声明
本文非本人原创,是对文献[1]、文献[2]和文献[3]的摘要总结,重点放在了隐私计算相关技术原理及其应用的介绍上,但是并不涉及技术细节。本博客仅发表在博客园,作者LightningStar,其他平台均为转载。
前言
隐私计算是在实现保护数据拥有者的权益安全及个人隐私的前提下,实现数据的流通及数据价值深度挖掘的一类重要方法,在一系列信息技术对数据进行分析计算的过程中,保障数据在流通与融合过程中的“可用不可见”。
隐私计算是指在保护数据本身不对外泄露的前提下实现数据分析计算的一类信息技术,包含了数据科学、密码学、人工智能等众多技术体系的交叉融合。从技术实现原理上看,隐私计算主要分为密码学和可信硬件两大领域。 密码学技术目前以多方安全计算为代表;可信硬件领域则主要指可信执行环境;此外,还有基于以上两种技术路径衍生出的联邦学习等相关应用技术。

在软硬件结构上,多方安全计算和联邦学习通常从软件层面设计安全框架,以通用硬件作为底层基础架构;可信执行环境则是以可信硬件为底层技术实现的。
在算法构造上,多方安全计算技术基于各类密码学工具设计不同的安全协议;联邦学习除可将多方安全计算协议作为其隐私保护的技术支撑外,基于噪声扰动的差分隐私技术也广泛应用于联邦学习框架中;可信执行环境通常与一些密码学算法、安全协议相结合为多方数据提供保护隐私的安全计算。
隐私计算主流技术
隐私计算领域的一些主流技术,包括多方安全计算、可信执行环境、联邦学习等.
多方安全计算
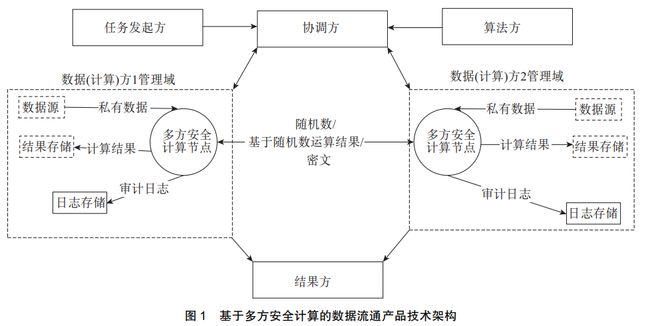
多方安全计算核心是设计特殊的加密算法和协议,基于密码学原理实现在无可信第三方的情况下,在多个参与方输入的加密数据之上直接进行计算。每个参与方不能得到其他参与方的任何输入信息,只能得到计算结果。
基础技术
多方安全计算的实现包含多个关键的底层密码学协议或框架:
- 不经意传输(Oblivious Transfer)
提出了一种在数据传输与交互过程中保护隐私的思路。在不经意传输协议中,数据发送方同时发送多个消息,而接收方仅获取其中之一。发送方无法判断接收方获取了具体哪个消息,接收方也对其他消息的内容一无所知。不经意传输常用构造多方安全计算协议,是GMW协议、混淆电路设计、乘法三元组的基础构件,还可用于实现隐私集合求交( Private SetIntersection,PSI)、隐私信息检索( Private Information Retrieval,PIR)等多种多方安全计算功能。 - 混淆电路(Garbled Circuit)
是一种将计算任务转化为布尔电路并对真值表进行加密打乱等混淆操作以保护输入隐私的思路。 利用计算机编程将目标函数转化为布尔电路后,对每一个门输出的真值进行加密,参与方之间在互相不掌握对方私有数据的情况下共同完成计算。 混淆电路是姚期智院士针对百万富翁问题提出的解决方案,因此又称姚氏电路。该技术可实现各种计算,常用于通用计算场景,通信量大但通信轮数固定,适用于高带宽高延迟场景。秘密分享计算量小、通信量较低,构造多方加法、乘法以及其他更复杂的运算有特别的优势,能实现联合统计、建模、预测等多种功能。 - 秘密分享(Secret Sharing)
也称秘密分割或秘密共享,给出了一种分而治之的秘密信息管理方案。 秘密分享的原理是将秘密拆分成多个分片(Share),每个分片交由不同的参与方管理。 只有超过一定门限数量的若干个参与方共同协作才能还原秘密信息,仅通过单一分片无法破解秘密。
技术特点
多方安全计算能够在不泄漏任何隐私数据的情况下让多方数据共同参与计算,然后获得准确的结果,可以使多个非互信主体在数据相互保密的前提下进行高效数据融合计算,达到“数据可用不可见”。最终实现数据的所有权和数据使用权相互分离,并控制数据的用途和用量,即某种程度上的用途可控可计量。多方安全计算具有很高的安全性,要求敏感的中间计算结果也不可以泄漏,并且在近40年的发展中其各种核心技术和构造方案不断接受学术界和工业界的检验具有很高的可信性,其性能在各种研究中不断提升,现在在很多场景下已经达到了产业能实际应用接受的程度。
发展
微软研究院自 2011 年开始大规模推进多方安全计算的研究,从两方安全计算入手,逐渐拓展至三方计算和不存在交互行为的多方计算。 但微软前期的MPC研究存在两个瓶颈,一是加密协议只针对一些简单的分析功能有效,如聚类分析、线性回归等;二是计算的执行必须运行在低水平的与或门电路中,执行过程麻烦而低效。 2018 年,微软印度研究院推出了EzPC项目,希望克服上述两个问题。 作为一个高效、可扩展的 MPC 协议,EzPC 是一个加密成本感知编译器,使用算术和布尔电路的组合,通过高级语言执行计算,支持神经网络训练和预测等复杂的算法。
可信执行环境
可信执行环境(Trusted Execution Environment, TEE)的核心思想是构建一个独立于操作系统而存在的可信的、隔离的机密空间,数据计算仅在该安全环境内进行,通过依赖可信硬件来保障其安全。
可信执行环境的最本质属性是隔离,通过芯片等硬件技术并与上层软件协同对数据进行保护,且同时保留与系统运行环境之间的算力共享。
可信执行环境通过软硬件方法在CPU中构建一个安全的区域,保证其内部加载的程序和数据在机密性和完整性上得到保护。

从底层硬件来说,不同于多方安全计算和联邦学习,TEE将多方数据集中到可信硬件构建的可信执行环境中一起进行安全计算。TEE中可信硬件一般是指可信执行控制单元已被预置集成的商用CPU计算芯片。从基础算法来说,为了保证传输至可信环境中的数据的安全性,TEE常结合相关密码学算法来实现加密和验证方案.从应用角度来说,作为通用的计算平台,TEE可以在可信执行环境中对多方数据完成联合统计、联合查询、联合建模及预测等各种安全计算。
严格来讲,可信执行环境并不属于“数据可用不可见”,但其通用性高、开发难度低,在通用计算、复杂算法的实现上更为灵活,使得其在数据保护要求不是特别严苛的场景下仍有很多发挥价值的空间。

Intel SGX
Intel SGX技术是一组预置在 Intel商用计算芯片内的用于增强应用程序代码和数据安全性的指令,主要面向PC端。开发者使用SGX指令把计算应用程序的安全计算过程封装在一个被称为飞地( Enclave)的容器内,保障用户关键代码和数据的机密性和完整性。Intel SGX将应用程序以外的软件栈(如OS、BIOS等)都排除在可信计算基( Trusted Computing Base,TCB)以外,一旦软件和数据位于 Encalve中,即便是操作系统和虚拟机监视器( Virtual MachineMonitor,VMM)(也称 Hypervisor)也无法影响 Enclave里面的代码和数据,从而在安全隔离的情况下保证软件功能的通用性。
ARM TrustZone
Armtrustzone技术基于ARM芯片,主要面向移动设备,是用于ARM指令集体系结构的TEE.ARM通过对原有硬件架构进行修改,在处理器层次引入了两个不同权限的保护域一一安全世界和普通世界,任何时刻处理器仅在其中的一个环境内运行。 Trustzone通过中断路由以及对内存总线和内存管理单元的限制来提供隔离保护。
技术特点
TEE通过隔离的执行环境,提供一个执行空间,该空间有更强的安全性,比安全芯片功能更丰富,提供代码和数据的机密性和完整性保护。另外,与纯软件的密码学隐私保护方案相比,TEE不会对隐私区域内的算法逻辑语言有可计算性方面的限制,支持更多的算子及复杂算法,上层业务表达性更强。利用TEE提供的计算度量功能,还可实现运行在其内部的身份、数据、算法全流程的计算一致性证明。
TEE因支持多层次、高复杂度的算法逻辑实现,运算效率高以及可信度量保证运行逻辑可信等的特点,被广泛认可,但其技术本身依赖硬件环境,CPU相关实现属于TCB,由芯片设备的设计生产厂商提供,必须确保芯片厂商可信。此外使用MPC等密码学技术与TEE技术相结合可以增强其安全性,强化TEE实例之间机密通信和组网的安全性,进一步防止隐私数据泄露。
发展
目前主要的通用计算芯片厂商发布的TEE技术方案包括X86指令集架构的 Intel SGX( Intel Software Guard Extensions)技术、AMDSEV( Secure Encrypted Virtualization)技术以及高级RISC机器( Advanced RISC Machine,ARM)指令集架构的 Trustzone技术。而国内计算芯片厂商推出的TEE功能则包括兆芯ZX-TCT( TrustedComputing Technology)技术、海光CSV( China Security Virtualization技术,以及ARM架构的飞腾、鯤鹏也已推出自主实现的 TrustZone功能。 由此诞生了很多基于以上产品的商业化实现方案,如百度 MesaTEE、华为 iTrustee 等。
Intel 的 SGX 和 ARM 的 TrustZone 处于 TEE 硬件的垄断地位。 TrustZone 在2008 年推出,而 SGX 最早在 2013 年推出,目前市场上可信执行环境的商业化落地都是基于 TrustZone 或 SGX 的解决方案。
联邦学习
联邦学习(Federated Learning, FL)的本质是分布式的机器学习,在保证数据隐私安全的基础上,实现共同建模,提升模型的效果。联邦学习是实现本地原始数据不出库的情况下,通过对中间加密数据的流通与处理来完成多方联合的机器学习训练。联邦学习参与方一般包括数据方、算法方、协调方、计算方、结果方、任务发起方等角色。

根据数据集分类
联邦学习的目标是在不聚合参与方原始数据的前提下,实现保护终端数据隐私的联合建模。 根据数据集的不同类型,联邦学习分为横向联邦学习、纵向联邦学习与联邦迁移学习。

- 横向联邦学习
横向联邦学习更适用于在特征重合较多,而样本重合较少的数据集间进行联合计算的场景。 以样本维度(即横向)对数据集进行切分,以特征相同而样本不完全相同的数据部分为对象进行训练。 - 纵向联邦学习
纵向联邦学习适用于样本重合较多,而特征重合较少的数据集间联合计算的场景。以特征维度对数据集进行切分,以样本相同而特征不完全相同的数据部分为对象进行训练。 - 联邦迁移学习
联邦迁移学习则适用于数据集间样本和特征重合均较少的场景。在这样的场景下,不再对数据进行切分,而是利用迁移学习来弥补数据或标签的不足。
根据拓扑结构分类
如何有效协调数据参与方协同构建模型是联邦学的一项主要工作。因此,根据协调方式的不同,联邦学习从拓扑架构的角度分析可分类为集中式拓扑架构和对等网络拓扑架构。
- 集中式拓扑结构
一般存在一个聚合各方本地模型参数信息的中心计算节点,该节点经过联邦平均等相应算法更新后,将结果返回各方。其中,中心计算节点既可能是独立于各参与方的第三方服务器,也可能是某一特定的参与方。优势在于易于设计与实现,往往被认为效率更高,但是在一定程度上牺牲了安全性。 - 对等式网络拓扑机构
不存在中心计算节点,各参与方在联邦学习框架中的地位平等。分布式的网络拓扑结构安全性更高。但需要平等对待联邦学习中的每个参与者且能够使参与方有效更新模型并提升性能,设计难度较大。
发展
谷歌是联邦学习的引路人,自 2017 年 4 月,谷歌便提出了联邦学习的概念,并于 2019 年发布论文给出了可扩展大规模移动端联邦系统的描述,用于改进谷歌输入法的自动关联与推荐。 但与此同时,2019 年 8月,谷歌又开源了名为 Private Join and Compute 的新型多方安全计算开源库,结合了隐私求交和同态加密两种基本的加密技术,帮助各组织和隐私数据集协同工作,针对个别项目还使用随机密钥进行高度加密,提高隐私性。
技术对比
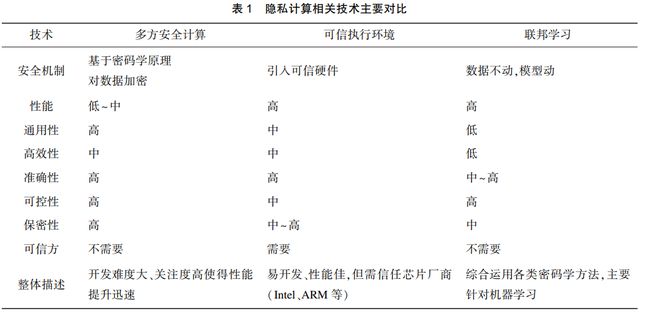
- 多方安全计算不依赖硬件且具备较高的安全性,但是仅支持一些相对简单的运算逻辑
- 可信执行环境技术具备更好的性能和算法适用性,但是对硬件有一定依赖性
- 联邦学习技术则可以解决复杂的算法建模问题,但是性能存在一定瓶颈
从技术路径上看,各国际企业相对更关注基于可信执行环境的隐私计算。 2019 年成立的 Linus 基金会旗 下 的 机 密 计 算 联 盟 ( Confidential Computing Consortium)便聚焦于此,关注基于可信硬件和云服务生态的数据安全。 该联盟的创始会员包括阿里、腾讯、ARM、谷歌、Intel、微软、百度、华为等世界级企业,2020年 AMD、英伟达、埃森哲、R3 等新一批知名企业也陆续加入。
隐私计算其他相关技术
同态加密
同态加密( Homomorphic Encryption,HE),能实现在密文上进行计算后对输出进行解密,得到的结果和直接对明文计算的结果一致。该概念最早在1978年由 Ron Rivest、 Leonard Adleman和 Michael I.Dertouzo提出,已发展出各种半同态加密和全同态加密算法。同态加密算法以通信量小、通信轮数少的特点,已在多方安全计算、联邦学习、区块链等存在数据隐私计算需求的场景落地应用。
同态加密计算开销大,通信开销小,安全性高,可用于联邦学习安全聚合】构造MPC协议。
零知识证明
零知识证明(Zero- Knowledge Proof,ZKP),由S. Goldwasser)S. Micali及C. Rackoff在20世纪80年代初首先提出,指的是证明者能够在不向验证者泄漏任何有用信息的情况下,使验证者相信某个论断是正确的。零知识证明是一种两方或多方的协议,两方或多方通过系列交互完成生成证明和验证。在实际应用中,零知识证明能实现证明者向验证者证明并使其相信自己知道或拥有某一消息,而证明过程不会向验证者泄漏任何关于被证明消息的信息。
零知识证明广泛应用于各类安全协议设计中,是各类认证协议的基础。
差分隐私
差分隐私( Differential Privacy,DP)技术是 Dwork在2006年针对数据库的隐私泄露问题提出的一种新型密码学手段。该机制是在源数据或计算结果上添加特定分布的噪音,确保各参与方无法通过得到的数据分析出数据集中是否包含某一特定实体。差分隐私包括本地差分隐私和计算结果差分隐私。本地差分隐私指在汇聚和计算前数据就加入噪声,用于数据收集方不可信的场景;计算结果差分隐私是指最终计算结果发布前对其加噪声。
差分隐私的计算和通信性能与直接明文计算几乎无区别,安全性损失依赖于噪声大小。
隐私计算中的信任问题
信任机制是隐私计算广泛应用的关键,隐私计算技术自诞生以来的重要使命便是保证隐私数据在被利用的过程中不被泄露。 作为一项新技术,如何自证安全、持续强化安全、建立市场信任是其能否被广泛应用的关键。
- 自证安全是隐私计算应用的瓶颈问题,当前隐私计算应用主要通过深入介绍产品保密算法机制、签订严格保密协议和引入第三方评测机构评测产品来实现。
- 持续强化安全是隐私计算应用的长效保障,目前主要通过不断优化算法来防范恶意攻击,以更加严格地控制计算流程来封堵漏洞等方式实现。
- 建立市场信任是隐私计算应用的关键问题,在隐私计算的过程中,通过严格的数据授权、身份验证、状态监控预警等方式让数据提供方始终清楚己方数据的用量、用法、用途均不超过实现约定,可以充分建立用户新人乃至市场信任。
隐私计算技术产品
我国的隐私计算技术产业化在2018年后开始进人快速启动阶段,形成了互联网大厂、大数据公司、运营商、金融机构和金融科技企业、隐私计算初创企业为代表的五大类市场主要参与者。
| 技术路线 | 参与企业 | |
|---|---|---|
| 多方安全计算 | 华控清交、富数科技、矩阵元 | 专注于打造以底层多方安全计算技术为基础的数据流通基础设施 |
| 可信执行环境 | 百度、阿里巴巴、冲量在线、隔镜科技 | 依赖于国外芯片的硬件支持;冲量在线已经与兆芯在国产化硬件研发上进行合作探索 |
| 联邦学习 | 各大运营商、金融科技公司等 | 由于机器学习应用需求突出,且具有较为成熟的开源社区作为支撑,开发难度相对轻松 |
开源生态

配套标准体系
《多方安全计算技术框架》和《基于TEE的安全计算》两项国际标准分别于2019年4月和2020年9月在电气电子工程师学会(IEEE)立项,但现有标准的内容主要是给出了通用性的技术框架,尚没有深入到应用中的细节。
中国信息通信研究院依托中国通信标准化协会大数据技术标准推进委员会于2018-2020年分别牵头制定了《基于多方安全计算的数据流通产品》《基于联邦学习的数据流通产品》《基于可信执行环境的数据计算平台》《区块辅助的隐私计算技术工具》4项隐私计算技术产品功能上的系列标准。
隐私计算面临的问题
- 市场对于隐私计算的认知度、认可度仍然不足
- 技术推广所需的成熟商业模式尚未形成
- 现有法律法规未对隐私计算地位进行明确定位
- 在满足通用性功能的基础之上,产品性能提升任重道远
隐私计算未来发展趋势
技术角度
- 软硬件协同优化以提升性能和技术的可用性
- 逐步向大规模分布式计算迈进
- 提供工具化、模块化的服务能力
应用角度
- 增强与区块链等其他技术的不断协同。区块链技术与隐私计算的功能是天然互补的,借助区块链去中心化、不可篡改、公开透明的特性,将增强隐私计算任务的可验证性、可审计性。
- 促进跨技术平台间的互联互通。隐私计算的目标是促进多方数据之间的互联互通。从长期来看,跨技术路径、跨系统平台之间的隐私计算技术工具的互联互通将成为广泛需求。
产业角度
- 隐私计算有望成为数据流通的关键基础设施。
- 技术发展将随着数据合规要求的不断变化而动态演化。
参考文献
开启新纪元: 隐私计算在金融领域应用发展报告2021 ↩︎
闫树, 吕艾临. 隐私计算发展综述.pdf[J]. 信息通信技术与政策, 2021(6). ↩︎
隐私计算白皮书[R/OL]. 隐私计算联盟;中国信息通信研究院云计算与大数据研究所, 2021[2021–11–04]. https://gw.alipayobjects.com/os/bmw-prod/73c5f163-d091-487a-bf5c-41841f546bc0.pdf. ↩︎