音频质量的评价方法:简单梳理
音频质量的评价方法
- 1. 语音质量评估(SQA)
-
- 1.1 主观评价和客观评价
- 1.2 主观音频评价标准
-
- ITU-T 评价标准
- ITU-R评价标准
- 1.3 客观音频评价标准
- 3.3 一些概念
- 2. 主观评价指标
-
- 平均意见得分(MOS)
- 失真等级评分(CMOS)
- ABX Test
- 3. 客观评价指标
-
- 3.1 有参考
-
- ITU-T P.861:PSQM
- ITU-T P.862:PESQ
- ITU-T P.863:POLQA
- 3.2 无参考
-
- (1)传统方法
- 基于信号:ITU-T P.563:P.563
- 基于参数:ITU-T G .I07:E-Model
- (2)基于深度学习的方法
- NISQA
- Quality-Net
- 3. 按照
- 4. 代码和工具
- 其他综合性参考
1. 语音质量评估(SQA)
1.1 主观评价和客观评价
语音质量评估(Speech Quality Assessment,SQA),就是通过人类或自动化的方法评价语音质量。在实践中,有很多主观和客观的方法评价语音质量。
-
主观评价就是通过人类(听声人员) 对语音进行打分,比如
MOS、CMOS和ABX Test。主观评价方法是基于大量听音人对原始声音信号和失真声音信号进行对比测听的基础上,根据某种预先规定的尺度对失真信号进行质量等级划分,它反映了听音人员对声音质量好坏程度的一种主观印象,这种评价是用户对音频质量的真实反映。
-
客观评价即是通过算法评测语音质量,在实时语音通话领域,这一问题研究较多,出现了诸如如
PESQ和P.563这样的有参考和无参考的语音质量评价标准。客观评价方法多采用某个特定的参数去表征声音通过数字音频系统后的失真程度,并以此来评估处理系统的性能优劣。
在大多数情况下,主观评价相对于客观评价而言,更能全面、有效地反映音频处理技术的性能,而客观评价多用于声音信号相关参数的性能评测。
1.2 主观音频评价标准
ITU-T 评价标准
ITU-T P.800《语音质量的主观评价方法》
其本质是平均意见得分(MOS)ITU-T P.830《电话宽度和宽带数字语音编码器的主观评价方法》ITU-T P.805《对话质量的主观评价》
ITU-R评价标准
ITU-R B5.1116《多声道音频系统中小损伤主观评价方法》ITU-R B5.1285《音频系统中小拟伤主观评价的预选方法》ITU- R B5.1534《 中等质量音频系统的主观评价方法》
1.3 客观音频评价标准
根据评价对象的不同,语音和音频质量的客观评价方法主要有基于输入-输出和基于输出两种。
- 基于输入-输出
基于输入-输出的评价是指系统同时具备输入音频( 一般为原始未失真的) 和输出音频( 经过音频系统处理的),再边过提取两种信号的特征参数来建立评价模型并给出客观评价结果。 - 基于输出
基于输出的评价是指在没有原始信号的条件下仅根据系统的输出信号进行质量评价的方法。
基于输入-输出的评价方法研究较多,产生的标准也较多,基于输出的评价方法因其实用性和可操作性逐渐成为国内外学者研究的重点,但研究难度较大,产生的标准也少。
3.3 一些概念
- 信噪比(SNR)
信噪比 (Signal-to-Noise Ratio,SNR)一直是衡量针对宽带噪声失真的语音增强算的常规方法。但要计算信噪比必需知道纯净语音信号,但在实际应用中这是不可能的。
因此,SNR主要用于纯净语音信号和噪声信号都是己知的算法的仿真中。 信噪比计算整个时间轴上的语音信号与噪声信号的平均功率之比。 - 分段信噪比(SegSNR)
分段信噪比(Segment Signal-to-Noise Ratio,SegSNR)。由于语音信号是一种缓慢变化的短时平稳信号,因而在不同时间段上的信噪比也应不一样。为了改善上面的问题,可以采用分段信噪比。
2. 主观评价指标
平均意见得分(MOS)
MOS评测实际是一种很宽泛的说法。由于给出评测分数的是人类,因此可以灵活的测试语音的不同方面。
在实时通讯领域,国际电信联盟(ITU)将语音质量的主观评价方法做了标准化处理,代号为ITU-T P.800.1。其中收听质量的绝对等级评分(Absolute Category Rating, ACR) 是目前比较广泛采用的一种主观评价方法。在使用ACR方法对语音质量评价时,参与评测的人员对语音整体质量进行打分,分值范围为1-5分,分数越大表示语音质量最好。

一般MOS应为4或者更高,这可以被认为是比较好的语音质量,若MOS低于3.6,则表示大部分被测不太满意这个语音质量。
除了绝对等级评分,其它常用的语音质量主观评价有失真等级评分(Degradation Category Rating, DCR)和相对等级评分(Comparative Category Rating, CCR),这两种方式不仅需要提供失真语音信号还需要原始语音信号,通过比较失真信号和原始信号获得评价结果(类似于ABX Test),比较适合于评估背景噪音对语音质量的影响,或者不同算法之间的直接较量。
失真等级评分(CMOS)
ABX Test
3. 客观评价指标
客观质量评估算法大概分三类,主要取决于是否使用无损的源视频作为参考。
1、全参考:比如PSNR就是典型的全参考算法,通过与源视频进行各种层面比对,来衡量损伤视频的质量。
2、无参考:有的算法不使用源视频,只使用接收端的视频,来衡量它自己本身的质量。
3、部分参考: 比如从源视频中提取一个特征向量,特征向量随着损伤视频一块发送到用户端用来计算质量。视频会议这种场景要做全参考本来是不现实的,因为不可能把本地无损的源视频送到用户端或者其他地方计算质量,我们这次所做的工作就是把会议这种典型的实时场景转化成一个可以使用全参考算法离线优化的场景。
3.1 有参考
ITU-T P.861:PSQM
ITU-T P.862:PESQ
PESQ(Perceptual evaluation of speech quality) 即:语音质量的感知评估,其在国际电信联盟的标注化代号为ITU-T P.862。
感知模型在PESQ算法中用来计算PESQ得分,即原始信号和退化信号之间的差异。
它是一个心理模型,能够对客观语音质量评估提供一个主观MOS的预测值,而且可以映射到MOS刻度范围。
PESQ算法需要带噪的衰减信号和一个原始的参考信号。PESQ得分范围在 -0.5–4.5 之间。得分越高表示语音质量越好。
def get_pesq(clean_wav, denoised_wav):
"""
计算两个音频的pesq,要求采样率为16000或8000,且8000只支持窄带。
PESQ就是用经过处理后的语音文件(语音压缩、重构等)与原始语音进行比较。PESQ得分范围在-0.5--4.5之间。得分越高表示语音质量越好。
git: https://github.com/vBaiCai/python-pesq
:param clean_wav: 原始文件
:param denoised_wav: 待评估文件
:return: score
"""
ref, sr0 = sf.read(clean_wav)
deg, sr1 = sf.read(denoised_wav)
# 检查采样率是否达标
if sr0 == sr1 and (sr0 == 16000 or sr0 == 8000):
logger.info("ref_audio/deg_audio音频采样率为: %s/%s" % (str(sr0), str(sr1)))
else:
logger.error("音频采样率必须为16000或窄带8000。ref_audio/deg_audio音频采样率为: %s/%s" % (str(sr0), str(sr1)))
return False
# 检查两个音频文件长度,帧数相差不大于10
if abs(len(ref) - len(deg)) > 10:
logger.error("ref_wav/deg_wav两个音频长度不一致: %d/%d" % (len(ref), len(deg)))
return False
score = pesq(ref, deg, sr0)
logger.success("PESQ算法计算的MOS值为:%s" % str(score))
return score
参考:音频质量评估及音频处理常用功能
ITU-T P.863:POLQA
ITU-T P.863《感知客观昕音质量分析方法》,该标准提出了下一代语音质量客观评价算法POLQA,适用于吏广泛的固定网络、移动网络和IP网络通话质量评价。
POLQA,类似于P.862 PESQ,是一种全参考(FR)算法,可对与原始信号相关的降级或处理过的语音信号进行评级。
3.2 无参考
(1)传统方法
基于信号:ITU-T P.563:P.563
该方法是ITU-T产生的第一个不需要参考语音的客观评价方法,被建议作为单端型非插入式的测量方法,即基于输出的评价方法,他考虑到了公用电话交换网中的各种失真情况,并且能够依据基于感知的测度MOS- LQO来预测语音质量 。
ITU-TP.563 并不仅限于端到端的测量,它也能用在传输链路的任意环节,可以实时测量窄带话音信号质量。但ITU-TP.563没有输入语音作参考,与主观结果的相关度没有PESQ高,算法较为复杂,还需要改进。
代码工具:
- github:https://github.com/qin/p.563
下载:P.563 Source Code - 修改版:https://github.com/JasonSWFu/Quality-Net
基于参数:ITU-T G .I07:E-Model
E-Model:基于传输网络参数的无参考语音质量评估
ITU-TG.107 《用于传输规划的计算模型:E模型》。为了克服PSQM和PESQ不能用于在数据
网络上分析语音质量的缺点,该标准提出E模型算法作为通用的ITU-T传输性能等级模型,成为VolP的语音质量评价标准。
E-Model和P.563一样,不需要原始语音就可以给出当前的语音质量。但是E-Model连退化语音都不需要,只是根据当前的传输网络,比如丢包率、延迟等给出当前的语音评估结果。
(2)基于深度学习的方法
基于深度学习的方法:AutoMOS、 QualityNet、 NISQA、MOSNet等
NISQA
NISQA: 无参考语音通信网络的语音质量
由于深度学习的火热,也有部分人利用深度网络评估语音质量。这类方法都比较简单,由于使用的深度网络可以自动进行特征提取,因此这类方法直接将梅尔频谱系数或者MFCC直接送入模型即可。

如上图,整个网络结构十分简单,对数梅尔系数分别送入CNN和计算MFCC,CNN实际输出了帧级别的语音质量。为了使整个模型能够对语音的整体质量进行评估,CNN输出的结果和MFCC连接起来送入LSTM,以得到最终的MOS分。
Quality-Net
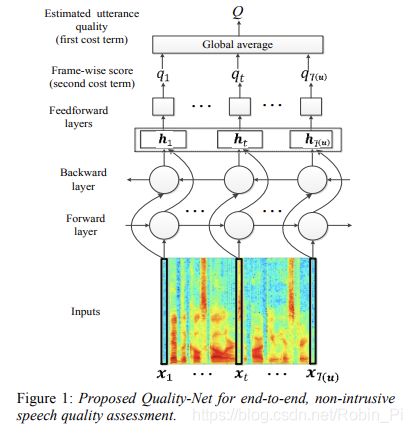
基于 bidirectional long short-term memory (BLSTM)的Quality-Net:
Quality-Net: An End-to-End Non-intrusive Speech Quality Assessment Model based on BLSTM (Interspeech 2018)
3. 按照
4. 代码和工具
汇总:Python 代码实现:python实现语音信号处理常用度量方法
-
TU PESQ官方网站
-
Python封装版的 python-pesq(PESQ): vBaiCai /python-pesq
-
相关博客:PESQ语音质量测试
-
aliutkus /speechmetrics——包装了MOSNet, BSSEval, STOI, PESQ, SRMR, SISDR 等语音质量评价指标。
-
Assessing Audio Quality with Deep Learning
-
语音分割_语音质量客观打分工具(mos_pesq)
-
schmiph2 / pysepm
其他综合性参考
-
音频质量评估及音频处理常用功能——这位博主总结了一些算法以及常用的音频处理工具
-
实时音视频质量评估方案——该博主从理论到项目应用,介绍的非常详细!
-
感知音频测试:POLQA 和 PESQ
补:
- 音频降噪
def optimize_audio(input_file, output_file):
"""
对音频进行降噪处理,隔离可听见的声音。将低通滤波器与高通滤波器结合使用。
过滤掉200hz及以下的内容,然后过滤掉3000hz及以上的内容,可以很好地保持可用的语音音频。
:param input_file: 原始文件
:param output_file: 处理后文件
:return:
"""
if not os.path.exists(input_file):
logger.error("文件不存在,请检查文件: %s" % input_file)
if os.path.isfile(output_file) and os.path.exists(output_file):
os.remove(output_file)
cmd = 'ffmpeg -i %s -af "highpass=f=200, lowpass=f=3000" %s' % (input_file, output_file)
subprocess_cmd(cmd, "handle_audio")
return output_file
参考:音频质量评估及音频处理常用功能
- 音频数据增强
iver56 / audiomentations
参考:
- 语音质量评价方法【音频质量专题】
- 语音质量评估
- 音频质量评估及音频处理常用功能——这位博主总结了一些算法以及常用的音频处理工具
- 《音频质量评价标准研究》
- 《阿里AI Lab高级算法专家张增明:天猫精灵的任务型智能对话》