JavaScript之后端Web服务器开发Node.JS数据库访问学习篇
JavaScript之后端Web服务器开发Node.JS数据库访问学习篇
- 访问数据库
- 使用Sequelize
- 建立Model
访问数据库
访问数据库
程序运行的时候,数据都是在内存中的。当程序终止的时候,通常都需要将数据保存到磁盘上,无论是保存到本地磁盘,还是通过网络保存到服务器上,最终都会将数据写入磁盘文件。
而如何定义数据的存储格式就是一个大问题。如果我们自己来定义存储格式,比如保存一个班级所有学生的成绩单:
名字 成绩
Michael 99
Bob 85
Bart 59
Lisa 87
可以用一个文本文件保存,一行保存一个学生,用,隔开:
Michael,99
Bob,85
Bart,59
Lisa,87
还可以用JSON格式保存,也是文本文件:
[
{"name":"Michael","score":99},
{"name":"Bob","score":85},
{"name":"Bart","score":59},
{"name":"Lisa","score":87}
]
还可以自己定义各种保存格式,但是问题来了:
- 存储和读取需要自己实现,JSON还是标准,自己定义的格式就各式各样了;
- 不能做快速查询,只有把数据全部读到内存中才能自己遍历,但有时候数据的大小远远超过了内存(比如蓝光电影,40GB的数据),根本无法全部读入内存。
为了便于程序保存和读取数据,而且,能直接通过条件快速查询到指定的数据,就出现了数据库(Database)这种专门用于集中存储和查询的软件。
数据库软件诞生的历史非常久远,早在1950年数据库就诞生了。经历了网状数据库,层次数据库,我们现在广泛使用的关系数据库是20世纪70年代基于关系模型的基础上诞生的。关系模型有一套复杂的数学理论,但是从概念上是十分容易理解的。举个学校的例子:
假设某个XX省YY市ZZ县第一实验小学有3个年级,要表示出这3个年级,可以在Excel中用一个表格画出来:

每个年级又有若干个班级,要把所有班级表示出来,可以在Excel中再画一个表格:
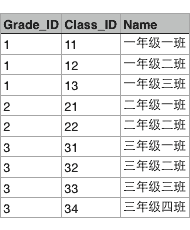
这两个表格有个映射关系,就是根据Grade_ID可以在班级表中查找到对应的所有班级:

也就是Grade表的每一行对应Class表的多行,在关系数据库中,这种基于表(Table)的一对多的关系就是关系数据库的基础。
根据某个年级的ID就可以查找所有班级的行,这种查询语句在关系数据库中称为SQL语句,可以写成:
SELECT * FROM classes WHERE grade_id = '1';
结果也是一个表:
---------+----------+----------
grade_id | class_id | name
---------+----------+----------
1 | 11 | 一年级一班
---------+----------+----------
1 | 12 | 一年级二班
---------+----------+----------
1 | 13 | 一年级三班
---------+----------+----------
类似的,Class表的一行记录又可以关联到Student表的多行记录:
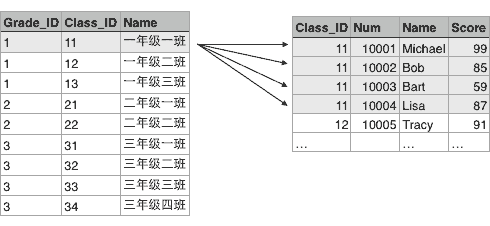
NoSQL
NoSQL数据库,很多NoSQL宣传其速度和规模远远超过关系数据库,所以有了NoSQL是否就不需要SQL了呢?
数据库类别
既然要使用关系数据库,就必须选择一个关系数据库。目前广泛使用的关系数据库也就这么几种:
付费的商用数据库:
Oracle,典型的高富帅;
SQL Server,微软自家产品,Windows定制专款;
DB2,IBM的产品,听起来挺高端;
Sybase,曾经跟微软是好基友,后来关系破裂,现在家境惨淡。
这些数据库都是不开源而且付费的,最大的好处是花了钱出了问题可以找厂家解决,不过在Web的世界里,常常需要部署成千上万的数据库服务器,当然不能把大把大把的银子扔给厂家,所以,无论是Google、Facebook,还是国内的BAT,无一例外都选择了免费的开源数据库:
免费开源数据库:
MySQL,大家都在用,一般错不了;
PostgreSQL,学术气息有点重,其实挺不错,但知名度没有MySQL高;
sqlite,嵌入式数据库,适合桌面和移动应用。
作为一个JavaScript全栈工程师,选择哪个免费数据库呢?当然是MySQL。因为MySQL普及率最高,出了错,可以很容易找到解决方法。而且,围绕MySQL有一大堆监控和运维的工具,安装和使用很方便。
安装MySQL
为了能继续后面的学习,需要从MySQL官方网站下载并安装MySQL Community Server 5.6,这个版本是免费的,其他高级版本是要收钱的。MySQL是跨平台的,选择对应的平台下载安装文件,安装即可。安装时,MySQL会提示输入root用户的口令,请务必记清楚。如果怕记不住,就把口令设置为password。
在Windows上,安装时请选择UTF-8编码,以便正确地处理中文。
在Mac或Linux上,需要编辑MySQL的配置文件,把数据库默认的编码全部改为UTF-8。MySQL的配置文件默认存放在/etc/my.cnf或者/etc/mysql/my.cnf:
[client]
default-character-set = utf8
[mysqld]
default-storage-engine = INNODB
character-set-server = utf8
collation-server = utf8_general_ci
重启MySQL后,可以通过MySQL的客户端命令行检查编码:
$ mysql -u root -p
Enter password:
Welcome to the MySQL monitor...
...
mysql> show variables like '%char%';
+--------------------------+--------------------------------------------------------+
| Variable_name | Value |
+--------------------------+--------------------------------------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/local/mysql-5.1.65-osx10.6-x86_64/share/charsets/ |
+--------------------------+--------------------------------------------------------+
8 rows in set (0.00 sec)
看到utf8字样就表示编码设置正确。
使用Sequelize
访问MySQL
当我们安装好MySQL后,Node.js程序如何访问MySQL数据库呢?
访问MySQL数据库只有一种方法,就是通过网络发送SQL命令,然后,MySQL服务器执行后返回结果。
我们可以在命令行窗口输入mysql -u root -p,然后输入root口令后,就连接到了MySQL服务器。因为没有指定--host参数,所以我们连接到的是localhost,也就是本机的MySQL服务器。
在命令行窗口下,可以输入命令,操作MySQL服务器:
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
+--------------------+
4 rows in set (0.05 sec)
输入exit退出MySQL命令行模式。
对于Node.js程序,访问MySQL也是通过网络发送SQL命令给MySQL服务器。这个访问MySQL服务器的软件包通常称为MySQL驱动程序。不同的编程语言需要实现自己的驱动,MySQL官方提供了Java、.Net、Python、Node.js、C++和C的驱动程序,官方的Node.js驱动目前仅支持5.7以上版本,而我们上面使用的命令行程序实际上用的就是C驱动。
目前使用最广泛的MySQL Node.js驱动程序是开源的mysql,可以直接使用npm安装。
ORM
如果直接使用mysql包提供的接口,我们编写的代码就比较底层,例如,查询代码:
connection.query('SELECT * FROM users WHERE id = ?', ['123'], function(err, rows) {
if (err) {
// error
} else {
for (let row in rows) {
processRow(row);
}
}
});
考虑到数据库表是一个二维表,包含多行多列,例如一个pets的表:
mysql> select * from pets;
+----+--------+------------+
| id | name | birth |
+----+--------+------------+
| 1 | Gaffey | 2007-07-07 |
| 2 | Odie | 2008-08-08 |
+----+--------+------------+
2 rows in set (0.00 sec)
每一行可以用一个JavaScript对象表示,例如第一行:
{
"id": 1,
"name": "Gaffey",
"birth": "2007-07-07"
}
这就是传说中的ORM技术:Object-Relational Mapping,把关系数据库的表结构映射到对象上。是不是很简单?但是由谁来做这个转换呢?所以ORM框架应运而生。
选择Node的ORM框架Sequelize来操作数据库。这样,读写的都是JavaScript对象,Sequelize帮我们把对象变成数据库中的行。用Sequelize查询pets表,代码像这样:
Pet.findAll()
.then(function (pets) {
for (let pet in pets) {
console.log(`${
pet.id}: ${
pet.name}`);
}
}).catch(function (err) {
// error
});
因为Sequelize返回的对象是Promise,所以我们可以用then()和catch()分别异步响应成功和失败。但是用then()和catch()仍然比较麻烦。有没有更简单的方法呢?
可以用ES7的await来调用任何一个Promise对象,这样写出来的代码就变成了:
var pets = await Pet.findAll();
await只有一个限制,就是必须在async函数中调用。上面的代码直接运行还差一点,可以改成:
(async () => {
var pets = await Pet.findAll();
})();
考虑到koa的处理函数都是async函数,所以我们实际上将来在koa的async函数中直接写await访问数据库就可以了!这也是为什么我们选择Sequelize的原因:只要API返回Promise,就可以用await调用,写代码就非常简单!
实战
在使用Sequlize操作数据库之前,我们先在MySQL中创建一个表来测试。我们可以在test数据库中创建一个pets表。test数据库是MySQL安装后自动创建的用于测试的数据库。在MySQL命令行执行下列命令:
grant all privileges on test.* to 'www'@'%' identified by 'www';
use test;
create table pets (
id varchar(50) not null,
name varchar(100) not null,
gender bool not null,
birth varchar(10) not null,
createdAt bigint not null,
updatedAt bigint not null,
version bigint not null,
primary key (id)
) engine=innodb;
第一条grant命令是创建MySQL的用户名和口令,均为www,并赋予操作test数据库的所有权限。
第二条use命令把当前数据库切换为test。
第三条命令创建了pets表。
然后,根据前面的工程结构创建hello-sequelize工程,结构如下:
hello-sequelize/
|
+- .vscode/
| |
| +- launch.json <-- VSCode 配置文件
|
+- init.txt <-- 初始化SQL命令
|
+- config.js <-- MySQL配置文件
|
+- app.js <-- 使用koa的js
|
+- package.json <-- 项目描述文件
|
+- node_modules/ <-- npm安装的所有依赖包
然后,添加如下依赖包:
"sequelize": "3.24.1",
"mysql": "2.11.1"
注意mysql是驱动,我们不直接使用,但是sequelize会用。用npm install安装。
config.js实际上是一个简单的配置文件:
var config = {
database: 'test', // 使用哪个数据库
username: 'www', // 用户名
password: 'www', // 口令
host: 'localhost', // 主机名
port: 3306 // 端口号,MySQL默认3306
};
module.exports = config;
下面,就可以在app.js中操作数据库了。使用Sequelize操作MySQL需要先做两件准备工作:
第一步,创建一个sequelize对象实例:
const Sequelize = require('sequelize');
const config = require('./config');
var sequelize = new Sequelize(config.database, config.username, config.password, {
host: config.host,
dialect: 'mysql',
pool: {
max: 5,
min: 0,
idle: 30000
}
});
第二步,定义模型Pet,告诉Sequelize如何映射数据库表:
var Pet = sequelize.define('pet', {
id: {
type: Sequelize.STRING(50),
primaryKey: true
},
name: Sequelize.STRING(100),
gender: Sequelize.BOOLEAN,
birth: Sequelize.STRING(10),
createdAt: Sequelize.BIGINT,
updatedAt: Sequelize.BIGINT,
version: Sequelize.BIGINT
}, {
timestamps: false
});
用sequelize.define()定义Model时,传入名称pet,默认的表名就是pets。第二个参数指定列名和数据类型,如果是主键,需要更详细地指定。第三个参数是额外的配置,我们传入{ timestamps: false }是为了关闭Sequelize的自动添加timestamp的功能。所有的ORM框架都有一种很不好的风气,总是自作聪明地加上所谓“自动化”的功能,但是会让人感到完全摸不着头脑。
接下来,我们就可以往数据库中塞一些数据了。我们可以用Promise的方式写:
var now = Date.now();
Pet.create({
id: 'g-' + now,
name: 'Gaffey',
gender: false,
birth: '2007-07-07',
createdAt: now,
updatedAt: now,
version: 0
}).then(function (p) {
console.log('created.' + JSON.stringify(p));
}).catch(function (err) {
console.log('failed: ' + err);
});
也可以用await写:
(async () => {
var dog = await Pet.create({
id: 'd-' + now,
name: 'Odie',
gender: false,
birth: '2008-08-08',
createdAt: now,
updatedAt: now,
version: 0
});
console.log('created: ' + JSON.stringify(dog));
})();
显然await代码更胜一筹。查询数据时,用await写法如下:
(async () => {
var pets = await Pet.findAll({
where: {
name: 'Gaffey'
}
});
console.log(`find ${
pets.length} pets:`);
for (let p of pets) {
console.log(JSON.stringify(p));
}
})();
如果要更新数据,可以对查询到的实例调用save()方法:
(async () => {
var p = await queryFromSomewhere();
p.gender = true;
p.updatedAt = Date.now();
p.version ++;
await p.save();
})();
如果要删除数据,可以对查询到的实例调用destroy()方法:
(async () => {
var p = await queryFromSomewhere();
await p.destroy();
})();
运行代码,可以看到Sequelize打印出的每一个SQL语句,便于我们查看:
Executing (default): INSERT INTO `pets` (`id`,`name`,`gender`,`birth`,`createdAt`,`updatedAt`,`version`) VALUES ('g-1471961204219','Gaffey',false,'2007-07-07',1471961204219,1471961204219,0);
Model
把通过sequelize.define()返回的Pet称为Model,它表示一个数据模型。把通过Pet.findAll()返回的一个或一组对象称为Model实例,每个实例都可以直接通过JSON.stringify序列化为JSON字符串。但是它们和普通JSON对象相比,多了一些由Sequelize添加的方法,比如save()和destroy()。调用这些方法我们可以执行更新或者删除操作。
所以,使用Sequelize操作数据库的一般步骤就是:
首先,通过某个Model对象的findAll()方法获取实例;
如果要更新实例,先对实例属性赋新值,再调用save()方法;
如果要删除实例,直接调用destroy()方法。
注意findAll()方法可以接收where、order这些参数,这和将要生成的SQL语句是对应的。
建立Model
直接使用Sequelize虽然可以,但是存在一些问题。团队开发时,有人喜欢自己加timestamp:
var Pet = sequelize.define('pet', {
id: {
type: Sequelize.STRING(50),
primaryKey: true
},
name: Sequelize.STRING(100),
createdAt: Sequelize.BIGINT,
updatedAt: Sequelize.BIGINT
}, {
timestamps: false
});
有人又喜欢自增主键,并且自定义表名:
var Pet = sequelize.define('pet', {
id: {
type: Sequelize.INTEGER,
autoIncrement: true,
primaryKey: true
},
name: Sequelize.STRING(100)
}, {
tableName: 't_pet'
});
一个大型Web App通常都有几十个映射表,一个映射表就是一个Model。如果按照各自喜好,那业务代码就不好写。Model不统一,很多代码也无法复用。所以我们需要一个统一的模型,强迫所有Model都遵守同一个规范,这样不但实现简单,而且容易统一风格。
首先要定义的就是Model存放的文件夹必须在models内,并且以Model名字命名,例如:Pet.js,User.js等等。
其次,每个Model必须遵守一套规范:
- 统一主键,名称必须是id,类型必须是STRING(50);
- 主键可以自己指定,也可以由框架自动生成(如果为null或undefined);
- 所有字段默认为NOT NULL,除非显式指定;
- 统一timestamp机制,每个Model必须有createdAt、updatedAt和version,分别记录创建时间、修改时间和版本号。其中,createdAt和updatedAt以BIGINT存储时间戳,最大的好处是无需处理时区,排序方便。version每次修改时自增。
所以,不要直接使用Sequelize的API,而是通过db.js间接地定义Model。例如,User.js应该定义如下:
const db = require('../db');
module.exports = db.defineModel('users', {
email: {
type: db.STRING(100),
unique: true
},
passwd: db.STRING(100),
name: db.STRING(100),
gender: db.BOOLEAN
});
这样,User就具有email、passwd、name和gender这4个业务字段。id、createdAt、updatedAt和version应该自动加上,而不是每个Model都去重复定义。
所以,db.js的作用就是统一Model的定义:
const Sequelize = require('sequelize');
console.log('init sequelize...');
var sequelize = new Sequelize('dbname', 'username', 'password', {
host: 'localhost',
dialect: 'mysql',
pool: {
max: 5,
min: 0,
idle: 10000
}
});
const ID_TYPE = Sequelize.STRING(50);
function defineModel(name, attributes) {
var attrs = {
};
for (let key in attributes) {
let value = attributes[key];
if (typeof value === 'object' && value['type']) {
value.allowNull = value.allowNull || false;
attrs[key] = value;
} else {
attrs[key] = {
type: value,
allowNull: false
};
}
}
attrs.id = {
type: ID_TYPE,
primaryKey: true
};
attrs.createdAt = {
type: Sequelize.BIGINT,
allowNull: false
};
attrs.updatedAt = {
type: Sequelize.BIGINT,
allowNull: false
};
attrs.version = {
type: Sequelize.BIGINT,
allowNull: false
};
return sequelize.define(name, attrs, {
tableName: name,
timestamps: false,
hooks: {
beforeValidate: function (obj) {
let now = Date.now();
if (obj.isNewRecord) {
if (!obj.id) {
obj.id = generateId();
}
obj.createdAt = now;
obj.updatedAt = now;
obj.version = 0;
} else {
obj.updatedAt = Date.now();
obj.version++;
}
}
}
});
}
我们定义的defineModel就是为了强制实现上述规则。Sequelize在创建、修改Entity时会调用我们指定的函数,这些函数通过hooks在定义Model时设定。我们在beforeValidate这个事件中根据是否是isNewRecord设置主键(如果主键为null或undefined)、设置时间戳和版本号。这么一来,Model定义的时候就可以大大简化。
数据库配置
接下来,我们把简单的config.js拆成3个配置文件:
- config-default.js:存储默认的配置;
- config-override.js:存储特定的配置;
- config-test.js:存储用于测试的配置。
例如,默认的config-default.js可以配置如下:
var config = {
dialect: 'mysql',
database: 'nodejs',
username: 'www',
password: 'www',
host: 'localhost',
port: 3306
};
module.exports = config;
而config-override.js可应用实际配置:
var config = {
database: 'production',
username: 'www',
password: 'secret-password',
host: '192.168.1.199'
};
module.exports = config;
config-test.js可应用测试环境的配置:
var config = {
database: 'test'
};
module.exports = config;
读取配置的时候,我们用config.js实现不同环境读取不同的配置文件:
const defaultConfig = './config-default.js';
// 可设定为绝对路径,如 /opt/product/config-override.js
const overrideConfig = './config-override.js';
const testConfig = './config-test.js';
const fs = require('fs');
var config = null;
if (process.env.NODE_ENV === 'test') {
console.log(`Load ${
testConfig}...`);
config = require(testConfig);
} else {
console.log(`Load ${
defaultConfig}...`);
config = require(defaultConfig);
try {
if (fs.statSync(overrideConfig).isFile()) {
console.log(`Load ${
overrideConfig}...`);
config = Object.assign(config, require(overrideConfig));
}
} catch (err) {
console.log(`Cannot load ${
overrideConfig}.`);
}
}
module.exports = config;
具体的规则是:
先读取config-default.js;
如果不是测试环境,就读取config-override.js,如果文件不存在,就忽略。
如果是测试环境,就读取config-test.js。
这样做的好处是,开发环境下,团队统一使用默认的配置,并且无需config-override.js。部署到服务器时,由运维团队配置好config-override.js,以覆盖config-override.js的默认设置。测试环境下,本地和CI服务器统一使用config-test.js,测试数据库可以反复清空,不会影响开发。
配置文件表面上写起来很容易,但是,既要保证开发效率,又要避免服务器配置文件泄漏,还要能方便地执行测试,就需要一开始搭建出好的结构,才能提升工程能力。
使用Model
要使用Model,就需要引入对应的Model文件,例如:User.js。一旦Model多了起来,如何引用也是一件麻烦事。自动化永远比手工做效率高,而且更可靠。我们写一个model.js,自动扫描并导入所有Model:
const fs = require('fs');
const db = require('./db');
let files = fs.readdirSync(__dirname + '/models');
let js_files = files.filter((f)=>{
return f.endsWith('.js');
}, files);
module.exports = {
};
for (let f of js_files) {
console.log(`import model from file ${
f}...`);
let name = f.substring(0, f.length - 3);
module.exports[name] = require(__dirname + '/models/' + f);
}
module.exports.sync = () => {
db.sync();
};
这样,需要用的时候,写起来就像这样:
const model = require('./model');
let
Pet = model.Pet,
User = model.User;
var pet = await Pet.create({
... });
工程结构
最终,我们创建的工程model-sequelize结构如下:
model-sequelize/
|
+- .vscode/
| |
| +- launch.json <-- VSCode 配置文件
|
+- models/ <-- 存放所有Model
| |
| +- Pet.js <-- Pet
| |
| +- User.js <-- User
|
+- config.js <-- 配置文件入口
|
+- config-default.js <-- 默认配置文件
|
+- config-test.js <-- 测试配置文件
|
+- db.js <-- 如何定义Model
|
+- model.js <-- 如何导入Model
|
+- init-db.js <-- 初始化数据库
|
+- app.js <-- 业务代码
|
+- package.json <-- 项目描述文件
|
+- node_modules/ <-- npm安装的所有依赖包
注意到我们其实不需要创建表的SQL,因为Sequelize提供了一个sync()方法,可以自动创建数据库。这个功能在开发和生产环境中没有什么用,但是在测试环境中非常有用。测试时,我们可以用sync()方法自动创建出表结构,而不是自己维护SQL脚本。这样,可以随时修改Model的定义,并立刻运行测试。开发环境下,首次使用sync()也可以自动创建出表结构,避免了手动运行SQL的问题。
init-db.js的代码非常简单:
const model = require('./model.js');
model.sync();
console.log('init db ok.');
process.exit(0);
它最大的好处是避免了手动维护一个SQL脚本。