超级详细scrapy爬虫教程;微博关键词爬虫;整个爬虫的编写与思路;最终爬取“EDG”有关微博生产词云。
微博关键词爬虫;超详细爬虫教程;整个爬虫编写流程和思路;Xpath表达式编写;数据存储和处理
我们大家都知道一般来说,要爬取微博的相关信息,还是weibo.cn这个站点要好爬取一些。但是这个站点却没有关键词检索,所以我们不能根据自己想搜索的关键词去爬取自己想要的内容。不过博主发现,微博有一个站点:“s.weibo.com”。这是一个专门根据关键词来检索相关微博的站点,下面我就该站点,利用scrapy爬取相关微博内容来为大家详细讲解其中的过程。
可以爬取的字段
首先展示可以爬取那些字段:

有了数据要怎么分析就是大家自己的事情了。下面我们详细介绍怎么去爬取这些数据。
一,网页分析
首先我们进入s.weibo.com,输入自己想要搜索的内容,如何按F12,观察网页格式。


要提取网页中自己想要的内容,我们选择用xpath去获取,scrapy中也有.xpath()的方法,方便我们爬虫的编写。这里教大家一个小技巧,我们选中自己想要标签后可以右键,如何选择copy xpath,就可以复制该标签的xpath表达式,如何我们按住Ctrl+F,将复制的表达式放入搜索框,然后我们就可以直接在后面修改表达式,就可以提取该标签或者和该标签同级的标签下相应的内容了。这一步非常重要,可以提高我们后面编写代码的编写效率。
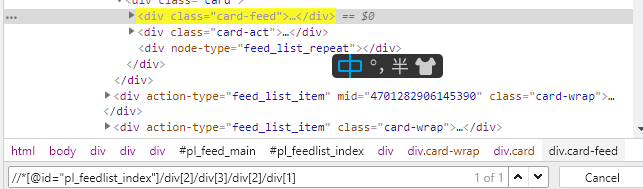
比如我们在这里复制了该页面第一条内容的xpath表达式,然后我修改表达式提取到同类标签。
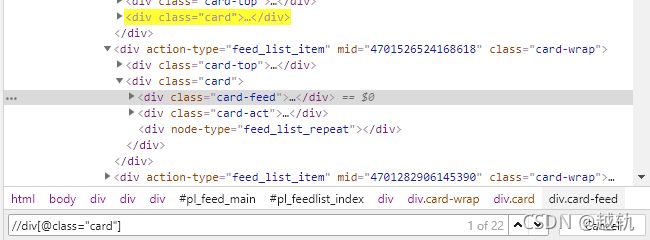
可以看见,该类标签有22个,我数了一下,该页面下刚好有22条微博,那么接下来,我们只需要在这个xpath表达式后面增加内容就可以进一步提取自己想要的字段了。下面我们以微博的文本内容为例。
首先我们先选择中微博的文本内容:

然后查看标签

此时我们只需要把p标签的文本提取出来就行,首先我们要定位p标签,在刚才的xpath表达式后面加上:“//p[@node-type=“feed_list_content””,这样我们就选中了了该页面下所有微博的文本内容了。其他的字段也是同样的道理,我们把所有字段的xpath表达式弄出来,在后面爬虫的时候再来具体处理。

二,爬虫部分
爬虫部分我们,采取scrapy框架编写,对于这个框架的安装和怎么创建一个项目我就不详细介绍了,大家可以自行查找资料。
在创建好项目,生产spider后,我们首先编写item.py,把我们要爬取的字段,先在item中定义好。
from scrapy import Item, Field
class KeywordItem(Item):
"""
关键词微博
"""
keyword = Field()
weibo_url = Field()
content = Field()
weibo_id = Field()
crawl_time = Field()
created_at = Field()
tool = Field()
repost_num = Field()
comment_num = Field()
like_num = Field()
user_url = Field()
user_id = Field()
然后编写pipeline.py,对爬虫进行本地数据库存储。
import pymongo
from pymongo.errors import DuplicateKeyError
from settings import MONGO_HOST, MONGO_PORT
class MongoDBPipeline(object):
def __init__(self):
client = pymongo.MongoClient(MONGO_HOST, MONGO_PORT)
db = client['edg']
self.Keyword = db["Keyword"]
def process_item(self, item, spider):
self.insert_item(self.Keyword, item)
@staticmethod
def insert_item(collection, item):
try:
collection.insert(dict(item))
except DuplicateKeyError:
pass
首先是初始化函数,定义好数据库的端口、名称和表的名称;然后process_item函数把item字段都插入到表Keyword中去,item是scrapy的一大特点,它类似于字典这一数据结构,爬虫部分将爬取到的数据存在item中然后提交给管道,进行存储。
然后我们开始写爬虫部分,在spider文件夹下面创建keyword.py,在start_requests中先定义好要爬取的网页和headers等。
def start_requests(self):
headers = {
'Host': 's.weibo.com',
'Cookie': ''
}
keywords = ['edg']
url = 'https://s.weibo.com/weibo?q={}&Refer=index&page=1'
那么我们要爬取数据肯定就不能只是爬取一页的数据,根据观察网站的URL我们可以发现有一个page参数,我们只需要构造该参数的值就可以实现生成不同页面的URL,我把他放在一个URL列表中,循环访问就可以了。
urls = []
for keyword in keywords:
urls.append(url.format(keyword))
for url in urls:
yield Request(url, callback=self.parse,headers=headers)
然后我们来写爬虫处理函数parse。
def parse(self, response):
if response.url.endswith('page=1'):
page = 50
for page_num in range(2, page+1):
page_url = response.url.replace('page=1', 'page={}'.format(page_num))
yield Request(page_url, self.parse, dont_filter=True, meta=response.meta)
if response.status == 200:
html_result = response.text
data = etree.HTML(html_result)
nodes = data.xpath('//div[@class="card"]')
首先是要判断URL最后的page参数是不是为1,如果是,那么我们将page复制为50(因为该网站最多显示50页的微博内容),然后用format方法构造50个URL,每个都递交给parse方法去处理。
如果访问成功,就提取去所有的“//div[@class=“card”]”赋值给nodes,这是我们上面网页分析是提取的所有的包含微博内容的xpath表达式。然后就在nodes循环提取所有的文本内容。
for node in nodes:
try:
content = node.xpath('.//p[@node-type="feed_list_content"]')
keyword_item['content']=extract_weibo_content(content[0].xpath('string(.)').strip())
yield keyword_item
except Exception as e:
self.logger.error(e)
这里我们只以提取微博文本内容为例
只需要将刚才在“//div[@class=“card”]”后面增加的提取的微博文本内容的xpath表达式,提取到content中,处理后在放入keyword_item(刚才说了它是类似于字典结构,用法跟字典都是一样的)中。怎么处理才能将所有的文本都提取出来呢,这个就需要大家不断的尝试,像我也是尝试很多次才知道是使用.xpath(‘string(.)’)。最后不要忘记提交给item哦。
extract_weibo_content()是一个处理提取文本中多余的表情,符号和网址的函数。代码如下:
def extract_weibo_content(weibo_html):
s = weibo_html
if 'class="ctt">' in s:
s = s.split('class="ctt">', maxsplit=1)[1]
s = emoji_re.sub('', s)
s = url_re.sub('', s)
s = div_re.sub('', s)
s = image_re.sub('', s)
if '' in s:
s = s.split('')[0]
splits = s.split('赞[')
if len(splits) == 2:
s = splits[0]
if len(splits) == 3:
origin_text = splits[0]
retweet_text = splits[1].split('转发理由:')[1]
s = origin_text + '转发理由:' + retweet_text
s = white_space_re.sub(' ', s)
s = keyword_re.sub('', s)
s = s.replace('\xa0', '')
s = s.strip(':')
s = s.strip()
return s
三,数据爬取与处理
然后我们就可以开始运行爬虫了。
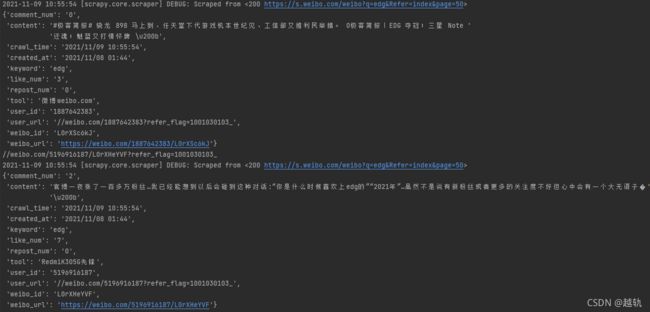
可以看见爬虫运行是没有问题的,我是使用一个ip和单个账号进行爬取的,经过测试,速度大概是一个小时能爬一万条。
最后在monogodb中查看我们爬取的数据,同时我还爬取了微博的评论

这里数据量有点少,主要是因为我爬了一会就停了,大家想要多爬些的,可以自己试试。
有了数据,想要怎么分析,就是后面的事情了,起码做饭我们是有米了。这里生产了微博和评论的词云


本人也是爬虫爱好者,希望写这篇文章能帮助到一些刚入门的人,欢迎大家一起交流和各位大佬批评指正。