kubernetes搭建prometheus(五)Alertmanager告警
prometheus可以配置告警策略,但无法发送告警信息到邮件或者其他终端媒介,Alertmanager就是实现将prometheus的告警信息发送到终端的一个插件。
本文介绍的是通过Alertmanager将告警发送到企业微信中
准备:
需要一个企业微信账号,网页端登录后创建一个应用,需要应用中的 AgentId 、Secret 和 企业ID
AgentId 、Secret 这两个点开创建的应用后就能看见
企业ID 在我的企业中最下方可以看到
创建告警配置文件
alertmanager-configmap-wx.yaml
apiVersion: v1
kind: ConfigMap
metadata:
# 配置文件名称
name: alertmanager-config
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: EnsureExists
data:
alertmanager.yml: |
global:
resolve_timeout: 5m
receivers:
- name: 'wx'
wechat_configs:
- send_resolved: true
agent_id: '1000007' # 自建应用的agentId
to_user: '@all' # 接收告警消息的人员Id
api_secret: 'xxxxxxxxxxxxxxxxx' # 自建应用的secret
corp_id: 'xxxxxxxxxx' # 企业ID
route:
group_interval: 1m
group_wait: 10s
receiver: wx
repeat_interval: 1m
templates:
- /etc/alertmanager/config/template.tmp1需要修改agent_di、api_secret 和 corp_id
创建告警模板文件
用于将告警信息格式化输出到企业微信中
就是 alertmanager-configmap-wx.yaml 中的 - /etc/alertmanager/config/template.tmp1
alertmanager-template.yaml
apiVersion: v1
kind: ConfigMap
metadata:
# 配置文件名称
name: alter-template-config
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: EnsureExists
data:
template.tmp1: |
{
{ define "wechat.default.message" }}
{
{- if gt (len .Alerts.Firing) 0 -}}
{
{- range $index, $alert := .Alerts -}}
{
{- if eq $index 0 }}
===异常告警===
告警类型: {
{ $alert.Labels.alertname }}
告警级别: {
{ $alert.Labels.severity }}
告警详情: {
{ $alert.Annotations.description}}
故障时间: {
{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{
{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {
{ $alert.Labels.instance }}
{
{- end }}
{
{- if gt (len $alert.Labels.namespace) 0 }}
命名空间: {
{ $alert.Labels.namespace }}
{
{- end }}
{
{- if gt (len $alert.Labels.node) 0 }}
节点信息: {
{ $alert.Labels.node }}
{
{- end }}
{
{- if gt (len $alert.Labels.pod) 0 }}
实例名称: {
{ $alert.Labels.pod }}
{
{- end }}
===END===
{
{- end }}
{
{- end }}
{
{- end }}
{
{- if gt (len .Alerts.Resolved) 0 -}}
{
{- range $index, $alert := .Alerts -}}
{
{- if eq $index 0 }}
===异常恢复===
告警类型: {
{ $alert.Labels.alertname }}
告警级别: {
{ $alert.Labels.severity }}
告警详情: {
{ $alert.Annotations.description}}
故障时间: {
{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
恢复时间: {
{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{
{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {
{ $alert.Labels.instance }}
{
{- end }}
{
{- if gt (len $alert.Labels.namespace) 0 }}
命名空间: {
{ $alert.Labels.namespace }}
{
{- end }}
{
{- if gt (len $alert.Labels.node) 0 }}
节点信息: {
{ $alert.Labels.node }}
{
{- end }}
{
{- if gt (len $alert.Labels.pod) 0 }}
实例名称: {
{ $alert.Labels.pod }}
{
{- end }}
===END===
{
{- end }}
{
{- end }}
{
{- end }}
{
{- end }}创建 Alertmanager 服务
alertmanager-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: kube-system
labels:
k8s-app: alertmanager
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
version: v0.14.0
spec:
replicas: 1
selector:
matchLabels:
k8s-app: alertmanager
version: v0.14.0
template:
metadata:
labels:
k8s-app: alertmanager
version: v0.14.0
spec:
priorityClassName: system-cluster-critical
containers:
- name: prometheus-alertmanager
image: "prom/alertmanager:v0.14.0"
imagePullPolicy: "IfNotPresent"
args:
- --config.file=/etc/config/alertmanager.yml
- --storage.path=/data
- --web.external-url=/
ports:
- containerPort: 9093
readinessProbe:
httpGet:
path: /#/status
port: 9093
initialDelaySeconds: 30
timeoutSeconds: 30
volumeMounts:
- name: config-volume
mountPath: /etc/config
- name: storage-volume
mountPath: "/data"
subPath: ""
# 添加模板文件
- name: template
mountPath: /etc/alertmanager/config
resources:
limits:
cpu: 10m
memory: 50Mi
requests:
cpu: 10m
memory: 50Mi
- name: prometheus-alertmanager-configmap-reload
# 修改镜像
image: "jimmidyson/configmap-reload:v0.4.0"
imagePullPolicy: "IfNotPresent"
args:
- --volume-dir=/etc/config
- --webhook-url=http://localhost:9093/-/reload
volumeMounts:
- name: config-volume
mountPath: /etc/config
readOnly: true
# 添加模板文件
- name: template
mountPath: /etc/alertmanager/config
resources:
limits:
cpu: 10m
memory: 10Mi
requests:
cpu: 10m
memory: 10Mi
volumes:
- name: config-volume
configMap:
name: alertmanager-config
# 修改为本地nfs挂载
- name: storage-volume
nfs:
server: xxxxxxxx.cn-hangzhou.nas.aliyuncs.com
path: /uat-pod-log/alertmanager
# 挂载模板文件
- configMap:
name: alter-template-config
name: template
# - name: storage-volume
# persistentVolumeClaim:
# claimName: alertmanager这里与原文件不同的是数据目录挂载改为阿里云NAS、以及增加模板文件挂载
Alertmanager 端口暴露
alertmanager-service.yaml
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "Alertmanager"
spec:
ports:
- name: http
port: 80
protocol: TCP
targetPort: 9093
selector:
k8s-app: alertmanager
type: "ClusterIP"这里可以增加node类型,然后使用ip+端口9093的形式访问web页面
我这里使用的是ingress
配置ingress代理Alertmanager
alertmanager-ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: alertmanager-ingress
namespace: kube-system
annotations:
kubernetes.io/ingress.class: "nginx"
nginx.ingress.kubernetes.io/affinity: "cookie"
nginx.ingress.kubernetes.io/affinity-mode: "persistent"
nginx.ingress.kubernetes.io/session-cookie-name: "route"
spec:
rules:
- host: uatalert.xxx.com
http:
paths:
- backend:
serviceName: alertmanager
servicePort: 9093
path: /
pathType: ImplementationSpecific我这个ingress规则没写SLB的ip地址,因为会自动配置上
绑定hosts后访问 uatalert.xxx.com 出现页面

此时告警插件Alertmanager就安装完成了,下面还需要配置告警以及prometheus连接Alertmanager
prometheus配置告警
prometheus-rules.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-rules
namespace: kube-system
data:
# 通用角色
general.rules: |
groups:
- name: general.rules
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
severity: error
annotations:
summary: "Instance {
{ $labels.instance }} 停止工作"
description: "{
{ $labels.instance }} job {
{ $labels.job }} 已经停止5分钟以上."
# Node对所有资源的监控
node.rules: |
groups:
- name: node.rules
rules:
- alert: NodeFilesystemUsage
expr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 80
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {
{ $labels.instance }} : {
{ $labels.mountpoint }} 分区使用率过高"
description: "{
{ $labels.instance }}: {
{ $labels.mountpoint }} 分区使用大于80% (当前值: {
{ $value }})"
- alert: NodeMemoryUsage
expr: 100 - (node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100 > 80
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {
{ $labels.instance }} 内存使用率过高"
description: "{
{ $labels.instance }}内存使用大于80% (当前值: {
{ $value }})"
- alert: NodeCPUUsage
expr: 100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) * 100) > 60
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {
{ $labels.instance }} CPU使用率过高"
description: "{
{ $labels.instance }}CPU使用大于60% (当前值: {
{ $value }})"
# 对Pod监控
pod.rules: |
groups:
- name: pod.rules
rules:
- alert: PodRestartNumber
expr: floor(delta(kube_pod_container_status_restarts_total{namespace="uat"}[3m]) != 0)
for: 1m
labels:
severity: warning
annotations:
#summary: "pod {
{ $labels.pod }} Pod发生重启"
description: "Pod: {
{ $labels.pod }}发生重启"这里注意一下告警规则是不是匹配你的,其他的都还好,对pod监控这里用的是是否发生重启,且策略里指定了命名空间,需要改成你的或者去掉。
prometheus挂载告警配置以及连接Alertmanager
prometheus-configmap.yaml
# Prometheus configuration format https://prometheus.io/docs/prometheus/latest/configuration/configuration/
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: EnsureExists
data:
prometheus.yml: |
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- localhost:9090
prometheus.yml: |
# 配置采集目标
scrape_configs:
- job_name: kubernetes-nodes
static_configs:
- targets:
# 采集自身
- 172.16.60.9:9100
- 172.16.60.10:9100
- job_name: kubernetes-apiservers
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: default;kubernetes;https
source_labels:
- __meta_kubernetes_namespace
- __meta_kubernetes_service_name
- __meta_kubernetes_endpoint_port_name
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
- job_name: kubernetes-nodes-kubelet
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
- job_name: kubernetes-nodes-cadvisor
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __metrics_path__
replacement: /metrics/cadvisor
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
- job_name: kubernetes-service-endpoints
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scrape
- action: replace
regex: (https?)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scheme
target_label: __scheme__
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_service_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_service_name
target_label: kubernetes_name
- job_name: kubernetes-services
kubernetes_sd_configs:
- role: service
metrics_path: /probe
params:
module:
- http_2xx
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_probe
- source_labels:
- __address__
target_label: __param_target
- replacement: blackbox
target_label: __address__
- source_labels:
- __param_target
target_label: instance
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- source_labels:
- __meta_kubernetes_service_name
target_label: kubernetes_name
- job_name: kubernetes-pods
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_pod_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: kubernetes_pod_name
alerting:
# 告警配置文件
alertmanagers:
# 修改:使用静态绑定
- static_configs:
# 修改:targets、指定地址与端口
- targets:
- alertmanager:80
# 添加指定告警文件
rule_files:
- /etc/config/rules/*.rules
# alerting:
# alertmanagers:
# - kubernetes_sd_configs:
# - role: pod
# tls_config:
# ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
# bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
# relabel_configs:
# - source_labels: [__meta_kubernetes_namespace]
# regex: kube-system
# action: keep
# - source_labels: [__meta_kubernetes_pod_label_k8s_app]
# regex: alertmanager
# action: keep
# - source_labels: [__meta_kubernetes_pod_container_port_number]
# regex:
# action: drop最下方注释处是原来的告警配置,现在改为:
alerting:
# 告警配置文件
alertmanagers:
# 修改:使用静态绑定
- static_configs:
# 修改:targets、指定地址与端口
- targets:
- alertmanager:80指定告警配置文件
# 添加指定告警文件
rule_files:
- /etc/config/rules/*.rules挂载告警文件
prometheus-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: prometheus
namespace: kube-system
labels:
k8s-app: prometheus
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
version: v2.2.1
spec:
serviceName: "prometheus"
replicas: 1
podManagementPolicy: "Parallel"
updateStrategy:
type: "RollingUpdate"
selector:
matchLabels:
k8s-app: prometheus
template:
metadata:
labels:
k8s-app: prometheus
spec:
priorityClassName: system-cluster-critical
serviceAccountName: prometheus
initContainers:
- name: "init-chown-data"
image: "busybox:latest"
imagePullPolicy: "IfNotPresent"
command: ["chown", "-R", "65534:65534", "/data"]
volumeMounts:
- name: prometheus-data
mountPath: /data
subPath: ""
containers:
- name: prometheus-server-configmap-reload
image: "jimmidyson/configmap-reload:v0.1"
imagePullPolicy: "IfNotPresent"
args:
- --volume-dir=/etc/config
- --webhook-url=http://localhost:9090/-/reload
volumeMounts:
- name: config-volume
mountPath: /etc/config
readOnly: true
resources:
limits:
cpu: 10m
memory: 10Mi
requests:
cpu: 10m
memory: 10Mi
- name: prometheus-server
image: "prom/prometheus:v2.24.0"
imagePullPolicy: "IfNotPresent"
args:
- --config.file=/etc/config/prometheus.yml
- --storage.tsdb.path=/data
- --web.console.libraries=/etc/prometheus/console_libraries
- --web.console.templates=/etc/prometheus/consoles
- --web.enable-lifecycle
ports:
- containerPort: 9090
readinessProbe:
httpGet:
path: /-/ready
port: 9090
initialDelaySeconds: 60
timeoutSeconds: 30
livenessProbe:
httpGet:
path: /-/healthy
port: 9090
initialDelaySeconds: 60
timeoutSeconds: 30
# based on 10 running nodes with 30 pods each
resources:
limits:
cpu: 1000m
memory: 1000Mi
requests:
cpu: 200m
memory: 1000Mi
volumeMounts:
- name: config-volume
mountPath: /etc/config
- name: prometheus-data
mountPath: /data
subPath: ""
# 挂载告警文件
- name: prometheus-rules
mountPath: /etc/config/rules
subPath: ""
terminationGracePeriodSeconds: 300
volumes:
- name: config-volume
configMap:
name: prometheus-config
- name: prometheus-data
nfs:
server: xxxxxxxxxxxxx.cn-hangzhou.nas.aliyuncs.com
path: /uat-pod-log/prometheus
# 挂载告警配置文件
- name: prometheus-rules
configMap:
name: prometheus-rules修改的位置是:
# 挂载告警文件
- name: prometheus-rules
mountPath: /etc/config/rules
subPath: ""
# 挂载告警配置文件
- name: prometheus-rules
configMap:
name: prometheus-rules重新加载configmap和prometheus-server后访问ui页面

可以看到告警策略已出现,并且我这里还有个告警,正好可以验证一下发送是否成功

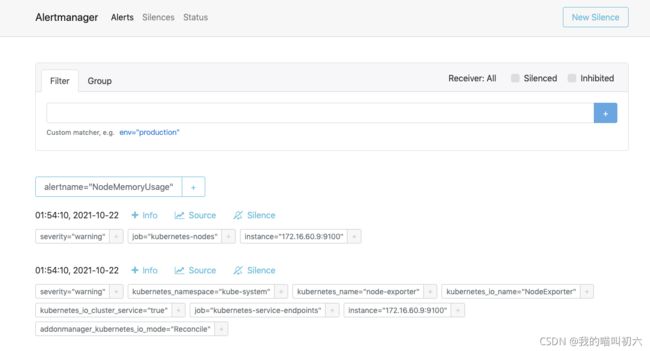
可以看到企业微信上和alertmanager上都有了显示,注意时间+8
静默

可以设置某个告警,让其在那些时间段不发送告警
应用场景就是必须你今天晚上有大规模调整,那那个时间段可以搞成静默,不过也无所谓吧,反正你都知道要发生事情,恢复了看一眼告警是不是都恢复了就完了呗。
我在搭建过程中发现了几个问题
刚开始prometheus使用的是 prom/prometheus:v2.30.0 版本
alertmanager 使用的是 prom/alertmanager:v0.14.0
发现prometheus连接不上alert,报错404
查看日志看到连接的路径里有 v2
外部通过curl确实是报404,然后我curl的时候改成了v1,就可以了
然后升级alert版本后启动又有问题,最后我把prometheus降级到prom/prometheus:v2.24.0就好了
上一篇:资源监控