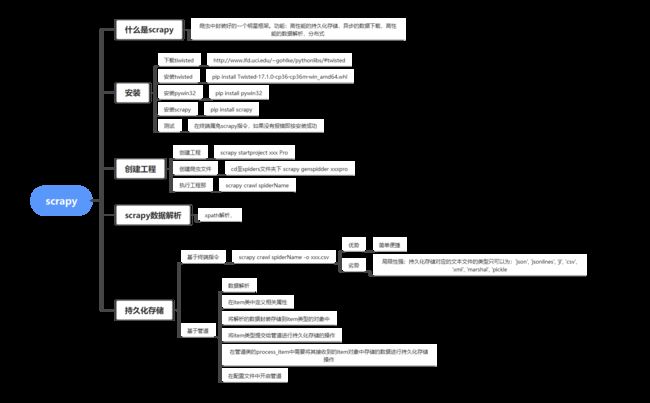
scrapy是一个爬虫中封装好的一个明星框架。具有高性能的持久化存储,异步的数据下载,高性能的数据解析,分布式。
对于初学者来说还是需要有一定的基础作为铺垫的学习。我将从下方的思维导图中进行逐步的解析讲述。
实验工具即环境:
笔记本:Y9000X 2020
系统:win10
Python版本:python3.8.6
pycharm版本:pycharm 2021.1.2(Professional Edition)
一、安装
下载tiwisted,此处位下载地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
下载好后打开终端进行安装scrapy的必要模块
安装tiwisted,pip install tiwisted-xxxx
安装pywin32:pip install pywin32
安装scrapy:pip install scrapy
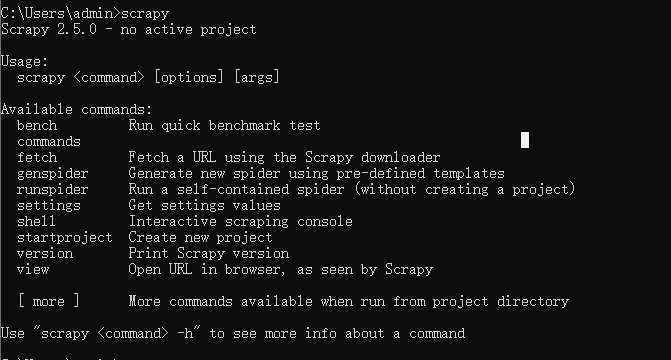
安装完成后在终端输入scrapy如果没有报错即安装成功。
二、创建scrapy的工程
在pycharm中创建好的项目中的中终端输入
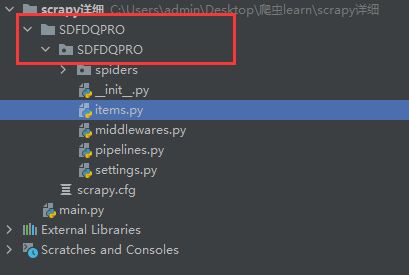
scrapy startproject SDFDQPRO

检查下项目目录即可发现多出了如下的工程目录
三、创建一个爬虫目录
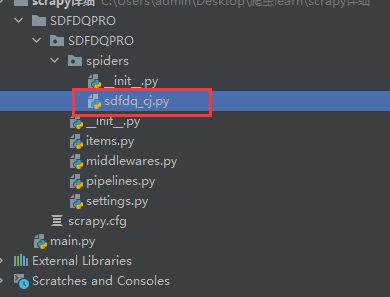
在终端找到之前所创建的工程目录,在此目录下输入scrapy genspider sdfdq_cj http://www.csrc.gov.cn/pub/shandong/
后方网站为中国证券监督管理委员会山东监管局。

运行后可发现工程目录中多出一个名为sdfdq_cj.py的爬虫文件。
进入到爬虫文件中可以看到如下代码
import scrapy class SdfdqCjSpider(scrapy.Spider): name = 'sdfdq_cj' # 表示被允许的url # allowed_domains = ['http://www.csrc.gov.cn/pub/shandong/'] # 起始url列表:该列表中存放的url会被scrapy自动进行请求的发送 start_urls = ['http://www.csrc.gov.cn/pub/shandong/sdfdqyxx/'] # 用作于数据解析:response参数表示的就是请求成功后对应的响应对象 def parse(self, response): pass
接下来对网站解析选取需要获取的内容
四、数据解析
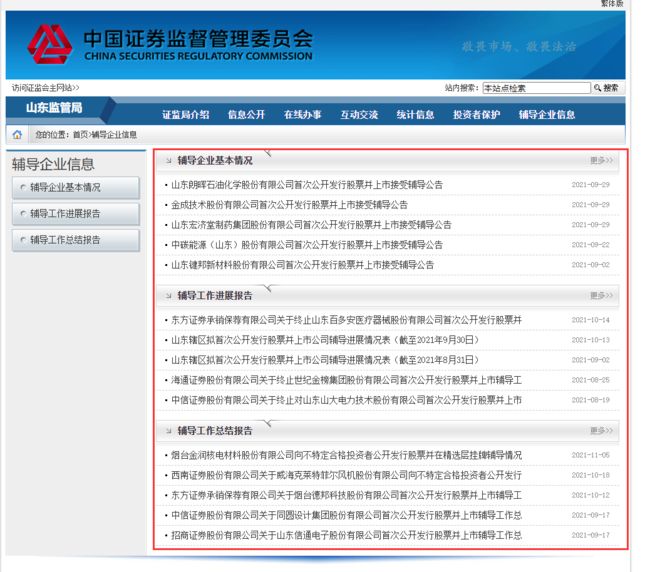
通过对网站的查看可以看出我们需要的是辅导期中的企业基本情况、工作进展报告、工作总结总的标题,日期以及链接。
scrapy对网站的解析沿用了xpath的解析方式。
import scrapy class SdfdqCjSpider(scrapy.Spider): name = 'sdfdq_cj' # 表示被允许的url # allowed_domains = ['http://www.csrc.gov.cn/pub/shandong/'] # 起始url列表:该列表中存放的url会被scrapy自动进行请求的发送 start_urls = ['http://www.csrc.gov.cn/pub/shandong/sdfdqyxx/'] # 用作于数据解析:response参数表示的就是请求成功后对应的响应对象 def parse(self, response): li_list = response.xpath('//div[@class="zi_er_right"]//div[@class="fl_list"]//li') for li in li_list: # xpath返回的是列表,但是列元素一定是Selector类型的对象 # extract可以将Selector对象中的data参数存储的字符串提取出来 # 列表调用了extract之后则表示将列表中每一个data参数存储的字符串提取出来 title = li.xpath('./a//text()')[0].extract() date = li.xpath('./span/text()')[0].extract() url = 'http://www.csrc.gov.cn/pub/shandong/sdfdqyxx'+li.xpath('./a/@href').extract_first() print('title',title) print('url',url) print('date',date)
对网站的内容解析后运行scrapy 终端输入 scrapy crawl sdfdq_cj 注意:此语句的运行目录
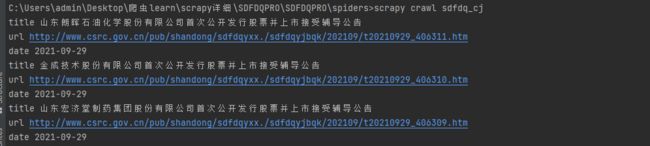
可以看到我们想获取的内容:
内容获取到我们必须要将其持久化存储才有意义:
五、scrapy的持久化存储
1)基于指令的持久化存储:
要求:只可以将parse的方法返回值存储到本地的文本文件中
def parse(self, response): # 创建一个列表接收获取的数据 all_data = [] li_list = response.xpath('//div[@class="zi_er_right"]//div[@class="fl_list"]//li') for li in li_list: # xpath返回的是列表,但是列元素一定是Selector类型的对象 # extract可以将Selector对象中的data参数存储的字符串提取出来 # 列表调用了extract之后则表示将列表中每一个data参数存储的字符串提取出来 title = li.xpath('./a//text()')[0].extract() date = li.xpath('./span/text()')[0].extract() url = 'http://www.csrc.gov.cn/pub/shandong/sdfdqyxx'+li.xpath('./a/@href').extract_first() # 基于终端指令的持久化存储操作 dic = { 'title':title, 'url':url, 'date':date } all_data.append(dic) return all_data
接下来在终端中输入 scrapy crawl sdfdq_cj -o ./sdfdq.csv
将获取的文本内容存储到对应路径下的sdfdq.csv文本文件中

2)基于管道的持久化存储
明天更。。。。。。。。。