java8 Stream API详解
目录
一、Stream流概述
二、创建Stream的方式
相关API
三、Stream的中间操作
筛选与切片
映射
排序
四、终止操作
第一大类API(太过简单)
第二大类AP
归约
收集
一、Stream流概述
1、java8中有两大最为重要的改变,第一就是Lambda表达式,另一个则是Stream API。
2、Stream API真正把函数式编程风格引入到Java中。这是目前为止,java类库中最好的补充,因为Stream API可以极大地提高java程序员的生产力,让程序员写出高效率、干净、简洁的代码。
3、Stream是java8中处理集合的关键抽象概念,它可以指定你希望对集合进行的操作,可以执行非常复杂的查找、过滤、和映射数据库等操作。使用Stream API对集合进行的操作是在java层面进行的,就类似于使用SQL执行的数据库查询操作,也可以使用Stream进行并行操作。
4、为什么要学习Stream API?
实际开发中,项目中很多数据源都是来源于Mysql、Oracle等关系型数据库,但对于MongDB、Redis等非关系型数据库查询出来的数据就需要在java层面进行处理。
5、Stream和Collection集合的区别:
集合的增删改查操作是在数据结构(内存)层面进行的,数据源会随之发生改变;
Stream操作是在数据(CPU)层面进行的,数据源不会随之发生改变。
6、图解Stream

7、使用Stream的步骤:
(1)产生一个流(Stream),
一个数据源,获取一个流;
(2)中间链式(流水线式)操作,
一个中间的操作链,对数据源的数据进行处理;
(3)产生一个新流,
一个终止操作,执行中间操作链,产生结果。
注意:Stream操作是延迟执行的,他们会等到需要结果时才会执行。
二、创建Stream的方式
-
相关API

- 具体事例
public static void main(String[] args) { //1.Collection中的方法 Collectioncollection = new ArrayList<>(); Stream stream = collection.stream(); Stream stream1 = collection.parallelStream(); //2.Arrays中的stream方法(静态方法,可直接调用) IntStream stream2 = Arrays.stream(new int[]{1, 2, 3}); //3.Stream中的of方法(静态方法,可直接调用) Stream stream3 = Stream.of("as", "cx1", "323"); //4.Stream中的方法-创作无限流(结果有无限多个) /** * 4.1 iterate : 这里的例子可理解为,从2开始,每隔2产生一个数据,总共产生无穷多个 * iterate的第二个参数是UnaryOperator,它是一个接口,继承内置函数型接口Function * public interface UnaryOperator extends Function stream4 = Stream.iterate(2, x -> x + 2); stream4.forEach(System.out::println); /** * 4.2 generate: * public static Stream generate(Supplier s) * 参数是内置供给型接口Supplier * 此处使用Lambda表达式以及方法引用 */ Stream stream5 = Stream.generate(() -> Math.random()); stream5.forEach(System.out::println); }
三、Stream的中间操作
筛选与切片
- filter
- Stream
filter(Predicate predicate); - 接收Lambda,从中排除某些元素,参数是内置断定型接口Predicate,
- 需要特别注意的是:Stream操作的“延迟加载”或叫“惰性加载”:只有执行终止操作,中间操作才会被执行。例子中进行了验证。
public class FilterTest { private static ListstuList; static { stuList = Arrays.asList( new Student(1, "zhangsan1", 12, 171.1, 3001D), new Student(2, "zhangsan1", 14, 172.1, 4001D), new Student(3, "zhangsan1", 16, 173.1, 5001D), new Student(4, "zhangsan1", 18, 174.1, 6001D), new Student(5, "zhangsan1", 20, 175.1, 7001D), new Student(6, "zhangsan1", 21, 176.1, 8001D), new Student(7, "zhangsan1", 22, 177.1, 9001D) ); }; @Test public void test01(){ //1.创建Stream流 Stream s1 = stuList.stream(); //2.中间操作,找年龄大于18岁的学生 Stream studentStream = s1.filter(x -> x.getAge() >= 18); //3.终止操作 studentStream.forEach(x-> System.out.println(x.getAge())); } /** * 注意如果只执行1、2,不执行终止操作,则不会输出任何结果 * 证明Stream操作的“延迟加载”或叫“惰性加载”:只有执行终止操作,中间操作才会被执行 */ @Test public void test02(){ //1.创建Stream流 Stream s1 = stuList.stream(); //2.中间操作,找年龄大于18岁的学生 Stream studentStream = s1.filter(x -> { System.out.println("正在执行过滤......."); return x.getAge() >= 18; } ); //3.终止操作 //studentStream.forEach(x-> System.out.println(x.getAge())); } /** * 链式操作 */ @Test public void test03(){ stuList.stream() .filter(x -> x.getAge() >= 18) .forEach(x-> System.out.println(x.getAge())); } }
- limit
- Stream
limit(long maxSize) - 截断流,使其长度不能超过给定数量。方法短路,效率高。
@Test public void test04(){ stuList.stream() .limit(3) .forEach(System.out::println); }
- skip
- Stream
skip(long n) - 跳过元素,返回扔掉了前n个元素的流,如果流中元素不足n,则返回一个空流。
@Test public void test04(){ stuList.stream() .skip(3) .forEach(x->System.out.println(x.getName())); }
- distinct
- Stream
distinct() - 筛选,根据流所生成元素的hashCode和equals方法去掉重复元素。所以如果使用的是引用类型,需要重写hashCode和equals。
- 方法重写
@Override public boolean equals(Object o) { if (this == o) return true; if (!(o instanceof Student)) return false; Student student = (Student) o; return Objects.equals(getId(), student.getId()) && Objects.equals(getName(), student.getName()) && Objects.equals(getAge(), student.getAge()) && Objects.equals(getHeight(), student.getHeight()) && Objects.equals(getSalary(), student.getSalary()); } @Override public int hashCode() { return Objects.hash(getId(), getName(), getAge(), getHeight(), getSalary()); }
- 具体事例
static { stuList = Arrays.asList( new Student(1, "zhangsan1", 12, 171.1, 3001D), new Student(1, "zhangsan1", 12, 171.1, 3001D), new Student(3, "zhangsan3", 16, 173.1, 5001D), new Student(4, "zhangsan4", 18, 174.1, 6001D), new Student(5, "zhangsan1", 20, 175.1, 7001D), new Student(6, "zhangsan6", 21, 176.1, 8001D), new Student(7, "zhangsan7", 22, 177.1, 9001D) ); } @Test public void test04(){ stuList.stream() .distinct() .forEach(System.out::println); }
映射
map:接收Lambda,将元素转换成其他形式或提取信息。接收一个参数,该参数会被应用到每个元素上,并将其映射成一个新的元素。
可以通俗的理解成数学中的函数,输入x,将x映射成相应的y,并返回覆盖原来的x,从而形成新的元素。
- 案例1:将字符串中的小写变大写
- 案例2:只获取学生姓名
- 案例3:获取年龄大于18岁的学生的名字
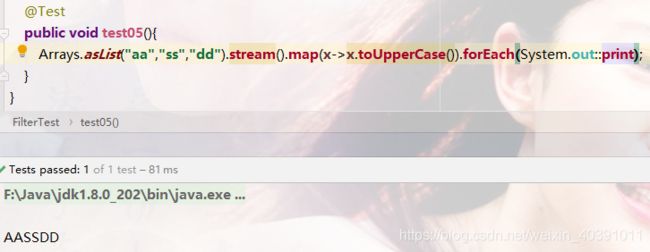


排序

- sorted
自然排序:底层根据内部比较器进行排序——>Conparable接口——>comparaTo方法

- 指定sorted排序策略
指定排序策略:底层根据外部比较器进行比较排序——>Comparator接口——>一定要自己重写compare方法来指定比较规则。

四、终止操作
第一大类API(太过简单)

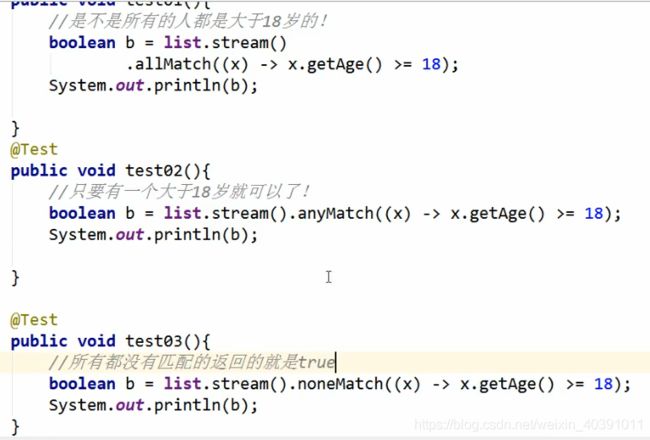
第二大类AP
用法大同小异,都不难。
但,需要注意的是,一部分先查找后返回的API,采用的是Optional进行接收。因为查找的结果有可能是空集合。

具体实例:

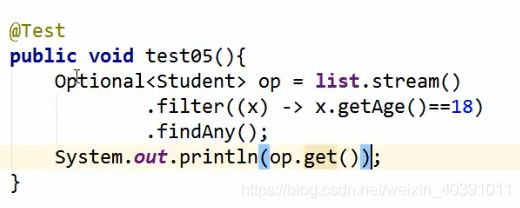

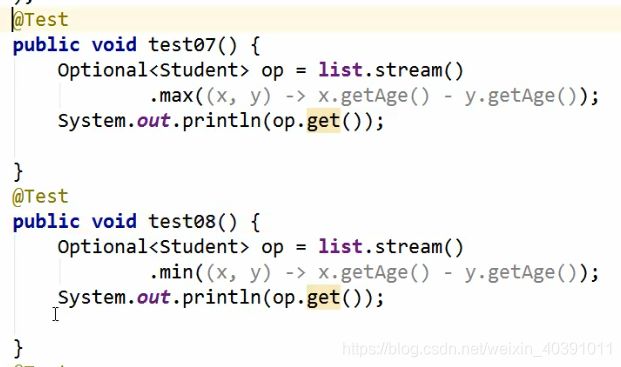

归约
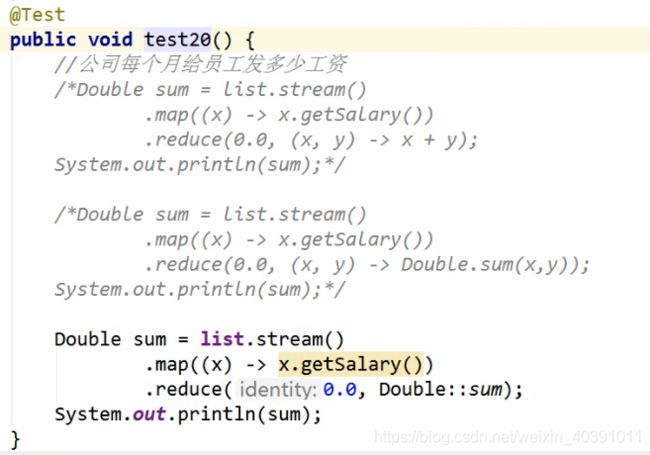
终止操作中稍微有点难理解的的就是归约。
- 归约:将流中的元素反复结合起来就行运算,得到一个值。
T reduce(T identity,BinaryOption
accumulator)
- 归约分析
- 实例

收集
- 收集:用于给Stream中的元素进行汇总。
方法形参:Collector接口
方法实参:应是Collector接口的实例;如何获取:有一个Collector类,里面提供了各种方法,返回给我们Collector接口实例。
- 收集的应用场景
(1)将代码放入指定的集合
- Collectors.toList()
- Collectors.toSet()
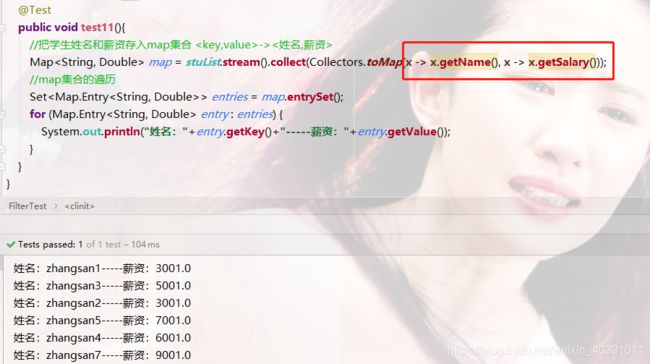
- Collectors.toMap()
由于Map集合结构的特殊性,这里需要注意 ,与以上两个不同的是,需要指定存储的key和value.


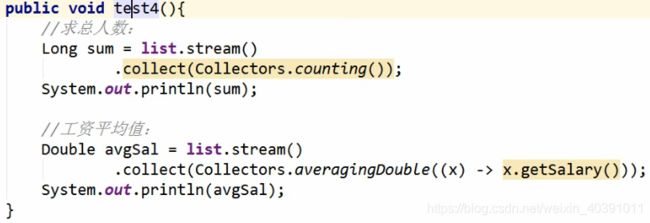
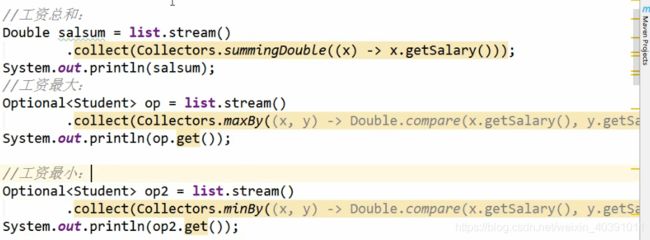
(2)总数,平均值,总和,最大值,最小值(太过简单,不做过多描述)
(3)分组(简单)
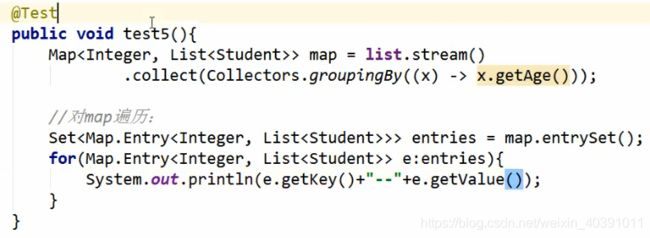
(4)分区:满足条件的在一个分区,不满足条件的在另一个分区(注意:总共只划分出两个分区)
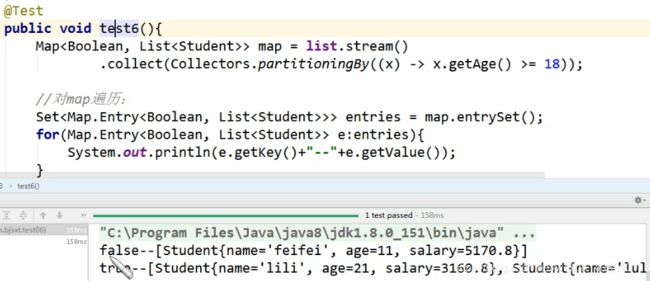
(5)连接:其实就是字符串拼接
