pytorch学习笔记
学习目标:学会如何应用pytorch;理解深度学习/神经网路的基础
人工智能:1、推理。根据外界信息做出决策。2、预测。例如根据猫的图片和抽象的概念(cat)联系起来。
机器学习:把推理、预测的过程通过算法实现;算法:穷举法,贪心法,分治法,动态规划。从数据集中把想要的算法提取出来(监督学习)
开发学习系统:基于规则的学习,经典的机器学习方法(进行手工特征提取得到特征向量,和输出之间找到映射关系)、表示学习(把高维特征转换为低维特征)
因为使用电脑不方便,略过了很多内容。有机会重拾一下。
本文内容是根据up主刘二大人视频整理。
用CNN网络实现MINIST手写数字识别代码实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.optim as optim
#数据处理
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))])
train_dataset = datasets.MNIST('./data',train=True,download=False,transform=transform)
test_dataset = datasets.MNIST('./data',train=False,transform=transform)
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size,drop_last=True)
test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size,drop_last=True)
#构建模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1,out_channels=10,padding=1,kernel_size=3)
self.conv2 = nn.Conv2d(in_channels=10,out_channels=20,kernel_size=3)
self.conv3 = nn.Conv2d(in_channels=20,out_channels=16,kernel_size=3)
self.pooling = nn.MaxPool2d(kernel_size=2)
self.layer1 = nn.Linear(64,128)
self.layer2 = nn.Linear(128,32)
self.layer3 = nn.Linear(32,10)
def forward(self,x):
x = self.pooling(F.relu(self.conv1(x)))
x = self.pooling(F.relu(self.conv2(x)))
x = self.pooling(F.relu(self.conv3(x)))
x = x.view(batch_size,-1)
x = F.relu(self.layer1(x))
x = F.relu(self.layer2(x))
x = self.layer3(x)
return x
#实例化模型
model = Net()
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
#选择损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
#定义训练函数
def train(epoch):
train_loss = 0.0
for idx,data in enumerate(train_loader):
inputs,target = data
inputs,target = inputs.to(device),target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs,target)
loss.backward()
optimizer.step()
train_loss += loss.item()
if idx % 300==299:
print("[%d,%5d] loss : %.3f"%(epoch+1,idx+1,train_loss/300))
train_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():#不计算梯度
for data in test_loader:
images,labels = data
images,labels = images.to(device),labels.to(device)
output = model(images)
_,predicted = torch.max(output.data,dim=1)
total += labels.size(0)
correct += (predicted==labels).sum().item()
print('Accuracy on test set:%d %%'%(100*correct/total))
if __name__=='__main__':
for epoch in range(10):
train(epoch)
if epoch % 1 ==0:
test()
注意的问题:卷积层输入通道和输出通道数要对应起来,卷积层的输出连接全连接层时要做flatten,在数据加载时,Datalodaer中的参数drop_last=True
google_net网络中的inception模块代码实现
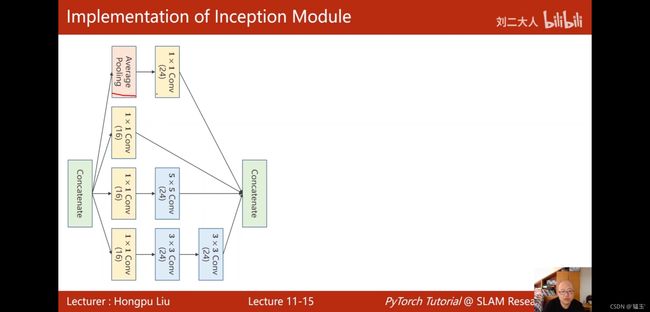
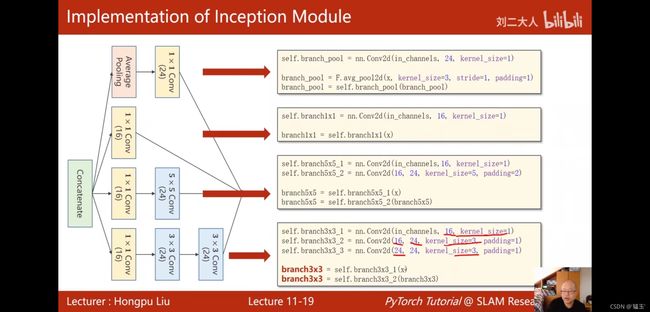
使用Google_Net网络实现手写数字识别:
#使用google_net实现手写数字识别
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.optim as optim
#数据准备
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))])
train_dataset = datasets.MNIST('./data',train=True,download=False,transform=transform)
test_dataset = datasets.MNIST('./data',train=False,transform=transform)
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size,drop_last=True)
test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size,drop_last=True)
#多了InceptionA类
class InceptionA(nn.Module):
def __init__(self,in_channels):
super(InceptionA, self).__init__()
self.branch1x1 = nn.Conv2d(in_channels=in_channels,out_channels=16,kernel_size=1)
self.branch5x5_1 = nn.Conv2d(in_channels,16,kernel_size=1)
self.branch5x5_2 = nn.Conv2d(16,24,kernel_size=5,padding=2)
self.branch3x3_1 = nn.Conv2d(in_channels,16,kernel_size=1)
self.branch3x3_2 = nn.Conv2d(16,24,kernel_size=3,padding=1)
self.branch3x3_3 = nn.Conv2d(24,24,kernel_size=3,padding=1)
self.branch_pool = nn.Conv2d(in_channels,24,kernel_size=1)
def forward(self,x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
branch_pool = F.avg_pool2d(x,kernel_size=3,stride=1,padding=1)#调用平均池化函数,没用现成的类
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1,branch5x5,branch3x3,branch_pool]
#沿着通道方向拼接起来,输出张量为[batch,channel,weight,height]所以dim=1,
return torch.cat(outputs,dim=1)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1,10,kernel_size=5)
self.conv2 = nn.Conv2d(88,20,kernel_size=5)
#为什么是88,在forward里inception的输出为(24*3+16)
self.incep1 = InceptionA(in_channels=10)
self.incep2 = InceptionA(in_channels=20)
self.mp = nn.MaxPool2d(kernel_size=2)
#全连接层
self.fc = nn.Linear(1408,10)
#这里的1408,可以让模根据全连接层之前的输出得到,forward中使用x.size()
def forward(self,x):
in_size = x.size(0)#in_size=batch_size
x = F.relu(self.mp(self.conv1(x)))
x = self.incep1(x)
x = F.relu(self.mp(self.conv2(x)))
x = self.incep2(x)
x = x.view(in_size,-1)
x = self.fc(x)
#全连接层不用做激活,因为使用nn.CrossEntropyLoss中包含了softmax激活
#未来可以增加全连接层来提高正确率
return x
#实例化模型
model = Net()
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
# 选择损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
#使用下面这段代码可以得到卷积层的输出张量,使用时去掉注释符,并把下面的训练代码和测试代码加上注释
# for idx, data in enumerate(train_loader):
# inputs, target = data
# inputs, target = inputs.to(device), target.to(device)
# optimizer.zero_grad()
# outputs = model(inputs)
# print(outputs.size())
# break
#torch.Size([64, 88, 4, 4])88*4*4=1408
#定义训练函数
def train(epoch):
train_loss = 0.0
for idx, data in enumerate(train_loader):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
train_loss += loss.item()
if idx % 300 == 299:
print("[%d,%5d] loss : %.3f" % (epoch + 1, idx + 1, train_loss / 300))
train_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad(): # 不计算梯度
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
output = model(images)
_, predicted = torch.max(output.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set:%d %%' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
if epoch % 1 == 0:
test()
Residual net 残差网络
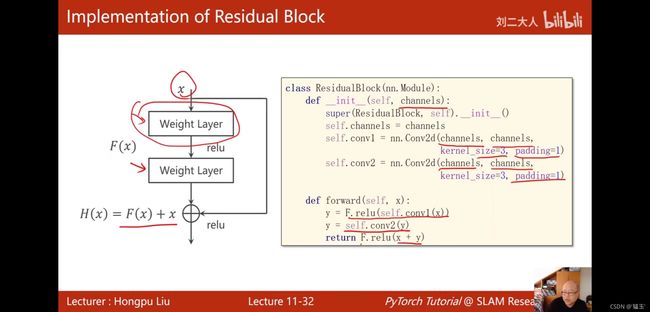
class ResidualBlock(nn.Module):
def __init__(self,channels):
super(ResidualBlock, self).__init__()
self.channels = channels
self.conv1 = nn.Conv2d(channels,channels,kernel_size=3,padding=1)
self.conv2 = nn.Conv2d(channels,channels,kernel_size=3,padding=1)
def forward(self,x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
return F.relu(x+y)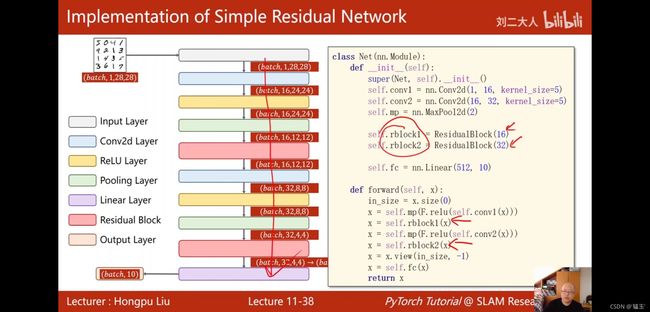
使用残差网络实现手写数字识别:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.optim as optim
#数据处理
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))])
train_dataset = datasets.MNIST('./data',train=True,download=False,transform=transform)
test_dataset = datasets.MNIST('./data',train=False,transform=transform)
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size,drop_last=True)
test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size,drop_last=True)
#做残差连接时输入输出的大小和通道数要相同
class ResidualBlock(nn.Module):
def __init__(self,channels):
super(ResidualBlock, self).__init__()
self.channels = channels
self.conv1 = nn.Conv2d(channels,channels,kernel_size=3,padding=1)
self.conv2 = nn.Conv2d(channels,channels,kernel_size=3,padding=1)
def forward(self,x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
return F.relu(x+y)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1,16,kernel_size=5)
self.conv2 = nn.Conv2d(16,32,kernel_size=5)
self.mp = nn.MaxPool2d(kernel_size=2)
self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(32)
self.fc = nn.Linear(512,10)
def forward(self,x):
in_size = x.size(0)
x = self.mp(F.relu(self.conv1(x)))
x = self.rblock1(x)
x = self.mp(F.relu(self.conv2(x)))
x = self.rblock2(x)
x = x.view(in_size,-1)
x = self.fc(x)
return x
#实例化模型
model = Net()
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
#选择损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
#定义训练函数
def train(epoch):
train_loss = 0.0
for idx, data in enumerate(train_loader):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
train_loss += loss.item()
if idx % 300 == 299:
print("[%d,%5d] loss : %.3f" % (epoch + 1, idx + 1, train_loss / 300))
train_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad(): # 不计算梯度
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
output = model(images)
_, predicted = torch.max(output.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set:%d %%' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
if epoch % 1 == 0:
test()
深度学习计划
1、理论学习《深度学习》
2、阅读pytorch文档(通读一遍)
3、复现经典工作(读代码+写代码)