为什么叫 HTTP/2 ,而不是 HTTP/2.0 ?
作者: Tom哥
简介:计算机研究生,校招进阿里,期间还拿过百度、华为、中兴、腾讯等6家大厂offer,P7 技术专家。出过专利,CSDN博客专家。
公众号:微观技术,分享其他地方看不到的知识与思考,欢迎关注
大家好,我是Tom哥~
今天跟大家聊聊下 HTTP协议,欢迎留言讨论
互联网时代,足不出户,点点鼠标就可以轻松了解外面的世界变化,这一切得益于网络传输数据。
我们都知道网络有7层模型,从底层到上层依次是:物理层、数据链路层、网络层、传输层、会话层、表示层、应用层。
越往上,越接近用户习惯,更容易被用户直观了解。
今天讲的 HTTP 协议属于应用层协议,也是互联网广泛使用的基础协议之一。
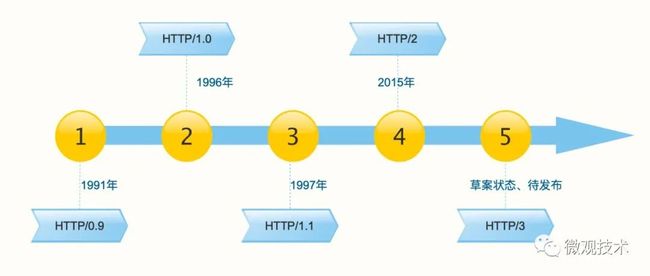
一、 HTTP/0.9
0.9 版本是HTTP最早的版本,诞生于 1991 年,比较简单。
1、只支持 GET 请求,没有请求头。每次请求都要单独创建一个TCP连接,复用性差,性能不高
2、服务端响应的数据只能是 HTML格式,服务器发送完毕,会关闭TCP连接。如果请求的页面不存在,也不会返回任何错误码。
当时,互联网刚起步,页面展现形式更多是文本为主,能满足基本需求。随着用户需求的多样化,对展示形态和性能也提出了更高要求,HTTP协议也开始了慢慢的升级之路。
二、 HTTP/1.0
1996年,HTTP/1.0 发布,相比之前版本增加了很多特性。
1、请求和响应增加了头信息(header),用来描述一些元数据,如:
Content-Type 让响应数据不只限于超文本
Expires、Last-Modified 缓存
Authorization 身份认证
Connection: keep-alive 支持长连接,但非标准
2、请求方法,除了 GET,还增加了 POST、HEAD命令,丰富了互动方式
3、丰富了传输内容的格式,有文本、图像、视频、二进制文件
4、请求时增加 HTTP 协议版本,响应端增加状态码。
缺点:
主要还是连接复用问题,每个TCP连接只能发送一个请求。当数据发送完毕后,连接就会关闭。由于TCP建立连接,需要三次握手,所以性能会比较差。
为了缓解这个问题,请求头引入一个非标准的Connection字段:Connection: keep-alive,要求服务器不要关闭TCP连接,从而达到复用效果。
当然,这个不是标准字段,只是一个临时方案。
三、 HTTP/1.1
1997年,HTTP/1.1 版本发布。进一步完善了HTTP协议,也是目前最流行的版本,一直活跃至今。
1、默认支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟
2、管线化技术。支持多个 HTTP 请求批量发送,不用排队,这就解决了 HTTP 队头阻塞问题。但批量发送的 HTTP 请求,必须按照发送的顺序返回响应
3、流式渲染,响应端可以不用一次返回所有数据,可以将数据拆分成多个模块,产生一块数据,就发送一块数据,这样客户端就可以同步对数据进行处理,减少响应延迟,降低白屏时间。
4、请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接
5、增加 Host 头,实现了虚拟主机技术,将一台服务器分成若干个主机,这样就可以在一台服务器上部署多个网站了。通过配置 Host 的域名和端口号,即可支持多个 HTTP 服务
6、头部增加一些缓存字段,如 E-Tag、Cache-Control 等
7、新增了24个错误状态响应码,如 409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
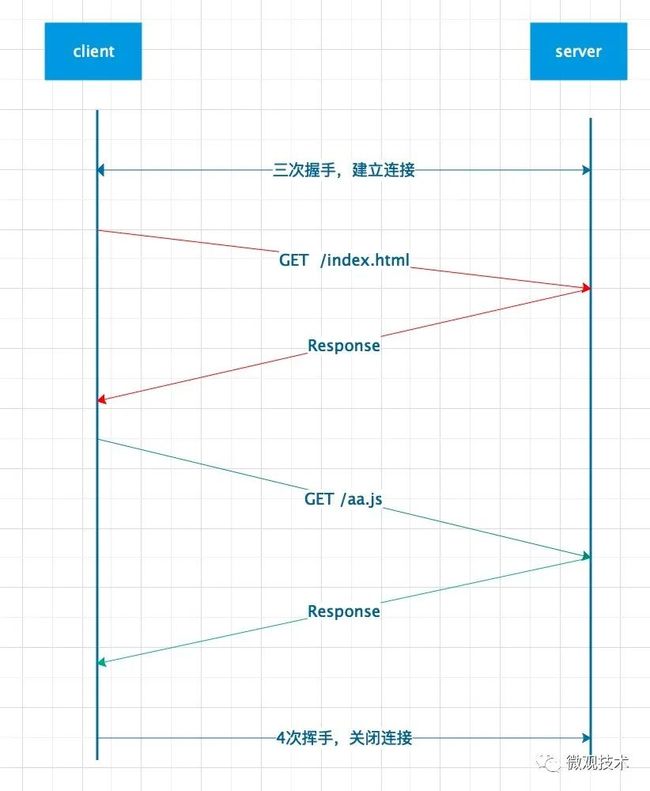
小结:
请求和响应成对出现,顺序串行。如果按QPS来理解的话,最大的并发数只能是 1
四、 HTTP/2
HTTP/2 诞生于 2015 年,最大特点是基于二进制的特性,对 HTTP 传输效率进行了深度优化。
新增了哪些特性?
1、二进制帧
HTTP/2 将一个 HTTP 请求划分为 3 个部分:二进制帧、消息、数据流
-
帧:一段二进制数据,是 HTTP/2 传输的最小单位
-
消息:逻辑上的 HTTP 消息,比如请求、响应等,由一或多个帧组成
-
数据流:连接中的一个虚拟信道,可以同时承载一条或多条消息,支持双向承载
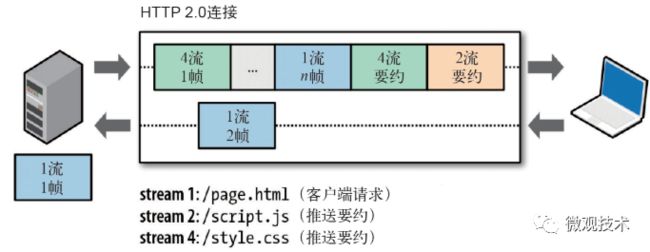
一个TCP连接上,承载着双向消息,一条消息包含多个二进制帧,每个帧都有唯一标识,来自不同数据流的帧可以交错发送,然后再根据每个帧头的数据流标识符重新组装,这样就实现了数据传输。
2、多路复用
HTTP/1.1 中的 KeepAlive 长连接虽然可以传输很多请求,但它的吞吐量很低,因为在发出请求等待响应的那段时间里,这个长连接不能做任何事!而 HTTP/2 通过 Stream 这一设计,允许请求并发传输。因此,HTTP/1.1 时代 Chrome 通过 6 个连接访问页面的速度,远远比不上 HTTP/2 单连接的速度。
HTTP/2 的并发性能比 HTTP/1.1 通过 TCP 连接实现并发要高。这是因为,当 HTTP/2 实现 100 个并发 Stream 时,只经历 1 次 TCP 握手、1 次 TCP 慢启动以及 1 次 TLS 握手,但 100 个 TCP 连接会把上述 3 个过程都放大 100 倍!
3、头部压缩
HTTP/1.1 的头部字段包含大量信息,而且每次请求都得带上,占用了大量的带宽。
HTTP/2 静态表仅用一个数字来表示,其中,映射数字与字符串对应关系的表格,被写死在 HTTP/2 实现框架中。这样的编码效率非常高,
什么是静态表呢?HTTP/2 将 61 个高频出现的头部,比如描述浏览器的 User-Agent、GET 或 POST 方法、返回的 200 SUCCESS 响应等,分别对应 1 个数字再构造出 ”字典“,并写入 HTTP/2 客户端与服务端,用索引号表示重复的字符串,可以达到 50%~90% 的高压缩率。
4、请求优先级
由于采用多路复用,多个请求会同时产生多个数据流,数据流中有一个优先级的标识,服务端根据这个标识决定响应的优先顺序。
流 ID 不能重用,只能顺序递增,客户端发起的 ID 是奇数,服务器端发起的 ID 是偶数;
5、服务器端推送
HTTP/1.1 不支持服务器主动推送消息,因此当客户端需要获取通知时,只能通过定时器不断地轮询拉取消息。HTTP/2 的消息推送结束了无效率的定时拉取,节约了大量带宽和服务器资源。
例如:HTTP/1.1 中请求一个页面时,浏览器会先发送一个 HTTP 请求,然后得到响应的 HTML 内容并开始解析,如果发现有