【大数据】☀️搞定Hadoop集群☀️概述&环境配置

目录
一、什么是Hadoop框架:
二、Hadoop三大发行版:
1.Apache Hadoop
2.Cloudera Hadoop
3.Hortonworks Hadoop
三、Hadoop的优势:
四、Hadoop组成:
1.HDFS架构概述:
a)NameNode(nn):
b)DataNode(dn):
c)Secondary NameNode(2nn):
2.YARN架构概述:
3.MapReduce框架概述:
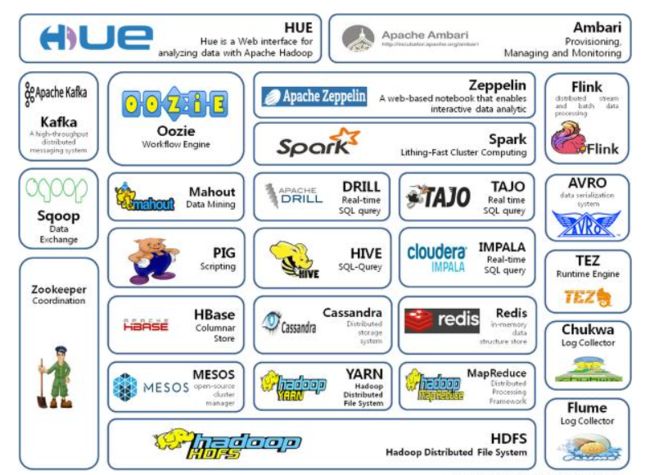
五、大数据生态体系:
六、VMware安装:
1.配置IP和主机名称:
修改虚拟机IP:
在虚拟机中修改配置:
在Windows中修该配置:
2.使用远程连接软件访问服务器:
3.配置模板虚拟机:
安装epel-release:
注意:
关闭防火墙,关闭防火墙开机自启:
配置用户权限:
4.创捷文件夹:
5.卸载虚拟机自带的JDK:
6.重启虚拟机:
六、克隆虚拟机:
修改克隆后的虚拟机IP:
七、在Hadoop_02虚拟机上安装JDK:
上传JDK和Hadoop的压缩包到主机:
八、在Hadoop_02虚拟机上安装Hadoop:
一、什么是Hadoop框架:
- Hadoop是一个由Apache基金会所开发的分布式系统基础框架。
- 解决海量数据的存储和海量数据的分析计算。
- Hadoop通常指一个更加广泛的概念——Hadoop生态圈。
- GFS——分布式存储——HDFS
- MapReduce——分布式计算——MR
- BigTable——分布式数据库——HBase
二、Hadoop三大发行版:
Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
Apache版本最原始(最基础)的版本,对于入门学习最好。
Cloudera内部集成了很多大数据框架。对应产品CDH。
Hortonworks文档较好。对应产品HDP。
1.Apache Hadoop
官网地址:http://hadoop.apache.org/releases.html
下载地址:Index of /dist/hadoop/common
2.Cloudera Hadoop
官网地址:https://www.cloudera.com/downloads/cdh/5-10-0.html
下载地址:http://archive-primary.cloudera.com/cdh5/cdh/5/
(1)2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。
(2)2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support
(3)CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强。Cloudera的标价为每年每个节点10000美元。
(4)Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。
3.Hortonworks Hadoop
官网地址:https://hortonworks.com/products/data-center/hdp/
下载地址:https://hortonworks.com/downloads/#data-platform
(1)2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。
(2)公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。
(3)Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了Ambari,一款开源的安装和管理系统。
(4)Hortonworks目前已经被Cloudera公司收购。
三、Hadoop的优势:
- 高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或者存储出现故障,也不会导致数据丢失。
- 高扩展性:在集群间分配任务数据,可方便扩展数以千记得节点。
- 高效性:MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
- 高容错性:能够自动将失败的任务重新分配。
解释:
- 并行是指“并排行走”或“同时实行或实施”。在操作系统中是指,一组程序按独立异步的速度执行,无论从微观还是宏观,程序都是一起执行的。对比地,并发是指:在同一个时间段内,两个或多个程序执行,有时间上的重叠(宏观上是同时,微观上仍是顺序执行)。
- 并发,在操作系统中,是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行,但任一个时刻点上只有一个程序在处理机上运行。
四、Hadoop组成:
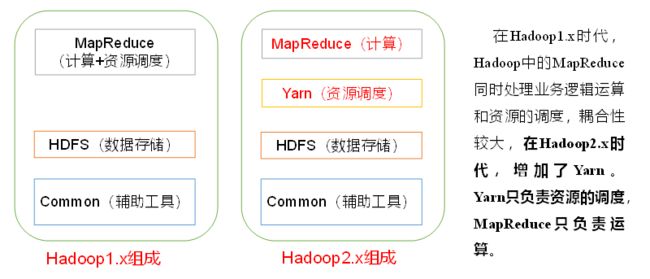
1.HDFS架构概述:
Hadoop Distributed File System:Hadoop分布式文件系统
a)NameNode(nn):
存储文件的元数据,如:文件名、目录结构、文件属性(生成时间、副本数、文件权限)、以及每个文件的块列表和块所在的DataNode等。
b)DataNode(dn):
在本地文件系统存储文件数据模块,以及块数据的校验和。
c)Secondary NameNode(2nn):
每隔一段时间对NameNode元数据备份(注意:他不是nn的热备份,不能替代nn执行相关的功能),协助nn执行功能。
2.YARN架构概述:
YARN资源调度:cpu、内存等
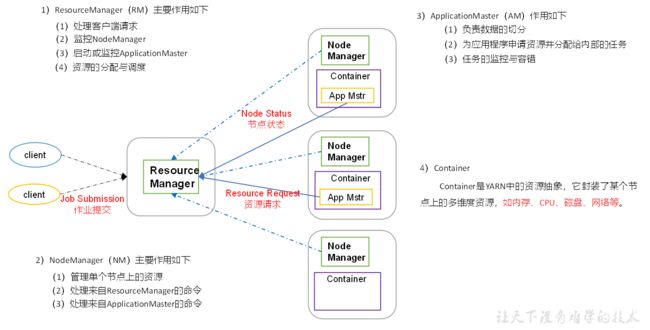
3.MapReduce框架概述:
MapReduce:将计算过程分为两个阶段:Map、Reduce
- Map阶段并行处理输入的数据
- Reduce阶段对Map结果进行汇总

五、大数据生态体系:

- Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySql)间进行数据的传递,可以将一个关系型数据库(例如:MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
- Flume:Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;
- Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统;
- Storm:Storm用于“连续计算”,对数据流做连续查询,在计算时就将结果以流的形式输出给用户。
- Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
- Flink:Flink是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。
- Oozie:Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。
- Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
- Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
- ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
六、VMware安装:
传送口:安装虚拟机
1.配置IP和主机名称:
修改虚拟机IP:
打开虚拟网络编辑器:
更改配置:
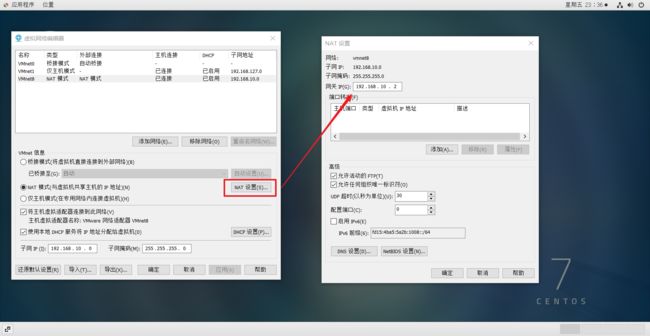
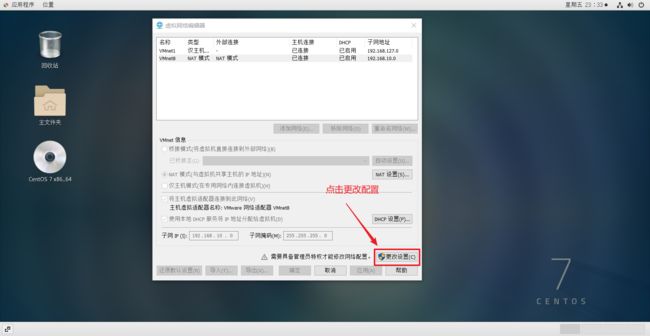
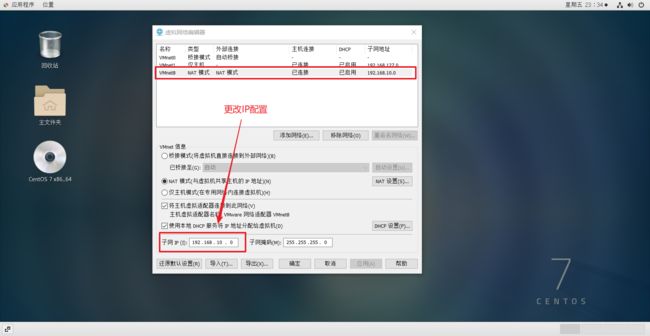
在虚拟机中修改配置:
在虚拟机中执行:vim /etc/sysconfig/network-scripts/ifcfg-ens33:打开Linux中的网络配置文件
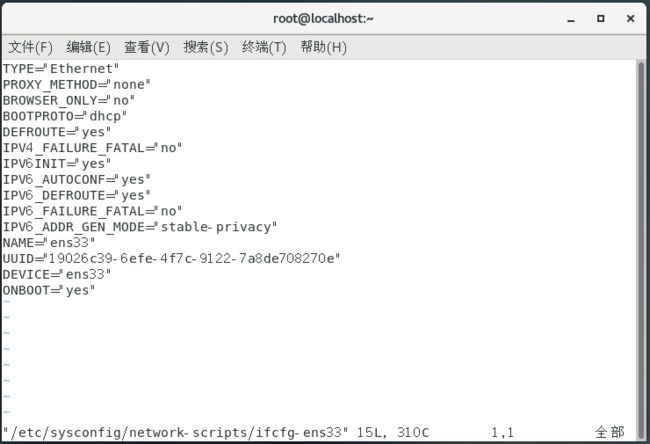
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static" //修改IP地址为静态地址,dhcp为动态IP地址
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="19026c39-6efe-4f7c-9122-7a8de708270e"
DEVICE="ens33"
ONBOOT="yes"
IPADDR=192.168.10.100
GATEWAY=192.168.10.2
DNS1=192.168.10.2vim /etc/hostname:修改主机名称
vim /etc/hosts:主机名映射
192.168.10.100 hadoop01
192.168.10.101 hadoop02
192.168.10.102 hadoop03
192.168.10.103 hadoop04
192.168.10.104 hadoop05
192.168.10.105 hadoop06
192.168.10.106 hadoop07
192.168.10.107 hadoop08
192.268.10.108 hadoop09reboot:重启Linux
ipconfig:查看ip地址
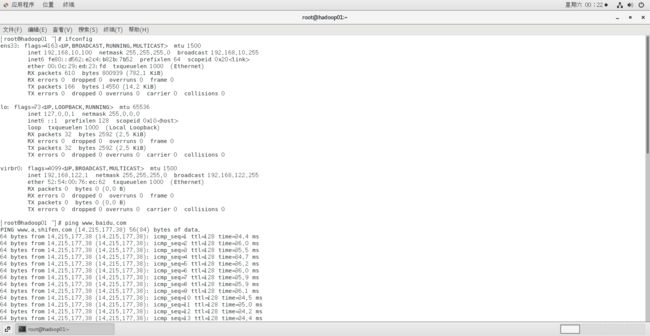
ping 外部网站连接:能ping成功说明网络连接成功
ctl+C:停止ping操作
在Windows中修该配置:
打开网络设置,修改适配器选项


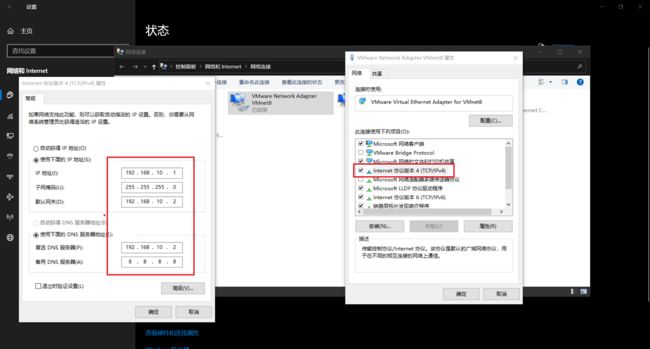
右键打开VMware属性,双击internet协议版本4(TCP/IPv4),修改常规
2.使用远程连接软件访问服务器:
Xshell:远程连接工具
Xftp:远程文件上传工具
3.配置模板虚拟机:
安装epel-release:
yum install -y epel-release
注意:
如果安装的是Linux最小系统版本,还需要安装如下工具,如果安装的是Linux的桌面标准版,则不需要执行以下操作:
- net-tool:工具包集合,包含
ifconfig等命令:yum install -y net-tools - vim:编辑器:
yum install -y vim
关闭防火墙,关闭防火墙开机自启:
systemctl stop firewalld:关闭防火墙
systemctl disable firewalld.service:关闭防火墙开机自启
配置用户权限:
创建用户,配置用户权限(我这里直接使用root用户)
4.创捷文件夹:
cd /opt:进入opt目录
sudo mkdir module:创建module文件夹
sudo mkdir software:创建software文件夹
5.卸载虚拟机自带的JDK:
注意:虚拟机是最小安装,可以不执行这一步!
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps- rpm -qa:查询安装的所有rpm软件包
- grep -i:忽略大小写
- xargs -n1:表示每一次只传递一个参数
- rpm -e --nodeps:强制卸载软件
6.重启虚拟机:
reboot:重启虚拟机六、克隆虚拟机:
注意:需要关闭虚拟机!!!(学习时只克隆了三台)

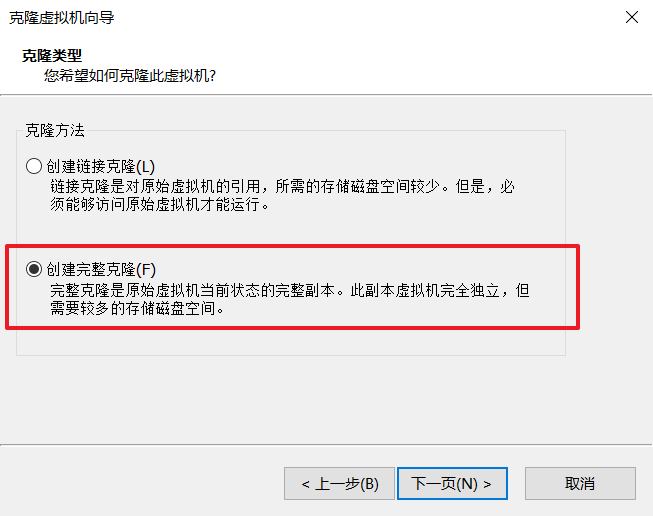
修改克隆后的虚拟机IP:
打开Hadoop_02虚拟机:
vim /etc/sysconfig/network-scripts/ifcfg-ens33:修改IP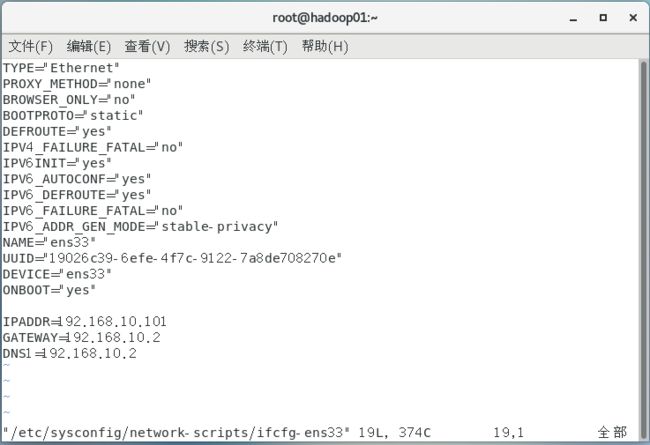
vim /etc/hostname:修改主机名
注意:按照上述步骤修改每一台虚拟机的配置!!!
七、在Hadoop_02虚拟机上安装JDK:
上传JDK和Hadoop的压缩包到主机:
使用Xftp上传文件到创建的software目录中:(cd /opt/software)
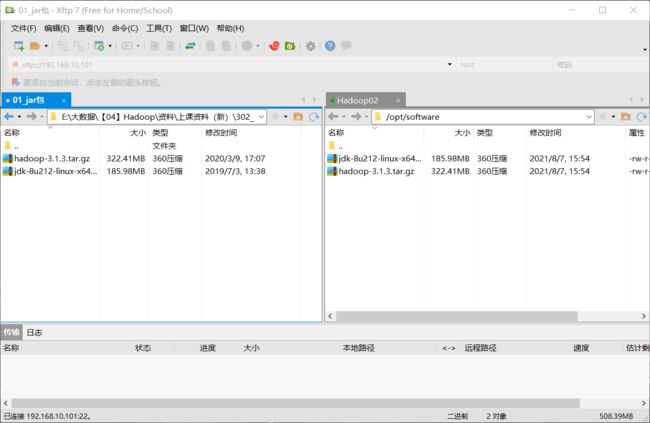
![]()
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/:解压tar压缩包
cd /etc/profile.d:进入目录
sudo vim my_env.sh:创建一个新的文件,对JAVA_HOME配置:
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
resource /etc/profile:重新加载配置文件

八、在Hadoop_02虚拟机上安装Hadoop:
cd /opt/software
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/:解压Hadoop压缩包
配置环境变量:
sudo vim /etc/profile.d/my_env.sh:编写配置文件
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADDOP_HOME/sbinsource /etc/profile
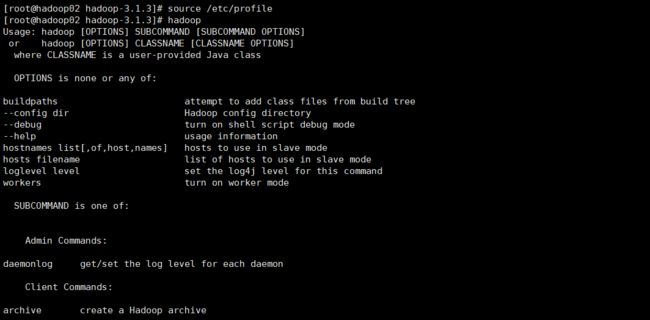
/opt/module/hadoop-3.1.3hadoop内容:
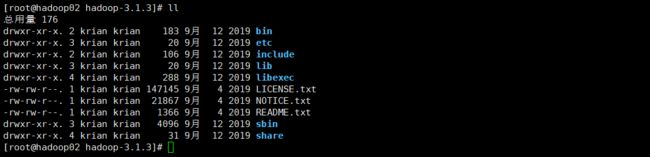
bin目录:
etc目录:

sbin目录:
