自学python一个月赚取第一桶金,内心超级激动就忍不住想要分享
自学python一个月赚取第一桶金
正文
-
- 自学python一个月赚取第一桶金
- 爬取数据
-
- 数据挖掘
-
- 提交订单
- 心得
大二学生一枚,了解到了python之后就开始了自学,通过csdn的学习,还有加入了python学习群向他们请教,学了一个月之后就尝试接单,赚取了第一桶金。在接单群接到了一份python期末设计。题目如下:
综合使用课程所学的python编程技术,数据处理和分析方法,数据挖掘技术,能够对各种业务数据进行预处理、分析和挖掘。通过课程设计,能熟练掌握和使用数据预处理方法,掌握数据探索方法,会根据数据进行模型选择和建模分析.
(1)从网上爬取某个业务数据,或者从网上下载公开的数据集
(2)对获取的数据集进行数据分析和探索
(3)根据行业知识确定数据挖掘的目标
(4)选择对应的数据挖掘算法对数据进行智能处理和挖掘
(5)对智能处理和挖掘的结果进行业务上的推断和整理
根据题目要求的,我们可以把问题拆分为三个部分:
- 爬取数据,这个我爬取的是淘宝网的手机数据
- 挖掘数据,对爬取的数据进行数据清洗,分析
- 报告排版
爬取数据
爬取的是淘宝手机销量数据,本文爬取淘宝关于“手机”的搜索结果,包含标题、价格、原价、店铺、月销量字段。将结果保存成csv格式,并作简单分析。
用到的python库:selenium、urllib、pyquery、pandas。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
import urllib.parse
from pyquery import PyQuery as pq
import pandas as pd
def scratch_page(driver, url, page):
"""获取网页源代码"""
wait = WebDriverWait(driver, 10)
retry_num = 0
while retry_num < 3: # 如果打开页面失败,则最多重复三次
try:
driver.get(url % (urllib.parse.quote(keyword), page))
# 等待页面加载完成
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR, '.pc-search-page-item-after'), '下一页'))
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.pc-search-items-list li')))
retry_num = 3
except:
retry_num += 1
return driver
def goods(html):
"""获取单页的所有商品"""
# 解析网页源代码
doc = pq(html)
# 抓取字段:标题、价格、原价、店铺名、月销量
items = doc('.pc-search-items-list').children('li')
for item in items.items():
title = item.find('.title-text').text() # 标题
discount_price = item.find('.coupon-price-afterCoupon').text() # 价格
original_price = item.find('.coupon-price-old').text() # 原价
shop = item.find('.seller-name').text() # 店铺
monthly_sales = item.find('.sell-info').text() # 月销量
yield [title, discount_price, original_price, shop, monthly_sales]
def main(keyword, total_pages):
url = 'https://uland.taobao.com/sem/tbsearch?keyword=%s&pnum=%d'
chrome_options = Options()
chrome_options.add_argument('--headless') # 设置无头chrome
driver = webdriver.Chrome(options=chrome_options)
goods_list = pd.DataFrame(columns=['category', 'title', 'discount', 'original_price', 'shop', 'monthly_sales'])
# 按页爬取
for page in range(total_pages + 1):
print('正在抓取第%d页...' % (page + 1))
driver = scratch_page(driver, url, page)
html = driver.page_source
items = goods(html)
for item in items:
item.insert(0, keyword)
goods_list.loc[len(goods_list)] = item
# 将结果保存到csv中
goods_list.to_csv('淘宝商品_%s.csv' % keyword, index=False, encoding='utf-8-sig')
driver.close()
print('\n抓取完成')
return
if __name__ == '__main__':
keyword = '手机'
total_pages = 16 # 每页60
main(keyword, total_pages)
在程序运行之后可以看到文件夹多出了.csv的文档,这就是爬取到的原始数据了接下来就是下一步。
数据挖掘

可以看到原始数据之中有很多的问题:
- 表格中原价的那一列中都是¥,我们要把它替换成数值
- 包含了手机壳、蓝牙耳机等非手机数据,需要做进一步数据清洗。
- 有重复值要进行去重处理
这里出现了一个问题:df[‘original_price’]=df[‘original_price’].astype(‘float64’)
could not convert string to float: ‘¥2699.00’
将original_price的货币价格转化为浮点数据的时候报错
pandas不能够直接将货币转为数值型
解决方案: pandas实现数据类型转换有三种基本方法:
使用astype()函数进行强制类型转换
自定义函数进行数据类型转换
使用Pandas提供的函数如to_numeric()、to_datetime()
import pandas as pd
import numpy as np
data=pd.read_csv('path',sep=',' ,header = 0,encoding='gbk',usecols=['col1','col2','col3'])#导入数据,把path改成文件路径;数据中有中文的话,就用encoding='gbk',没有中文的话就用encoding='utf-8';usecols是可以让我们选择哪几列
data.head()#查看前五行
data.info()#查看各字段的信息,其中包含行数、是否为空、字符类型
data.shape#查看数据集行列分布,几行几列
data.describe()#查看数据的描述性统计,其中包括总数、均值、标准方差、最小最大、第一四分位数、中位数
计算各个属性的统计指标:均值、方差、中位数、众数、最大值、最小值、偏度、峰度、极差、分位数,画出箱型图、直方图、概率分布图等,观察数据的特性。
个

利用matplotlib子模块pyplot中的boxplot函数可以非常方便地绘制箱线图,其中左图的上下须设定为1.5倍的四分位差,右图的上下须设定为3倍的四分位差。从左图可知,发现数据集中至少存在5个异常点,它们均在上须之上;而在右图中并没有显示极端异常点。
import numpy as np
import matplotlib.pyplot as plt
df=pd.read_csv('淘宝商品_手机.csv')
plt.boxplot(x=df.original_price,
whis=1.5,
widths=0.7,
patch_artist=True,
showbox=True,
boxprops={
'facecolor': 'steelblue'}, # 指定箱体的填充色为铁蓝色
# 指定异常点的填充色、边框色和大小
flierprops={
'markerfacecolor': 'red', 'markeredgecolor': 'red', 'markersize': 4},
# 指定均值点的标记符号(菱形)、填充色和大小
meanprops={
'marker': 'D', 'markerfacecolor': 'black', 'markersize': 4},
medianprops={
'linestyle': '--', 'color': 'orange'}, # 指定中位数的标记符号(虚线)和颜色
labels=[''] # 去除箱线图的x轴刻度值
)
# 显示图形
plt.show()

可以对数据进行深一步挖掘,然后在进行分析

可以看到“打折“力度大的基本都是低端机型,在价格透明、利润降低的今天,商家难以再维持多年前低配高价的情景。老年机、山寨机打着股折价的幌子,继续靠此手段吸引信息不对称的低收入人群。
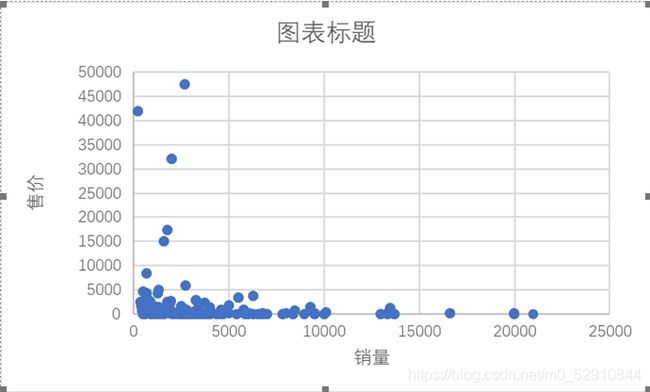
1000-2000元档的手机销量最好。普通打工人不会花太高的钱去买一部手机,再一个,电子产品更新迭代的很快,现在1000出头的手机已经做的不错了,看电视、拍照、打游戏都绰绰有余。
售价出现频率直方图: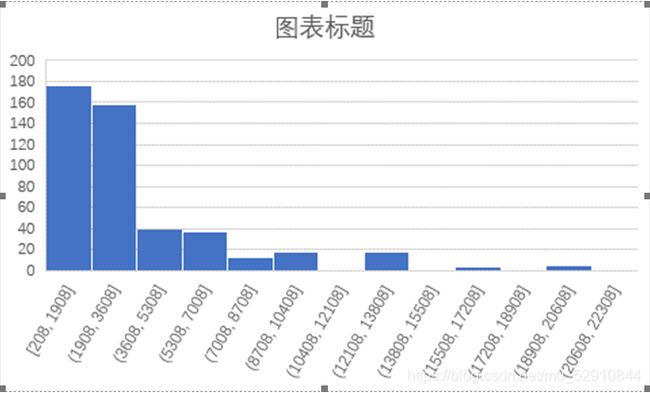
可以看到绝大多数手机价位分布在3600一下,这和现在智能机的普及有很大的关系,手机基本人手一套,飞入百姓寻常家。
提交订单
完成上面的步骤之后,就是要对报告进行排版布局及进一步整理,这里就不多一一赘述了,然后就是喜闻乐见的时刻,就是提交文档,审核通过之后就等待佣金的发放了。

听到熟悉的支付宝到账,那时候莫名的心安,不枉我洗头掉的那几根头发啊
心得
老实说虽然之前也通过一些其他的兼职(办卡,销售,跑腿,包括现在的寒假工)实现了经济的部分独立,但是结合专业知识赚钱还是头一遭啊,内心肯定是非常的激动的,不过在这一单中真的发现了自己的水平很差劲,有时候大佬们要解释很久才知道自己是哪里出现了问题,只能深深的懊恼,而且在之后和别人解释的时候发现了自己竟然有很多地方都不明白,只能说可以拿过来用却不知道怎么和别人解释,只能说且行且珍惜,慢慢来,好好生活,慢慢遇见。
要是有兴趣的可以点个关注,支持一下我啊,超级感谢,想要交流的也可以加我q1825487691,欢迎交流啊。