❤️【Python】精彩解析拉钩网反反爬虫,❤️采集各行业招聘数据,分析行业行情❤️
目录
前言
开始
分析(x0)
分析(x1)
分析(x2)
分析(x3)
分析(x4)
代码
效果
我有话说
前言
emmmmmm, 大家好我叫善念。基本是每天更新一篇Python爬虫实战的文章,不过反响好像也不怎么好,都是几百阅读吧,我自认为我每篇文章都讲解的非常仔细,大家感兴趣可以去考评一下:
【Python】绕过反爬,开发音乐爬虫,实现完美采集
【Python】纯干货,5000字的博文教你采集整站小说(附源码)
【Python】绕过X音_signature签名,完美采集整站视频、个人视频
好与坏都能接受,精进是咱一直在做的事情
开始
目标网址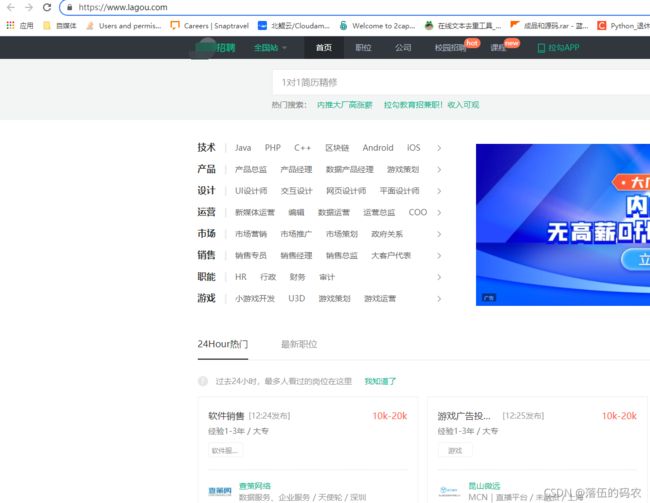
搜下Python相关的工作
好了,这个页面就是咱们想要采集的一些数据。
分析(x0)
这次直接点,查看网页源代码,搜一下我们需要采集的内容,看下源代码中是否有咱们需要的数据:
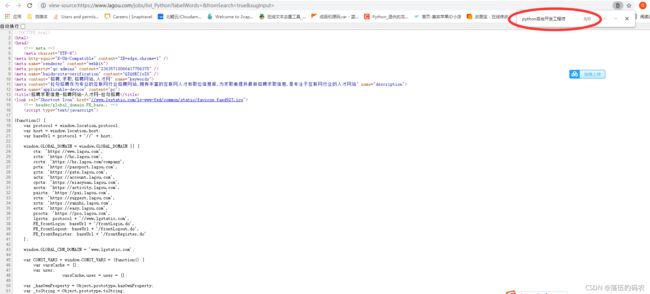
显示的结果为0,也就是说数据不在咱们的网页源代码中。
但是它是在咱们的element网页元素中的,这就是我反复强调的:网页源代码才是服务器传给浏览器的原始数据,而网页元素是网页源代码通过浏览器渲染后的数据(可能浏览器会执行某些源代码中的JavaScript脚本而实现的效果)
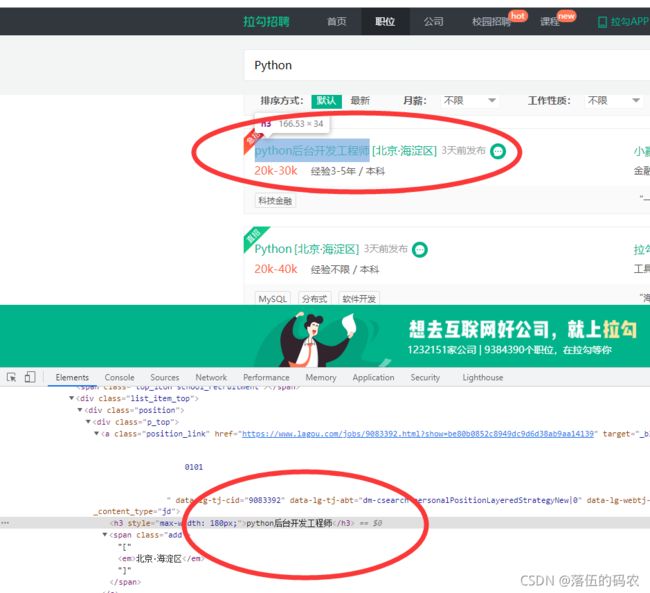
分析(x1)
既然网页源代码中没有,元素中有,那么我们可以用selenium去进行一个数据采集,因为selenium采集的数据就是元素中的数据,但是缺点就是采集的速度慢。
不想速度慢,就继续去分析,咱们抓一下包看看是不是浏览器执行了网页源码中的JavaScript脚本从而调用了某个接口api生成了咱们需要的数据。刷新当前页面抓包:

嘿嘿,可以看到出现了禁止调试阿,开发人员写了个JavaScript语句防止咱们调试怎么办?
点一下向右的箭头,打开无视断点,然后再点一下运行即可。
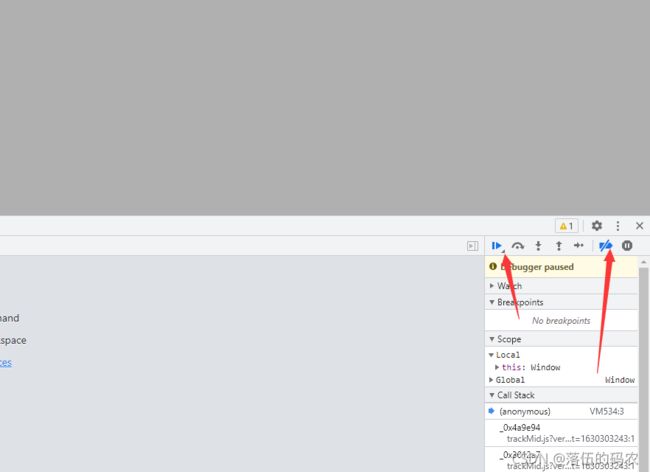
emmmmm看下抓到的数据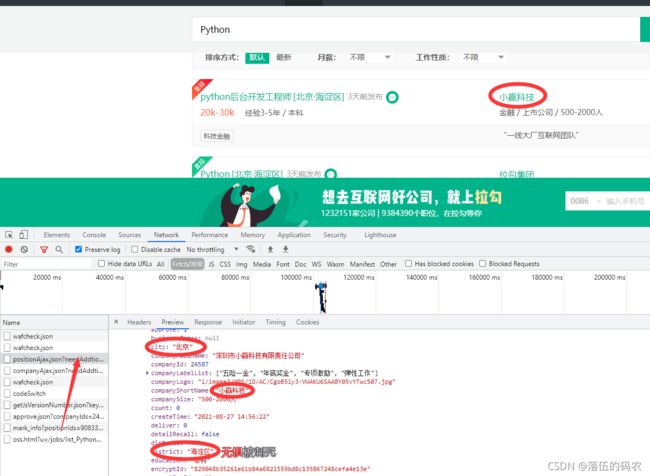
已经确认就是这个包了,然后咱们分析下这个请求
post请求,然后有这么三个参数:

first不知道什么意思,pn为1(这是第一页)kd为Python(搜的关键词为Python)。
说明说明?只要我们请求这个链接就可以得到想要的数据咯!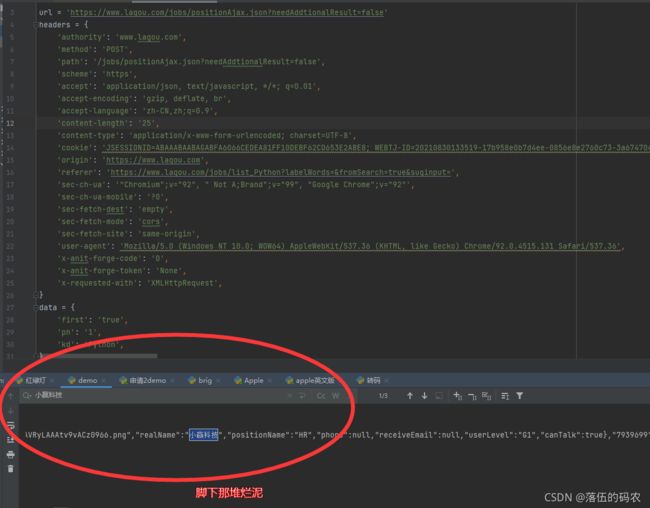
这里千万注意,服务器会检测cookies, 也就是咱们请求头中一定要携带cookies!自己去测试一下即可。
分析(x2)
那么第一页咱们就愉快的采集下来了,用提取规则提取出想要的数据即可。
那么分析X1里面的一个点再重复讲一下,服务器会检测cookies, 也就是咱们请求头中一定要携带cookies!
而cookies有时效性(比如你登录了某某网站,那么短时间内无需重新登录,而十天半个月后可能就需要你重新登录了,就是这么个道理)
那么说明:我们在采集数据之前,首先去自动获取网页的cookies,然后再用这个cookies去采集数据。这样就可以实现一个全自动化,而非手动去复制cookies
那么思路就清晰了:先白用户(不携带cookies),requests访问网站首页得到服务器返回的cookies,然后用这个cookies去post接口得到咱们需要的数据
到此为止,咱们也只是采集到了第一页的数据,而如果咱们需要采集所有的数据呢?
咱们继续分析,如果要采集所有的页码上数据,我经常跟你们讲的思路:先看看翻页后咱们网站的变化,很明显在这里咱们行不通了,因为数据是接口api生成的。所以呢,我们转换下思路,翻页后抓到第二页的api看看与第一页api的不同之处。
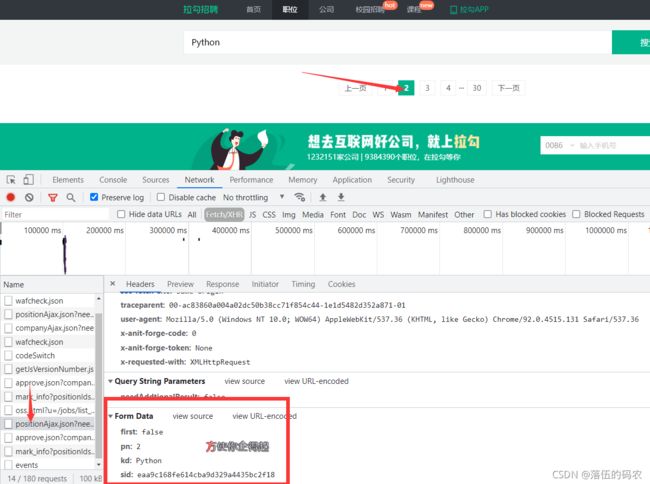
看得到,几个变化的点,和不变化的点,首先post的地址是没变的,而参数变了。
first变为了false,pn为页码变成了2,关键词还是Python不变,新增了sid参数。
分析(x3)
看下第三页,是不是first还是FALSE,sid值也不变,如果不变就好办了(也就是说第一页与后面页码的参数不同而已),如果一直无限变化,咱们就需要找找变化的规律了。

看了第三页的包,我知道事情好办了。
规律总结:参数frist第一页为ture,其它页全为FALSE,pn随页码变化,kd为自己搜索的关键词,sid第一页为空,后面的页码为固定值(这里我要跟大家解释一下,其实你第一页把这个sid参数传入进去,一样是可以访问的。别问为什么,这个是作为一个高级爬虫师的一个直觉)。
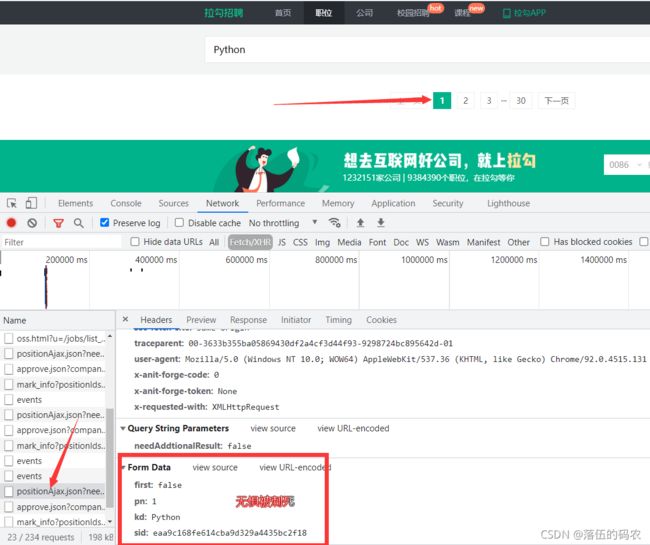
当我们翻到第一页,果然真的是携带sid的.......而且first变为了FALSE,这就很神奇了。
神奇的点在哪?咱们前面抓首页的包的时候,可以看到first为TRUE,sid是没有这个参数的,那么也就是说是访问了第一页后生成了sid这个参数,然后把sid传入到第二个页码接口的参数当中的。
如果说咱们如果直接把所有页码接口的参数都写成四个,first都没TRUE,sid为固定死,可行吗?
不可行,除非你手动抓包去复制sid,因为sid是访问了第一页的数据后生成的......
如果理解不了多看看神奇的点在哪这一段话。
总结一下咱们现在需要做的事情就是去搞清楚sid这个值从何而来。
分析(x4)
直接ctrl+f搜一下即可,可以知道sid果然是第一页的post后得到数据。
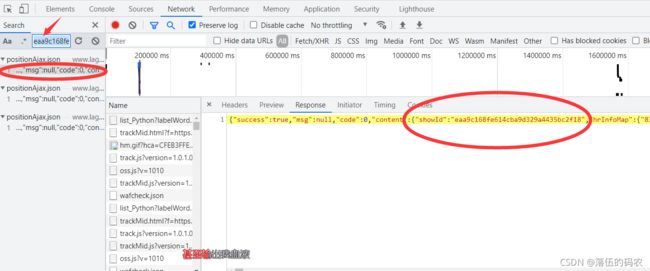
那么总思路就是,先访问首页获取cookies,然后post第一页得到sid。而第一页的参数first为TRUE,sid为空,后面的页码first为FALSE,sid为第一页post后得到的值。
......我刚手动翻页的时候
醉了,网站改版了,未登录用户操作次数过多会直接让你去登录......也就是说cookies只能去手动登录后去复制了,因为这个登录也有那个特殊的验证码,没法去过。找打码台子也不划算.....
没办法,委屈各位手动cookies了。
代码
import requests
import time
import sys
cookies = '手动copy'
url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
headers = {
'authority': 'www.lagou.com',
'method': 'POST',
'path': '/jobs/positionAjax.json?needAddtionalResult=false',
'scheme': 'https',
'accept': 'application/json, text/javascript, */*; q=0.01',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'content-length': '63',
'content-type': 'application/x-www-form-urlencoded; charset=UTF-8',
'cookie': cookies,
'origin': 'https://www.lagou.com',
'referer': 'https://www.lagou.com/jobs/list_Python?labelWords=&fromSearch=true&suginput=',
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
# 'traceparent': '00-2a566c511e611ee8d3273a683ca165f1-0c07ea0cee3e19f8-01',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36',
'x-anit-forge-code': '0',
'x-anit-forge-token': 'None',
'x-requested-with': 'XMLHttpRequest',
}
sid = ""
def get_data(flag, page, sid):
data = {
'first': flag,
'pn': page,
'kd': 'python',
'sid': sid
}
return data
for page in range(1, sys.maxsize):
time.sleep(5)
if page == 1:
flag = True
else:
flag = False
response = requests.post(url=url, headers=headers, data=get_data(flag, page, sid))
sid = response.json()["content"]['showId']
text = response.json()['content']['positionResult']['result']
print(text)
with open("result.csv", "a", encoding='utf-8') as file:
for cp in text:
cp_msg = f"{cp['city']},{cp['companyFullName']},{cp['companySize']},{cp['education']},{cp['positionName']},{cp['salary']},{cp['workYear']}\n"
file.write(cp_msg)
print(f"第{page}页爬取完成")
print("爬取完成")
效果

我有话说
—— 有一些人,
他们赤脚在你生命中走过,
眉眼带笑,不短暂,也不漫长 .
却足以让你体会幸福,
领略痛楚,回忆一生 .

文章的话是现写的,每篇文章我都会说的很细致,所以花费的时间比较久,一般都是两个小时以上。
原创不易,再次谢谢大家的支持。
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
在我主页左下角的联系模块中,联系我。或者私信我。
