使用 Rook 快速搭建 Ceph 集群
Rook、Ceph简介
Rook
Rook是一个开源的云原生存储编排工具,提供平台、框架和对各种存储解决方案的支持,以和云原生环境进行本地集成。
Rook 将存储软件转变成自我管理、自我扩展和自我修复的存储服务,通过自动化部署、启动、配置、供应、扩展、升级、迁移、灾难恢复、监控和资源管理来实现。Rook 底层使用云原生容器管理、调度和编排平台提供的能力来提供这些功能。
Rook 利用扩展功能将其深度地集成到云原生环境中,并为调度、生命周期管理、资源管理、安全性、监控等提供了无缝的体验。有关 Rook 当前支持的存储解决方案的状态相关的更多详细信息,可以参考 Rook 仓库 的项目介绍。Rook 目前支持Ceph、NFS、Minio Object Store和CockroachDB。

Ceph分布式存储系统
Ceph是一种高度可扩展的分布式存储解决方案,提供对象、文件和块存储。在每个存储节点上,您将找到Ceph存储对象的文件系统和Ceph OSD(对象存储守护程序)进程。在Ceph集群上,您还可以找到Ceph MON(监控)守护程序,它们确保Ceph集群保持高可用性。
环境说明:
1. Kubernetes: v1.16.2
2.Docker:18.09.9
3.Rook:release-1.1
4.在集群中至少有三个节点可用,满足ceph高可用要求,并且服务器具备一块未格式化未分区的硬盘。
部署 Rook Operator
这里部署 release-1.1 版本的 Rook,点击查看部署使用的 部署清单文件。
从上面链接中下载 common.yaml 与 operator.yaml 两个资源清单文件
$ kubectl apply -f common.yaml
$ kubectl apply -f operator.yaml在继续操作之前,验证 rook-ceph-operator 是否处于“Running”状态
$ kubectl get pod -n rook-ceph创建 Rook Ceph 集群
现在 Rook Operator 处于 Running 状态,接下来我们就可以创建 Ceph 集群了。为了使集群在重启后不受影响,请确保设置的 dataDirHostPath 属性值为有效得主机路径。更多相关设置,可以查看集群配置相关文档。
创建如下的资源清单文件:(cluster.yaml)
apiVersion: ceph.rook.io/v1
kind: CephCluster
metadata:
name: rook-ceph
namespace: rook-ceph
spec:
cephVersion:
# 最新得 ceph 镜像, 可以查看 https://hub.docker.com/r/ceph/ceph/tags
image: ceph/ceph:v14.2.4-20190917
dataDirHostPath: /data/rook # 主机有效目录
mon:
count: 3
dashboard:
enabled: true
storage:
useAllNodes: true
useAllDevices: false
# 重要: Directories 应该只在预生产环境中使用
directories:
- path: /var/lib/rook然后直接创建即可
$ kubectl apply -f cluster.yaml我们可以通过 kubectl 来查看 rook-ceph 命名空间下面的 Pod 状态,出现类似于如下的情况,证明已经全部运行了
$ kubectl get pods -n rook-ceph
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-cp5mc 3/3 Running 0 24m
csi-cephfsplugin-fs9s5 3/3 Running 0 24m
csi-cephfsplugin-provisioner-75c965db4f-b5wf4 4/4 Running 0 24m
csi-cephfsplugin-provisioner-75c965db4f-zkrth 4/4 Running 0 24m
csi-cephfsplugin-qvfpb 3/3 Running 0 24m
csi-cephfsplugin-vgzl6 3/3 Running 0 24m
csi-rbdplugin-cj842 3/3 Running 0 24m
csi-rbdplugin-ksc24 3/3 Running 0 24m
csi-rbdplugin-provisioner-56cbc4d585-5dkzg 5/5 Running 0 24m
csi-rbdplugin-provisioner-56cbc4d585-xdqw9 5/5 Running 0 24m
csi-rbdplugin-s5kjc 3/3 Running 0 24m
csi-rbdplugin-z6bj2 3/3 Running 0 24m
rook-ceph-mgr-a-68977dd7ff-t9rmk 1/1 Running 0 17m
rook-ceph-mon-a-84f4d48897-5lqtl 1/1 Running 0 22m
rook-ceph-mon-b-5d4858f579-5z9ld 1/1 Running 0 19m
rook-ceph-mon-c-8675b47cf7-82q8r 1/1 Running 0 19m
rook-ceph-operator-587d765957-lrmsr 1/1 Running 0 152m
rook-ceph-osd-1-856db94654-smdhp 1/1 Running 0 16m
rook-ceph-osd-20-77d7f7787f-h2dkg 1/1 Running 0 8m50s
rook-ceph-osd-prepare-ydzs-node1-qgmsc 0/1 Completed 0 5m2s
rook-ceph-osd-prepare-ydzs-node2-h667n 0/1 Completed 0 4m59s
rook-discover-bd8qh 1/1 Running 0 139m
rook-discover-bq6w8 1/1 Running 4 85m
rook-discover-c8qmz 1/1 Running 0 116m
rook-discover-ncjts 1/1 Running 0 139mOSD Pod 的数量将取决于集群中的节点数量以及配置的设备和目录的数量。如果用上面我们的资源清单,则每个节点将创建一个 OSD。rook-ceph-agent 和 rook-discover 是否存在也是依赖于我们的配置的。
Rook 工具箱
要验证集群是否处于正常状态,我们可以使用 Rook 工具箱 来运行 ceph status 命令查看。
Rook 工具箱是一个用于调试和测试 Rook 的常用工具容器,该工具基于 CentOS 镜像,所以可以使用 yum 来轻松安装更多的工具包。我们这里用 Deployment 控制器来部署 Rook 工具箱,部署的资源清单文件如下所示:(toolbox.yaml)
apiVersion: apps/v1
kind: Deployment
metadata:
name: rook-ceph-tools
namespace: rook-ceph
labels:
app: rook-ceph-tools
spec:
selector:
matchLabels:
app: rook-ceph-tools
template:
metadata:
labels:
app: rook-ceph-tools
spec:
dnsPolicy: ClusterFirstWithHostNet
containers:
- name: rook-ceph-tools
image: rook/ceph:v1.1.0
command: ["/tini"]
args: ["-g", "--", "/usr/local/bin/toolbox.sh"]
imagePullPolicy: IfNotPresent
env:
- name: ROOK_ADMIN_SECRET
valueFrom:
secretKeyRef:
name: rook-ceph-mon
key: admin-secret
securityContext:
privileged: true
volumeMounts:
- mountPath: /dev
name: dev
- mountPath: /sys/bus
name: sysbus
- mountPath: /lib/modules
name: libmodules
- name: mon-endpoint-volume
mountPath: /etc/rook
# 如果设置 hostNetwork: false, "rbd map" 命令会被 hang 住, 参考 https://github.com/rook/rook/issues/2021
hostNetwork: true
volumes:
- name: dev
hostPath:
path: /dev
- name: sysbus
hostPath:
path: /sys/bus
- name: libmodules
hostPath:
path: /lib/modules
- name: mon-endpoint-volume
configMap:
name: rook-ceph-mon-endpoints
items:
- key: data
path: mon-endpoints然后直接运行这个 rook-ceph-tools pod
$ kubectl apply -f toolbox.yaml一旦 toolbox 的 Pod 运行成功后,我们就可以使用下面的命令进入到工具箱内部进行操作:
$ kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash工具箱中的所有可用工具命令均已准备就绪,可满足您的故障排除需求。例如:
ceph status
ceph osd status
ceph df
rados df比如现在我们要查看集群的状态,需要满足下面的条件才认为是健康的:
- 所有 mons 应该达到法定数量
- mgr 应该是激活状态
- 至少有一个 OSD 处于激活状态
- 如果不是 HEALTH_OK 状态,则应该查看告警或者错误信息
$ ceph status
ceph status
cluster:
id: dae083e6-8487-447b-b6ae-9eb321818439
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 15m)
mgr: a(active, since 2m)
osd: 31 osds: 2 up (since 6m), 2 in (since 6m)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 79 GiB used, 314 GiB / 393 GiB avail
pgs:如果群集运行不正常,可以查看 Ceph 常见问题以了解更多详细信息和可能的解决方案。
存储
对于 Rook 暴露的三种存储类型可以查看对应的文档:
- 块存储:创建一个 Pod 使用的块存储
- 对象存储:创建一个在 Kubernetes 集群内部和外部都可以访问的对象存储
- 共享文件系统:创建要在多个 Pod 之间共享的文件系统
Ceph Dashboard
Ceph 有一个 Dashboard 工具,我们可以在上面查看集群的状态,包括总体运行状态,mgr、osd 和其他 Ceph 进程的状态,查看池和 PG 状态,以及显示守护进程的日志等等。
我们可以在上面的 cluster CRD 对象中开启 dashboard,设置dashboard.enable=true即可,这样 Rook Operator 就会启用 ceph-mgr dashboard 模块,并将创建一个 Kubernetes Service 来暴露该服务,将启用端口 7000 进行 https 访问,如果 Ceph 集群部署成功了,我们可以使用下面的命令来查看 Dashboard 的 Service:
$ kubectl get service -n rook-ceph
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rook-ceph-mgr ClusterIP 10.96.49.29 9283/TCP 23m
rook-ceph-mgr-dashboard ClusterIP 10.109.8.98 7000/TCP 23m 这里的 rook-ceph-mgr 服务用于报告 Prometheus metrics 指标数据的,而后面的的 rook-ceph-mgr-dashboard 服务就是我们的 Dashboard 服务,如果在集群内部我们可以通过 DNS 名称 http://rook-ceph-mgr-dashboard.rook-ceph:7000 或者 CluterIP http://10.109.8.98:7000 来进行访问,但是如果要在集群外部进行访问的话,我们就需要通过 Ingress 或者 NodePort 类型的 Service 来暴露了,为了方便测试我们这里创建一个新的 NodePort 类型的服务来访问 Dashboard,资源清单如下所示:(dashboard-external.yaml)
apiVersion: v1
kind: Service
metadata:
name: rook-ceph-mgr-dashboard-external
namespace: rook-ceph
labels:
app: rook-ceph-mgr
rook_cluster: rook-ceph
spec:
ports:
- name: dashboard
port: 7000
protocol: TCP
targetPort: 7000
selector:
app: rook-ceph-mgr
rook_cluster: rook-ceph
type: NodePort同样直接创建即可
$ kubectl apply -f dashboard-external.yaml创建完成后我们可以查看到新创建的 rook-ceph-mgr-dashboard-external 这个 Service 服务
$ kubectl get service -n rook-ceph
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rook-ceph-mgr ClusterIP 10.96.49.29 9283/TCP 23m
rook-ceph-mgr-dashboard ClusterIP 10.109.8.98 7000/TCP 23m
rook-ceph-mgr-dashboard-external NodePort 10.98.8.0 7000:32381/TCP 3m30s 现在我们需要通过 http:// 就可以访问到 Dashboard 了。

ceph dashboard login
在访问的时候需要我们登录才能够访问,Rook 创建了一个默认的用户 admin,并在运行 Rook 的命名空间中生成了一个名为 rook-ceph-dashboard-admin-password 的 Secret,要获取密码,可以运行以下命令:
$ kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" | base64 --decode && echo
xxxx(登录密码)用上面获得的密码和用户名 admin 就可以登录 Dashboard 了,在 Dashboard 上面可以查看到整个集群的状态:
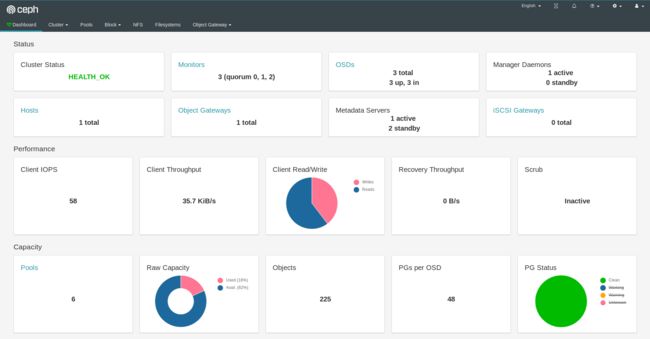
ceph dashboard
配置 Dashboard
除此之外在使用上面的 CRD 创建 ceph 集群的时候我们还可以通过如下的配置来配置 Dashboard:
spec:
dashboard:
urlPrefix: /ceph-dashboard
port: 8443
ssl: true-
urlPrefix:如果通过反向代理访问 Dashboard,则可能希望在 URL 前缀下来访问,要让 Dashboard 使用包含前缀的的链接,可以设置urlPrefix -
port:可以使用端口设置将为 Dashboard 提供服务的端口从默认值修改为其他端口,K8S 服务暴露的端口也会相应的更新 -
ssl:通过设置ssl=false,可以在不使用 SSL 的情况下为 Dashboard 提供服务
开启 Object Gateway 管理
为了在 Dashboard 上面使用 Object Gateway 管理功能,你需要提供一个一个带有 system 标志的登录认证用户。如果没有这样的用户,可以使用下面的命令创建一个:
# 先进入 Rook 工具箱 Pod
$ kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash
# 创建用户
$ radosgw-admin user create --uid=myuser --display-name=test-user \
--system
{
"user_id": "myuser",
"display_name": "test-user",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"subusers": [],
"keys": [
{
"user": "myuser",
"access_key": "<记住ak这个值>",
"secret_key": "<记住sk这个值>"
}
],
......
}创建后会为当前用户生成 access_key 和 secret_key 这两个值,记住这两个值,下面需要用到。
然后执行下面的命令进行配置:
$ ceph dashboard set-rgw-api-user-id myuser
Option RGW_API_USER_ID updated
$ ceph dashboard set-rgw-api-access-key
Option RGW_API_ACCESS_KEY updated
$ ceph dashboard set-rgw-api-secret-key
Option RGW_API_SECRET_KEY updated 现在就可以访问 Object Gateway 的菜单了。
监控
每个 Rook 群集都有一些内置的指标 collectors/exporters,用于使用 Prometheus 进行监控。要了解如何为 Rook 群集设置监控,可以按照监控指南中的步骤进行操作。
删除集群并清除数据
删除Cephcluster CRD
[root@kmaster ceph]# kubectl get crd
NAME CREATED AT
cephblockpools.ceph.rook.io 2021-09-26T08:18:55Z
cephclients.ceph.rook.io 2021-09-26T08:18:55Z
cephclusters.ceph.rook.io 2021-09-26T08:18:55Z
cephfilesystems.ceph.rook.io 2021-09-26T08:18:55Z
cephnfses.ceph.rook.io 2021-09-26T08:18:55Z
cephobjectrealms.ceph.rook.io 2021-09-26T08:18:55Z
cephobjectstores.ceph.rook.io 2021-09-26T08:18:55Z
cephobjectstoreusers.ceph.rook.io 2021-09-26T08:18:55Z
cephobjectzonegroups.ceph.rook.io 2021-09-26T08:18:55Z
cephobjectzones.ceph.rook.io 2021-09-26T08:18:55Z
cephrbdmirrors.ceph.rook.io 2021-09-26T08:18:55Z
objectbucketclaims.objectbucket.io 2021-09-26T08:18:55Z
objectbuckets.objectbucket.io 2021-09-26T08:18:55Z
volumes.rook.io 2021-09-26T08:18:55Z
删除Operator 和相关的资源
kubectl delete -f operator.yaml
kubectl delete -f common.yaml
kubectl delete -f cluster.yaml
删除主机上的数据
rook创建cluster的时候会把部分数据卸载本机的/var/lib/rook(dataDirHostPath指定的目录)中,如果不删除会影响下次集群部署,rook据说下个版本会增加k8s 本地存储调用的功能,就不会直接存在硬盘上了
rm -rf /var/lib/rook
擦除硬盘上的数据
创建osd时被写入了数据,需要擦除,否则无法再次创建ceph集群,脚本中有各种硬盘的擦除命令,不需要全部执行成功,根据当前机器的硬盘情况确定。
vim clean-ceph.sh
#!/usr/bin/env bash
DISK="/dev/vdb"sgdisk --zap-all $DISK
dd if=/dev/zero of="$DISK" bs=1M count=100 oflag=direct,dsync
blkdiscard $DISK
ls /dev/mapper/ceph-* | xargs -I% -- dmsetup remove %
rm -rf /dev/ceph-*
rm -rf /dev/mapper/ceph--*
卸载删除ceph-rook,kubectl get pod -n rook-ceph ,pods 显示未Terminating,无法删除
kubectl get pods -n rook-ceph| grep Terminating | awk '{print $1}' | xargs kubectl delete pod -n rook-ceph --grace-period=0 --force
卸载删除ceph-rook,kubectl get ns ,rook-ceph 显示未Terminating,无法删除
NAMESPACE=rook-ceph
kubectl proxy &
kubectl get namespace $NAMESPACE -o json |jq '.spec = {"finalizers":[]}' >temp.json
curl -k -H "Content-Type: application/json" -X PUT --data-binary @temp.json 127.0.0.1:8001/api/v1/namespaces/$NAMESPACE/finalize
卸载osd 或者卸载集群另外一个后遗症,rook-ceph 名称空间删除了,但是 cephcluster无法删除
[root@kmaster ceph]# kubectl get ns
NAME STATUS AGE
default Active 150d
ingress-nginx Active 149d
kube-node-lease Active 150d
kube-public Active 150d
kube-system Active 150d
kubernetes-dashboard Active 144d
test-ns Active 150d
[root@kmaster ceph]# kubectl -n rook-ceph get cephcluster
NAME DATADIRHOSTPATH MONCOUNT AGE PHASE MESSAGE HEALTH
rook-ceph /data/rook 4 18h Progressing Cluster is creating
[root@kmaster ceph]# kubectl api-resources --namespaced=true -o name|xargs -n 1 kubectl get --show-kind --ignore-not-found -n rook-ceph
Error from server (MethodNotAllowed): the server does not allow this method on the requested resource
Error from server (MethodNotAllowed): the server does not allow this method on the requested resource
NAME DATADIRHOSTPATH MONCOUNT AGE PHASE MESSAGE HEALTH
cephcluster.ceph.rook.io/rook-ceph /data/rook 4 18h Progressing Cluster is creating
[root@kmaster ceph]# kubectl edit cephcluster.ceph.rook.io -n rook-ceph
error: cephclusters.ceph.rook.io "rook-ceph" could not be found on the server
The edits you made on deleted resources have been saved to "/tmp/kubectl-edit-9ln94.yaml"# 解决方法:
把finalizers的值删掉,cephcluster.ceph.rook.io便会自己删除