我tmd 烦死了,没有数据集?不好意思,我要白嫖!
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
推荐阅读31个Python实战项目教你掌握图像处理,PDF开放下载opencv_contrib扩展模块中文教程pdf,限时领取
上一篇我们讲到了如何白嫖一些免费的GPU
白嫖GPU,我们是认真的!
人工智能的发展离不开:数据、算法、算力 今天要分享的内容是关于数据如何获取 除了一些开源的数据集以及手动标注以外,我们是否还有其他办法获取呢?答案肯定是有的 我们可以利用一些平台提供的接口来白嫖数据集,来训练我们自己的模型,这样就变成我们的东西了,小机灵鬼,这是实际工作中非常有用。
当然要注意,调用这些平台的接口,实际上你的数据和标注数据也同样被平台获取了,如果是机密的数据,不建议这样子用。
本文以预测颜值的数据集获取为例,来进行分析
推荐项目:https://github.com/HCIILAB/SCUT-FBP5500-Database-Release (含数据集)
预测颜值可以看做是分类问题,也可以是回归问题。但无论是采用哪种方法去做,最基础的是要获取一张图片中人脸的位置信息 + 对应的颜值评分
测试图片:

结果:

看上去好像很复杂,实际上这些都可以用一个json来存储 描述一下json的信息 指出人脸的坐标,颜值,年龄等信息
接下来就是如何通过这些平台开放的免费接口来白嫖了 以百度的为例
大致步骤:
1、注册
2、代码编写
今天我们以百度的API 为例,获取颜值评分等标注信息。
1、注册账号
首先需要去 百度云平台(当然也可以去其他开放平台)注册一个账号,并创建一个应用 具体如下:
平台的地址:https://login.bce.baidu.com/?account=&redirect=http%3A%2F%2Fconsole.bce.baidu.com%2Fai%2F#/ai/roboticvision/overview/index
注册 & 应用创建说明:
http://www.atyun.com/35233.html
按照上述教程,创建应用之后,获取我们最关心的三个东西:

AppID、API Key、 Secret Key
接下来看一下我们可以白嫖的内容有哪些
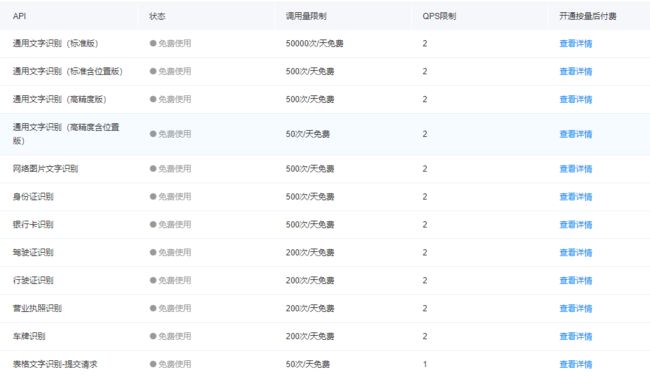
可以白嫖的东西很多,包括文字识别、身份证识别、车票识别、以及我们今天要用的颜值预测(属于人脸属性分析这块) 具体链接:https://cloud.baidu.com/product/face/detect
不过这些都是有一定限制的,比如每日的调用次数,毕竟白嫖嘛,不能太嚣张了
查看可以调用的类型 具体网址:
https://console.bce.baidu.com/ai/?_=1611544091386#/ai/roboticvision/overview/index
官方提供了一个在线上传获取结果的接口,但是对于我们来说,这远远不够。

因此,我们需要一个脚本能够批量的获取这些数据。
2、代码实现
from time import sleep
from aip import AipFace
import cv2
import base64
import numpy as np
import os
import traceback
import json
import tqdm
##cv2转base64
def cv2_base64(image):
base64_str = cv2.imencode('.jpg', image)[1].tobytes()
base64_str = base64.b64encode(base64_str)
return base64_str
##base64转cv2
def base64_cv2(base64_str):
imgString = base64.b64decode(base64_str)
nparr = np.fromstring(imgString, np.uint8)
image = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
return image
""" 你的 APPID AK SK """
APP_ID = '*****'
API_KEY = '*****'
SECRET_KEY = '*****'
client = AipFace(APP_ID, API_KEY, SECRET_KEY)
imageType = "BASE64"
""" 如果有可选参数 """
options = {}
options["face_field"] = "age,beauty"
options["max_face_num"] = 2
options["face_type"] = "LIVE"
options["liveness_control"] = "LOW"
error_time = 0
def predict(img_path):
"""
使用百度API 调用接口 返回人脸相关数据(年龄,颜值,矩形框位置等等)
:param img_path: 图片路径
:return:
"""
result = {"error_code": -1}
try:
# opencv 方式读取 读取出来为numpy
img_cv = cv2.imread(img_path)
img_cv = A.SmallestMaxSize(256)(image=img_cv)["image"]
# numpy -> base64 注意需要在最后加个 decode
image = cv2_base64(img_cv).decode('utf-8')
for i in range(3):
""" 带参数调用人脸检测 """
result = client.detect(image, imageType, options)
error_code = result["error_code"]
if error_code == 0 or error_code == 222202:
return result
sleep(1.0)
print(f"the {i+1} try error!")
print(img_path)
print(result)
except Exception as e:
print(traceback.format_exc())
return result
def write_label_json(label_json_path, result):
"""
将json写入到指定的文件下
:param label_json_path:写入的文件名称
:param result: 字典
:return:
"""
with open(label_json_path, "w") as f:
json.dump(result,f)
def write_log(log_path, msg):
with open(log_path, "a+") as f:
f.write(msg)
def make_label_json(root_path, img_path_name):
"""
label制作
:param root_path: 数据集存在的根目录
:param img_path_name: 图片存在的目录名称
:return:
"""
img_root_path = os.path.join(root_path, img_path_name)
img_name_ls = os.listdir(img_root_path)
img_path_ls = [os.path.join(img_root_path, img_name) for img_name in img_name_ls]
label_root_path = os.path.join(root_path, "label_json")
if not os.path.exists(label_root_path):
os.mkdir(label_root_path)
log_path = os.path.join(root_path, "error_img.txt")
write_log(log_path, "-----------------------------------\n")
error_json_dir_path = os.path.join(root_path, "error_json")
if not os.path.exists(error_json_dir_path):
os.mkdir(error_json_dir_path)
success_counts = 0
for i, img_path in tqdm.tqdm(list(enumerate(img_path_ls))):
result = predict(img_path)
img_name = img_name_ls[i]
name, ext = os.path.splitext(img_name)
label_name = name + ".json"
label_json_path = os.path.join(label_root_path, label_name)
if result["error_code"] != 0:
write_log(log_path, img_path + "\n")
write_label_json(os.path.join(error_json_dir_path, label_name), result)
else:
success_counts += 1
write_label_json(label_json_path, result)
sleep(0.5)
if i % 100 == 0:
print("成功检测:", success_counts)
print("成功检测:", success_counts)
root_path = "./"
img_path_name = "test"
make_label_json(root_path, img_path_name)
可能存在的问题:
# 1、no module named 'aip'
pip install baidu_aip
# 2、如果需要在vscode 中方便的查看 json文件, 可以考虑
# 安装json-tools
使用 ctrl + alt + m,切换显示风格
文件格式
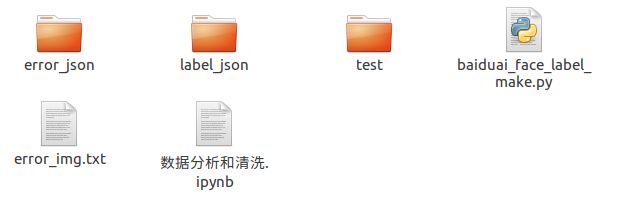
将所有需要标注的图片,都放在 test 文件夹下
最终输出结果会报错在 error_json和 label_json 文件夹下
打开一个json文件看看里面的内容:
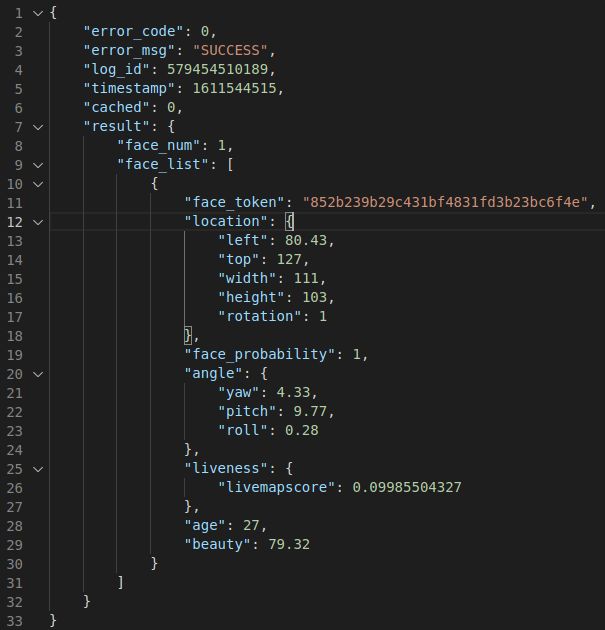
可以看到有我们需要的颜值信息(beauty),人脸位置、年龄信息等等
剩下的就是将获取的标注信息转换成模型需要的格式即
总结
是不是非常的实用
利用现有平台和工具生产我们所需要的东西,是非常重要的技能,如果对你有帮助,可以给我来三连!这是我周末加班写文章的动力!
个人微信(如果没有备注不拉群!)
请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2020
在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文
觉得不错就点亮在看吧