(tee_mm_entry_t));
if (pool->entry == NULL)
return false;
if (pool->flags & TEE_MM_POOL_HI_ALLOC)
pool->entry->offset = ((hi - lo - 1) >> shift) + 1;
pool->entry->pool = pool;
pool->lock = SPINLOCK_UNLOCK;
return true;
}
在generic_boot.c中, 调用tee_mm_init,创建tee_mm_vcore的pool
static void init_vcore(tee_mm_pool_t *mm_vcore)
{
const vaddr_t begin = TEE_RAM_VA_START; ------------------------注意这里是TEE RAM
vaddr_t end = TEE_RAM_VA_START + TEE_RAM_VA_SIZE;
#ifdef CFG_CORE_SANITIZE_KADDRESS
/* Carve out asan memory, flat maped after core memory */
if (end > ASAN_SHADOW_PA)
end = ASAN_MAP_PA;
#endif
if (!tee_mm_init(mm_vcore, begin, end, SMALL_PAGE_SHIFT,
TEE_MM_POOL_NO_FLAGS))
panic("tee_mm_vcore init failed");
}
在tee_mm_alloc函数中,先去查找entry链表,找到空闲的区域; 如果找不到,则在根据tee_mm_vcore的pool结构体中的hi/lo地址,在物理内存中再申请一块内存,然后调用tee_mm_add(entry, nn), 而tee_mm_add(entry, nn)的作用就是将这块物理内存,注册到entry链表中
tee_mm_entry_t *tee_mm_alloc(tee_mm_pool_t *pool, size_t size)
{
size_t psize;
tee_mm_entry_t *entry;
tee_mm_entry_t *nn;kongx
size_t remaining;
uint32_t exceptions;
/* Check that pool is initialized */
if (!pool || !pool->entry)
return NULL;
nn = malloc(sizeof(tee_mm_entry_t));
if (!nn)
return NULL;
exceptions = cpu_spin_lock_xsave(&pool->lock);
entry = pool->entry;
if (size == 0)
psize = 0;
else
psize = ((size - 1) >> pool->shift) + 1;
/* find free slot */
if (pool->flags & TEE_MM_POOL_HI_ALLOC) {
while (entry->next != NULL && psize >
(entry->offset - entry->next->offset -
entry->next->size))
entry = entry->next;
} else {
while (entry->next != NULL && psize >
(entry->next->offset - entry->size - entry->offset))
entry = entry->next;
}
/* check if we have enough memory */
if (entry->next == NULL) {
if (pool->flags & TEE_MM_POOL_HI_ALLOC) {
/*
* entry->offset is a "block count" offset from
* pool->lo. The byte offset is
* (entry->offset << pool->shift).
* In the HI_ALLOC allocation scheme the memory is
* allocated from the end of the segment, thus to
* validate there is sufficient memory validate that
* (entry->offset << pool->shift) > size.
*/
if ((entry->offset << pool->shift) < size) {
/* out of memory */
goto err;
}
} else {
if (pool->hi <= pool->lo)
panic("invalid pool");
remaining = (pool->hi - pool->lo);
remaining -= ((entry->offset + entry->size) <<
pool->shift);
if (remaining < size) {
/* out of memory */
goto err;
}
}
}
tee_mm_add(entry, nn);
if (pool->flags & TEE_MM_POOL_HI_ALLOC)
nn->offset = entry->offset - psize;
else
nn->offset = entry->offset + entry->size;
nn->size = psize;
nn->pool = pool;
update_max_allocated(pool);
cpu_spin_unlock_xrestore(&pool->lock, exceptions);
return nn;
err:
cpu_spin_unlock_xrestore(&pool->lock, exceptions);
free(nn);
return NULL;
}
在generic_boot.c中,调用tee_mm_alloc申请在TEE RAM申请内存的示例
mm = tee_mm_alloc(&tee_mm_sec_ddr, pageable_size);
那么除了TEE RAM,opteeos中还有哪些物理内存块呢?
tee_mm_shm //share memory
static TEE_Result mobj_mapped_shm_init(void)
{
vaddr_t pool_start;
vaddr_t pool_end;
core_mmu_get_mem_by_type(MEM_AREA_SHM_VASPACE, &pool_start, &pool_end);
if (!pool_start || !pool_end)
panic("Can't find region for shmem pool");
if (!tee_mm_init(&tee_mm_shm, pool_start, pool_end, SMALL_PAGE_SHIFT,
TEE_MM_POOL_NO_FLAGS))
panic("Could not create shmem pool");
DMSG("Shared memory address range: %" PRIxVA ", %" PRIxVA,
pool_start, pool_end);
return TEE_SUCCESS;
}
service_init(mobj_mapped_shm_init);
tee_mm_sec_ddr // TA RAM
void teecore_init_ta_ram(void)
{
vaddr_t s;
vaddr_t e;
paddr_t ps;
paddr_t pe;
/* get virtual addr/size of RAM where TA are loaded/executedNSec
* shared mem allcated from teecore */
core_mmu_get_mem_by_type(MEM_AREA_TA_RAM, &s, &e);
ps = virt_to_phys((void *)s);
pe = virt_to_phys((void *)(e - 1)) + 1;
if (!ps || (ps & CORE_MMU_USER_CODE_MASK) ||
!pe || (pe & CORE_MMU_USER_CODE_MASK))
panic("invalid TA RAM");
/* extra check: we could rely on core_mmu_get_mem_by_type() */
if (!tee_pbuf_is_sec(ps, pe - ps))
panic("TA RAM is not secure");
if (!tee_mm_is_empty(&tee_mm_sec_ddr))
panic("TA RAM pool is not empty");
/* remove previous config and init TA ddr memory pool */
tee_mm_final(&tee_mm_sec_ddr);
tee_mm_init(&tee_mm_sec_ddr, ps, pe, CORE_MMU_USER_CODE_SHIFT,
TEE_MM_POOL_NO_FLAGS);
}
rpmb的RAM
static TEE_Result rpmb_fs_open_internal(struct rpmb_file_handle *fh,
const TEE_UUID *uuid, bool create)
{
tee_mm_pool_t p;
bool pool_result;
TEE_Result res = TEE_ERROR_GENERIC;
/* We need to do setup in order to make sure fs_par is filled in */
res = rpmb_fs_setup();
if (res != TEE_SUCCESS)
goto out;
fh->uuid = uuid;
if (create) {
/* Upper memory allocation must be used for RPMB_FS. */
pool_result = tee_mm_init(&p,
RPMB_STORAGE_START_ADDRESS,
fs_par->max_rpmb_address,
RPMB_BLOCK_SIZE_SHIFT,
TEE_MM_POOL_HI_ALLOC);
if (!pool_result) {
res = TEE_ERROR_OUT_OF_MEMORY;
goto out;
}
res = read_fat(fh, &p);
tee_mm_final(&p);
if (res != TEE_SUCCESS)
goto out;
} else {
res = read_fat(fh, NULL);
if (res != TEE_SUCCESS)
goto out;
}
......
}
我们再次总结一下:
在generic_boot的时候,通过写死的物理地址参数,调用tee_mm_init & tee_mm_alloc,注册了TEE RAM段,后续的TEE内存申请,都是在TEE RAM中申请.
由于是写死的物理地址,所以TEE RAM必需是一块连续的物理地址
而在
在MMU初始化的时候,将系统中的非TEE RAM的内存,都添加到了页表中,并且类型为MEM_AREA_TA_RAM。 然后在teecore_init_ta_ram
1.1.3 总结
两个重要结构体,pool指向entry链表,entry链表又执行它的pool
struct _tee_mm_entry_t {
struct _tee_mm_pool_t *pool;
struct _tee_mm_entry_t *next;
uint32_t offset; /* offset in pages/sections */
uint32_t size; /* size in pages/sections */
};
typedef struct _tee_mm_entry_t tee_mm_entry_t;
struct _tee_mm_pool_t {
tee_mm_entry_t *entry;
paddr_t lo; /* low boundary of the pool */
paddr_t hi; /* high boundary of the pool */
uint32_t flags; /* Config flags for the pool */
uint8_t shift; /* size shift */
unsigned int lock;
#ifdef CFG_WITH_STATS
size_t max_allocated;
#endif
};
typedef struct _tee_mm_pool_t tee_mm_pool_t;
在调用tee_mm_alloc时,先在pool指向的entry链表中,找空闲的内存。
如果找不到,再去pool指向的物理块中,申请一块entry,并加入链表中.
操作完毕后,还会调用update_max_allocated(pool)更新pool
这里看不明白的是,如果多个不连续的物理块,也就是多个大pool,那么怎么用的呢
tee_mm_entry_t *tee_mm_alloc(tee_mm_pool_t *pool, size_t size)
{
size_t psize;
tee_mm_entry_t *entry;
tee_mm_entry_t *nn;
size_t remaining;
uint32_t exceptions;
/* Check that pool is initialized */
if (!pool || !pool->entry)
return NULL;
nn = malloc(sizeof(tee_mm_entry_t));
if (!nn)
return NULL;
exceptions = cpu_spin_lock_xsave(&pool->lock);
entry = pool->entry;
if (size == 0)
psize = 0;
else
psize = ((size - 1) >> pool->shift) + 1;
/* find free slot */
if (pool->flags & TEE_MM_POOL_HI_ALLOC) {
while (entry->next != NULL && psize >
(entry->offset - entry->next->offset -
entry->next->size))
entry = entry->next;
} else {
while (entry->next != NULL && psize >
(entry->next->offset - entry->size - entry->offset))
entry = entry->next;
}
/* check if we have enough memory */
if (entry->next == NULL) {
if (pool->flags & TEE_MM_POOL_HI_ALLOC) {
/*
* entry->offset is a "block count" offset from
* pool->lo. The byte offset is
* (entry->offset << pool->shift).
* In the HI_ALLOC allocation scheme the memory is
* allocated from the end of the segment, thus to
* validate there is sufficient memory validate that
* (entry->offset << pool->shift) > size.
*/
if ((entry->offset << pool->shift) < size) {
/* out of memory */
goto err;
}
} else {
if (pool->hi <= pool->lo)
panic("invalid pool");
remaining = (pool->hi - pool->lo);
remaining -= ((entry->offset + entry->size) <<
pool->shift);
if (remaining < size) {
/* out of memory */
goto err;
}
}
}
tee_mm_add(entry, nn);
if (pool->flags & TEE_MM_POOL_HI_ALLOC)
nn->offset = entry->offset - psize;
else
nn->offset = entry->offset + entry->size;
nn->size = psize;
nn->pool = pool;
update_max_allocated(pool);
cpu_spin_unlock_xrestore(&pool->lock, exceptions);
return nn;
err:
cpu_spin_unlock_xrestore(&pool->lock, exceptions);
free(nn);
return NULL;
}