零基础python爬虫入门:搜索和批量下载图片
目录
- python爬虫批量下载图片
-
- 前言
- 一、具体流程
-
- 1、使用必应搜索图片
- 2、实现方法
-
- 导入模块
- 具体代码
- 二、效果演示
python爬虫批量下载图片
前言
本篇文章以在必应下载硬币图片为例,实现python爬虫搜索和批量下载图片。
以下为本篇文章的正文内容。
一、具体流程
1、使用必应搜索图片
和上篇文章实现小说下载一样,首先我们要查看搜索页面的HTML。如下图右侧所示,那个’murl‘就是第一张图所对应的网址。
但是当我们将页面往下拉时,从下图所示位置的内容和上图对比可以发现该内容中的网址发生了改变。

复制该网址并在前面加上https://cn.bing.com,进入网址后,我们可以尝试将该网址的某些我们不需要的东西删去(可以一个一个删,根据删除后页面的变化判断是否可以删去)将“https://cn.bing.com/images/async?q=硬币&first=292&count=35&cw=1177&ch=737&relp=35&tsc=ImageBasicHover&datsrc=I&layout=RowBased&mmasync=1&dgState=x440_y1152_h180_c2_i281_r60”变成“https://cn.bing.com/images/async?q=硬币&first=1&count=35&cw=1177&ch=737&relp=35&tsc=ImageBasicHover&datsrc=I&layout=RowBased&mmasync=1”。变化如下图所示,也可发现通过改变first可以切换页面。

在此页面中,我们依然可以找到图片所对应的网址。之后类似之前下载小说的方法,就可以实现图片批量下载了。
2、实现方法
整体思路:首先通过前篇文章中使用的requests和BeautifulSoup模块,发送get请求和使用find_all找到对应标签的方法,得到获取上图网址中图片网址所在标签的内容,然后将其中的"m=…"提取出来。再从提取后的内容中把对应图片网址的"murl"提取出来,然后发送get请求并将其二进制数据写入至xx.jpg中。
前半段的实现方法和前篇文章的方法大同小异,后半段的"murl"是json字符串中的内容,我们可以通过json模块将其转化为字典形式。
import requests
from bs4 import BeautifulSoup
import json
url = 'https://cn.bing.com/images/async?q=硬币&first=1&count=35&cw=1177&ch=737&relp=35&tsc=ImageBasicHover&datsrc=I&layout=RowBased&mmasync=1'
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.64'
}
r0 = requests.get(url,headers = head).text #发送get请求并将内容转化成文本
soup = BeautifulSoup(r0,features="lxml").find_all('a','iusc') #解析r0并找到a和class=iusc的标签
data = str(soup[0].get('m')) #将列表soup的第0位中的m提取出来
zidian = json.loads(data) #将data转化成字典形式
print(data)
print('\n')
print(zidian)

其中head为该网址的请求标头内容。同样的,后面图片对应的网址也有其对应的请求标头,右键检查后点击网络,再刷新下该网页,就可以看到下图所示的请求标头了。其murl对应的网址为"http://pic40.nipic.com/20140407/17944631_094106491173_2.jpg"。(虽然此处不用请求标头同样可以获取图片的二进制数据)
有35张图片页面可以通过len()的方法判断图片数量,当然也可以一张一张数,效果一样。
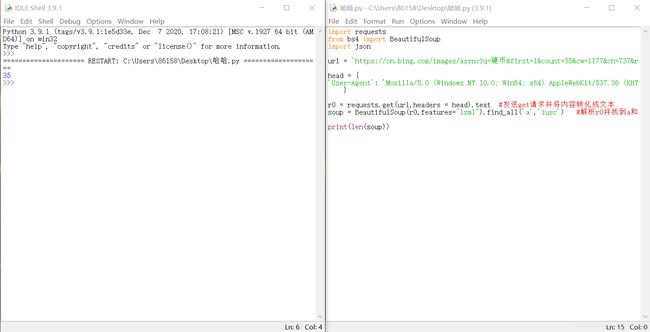
导入模块
import requests
from bs4 import BeautifulSoup
import json
import eventlet
import os
导入之前可以先使用pip方法安装对应的库
pip install xxx
其中eventlet模块是用来判断访问是否超时的,如下所示
with eventlet.Timeout(1,False): #设定1秒的超时判断
try:
picture = requests.get(url).content
except:
print('图片超时异常') #说明图片异常
如超过1秒则会运行except的内容。
具体代码
具体代码如下所示,此代码会在其所在目录下创建一个名为"图片"的文件夹,然后通过用户输入的查找内容和查找图片数量,将对应内容和数量的图片下载到"图片"文件夹中。(前提是该目录下不存在名为"图片"的文件夹)
import requests
from bs4 import BeautifulSoup
import json
import eventlet
import os
urlshu = 1 #url中first = urlshu
pictureshu = 1 #图片下载时的名字(加上异常图片的第几张图片)
soupshu = 0 #每35张soup列表中第soupshu个
whileshu = 35 #用于while循环的数(因为每个页面35张图片)
os.mkdir('C:/tu/图片') #创建文件夹'图片'
url1 = 'https://cn.bing.com/images/async?q='
url2 = '&first=%d&count=35&cw=1177&ch=737&relp=35&tsc=ImageBasicHover&datsrc=I&layout=RowBased&mmasync=1'
head1 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.64'
}
#有35张图片的网页的请求标头
head2 = {
'Cookie': 'Hm_lvt_d60c24a3d320c44bcd724270bc61f703=1624084633,1624111635',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.64'
}
#具体图片的网页的请求标头
print('请输入查找内容:')
content = input()
print('请输入查找图片数量:')
number = int(input())
url = url1 + content + url2 #合并成去往有35张图片的网址
while whileshu:
r0 = requests.get(url%urlshu,headers = head1).text #发送get请求并将内容转化成文本
soup = BeautifulSoup(r0,features="lxml").find_all('a','iusc') #解析r0并找到a和class=iusc的标签
data = str(soup[soupshu].get('m')) #将列表soup的第soupshu位中的m提取出来
zidian = json.loads(data) #将data转化成字典形式
ifopen = 1 #用于下方判断是否下载图片
with eventlet.Timeout(1,False): #设定1秒的超时判断
try:
picture = requests.get(zidian['murl'],headers = head2).content #发送get请求并返回二进制数据
except:
print('图片%d超时异常'%pictureshu) #说明图片异常
ifopen = 0 #取消下载此图片,否则会一直卡着然后报错
while ifopen == 1:
text = open('图片/' + '%d'%pictureshu + '.jpg','wb') #将图片下载至文件夹'图片'中
text.write(picture) #上行代码中'wb'为写入二进制数据
text.close()
ifopen = 0
number = number - 1
pictureshu = pictureshu + 1
soupshu = soupshu + 1
whileshu = whileshu - 1
if whileshu == 0: #第一页图片下载完成,将网址的first进1
urlshu = urlshu + 1
whileshu = 35
soupshu = 0
if number == 0: #下载图片数量达标,退出循环
break
二、效果演示
不知道为啥,有些图片下载得很慢。这个演示的是下载40张图片的,中间有2张图片判断为超时然后跳过了,所以图片下载到了42.jpg。
python爬虫批量下载图片
我是一名学生,目前正在学习中,本篇文章也是我的学习笔记,如有错误的话还请指正。