基于flask实现疫情可视化监控系统
目录
- 第一章 绪论
-
- 1.1 课题背景及意义
- 第二章 相关理论及技术
-
- 2.1 flask框架概述
- 2.2 Layui框架概述
- 2.3 开发工具
-
- 2.3.1 MySQL数据库技术
- 2.3.2 pycharm技术
- 2.3.3 .爬虫技术
- 2.3.4 Echarts技术
- 3.1 业务流程调研及分析
- 3.2 系统功能需求分析
-
- 3.2.1 系统安全需求
- 3.2.2 用户角色定义
- 3.3 解决方案的提出与分析
- 3.4 系统非功能性需求
- 第四章 系统设计
-
- 4.1 系统技术架构设计
-
- 4.1.1 总体架构
- 4.1.2 软件逻辑结构
- 4.2 系统功能结构设计
-
- 4.2.1 爬虫功能模块设计
- 4.2.3 登录模块设计
- 4.2.4 展示模块设计
- 4.2.5 后台模块设计
- 4.3 数据库设计
-
- 4.3.1 主要E—R图
- 4.3.2 主要数据库表
- 第五章 系统实现
-
- 5.1 系统运行环境
- 5.2 主要功能实现
-
- 5.2.1 爬虫功能实现
- 5.2.2 登录模块实现
- 5.2.3 展示模块实现
- 5.2.4 后台模块实现
- 第六章 系统测试
-
- 6.1 测试方案与测试目标
- 6.2 系统功能测试
-
- 6.2.1 登录功能测试
- 6.2.2 数据库连接功能测试
- 6.2.3 爬虫功能测试
- 6.2.4 数据展示功能测试
- 6.3 测试结论
- 第七章 总结与展望
-
- 7.1 总结
- 7.2 展望
- 致谢
第一章 绪论
1.1 课题背景及意义
我们身处一个信息极度丰富的时代,信息以更多的维度、更丰富的形态充满着我们的生活,潜移默化地影响着我们的决策。
全球Covid-19大危机影响我们的生活,我们的出行、交流、教育、经济等都发生了巨大的变化,全球疫情大数据可视化分析与展示,可用于社会各界接入疫情数据,感知疫情相关情况的实时交互式态势,是重要的疫情分析、防控决策依据。
对于同学们而言,导师将在项目中带领大家掌握一门编程语言,探索揭秘大数据分析原理,数据科学不仅是未来科研、职业发展的重要基础,更有助于锻炼逻辑能力,培养谨慎、客观、独立的思维习惯。
第二章 相关理论及技术
下面将介绍本文所涉及的相关技术与理论的内容,将主要介绍flask框架,开发工具以及系统的机构模式,SQL的内容。
2.1 flask框架概述
Flask是一个使用 Python 编写的轻量级 Web 应用框架。其 WSGI 工具箱采用 Werkzeug ,模板引擎则使用 Jinja2 。Flask使用 BSD 授权。Flask也被称为 “microframework” ,因为它使用简单的核心,用 extension 增加其他功能。Flask没有默认使用的数据库
2.2 Layui框架概述
layui(谐音:类 UI) 是一套开源的 Web UI 解决方案,采用自身经典的模块化规范,并遵循原生 HTML/CSS/JS 的开发方式,常适合网页界面的快速开发。layui 区别于那些基于MVVM 底层的前端框架,它更多是面向后端开发者,无需涉足前端各种工具,只需面对浏览器本身,让一切所需要的元素与交互。
2.3 开发工具
2.3.1 MySQL数据库技术
MYSQL数据库. MySQL 是一种 开放源代码 的关系型 数据库管理 系统(RDBMS),使用最常用的数据库管理语言-- 结构化查询语言 (SQL)进行数据库管理。. MySQL是开放源代码的,因此任何人都可以在General Public License的许可下下载并根据个性化的 需要 对其进行修改。. MySQL因为其速度、可靠性和适应性而备受关注。. 大多数人都认为在不需要 事务 化处理的情况下,MySQL是管理内容最好的选择。
MySQL 是一款安全、跨平台、高效的,并与 PHP、Java 等主流编程语言紧密结合的数据库系统。该数据库系统是由瑞典的 MySQL AB 公司开发、发布并支持,由 MySQL 的初始开发人员 David Axmark 和 Michael Monty Widenius 于 1995 年建立的。
MySQL 的象征符号是一只名为 Sakila 的海豚,代表着 MySQL 数据库的速度、能力、精确和优秀本质。目前 MySQL 被广泛地应用在 Internet 上的中小型网站中。由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,使得很多公司都采用 MySQL 数据库以降低成本。
MySQL 数据库可以称得上是目前运行速度最快的 SQL 语言数据库之一。除了具有许多其他数据库所不具备的功能外,MySQL 数据库还是一种完全免费的产品,用户可以直接通过网络下载 MySQL 数据库,而不必支付任何费用。
2.3.2 pycharm技术
PyCharm是一种Python IDE(Integrated Development Environment,集成开发环境),带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试、版本控制。此外,该IDE提供了一些高级功能,以用于支持Django框架下的专业Web开发。
2.3.3 .爬虫技术
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息Python 爬虫架构主要由五个部分组成,分别是调度器、URL管理器、网页下载器、网页解析器、应用程序(爬取的有价值数据)。
调度器:相当于一台电脑的CPU,主要负责调度URL管理器、下载器、解析器之间的协调工作。
URL管理器:包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL和循环抓取URL,实现URL管理器主要用三种方式,通过内存、数据库、缓存数据库来实现。
网页下载器:通过传入一个URL地址来下载网页,将网页转换成一个字符串,网页下载器有urllib2(Python官方基础模块)包括需要登录、代理、和cookie,requests(第三方包)
网页解析器:将一个网页字符串进行解析,可以按照我们的要求来提取出我们有用的信息,也可以根据DOM树的解析方式来解析。网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方式来提取有价值的信息,当文档比较复杂的时候,该方法提取数据的时候就会非常的困难)、html.parser(Python自带的)、beautifulsoup(第三方插件,可以使用Python自带的html.parser进行解析,也可以使用lxml进行解析,相对于其他几种来说要强大一些)、lxml(第三方插件,可以解析 xml 和 HTML),html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 树的方式进行解析的。
应用程序:就是从网页中提取的有用数据组成的一个应用。
2.3.4 Echarts技术
ECharts 是一个使用 JavaScript 实现的开源可视化库,涵盖各行业图表,满足各种需求。它遵循 Apache-2.0 开源协议,免费商用,且兼容当前绝大部分浏览器(IE8/9/10/11,Chrome,Firefox,Safari等)及兼容多种设备,可随时随地任性展示。
百度最早内部图表组件使用的是 Flash 技术,后来随着 HTML5 的崛起,来自 Safari 的 Canvas 逐渐得到了广泛支持,加上 Apple 在 iOS 中明确不支持 Flash,使得 Flash 的技术前景开始黯淡。
于是百度商业前端团队就尝试基于 Canvas 来开发图表库 ECharts,比起 SVG/VML,Canvas 虽然调试麻烦,但在大量数据点下性能更好,且早期开发者很快的补齐了大量常用图表,加上中文文档的优势,ECharts 很快在国内流行起来,它至今依然是国内最火的图表库。
2017 年陆奇加入百度后大力推广开源,ECharts 也在 2018 年进入 Apache 孵化器,从此ECharts开始在国外受到关注。
第三章 系统需求分析
系统的需求分析作为系统设计、系统实现的基础内容,要求本论文与系统的
用户的进行调研工作,掌握对系统的功能与性能需求方面的体系知识,并且需要
本论文把这些知识进行细化、分解,建立系统工作文档。此项工作被视为系统实
施阶段的推理内容,涉及学生成绩管理工作的实际问题与系统功能、性能,目的
在于使本论文加强对系统了解,然后付出实际工作,并把掌握的需求由书面的方
式体现出来,来辅助系统的研发工作,下面将从业务流程调研与分析,系统功能
需求分析,系统解决方案的提出与分析与系统非功能需求四个方面进行系统需求
分析。
3.1 业务流程调研及分析
2019年在武汉爆发的新型冠状病毒肺炎(国家卫健委简称NCP)传播迅猛,已被世界卫生组织(WHO)定为“国际关注的突发公共卫生事件”。对疫情的控制,自1月24日武汉宣布封城之后,各个省市也陆续通过启动启动重大突发公共卫生事件一级响应来控制人口流动;同时,各省市医疗队伍驰援武汉,武汉的防控措施也急速加强;但全国疫情,特别是湖北省的状况依然让人揪心。公众非常关心疫情的发展趋势,期待“拐点”的出现;疫情防控部门希望不断总结经验教训,评估现有措施的有效性。该疫情的发展成为了涉及到我国政治经济民生的一件大事。
此次的病毒到底如何从武汉向外传播?不同省市疫情的发展呈现怎样的差别?封城、社区化隔离等一系列措施对减缓疾病传播起到了多大的作用;更为重要的是,拐点何时出现?
我们的报告首先从已有数据的可视化来展示疫情传播特点,然后通过建立传染病动力学模型,评估疫情防控措施,提出建议并预警,同时预测疫情疾病走势,给疫情防控决策和大众行为作为参考。
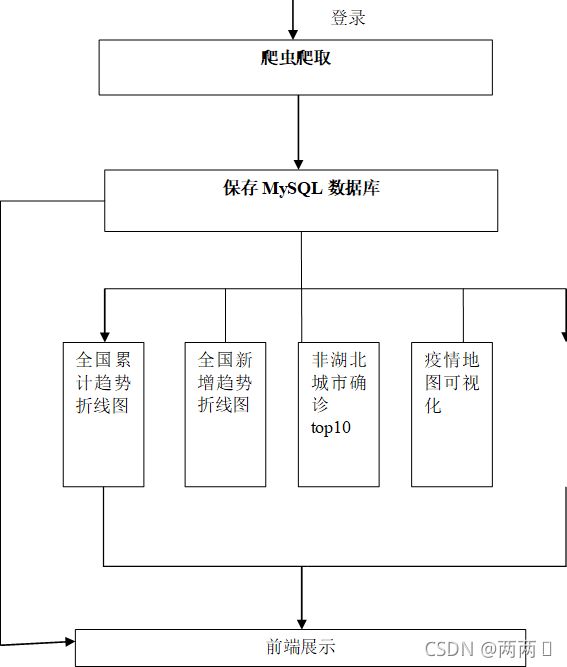
图 3.1 业务流程
3.2 系统功能需求分析
3.2.1 系统安全需求
基于数据安全和保密需要,设置大屏密码登录保护;参观人员必须输入管理员账号才能进行访问。
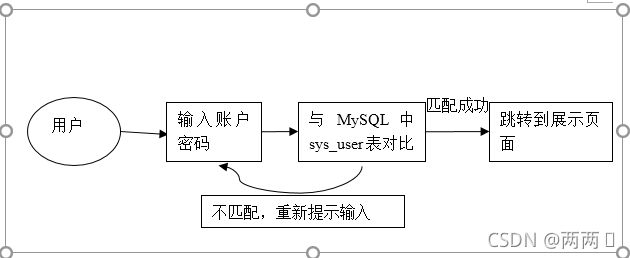
图片 3.2.1 系统安全需求
3.2.2 用户角色定义
通过对与系统的访问,用户可以查看后台数据,启动爬虫,修改表格数据,以及访问疫情大数据看板。
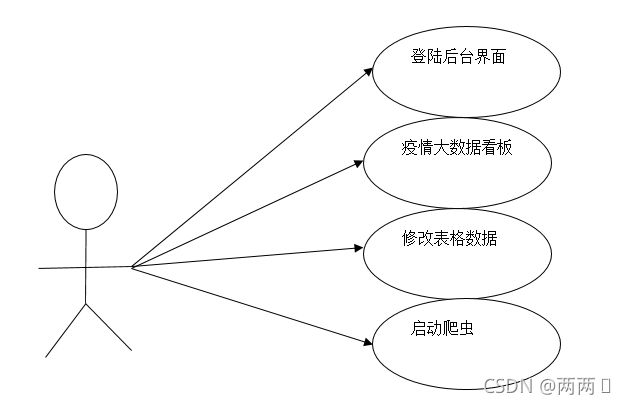
图片 3.2.2用户角色定义
3.3 解决方案的提出与分析
首先,需要先简单澄清下数据可视化的基本概念。数据可视化,实质上是把一些概要信息(数据、关键内容),并结合动静态的图像视频等形式进行展示,从而清晰传递核心信息。较为注重视觉层面的触达。
所以我们需要在数据之中挖掘一些重要的价值信息,并以一个可观的方式呈现。而“重要”的定义是十分明显的,核心数据、用户感兴趣、有决策意义,都可称之为重要。
根据马斯洛五层次需求理论,那么数据可视化在其中属于什么层次的需求?受疫情影响,生命安全成了最重要的社会需求。那么满足大众对这方面的广泛需求,推出这样的数据可视化产品是十分有必要,满足用户对疫情情况、资讯信息、医疗信息等方面的获取,从而保障自己基本的需求。初始,丁香医生率先推出一个H5的可视化页面,汇总披露病例数据。随后,一些大厂也开始陆续推出,包括头条、腾讯等等。
而为什么大家都纷纷推出这样的数据服务,从战略层来说:一是做好企业责任,满足用户的知情需求;其二是满足自己的平台用户,并吸引流量,这都是拉新、促活的宝贵方式。而展示的信息,主要包括每日的新增、累计病例数,各地区的病例分布,以及疫情新闻、医学知识等方面的内容。
价值
用户:主要满足3类用户:大众用户、政企用户和患者用户。其中主要是前2者。大众用户是指像我们普遍受此前疫情影响生活、工作等方面的大众群体。政企用户是指政府和企业机构,同样受此次疫情影响,对机构的运作肯定也是有影响的,他们需要基于此做合适的决策,保障企业和员工的安全。患者用户是指受此次疫情传播切身影响到的用户,包括确诊、疑似、接触、被动隔离等,这类用户对医学信息的获取会更为迫切。
需求:面对3类不同的用户,主要是满足2大类需求,分布是资讯信息和医疗信息的获取。其中资讯信息包括疫情信息、政府信息、权威报道等。医疗信息包括医学知识、医院信息、医学服务等。
而接下来,也将依据用户体验五要素中的范围层、框架层、表现层,分别对这个疫情数据可视化的产品服务进行分析。
范围层的定义是决定这样的产品服务需要提供什么范围内的功能服务,什么是不做的。以及要做的数据指标,哪些是关键的,哪些是次要的。所以我们可以罗列一下这样数据可视化产品,基于用户的需求是需要准备什么样的数据指标。
从中可以看出,大致可以划分两类关键数据:一个是病例的数据,一个是辅助性的数据。我们需要从中挑出其适合展示同时也是用户需要关心的数据。
通常做这种可视化产品,总结性的数据是十分关键的。而基于用户的关注点,每日新增、累计,就是其中的关键。
另外,基于“时间”和“地区”,代表了数据的“属性”。而属性则反应了这个数据可以以什么样的特点进行展现。而“时间”和“地区”是,最适合以数据趋势和数据分布的两种主要数据可视化表达形式。
框架层的定义是指根据要做的功能范围,应该确定如何正确布局和设计,可以简单理解为PPT的排版一样,以什么样的方式来排列展现这些元素。
从数据指标来看,确诊、疑似、治愈、死亡这4个是关键指标,而累计要较新增重要些。
从时间和地域上看,中国整体数据、各省市数据、全球各国数据这3类为关键指标。而由于目标用户主要为国内广大用户,那么按照优先级排序应以全国到各省市,再到全球各国,这样的顺序排列。
大致的布局是已经清晰了,那么接下来就需要基于数据类型采用合理的可视化展示形式。
前面也提过,由于是时间和地区下的各类数据,基于这样的属性,是可以做趋势、地域、列表等分布的展示方式。支持趋势的图形则主要为折线、柱状图,支持地域分布类型则为地图,而列表则为常规的类报表方式等。
其中,由于时间跨度较长和地区明细较多,如果使用柱状图,则会显得横轴较长,所以在有限的手机屏幕尺寸下,是不适宜展示的。
趋势:由于时间跨度较长和地区明细较多,如果使用柱状图,则会显得横轴较长,所以在有限的手机屏幕尺寸下,是不适宜展示的。
地图:地图的可视化有很多,比如像基础的echats组件,就支持各类2D、3D图形。但是在这里我们需要考虑的是,用户主要打开的应用设备是手机。那么手机的设备性能一定程度上限制了可视化的效果呈现。先忽略开发成本,过于酷炫的效果,会导致页面加载、渲染十分久,这在体验上十分不划算的。所以在这里,更倾向于采用粗一些的2D省级行政地图形式,开发周期短,且满足最基本需求。
3.4 系统非功能性需求
一. 安全需求
需要有登录模块,防止用户因为操作失误而出现数据库误删,所以需要设计登录模块,只有管理员账户才可以登陆后台
二. 数据管理需求
选择数据,需确保数据的准确性、稳定性和易读性;一个理想的可视化设计流程,需要经历“数据指标的范围筛选、页面的布局抉择、可视化的视觉设计“等关键步骤。
三. 美观需求
数据可视化的布局本质上就是讲好一个“故事”,所以是故事就要有先后顺序、递进关系;数据可视化的核心,是需要明确展示的目的和主题,同时需要分清主要和次要关键信息;
四. 可扩展需求
数据的内涵和属性确定了可适用的展示方式,比如地理信息适用使用地图,占比分布适宜使用饼状图等;进行可视化设计前,需要了解主要用户使用的设备类型,以及开发的主程序,切勿过于追求视觉效果,毕竟设备性能之间、APP和手机网页之间,都是有较大的性能差别的;
五. 数据需求
视觉是数据可视化的一大利器,善用有利于合理化的展示,其中图表的设计、色彩的搭配至关重要。数据的罗列展示要整齐划一,一般遵循从大到小、从外到里的原则。每个元素组件,兼顾数据及数据之间背后的逻辑、关联关系;
第四章 系统设计
4.1 系统技术架构设计
4.1.1 总体架构
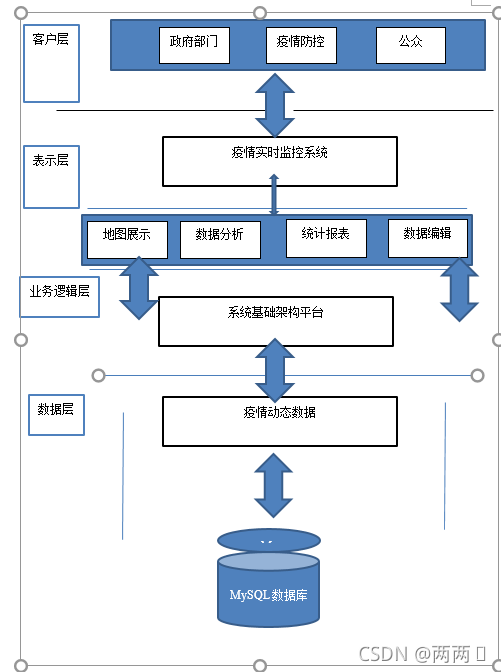
作为当前主流的系统开发模式–B/S 模式,此模块中的业务层被划分为:客户层、表示层、业务逻辑层以及数据层。
B/S 模式(Browser / Server 模式)的突出特点在于,在不安装系统软件的情况下,用户通过系统就能够实现相应的办公操作,而实现的前提是需要在客户端安装 web 浏览器。这样的有效结合具备了系统的运行条件,从而能够大大的简化客户端的工作负担,能够有效提升系统的运转速度。
综上所述,本文的系统则采用了分层的设计模式对系统进行设计,下图
即为系统的总体架构图设计。
客户层:即为需要安装 Web 浏览器的客户端位置,用户在该层实现各自的功
表示层:即是为疫情实时监控系统为用户提供疫情数据监控的功能操作后显示出来的操作界面,系统用户可以在该层的操作界面中输入要查询管
理疫情信息以及相关的内容,能够实现对疫情信息的录入、维护以
及信息的查询操作等管理功能。
业务逻辑层与数据层:该层主要负责提供数据信息的交换以及共享功能,能够对不同数据格式以及信息实现共享和交换。
4.1.2 软件逻辑结构
本文的系统在软件逻辑架构的设计工作上采用的是轻量级 flask 框架,该框架是基于 MVC 模式的一种架构图 4-2 为本文系统的软件逻辑架构示意图。
在 flask 框架技术中,wsgi 具有控制器的功能,而 werkzeug则是用来充当系统的控制模型的角色。具体实现的过程为:当用户提出操作请求之后,第一步会由 flask服务器负责接收用户发出的操作请求的信息,在将
此信息请求传送到控制器 wsgi 中,wsgi 来负责接收操作指令,
然后从数据库 My SQL 中找到的对应信息,之后再将数据访问结果返回给jiajie渲染的视图呈现给用户。
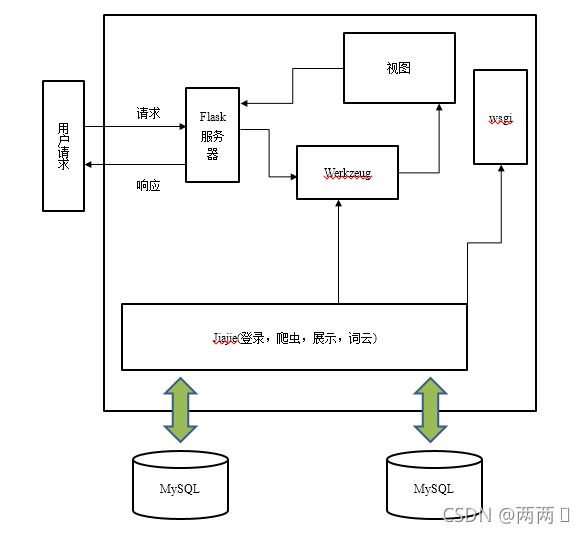
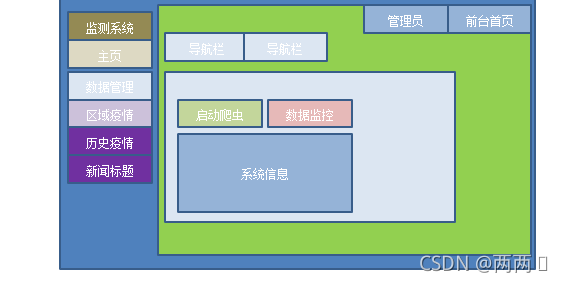
4.2 系统功能结构设计
疫情实时监控管理系统中,从系统用户操作需求的角度,本论文可以将系统的功能划分为四大子系统,它们分别是登录系统、爬虫系统、数据连接系统和展示系统,下面本文给出了系统的功能架构所示。
登录系统:Flask-Login 和其他 Flask 组件并没有太大区别,有必要开始之前了解下用户登录的步骤:
1 登录:用户提供登录凭证(如用户名和密码)提交给服务器
2 建立会话:服务器验证用户提供的凭证,如果通过验证,则建立会话( Session ),并返回给用户一个会话号( Session id )
3 验证:用户在后续的交互中提供会话号,服务器将根据会话号( Session id )确定用户是否有效
4 登出:当用户不再与服务器交互时,注销与服务器建立的会话
依据以上步骤,我们设计一个应用场景,作为实现:
提供一个主页,需要登录才能访问
如果没有登录,跳转到登录页面,登录成功再跳回
登录成功后,可以点击登出退出登录
在登录页面提供注册连接,点击后跳转到注册页面
注册完成后,跳转到登录页面
爬虫系统:爬取腾讯疫情数据,并且对数据进行数据的清洗和结构化处理
展示系统:用于从数据库中调取数据,按照一定的数据结构采用echarts在web端进行数据的展示
书记库连接系统:对数据库进行连接,并且对于数据库的增删改查操作进行封装,并且在web端进行集成绑定。
4.2.1 爬虫功能模块设计
Selenium是一个用电脑模拟人操作浏览器网页,可以实现自动化爬虫。
浏览器为Firefox,驱动为geckodriver.( 需要把浏览器驱动放入系统路径中,或者直接告知selenuim的驱动路径)
爬取的url地址:
url1 = “https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5”
url2 = “https://view.inews.qq.com/g2/getOnsInfo?name=disease_other”
这两个地址就是腾讯新闻网的数据接口,已经存储json数据类型。打开网址就可以发现网站的键值对数据格式,这里采用selenium来模拟浏览器爬取网页。再把保存下来的数据进行格式化清理,保存至MySQL数据库对应的表格里。对于今日热搜数据也是一样模拟浏览器进行打开网页,但是和上面不同的地方在于数据并不是可以直接拿来用的json格式数据,而是需要我们用xpath来选择我们需要的数据。再把数据保存在MySQL表中。
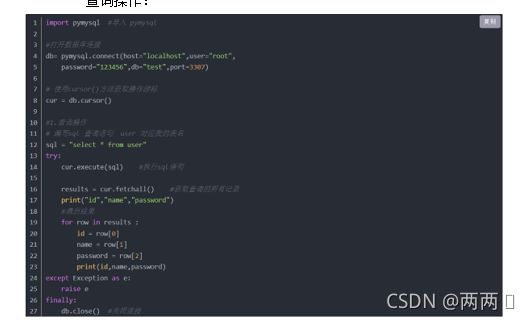
4.2.2 数据库连接模块设计
Python连接数据库用pymysql连接mysql数据库,首先需要导入pymysql模块。
查询操作:
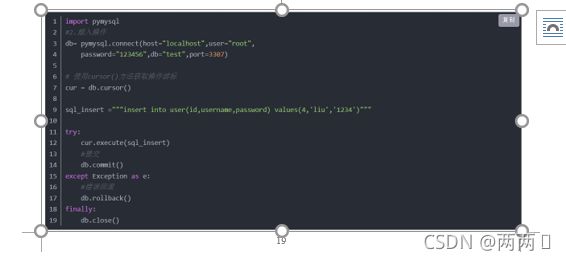
插入操作:
更新操作:

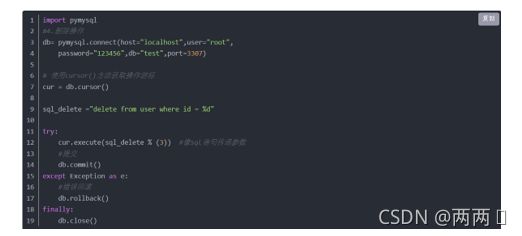
删除操作:
4.2.3 登录模块设计
存在用户登录的情况,不存在用户需要完成注册才能登录。注册功能和登录很类似,页面上多了密码确认字段,并且需要验证两次输入的密码是否一致,后台逻辑是:如果用户不存在,且通过检验,将用户数据保存到 USERS 列表中,跳转到 login 页面。
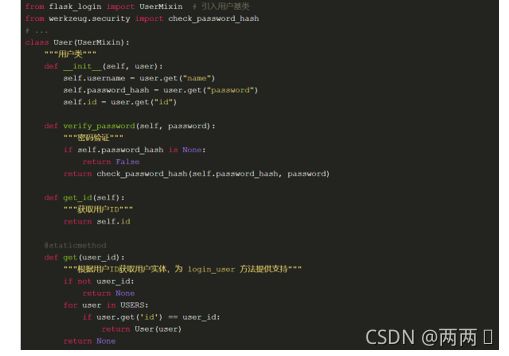
实例化方法接受一个用户记录,即 USERS 列表中的一个元素,用来初始化成员变量
get_id 方法返回用户实例的 ID,这是必须实现的,不然 Flask-Login 将无法判断用户是否被验证
get 是个静态方法,即可以通过类之间调用,是为了在获取验证后的用户实例时用的,必须接受参数 ID,返回 ID 所以对应的用户实例
verify_password 方法接受一个明文密码,与用户实例中的密码做校验,将被用在用户验证的判断逻辑中
4.2.4 展示模块设计
展示模块分为前后端,前端界面由和html+js+css写成,后端加入业务逻辑代码,由flask分发路由,由工具类连接数据库并提取数据展示到前端界面。具体前端界面细节设计如下图:

4.2.5 后台模块设计
后台分为前后端,其中前端采用layui框架快速构建后台系统,后端则是使用flask分发路由进行业务逻辑设计。具体设计如图:
4.3 数据库设计
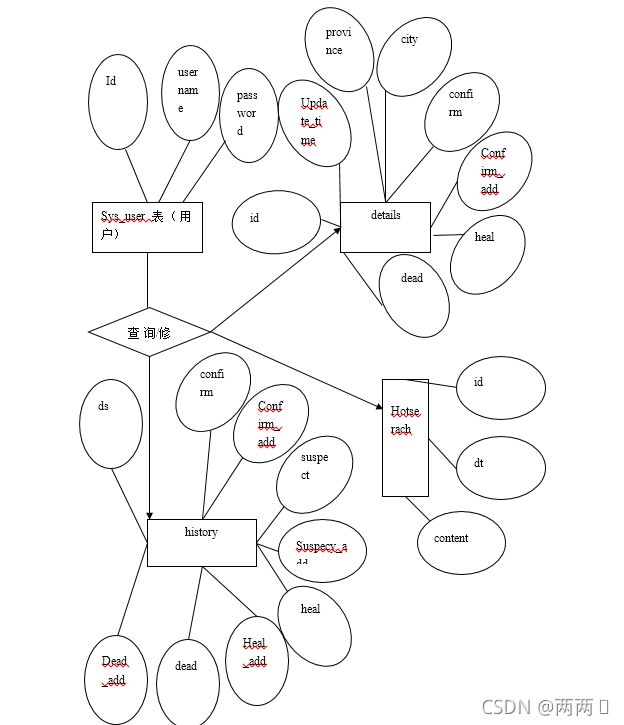
这一部分内容的设计一般是在对系统进行概念的设计工作中,将用户的视角
中的数据信息以一种逻辑的形式表现出来,而主要表现形式是通过 E-R 图来展现
的,它包含了是三个部分:即实体、属性以及它们之间的关系
4.3.1 主要E—R图
4.3.2 主要数据库表
在疫情可视化系统中,包含了许多张表,本论文从中选择四张表,用 sys_user来保存管理员登陆账户,用details表来保存疫情数据细节表,用history表来保存历史疫情数据,用hotsearch表来保存今日热搜数据。
1. sys_user表:在此表中,对登录用户的管理员账号进行存储,此类信息的字段名,类型,代码和长度。见下表4-1sys_user表:
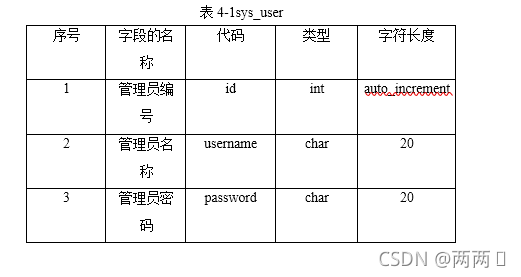

表4-1sys_user
序号 字段的名称 代码 类型 字符长度
1 管理员编号 id int auto_increment
2 管理员名称 username char 20
3 管理员密码 password char 20
2. details表:在此表中,对疫情数据的细节存储,此类信息的字段名,类型,代码和长度。见下表4-2 details表:
表4-2 details


序号 字段的名称 代码 类型 字符长度
1 数据编号 id Int(part of primary key) auto_increment
2 省 Province Varchar 15
3 市 City varchar 15
4 累计确诊 Confirm Int
5 新增确诊 Confirm_add Int
6 累计治愈 Heal Int
7 累计死亡 Dead Int
8 数据最后更新时间 Updata_time datatime
3. history表:在此表中,对历史疫情数据进行存储,此类信息的字段名,类型,代码和长度。见下表4-3 history表:
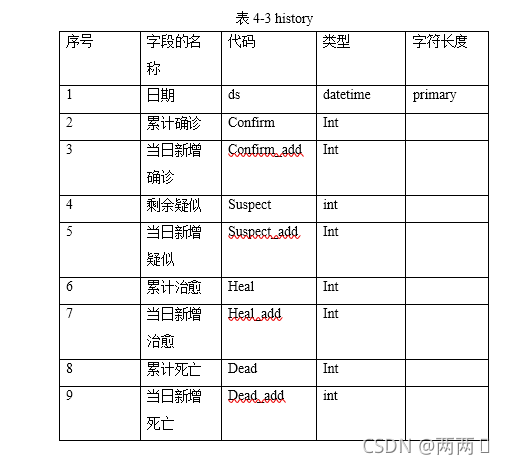
表4-3 history
序号 字段的名称 代码 类型 字符长度
1 日期 ds datetime primary
2 累计确诊 Confirm Int
3 当日新增确诊 Confirm_add Int
4 剩余疑似 Suspect int
5 当日新增疑似 Suspect_add Int
6 累计治愈 Heal Int
7 当日新增治愈 Heal_add Int
8 累计死亡 Dead Int
9 当日新增死亡 Dead_add int

4. hotsearch表:在此表中,对今日疫情热搜进行存储,此类信息的字段名,类型,代码和长度。见下表4-4 hotsearch表:

表4-4 hotsearch
序号 字段的名称 代码 类型 字符长度
1 数据编号 id Int(part of primary key) auto_increment
2 日期 dt datetime
3 描述 Content varchar 255

第五章 系统实现
完成了系统的设计工作之后,本章节将以此为基础,将完成系统实现的内容。
本章节采用程序流程图、代码和屏幕截图的方式,对学生成绩管理系统的主要功
能的实现过程进行描述。在介绍的内容中,主要内容为系统主要功能模块实现的
过程,还有系统开发环境与运行环境的说明。
5.1 系统运行环境
本系统采用 B/S 结构作为系统开发模式,系统软件逻辑结构设计采用 flask框架技术实现 MVC 的设计模式,开发工具选用 pycharm工具,开发语言为 python语言,后台数据库选用易用,快速和健壮的 My Sql 数据库管理系统,数据库软件为datagrip,WEB 应用服务器选用轻巧灵活的 flask,服务器操作系统采用 Windows 11。浏览器采用火狐浏览器,selenium驱动为火狐驱动,前端展示为echarts展示.
5.2 主要功能实现
5.2.1 爬虫功能实现
第三方模块
1.json 主要功能:处理接口数据
2.requests 主要功能:获取接口数据
3.pandas 主要功能:将数据保存为csv
4.datetime 主要功能:文件保存时间
5.pyecahrts 主要功能:数据可视化制作地图等 版本1.7.0
6.flask 主要功能:web展示
5.2.2 登录模块实现

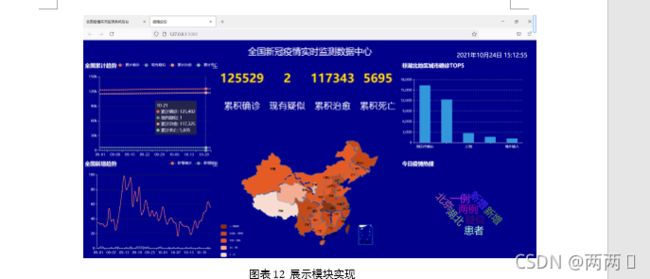
5.2.3 展示模块实现
Flask是由python实现的一个web微框架,让我们可以使用Python语言快速实现一个网站或Web服务。
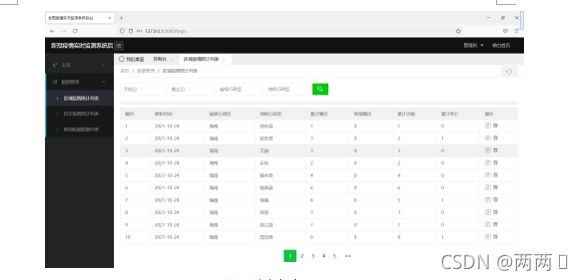
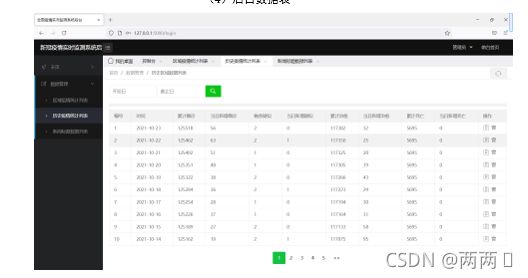
5.2.4 后台模块实现
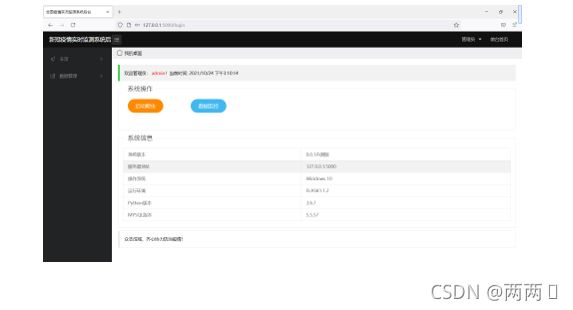
(4)后台数据表
第六章 系统测试
在本章节的内容中,本论文将通过黑盒强测试方法,即为功强能测试法,通过测
试强来检测系统的功能的正确性,具体将介绍的内容涉及系统测试方案与目标,部
分功能模块与性能方面的测试内容
6.1 测试方案与测试目标
该系统采用黑盒强测试方法,黑盒测试也称功强能测试,通过测试来检测每个功能是否都能正常使用。测试在运行程序实施测试工作,仅仅检测程序功能是否满足系统目标的要求可以正常进行操作,程序能否可以适当地获取输入数锯而产生符合要求的输出数据,并且保强持外部的数据(如数据库中的数据或文件)的整体性。“黑盒”法即是输入数据进行测试,将全部的需要的强输入都作为测试情况的条件,就能以强该种测试方式查出程序冯中全部的错误
系统测试分为功能测试和性能测试。功能测试抽取几个主要模块去进行功能
测试;性能测试采用 loadRunner 工具对系统与服务器进行性能测试。
6.2 系统功能测试
6.2.1 登录功能测试
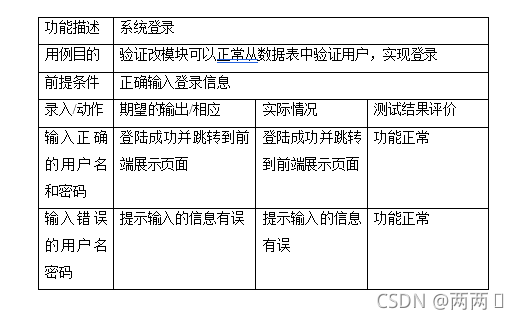
功能描述 系统登录
用例目的 验证改模块可以正常从数据表中验证用户,实现登录
前提条件 正确输入登录信息
录入/动作 期望的输出/相应 实际情况 测试结果评价
输入正确的用户名和密码 登陆成功并跳转到前端展示页面 登陆成功并跳转到前端展示页面 功能正常
输入错误的用户名密码 提示输入的信息有误 提示输入的信息有误 功能正常
6.2.2 数据库连接功能测试
功能描述 数据库连接功能
用例目的 验证改模块可以正常从数据表中显示信息,添加,修改,查询
前提条件 正确登录进入后台管理页面
录入/动作 期望的输出/相应 实际情况 测试结果评价
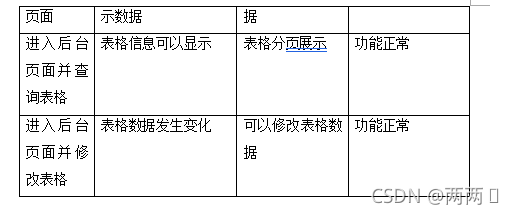
进入前端页面 各个表格可以正常显示数据 表格可以显示数据 功能正常
进入后台页面并查询表格 表格信息可以显示 表格分页展示 功能正常
进入后台页面并修改表格 表格数据发生变化 可以修改表格数据 功能正常

6.2.3 爬虫功能测试
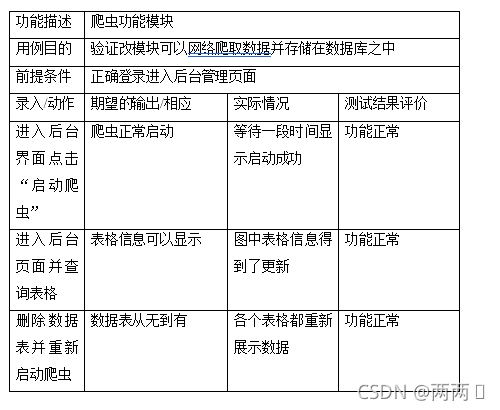
功能描述 爬虫功能模块
用例目的 验证改模块可以网络爬取数据并存储在数据库之中
前提条件 正确登录进入后台管理页面
录入/动作 期望的输出/相应 实际情况 测试结果评价
进入后台界面点击“启动爬虫” 爬虫正常启动 等待一段时间显示启动成功 功能正常
进入后台页面并查询表格 表格信息可以显示 图中表格信息得到了更新 功能正常
删除数据表并重新启动爬虫 数据表从无到有 各个表格都重新展示数据 功能正常
6.2.4 数据展示功能测试
功能描述 数据展示功能测试
用例目的 验证改模块可以从数据库提取数据并在前端界面展示
前提条件 正确登录进入后台管理页面
录入/动作 期望的输出/相应 实际情况 测试结果评价
进入后台界面点击“启动爬虫” 爬虫正常启动 等待一段时间显示启动成功 功能正常
进入前台页面 数据得到刷新 时间在跳转,词云图有数据,疫情地图和折线图数据都得到了展示 功能正常
删除数据表并重新启动爬虫 数据表从无到有 可以看到前端界面的表格重新加载 功能正常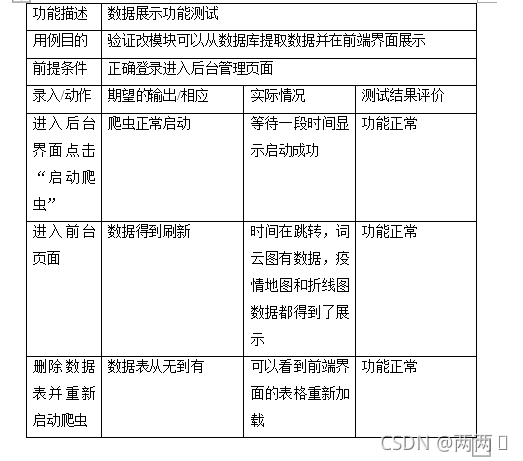
6.3 测试结论
在系统的功能测试中,本论文从主要功能模块中抽出了三个模块进行测试,
包括登录模块、数据库链接模块,数据展示模块和爬虫模块的测试。
之后,该系统可以正常运行,达到了预期的要求。
第七章 总结与展望
7.1 总结
还有很多知识我们都不懂,比如有点糊里糊涂的感觉。看来,课本的知识还是不够的,我们应该扩展自己的课外知识,多多阅读课外的相关知识,这样才能对flask、MySQL、Intellij IDEA、Python、Echarts更加熟悉。 在此我们要谢谢帮助我们解决难题的同学们,没有他们的解答和热心帮助,我们很难完成这个课设。如今科技发展迅速,而Java作为一门计算机语言类的重要课程,要学好python 是必然的。我们坚信,只要有兴趣,就能学好。我们会培养好自己对Java的兴趣,而且继续保持下去,为以后的路做好铺垫。
经过一个月的努力,疫情实时监控系统的基本功能已经实现。虽然时间很短暂,但却是对几年学习中理论知识和实践相结合的一次综合检验。通过这次毕业设计,收到了比以往理论课程还要大的收益,虽然由于时间仓促及团队能力有限,系统还有很多不尽人意的地方:比如说界面不够美观;有些功能还不够完善和强大;代码的重用性不够高;一些细节的问题还没有解决。这些都需要平时经验的积累和对技术的熟练掌握,希望在以后的工作学习中能有进一步的提高。
当然因团队能力与时间的限制,系统的一些功能还存在一些不足,有待改进与完善。最后在整个过程中得到了指导老师和同学们的许多帮助,使我们顺利的完成了这个系统,在这里,我们表示衷心的感谢!
7.2 展望
和python相比,老牌语言C和C++有许多细节需要我们自己处理,在处理不当的情况下会产生程序崩溃和其他很难解决的问题。Java虽说解决了前者的许多缺点,但相比之下代码更加冗长,写起来也有许多限制。 python简洁的语法可以让我们写出比静态语言更短的程序,它的设计极大的增强了代码的可读性,这就可以让我们初学者学习和记忆更加容易,也更容易修改。我希望学习这门课后可以自己用python这一语言编写爬虫,爬取B站上我喜欢的UP主的视频。这次项目设计开发为今后的学习和工作产生了积极的意义。由于还是初学者,在项目设计中还有欠缺和考虑不周的地方。
致谢
时光飞逝,一个月的学习即将划上圆满的句号,回忆逝去的学习光阴,
心中的感激之情溢于言表。我能够顺利的完成此阶段的学习任务,与
老师、学友和朋友的关心与支持是分不开的,也离不开学校各部门的
工作人员和老师的指导与帮助。借此机会,向所有帮
助过我的人道声真诚的感谢!
老师的严谨的治学风格以及丰富的学识,给我留下了深刻的印象;
老师那的高尚师德及良好的生活态度,将是我的力量源泉,
在以后的生活道路上,
也将继续激励着自己克服生活及学习中的困难。
此外,还要感谢我的父母,还有给我关心和支持的亲人,正是他们的帮助和
支持,使我有毅力、信心完成学业。祝你们平安、健康。