【Python + OpenCV】分析细胞核细胞质的面积比(自动阈值)
一、基于单张图片的分析

对于这张图片,想要进行细胞核细胞质面积比的计算,一种常用的手段是通过识别图像的灰度,从而划分图片中各个部分。
因此首先要做的就是对图像进行二值化处理。图像二值化在数字图像处理领域是一种非常常见的技术,以设定的阈值为参考,将图像上的像素灰度值设置为0或255,便可以区分出细胞核、细胞质和图片背景。
使用OpenCV库或Pillow库均能完成二值化的工作。使用Pillow库完成这个工作时,我们只需要先将图像转换为黑白图片,然后根据每个像素点的明度判断它是属于细胞核还是细胞质。值得注意的是,针对每张图的灰度阈值是不一样的,因此需要经过多次调整与试错才能得到合适的阈值。
或者可以通过PS帮助找出最佳的阈值,分别使用选择工具选中整个细胞和细胞核,调出直方图工具,就可以查到区域的灰度分布。
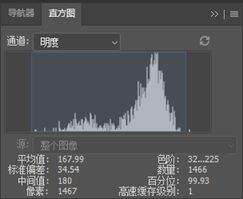
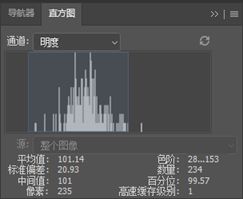
可以看到整个细胞的灰度值分布在225以下,而细胞核的灰度分布在153以下。甚至连像素数量都拿到了,因此可以直接粗略地计算出来它的细胞核和细胞质的面积比,大约是0.18。
接下来以这个数据为一个参考值,就可以方便地验证我们的算法是否正确。
from PIL import Image
img = Image.open("../cell.jpg")
img = img.convert('L')
# 获取图片大小
width = img.size[0]
height = img.size[1]
pix = img.load()
img.show()
cell_whole = 0
cell_nucleus = 0
pixels = 0
for x in range(width):
for y in range(height):
pixels = pixels + 1
grayScale = pix[x, y]
if grayScale <= 225:
cell_whole = cell_whole + 1
if grayScale <= 150:
cell_nucleus = cell_nucleus + 1
print("细胞质面积:",cell_whole)
print("细胞核面积:",cell_nucleus)
print("核质面积比:{:.3f}".format(cell_nucleus / (cell_whole - cell_nucleus)))
基于Pillow完成的测量效果并不理想,最后的结果大概是这样:
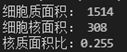
和预期的0.19差得有点远了。原因其实很好解释,因为Pillow是对整个图片中所有的像素点进行统计,因此细胞质中一些较深的像素点被不可避免地统计在了细胞核的面积中,导致细胞核的面积偏大。
既然纯粹使用灰度的统计方法无法完成这项工作,那么单纯使用Pillow库就没法完成这项任务了,接下来就请出我们的OpenCV库。
OpenCV在Pillow的基础上多了很多与计算机视觉有关的库,比如说,可以在灰度识别、二值化的基础上,再提取出图形的轮廓,然后相加。
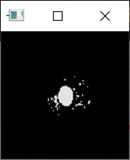

但是可以注意到,在识别的时候,OpenCV识别出的轮廓不只有细胞核,还有细胞质中的一些深色色块。这也是Pillow库识别的时候细胞核面积偏大的原因,解决方法也很简单,只需要找出最大的轮廓就可以了,剩下的深色色块不需要算进细胞核面积中。
![]()
通过这种方法,我们得到了面积比0.175,和之前得到的0.18参考值差不多,在合理的误差范围内。
至此,我们已经完成了关于这张图的细胞核和细胞质面积比的计算。
二、更一般性的考虑
再又进一步考虑,如果上传的图片是任意一张单个细胞的图片,该怎么获取细胞的核质面积比呢?
于是我与一位大佬经过一个晚上加一个大半天的讨论与研究,成功找到了一套能够获取任意单个细胞图片核质面积比的方法。
基于上面已有的获取单个细胞的方法,获取多个细胞的难点在于如何获得两个灰度值的阈值。这两个阈值决定着能否正确从图片中分出细胞质与细胞核,而对于每一张细胞的图片,它的阈值都是不同的。
起初我们的思路是通过分析整张细胞图片的灰度值分布,尝试找到一些特殊的规律,从而找到那两个阈值。
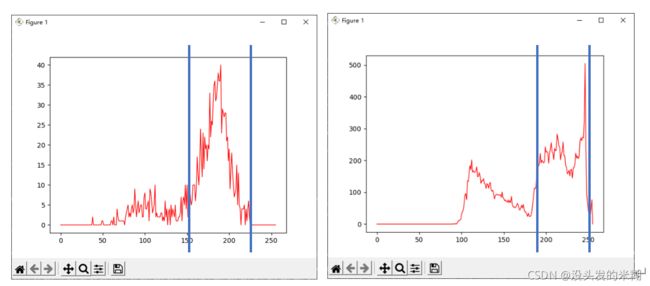
确实很难从这种杂乱无章的曲线中找出些什么,但实际上它确实是存在着某种规律,第一个细胞的两个阈值分别是225、153,第二个细胞的两个阈值分别是252、192。它们大致都处于一个波峰的两端,这个波峰恰巧是代表细胞质灰度值的像素点的波峰,而它们的左侧都有一个波峰,代表细胞核灰度值像素点的波峰,它们右侧代表背景的波峰因为数值实在是过大,会影响整个图的观察,因此被我们手工切除了。
那天晚上我们讨论到很晚,从曲线的平滑化一直讨论到函数的凹凸性,想通过这个灰度值找出合适的阈值,一直到最后都还是找不到合理的方案,因为整个数据的噪声太大了,我们能想到的算法都非常容易受到干扰。
第二天早上,我带着一个全新的方案。根据我们找到的两个图片,我决定使用椭圆拟合的方法去找到合适的阈值点。

具体的思路就是使用椭圆去拟合根据灰度阈值二值化后的图片所生成的轮廓,然后比较拟合出的椭圆与轮廓的匹配程度,匹配度越高则说明拟合出的轮廓越规则,则越有可能是正确的灰度值。
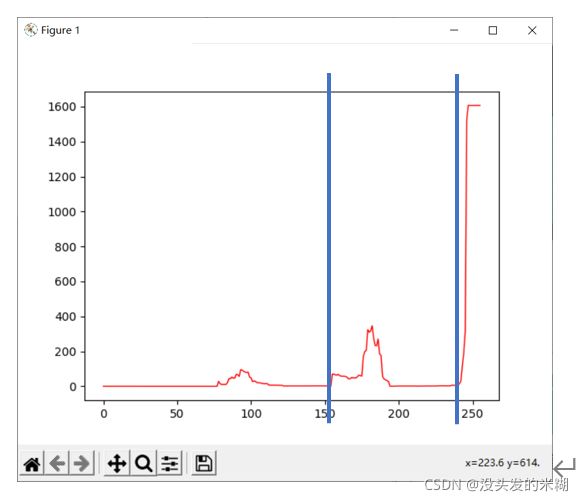
这是一张在0-255的不同灰度值作为阈值的情况下,通过二值化得到的轮廓与拟合出的椭圆的误差,这张图就明显比刚刚那个图噪声小了很多,两个我们想要的阈值刚好在从右到左数的两个波底上。
然后我们想办法整了个计算方法,即比较右侧曲线的平均斜率和左侧曲线的平均斜率,如果它们的比大于数据的平均变化程度,并且拟合的误差小于某个值,那么就认为这是我们要找的灰度阈值。
并且考虑到这样的算法并不一定100%准确,因此我们用tkinter写了一个简单的GUI界面,以保证在自动阈值检测失效的情况下,仍然能通过手动调节得到合适的核质面积比。
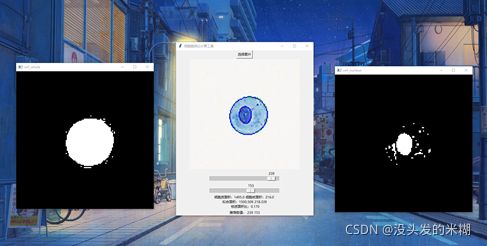
最后得到了这样的一个简单的小工具。当导入图片时,它会根据我们写的小算法检测出可能合适的灰度阈值,并直接应用。之后仍然可以通过左中右三张辅助图和中间的滑块来微调阈值或者重设阈值,以得到更加准确的面积比。
我们还在网络上多找了几个细胞图片进行测试,发现成功率确实超出了我们原本的预估。但也没办法避免一些失败的情况,这些失败的情况普遍是只找到了细胞核或细胞质中的其中一个,但毕竟我们的程序只花了一个晚上加一个大半天,所以还有很多思考和改进的空间。
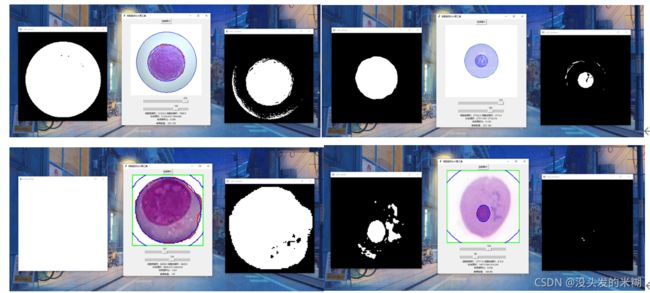
因为我们之前也没有接触过太多有关机器视觉的东西,所以这两天折腾出来的东西纯属是凭借想象力和肝。以后如果进一步系统地去学习这方面的知识,应该又会有不一样的思路和想法吧。
三、代码实现
import tkinter
from tkinter import *
from PIL import Image, ImageTk ###这个是没有想到的模块,也不确定能不能省
from tkinter.filedialog import askopenfilename
import time
import cv2 as cv
import numpy as np
import math
from time import sleep
import matplotlib.pyplot as plt
# from scipy.signal import savgol_filter
root = Tk()
root.geometry('500x600') ##这个小了一点,不知道怎么自适应
root.title('细胞胞质比计算工具')
def slopeComparison(i,ls,ls1):
left = abs(ls[i] - ls[i - 1]) + abs(ls[i-1] - ls[i-2])
right = ls[i+2] - ls[i]
mean = np.mean(ls1)
mean2 = np.mean(ls)
# 如果右侧平均变化率和左侧平均变化率的比值大于平均变化程度,并且左边不是0,并且误差的值不能太大
if right > mean * left and left != 0 and (abs(ls[i] - ls[i - 1]) > 0.01) and 0 < ls[i] < mean:
return True
else:
return False
def choosepic():
global scaleX1
global scaleX2
global cell_o
global words
global rec
path_ = askopenfilename()
print(path_)
rec['text'] = "推荐数值:"
cell_o = cv.imread(path_, 1)
changePic(cell_o)
ls = []
for i in range(0, 256):
scaleX1.set(i)
scaleX2.set(154)
try:
whole_area, nucleus_area, whole_area_ellipse, nucleus_area_ellipse = runDetect(i, 154)
ls.append(abs(whole_area - whole_area_ellipse))
except Exception:
ls.append(0.1)
# ls = list(savgol_filter(ls, 9, 5, mode= 'nearest'))
flag = False
ls1 = []
amount = 0
for i in range(len(ls)-1):
ls1.append(abs(ls[i+1] - ls[i]))
for i in list(range(2, len(ls) - 2))[::-1]:
if slopeComparison(i,ls,ls1):
if flag == False:
flag = True
print(i-1)
print("{} {:.2f}".format(i, ls[i]))
rec['text'] = rec['text'] + " " + str(i-1)
amount = amount + 1
if amount == 1:
scaleX1.set(i-1)
elif amount == 2:
scaleX2.set(i-1)
runDetect(scaleX1.get(),scaleX2.get())
else:
flag = False
# for i in range(0, len(ls)):
# print("{} {:.2f}".format(i, ls[i]))
# plt.plot(range(0, 256), ls, linewidth=1, color='r', marker='o', markersize=0)
# plt.show()
def changePic(cell_o):
dst = cv.cvtColor(cell_o, cv.COLOR_BGR2RGB)
up_width = 400
up_height = 400
up_points = (up_width, up_height)
dst = cv.resize(dst, up_points, interpolation=cv.INTER_CUBIC)
current_image = Image.fromarray(dst)
imgtk = ImageTk.PhotoImage(image=current_image)
image_label.config(image=imgtk)
image_label.image = imgtk # keep a reference
cell_o = cv.imread("../../cell.jpg", 1)
def runDetect(x1, x2):
global cell_o
global words
cell = cv.cvtColor(cell_o, cv.COLOR_BGR2GRAY)
rows, cols = cell_o.shape[:2] # 获得图片的高和宽
mapx = np.zeros(cell_o.shape[:2], np.float32) # mapx是一个图片大小的变换矩阵
mapy = np.zeros(cell_o.shape[:2], np.float32) # mapy也是一个图片大小的变换矩阵
for i in range(rows): # 遍历,将获得到图片的宽和稿依次赋予两个变换矩阵
for j in range(cols):
mapx.itemset((i, j), j)
mapy.itemset((i, j), i)
img = cv.remap(cell_o, mapx, mapy, cv.INTER_LINEAR) # 用仿射函数实现仿射变换
# 将图像转换为二值图,第二个值为阈值
ret, cell_2v_whole = cv.threshold(cell, x1, 255, cv.THRESH_BINARY_INV) # 获取整个细胞的二值图
ret, cell_2v_nucleus = cv.threshold(cell, x2, 255, cv.THRESH_BINARY_INV) # 获取细胞核的二值图
cv.namedWindow("cell_whole", 0)
cv.resizeWindow("cell_whole", 500, 500)
cv.imshow("cell_whole", cell_2v_whole)
cv.namedWindow("cell_nucleus", 0)
cv.resizeWindow("cell_nucleus", 500, 500)
cv.imshow("cell_nucleus", cell_2v_nucleus)
# 基于二值图像用外轮廓的模式,通过全点连接轮廓的方法提取轮廓
contours_whole, hierarchy = cv.findContours(cell_2v_whole, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_NONE)
contours_nucleus, hierarchy = cv.findContours(cell_2v_nucleus, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_NONE)
# 获取目标图像的最小矩阵,找到最大的轮廓
maxArea = 0
maxContour = {}
for item in contours_whole:
x, y, w, h = cv.boundingRect(item)
if w * h > maxArea:
maxArea = w * h
maxContour = item
whole_area = 0
whole_area += cv.contourArea(maxContour)
img = cv.drawContours(cell_o.copy(), maxContour, -1, (0, 255, 0), 1)
cnt = maxContour
ellipse = cv.fitEllipse(cnt)
(x, y), (a, b), angle = cv.fitEllipse(cnt)
cv.ellipse(img, ellipse, (255, 0, 0), 1)
whole_area_ellipse = math.pi * a * b / 4
# 重复,查找细胞核的最大轮廓
maxArea = 0
maxContour = {}
for item in contours_nucleus:
x, y, w, h = cv.boundingRect(item)
if w * h > maxArea:
maxArea = w * h
maxContour = item
nucleus_area = 0
nucleus_area += cv.contourArea(maxContour)
img = cv.drawContours(img, maxContour, -1, (0, 0, 255), 1)
cnt = maxContour
ellipse = cv.fitEllipse(cnt)
(x, y), (a, b), angle = cv.fitEllipse(cnt)
cv.ellipse(img, ellipse, (255, 0, 0), 1)
nucleus_area_ellipse = math.pi * a * b / 4
# img = cv.rectangle(img,(x,y),(x+w,y+h),(0,255,0),1)
changePic(img)
# 绘制目标框
words['text'] = "细胞质面积:{} 细胞核面积:{} \n 拟合面积:{:.3f} {:.3f} \n 核质面积比:{:.3f}".format(whole_area, nucleus_area,
whole_area_ellipse,
nucleus_area_ellipse,
nucleus_area_ellipse / (
whole_area_ellipse - nucleus_area_ellipse))
return whole_area, nucleus_area, whole_area_ellipse, nucleus_area_ellipse
def handleLeftButtonReleaseEvent(e):
global scaleX1
global scaleX2
runDetect(scaleX1.get(), scaleX2.get())
path = StringVar()
Button(root, text='选择图片', command=choosepic).pack()
file_entry = Entry(root, state='readonly', text=path)
# file_entry.pack()
image_label = Label(root)
image_label.pack()
scaleX1 = Scale(root, from_=0, to=255, orient=HORIZONTAL, length=255)
scaleX2 = Scale(root, from_=0, to=255, orient=HORIZONTAL, length=255)
scaleX1.bind("", handleLeftButtonReleaseEvent)
scaleX2.bind("", handleLeftButtonReleaseEvent)
scaleX1.pack()
scaleX2.pack()
words = Label(root)
words.pack()
rec = Label(root)
rec.pack()
# plt.plot(list(ls),list(range(1,256)),linewidth=1,color='r',marker='o',markersize=0)
# plt.xlabel('Position(2-Theta)')
# plt.ylabel('Intensity')
# plt.legend()
# plt.show()
root.mainloop()