keras之父《python深度学习》笔记 第四章
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
机器学习基础
- 前言
- 一、机器学习的四个分支
-
- 1.监督学习
- 2.无监督学习
- 3.自监督学习
- 4.强化学习
- 二、评估机器学习模型
-
- 1.训练集、验证集和测试集
- 三、数据预处理和特征学习
-
- 1.神经网络的数据预处理
- 四、欠拟合和过拟合处理
-
- 1.正则化
- 2.dropout
- 五、机器学习流程
-
- 1.定义问题、收集数据
- 2.选择衡量成功的指标
- 3.确定评估方法
- 4.准备数据
- 5.开发比基准更高的模型
- 6.扩大模型规模:开发过拟合的模型
- 7.模型正则化与调节超参数
- 总结
前言
学完第3 章的三个实例,你应该已经知道如何用神经网络解决分类问题和回归问题,而且也看到了机器学习的核心难题:过拟合。本章会将你对这些问题的直觉固化为解决深度学习问题的可靠的概念框架。我们将把所有这些概念——模型评估、数据预处理、特征工程、解决过拟合——整合为详细的七步工作流程,用来解决任何机器学习任务。。
提示:以下是本篇文章正文内容,下面案例可供参考
一、机器学习的四个分支
1.监督学习
监督学习是机器学习最常见的类型。给定一组样本,学会将输入样本映射到已知目标。上一章的三个例子都属于监督学习,常见的监督学习就是分类和回归,不过也有一些其他类型的监督学习:
序列生成:给定一个序列,预测序列下一个对象。比如根据一段文字预测下一个单词。
语法树预测:给定一个句子,预测其分解生成的语法树。
目标检测:给定一张图像,在图中特定目标的周围画一个边界框。
图像分割:给定一个图像,在特定物体上画一个像素级的掩模(mask)。
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
2.无监督学习
无监督学习是指在没有目标的情况下寻找输入数据的有趣变换,其目的在于数据可视化、
数据压缩、数据去噪或更好地理解数据中的相关性。无监督学习是数据分析的必备技能,在解
决监督学习问题之前,为了更好地了解数据集,它通常是一个必要步骤。降维(dimensionality
reduction)和聚类(clustering)都是众所周知的无监督学习方法。
3.自监督学习
自监督学习是监督学习的一个特例,它与众不同,值得单独归为一类。自监督学习是没有人工标注的标签的监督学习,你可以将它看作没有人类参与的监督学习。标签仍然存在(因为总要有什么东西来监督学习过程),但它们是从输入数据中生成的,通常是使用启发式算法生成的。
举个例子,自编码器(autoencoder)是有名的自监督学习的例子,其生成的目标就是未经修改的输入。同样,给定视频中过去的帧来预测下一帧,或者给定文本中前面的词来预测下一个词,
都是自监督学习的例子[这两个例子也属于时序监督学习(temporally supervised learning),即用未来的输入数据作为监督]。注意,监督学习、自监督学习和无监督学习之间的区别有时很模糊,这三个类别更像是没有明确界限的连续体。自监督学习可以被重新解释为监督学习或无监督学习,这取决于你关注的是学习机制还是应用场景。
4.强化学习
强化学习一直以来被人们所忽视,但最近随着Google 的DeepMind 公司将其成功应用于学习玩Atari 游戏(以及后来学习下围棋并达到最高水平),机器学习的这一分支开始受到大量关注。
在强化学习中,智能体(agent)接收有关其环境的信息,并学会选择使某种奖励最大化的行动。例如,神经网络会“观察”视频游戏的屏幕并输出游戏操作,目的是尽可能得高分,这种神经网络可以通过强化学习来训练。
二、评估机器学习模型
1.训练集、验证集和测试集
评估模型的重点是将数据划分为三个集合:训练集、验证集和测试集。在训练数据上训练模型,在验证数据上评估模型。一旦找到了最佳参数,就在测试数据上最后测试一次。
之所以要分成三个数据集合是因为开发模型是需要调节参数,以达到更好的训练效果。但是神经网络很容易出现过拟合,所以为了验证结果需要用未经训练的数据集合来测试。但是如果只分训练集和测试集的话,每次测试都是造成信息泄露。因为我们调节模型的原因是在测试集表现不好,这样相当于模型一步步获得了一些测试集的信息,造成测试结果不准。所以我们在训练集训练,在验证集先验证,最后验证好再用测试集测试,这样可以最大程度避免测试集数据特征泄露到我们的算法模型上,也更能保证模型的泛化能力。
训练数据划分为训练集和验证集有几种思路:
1.简单留出验证。留出一定比例的数据作为验证集,剩余训练数据作为训练集,这是最简单的一种方案。
num_validation_samples = 10000
np.random.shuffle(data)
validation_data = data[:num_validation_samples]
data = data[num_validation_samples:]
training_data = data[:]
model = get_model()
model.train(training_data)
validation_score = model.evaluate(validation_data)
model = get_model()
model.train(np.concatenate([training_data,
validation_data]))
test_score = model.evaluate(test_data)
k折验证,k折验证在上一章当中实现过,原理就是将数据分为k份,每次用k-1份做训练,用剩下的一份来评估。最终的分数等于k个分数的平均值。
3.带打乱的k折数据验证
如果可用的数据相对较少,而你又需要尽可能精确地评估模型,那么可以选择带有打乱数据的重复K 折验证(iterated K-fold validation with shuffling)。我发现这种方法在Kaggle 竞赛中特别有用。具体做法是多次使用K 折验证,在每次将数据划分为K 个分区之前都先将数据打乱。
最终分数是每次K 折验证分数的平均值。注意,这种方法一共要训练和评估P×K 个模型(P是重复次数),计算代价很大。
三、数据预处理和特征学习
1.神经网络的数据预处理
神经网络的数据预处理包括张量化、标准化、处理缺失值和特征提取
张量化是数据最基础的处理,因为深度学习中处理的都是张量,所以无论是什么数据都要进行张量化。比如文本分类中我们把数据onehot之后转换为张量。
标准化主要是将数据变换到[0,1]之间的数据,如果将异质数据输入到神经网络中(比如一个0-1范围,另一个100-200范围),这么做很有可能导致网络无法收敛,所以为了让神经网络学习能够收敛,需要取值范围0到1之间的同质数据。
数据当中有缺失值也是常见现象。常见的操作是将缺失值设为0,只要0不是一个有意义的值,网络就会学习到0是缺失数据,并且忽略这个值(从这个例子也可以感受到神经网络的强大之处)。
四、欠拟合和过拟合处理
深度学习中,训练过程中常见的问题就是过拟合,因为神经网络有非常多的参数,很容易学习到样本中的特征,有些特征是我们想要它学习的,但是也有一些是不必要的,防止神经网络学习到过度多的特征,也是要解决的问题。
最简单的减少过拟合的方法就是减小网络大小,因为网络变小了那么参数会变小,能够学习到的特征也就会变小。
减少过拟合更常见的方法是正则化和dropout。
1.正则化
正则化的思想来源于奥卡姆剃刀原理:如果一件事情有多种解释,那么最简单的解释最有可能是正确的。把这个原理引入到神经网络当中就是说:当有很多模型可以解释一个问题时,那么最简洁的模型最有可能是最好的。
通常的处理措施是权重正则化,实现方法是向损失函数中添加与权重相关的成本,这个成本有两种形式:
L1 正则化(L1 regularization):添加的成本与权重系数的绝对值[权重的 L1 范数(norm)]
成正比。
L2 正则化(L2 regularization):添加的成本与权重系数的平方(权重的L2 范数)成正比。
神经网络的L2 正则化也叫权重衰减(weight decay)。不要被不同的名称搞混,权重衰减
与L2 正则化在数学上是完全相同的。
keras中可以很简单的实现正则化,比如下面这段代码
from keras import regularizers
model = models.Sequential()
model.add(layers.Dense(16, kernel_regularizer=regularizers.l2(0.001),
activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, kernel_regularizer=regularizers.l2(0.001),
activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
l2(0.001) 的意思是该层权重矩阵的每个系数都会使网络总损失增加0.001 * weight_
coefficient_value。注意,由于这个惩罚项只在训练时添加,所以这个网络的训练损失会
比测试损失大很多。
类似的,keras中也可以实现L1正则化或者同时做L1和L2的正则化
from keras import regularizers
regularizers.l1(0.001)
#L1正则化
regularizers.l1_l2(l1=0.001, l2=0.001)
#同时做L1和L2正则化
2.dropout
dropout也是一个简单但是很有效的正则化方法,操作也很简单:就是随机将一些输出特征舍弃(设置为0)。dropout的比例通常为0.2到0.5之间。这个方法听起来有点随意,但是实践证明这个确实能很有效的减少过拟合。
keras中可以添加dropout层来实现dropout,这个层将会对前一层的输出做dropput。
model.add(layers.Dropout(0.5))
我们以IMDB网络为例,测试一下dropout的效果。
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
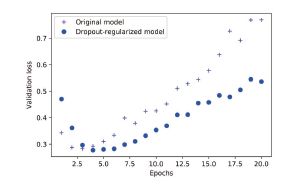
五、机器学习流程
1.定义问题、收集数据
知乎上有句话先问是不是再问为什么,首先要定义面对的需要解决的问题是什么,定义好问题之后再去寻找相关数据。
2.选择衡量成功的指标
要取得成功,就必须给出成功的定义:精度?准确
率(precision)和召回率(recall)?客户保留率?衡量成功的指标将指引你选择损失函数,即模型要优化什么。它应该直接与你的目标(如业务成功)保持一致。
3.确定评估方法
一旦明确了目标,你必须确定如何衡量当前的进展。前面介绍了三种常见的评估方法。
留出验证集。数据量很大时可以采用这种方法。
K折交叉验证。如果留出验证的样本量太少,无法保证可靠性,那么应该选择这种方法。
重复的 K 折验证。如果可用的数据很少,同时模型评估又需要非常准确,那么应该使用
这种方法。
只需选择三者之一。大多数情况下,第一种方法足以满足要求。
4.准备数据
一旦知道了要训练什么、要优化什么以及评估方法,那么你就几乎已经准备好训练模型了。
但首先你应该将数据格式化,使其可以输入到机器学习模型中(这里假设模型为深度神经网络)。
如前所述,应该将数据格式化为张量。
这些张量的取值通常应该缩放为较小的值,比如在 [-1, 1] 区间或 [0, 1] 区间。
如果不同的特征具有不同的取值范围(异质数据),那么应该做数据标准化。
你可能需要做特征工程,尤其是对于小数据问题。
准备好输入数据和目标数据的张量后,你就可以开始训练模型了。
5.开发比基准更高的模型
这一阶段的目标是获得统计功效(statistical power),即开发一个小型模型,它能够打败纯
随机的基准(dumb baseline)。在MNIST 数字分类的例子中,任何精度大于0.1 的模型都可以说
具有统计功效;在IMDB 的例子中,任何精度大于0.5 的模型都可以说具有统计功效。
注意,不一定总是能获得统计功效。如果你尝试了多种合理架构之后仍然无法打败随机基准,
那么原因可能是问题的答案并不在输入数据中。要记住你所做的两个假设。
假设输出是可以根据输入进行预测的。
假设可用的数据包含足够多的信息,足以学习输入和输出之间的关系。
这些假设很可能是错误的,这样的话你需要从头重新开始。
如果一切顺利,你还需要选择三个关键参数来构建第一个工作模型。
最后一层的激活。它对网络输出进行有效的限制。例如,IMDB 分类的例子在最后一层
使用了sigmoid,回归的例子在最后一层没有使用激活,等等。
损失函数。它应该匹配你要解决的问题的类型。例如,IMDB 的例子使用 binary_crossentropy、回归的例子使用mse,等等。
优化配置。你要使用哪种优化器?学习率是多少?大多数情况下,使用 rmsprop 及其默认的学习率是稳妥的。
关于损失函数的选择,需要注意,直接优化衡量问题成功的指标不一定总是可行的。有时难以将指标转化为损失函数,要知道,损失函数需要在只有小批量数据时即可计算(理想情况下,只有一个数据点时,损失函数应该也是可计算的),而且还必须是可微的(否则无法用反向
传播来训练网络)。例如,广泛使用的分类指标ROC AUC 就不能被直接优化。因此在分类任务中,常见的做法是优化ROC AUC 的替代指标,比如交叉熵。一般来说,你可以认为交叉熵越小,ROC AUC 越大。
6.扩大模型规模:开发过拟合的模型
一旦得到了具有统计功效的模型,问题就变成了:模型是否足够强大?它是否具有足够多
的层和参数来对问题进行建模?例如,只有单个隐藏层且只有两个单元的网络,在MNIST 问题
上具有统计功效,但并不足以很好地解决问题。请记住,机器学习中无处不在的对立是优化和
泛化的对立,理想的模型是刚好在欠拟合和过拟合的界线上,在容量不足和容量过大的界线上。
为了找到这条界线,你必须穿过它。
要搞清楚你需要多大的模型,就必须开发一个过拟合的模型,这很简单。
(1) 添加更多的层。
(2) 让每一层变得更大。
(3) 训练更多的轮次。
要始终监控训练损失和验证损失,以及你所关心的指标的训练值和验证值。如果你发现模型在验证数据上的性能开始下降,那么就出现了过拟合。下一阶段将开始正则化和调节模型,以便尽可能地接近理想模型,既不过拟合也不欠拟合。
7.模型正则化与调节超参数
这一步是最费时间的:你将不断地调节模型、训练、在验证数据上评估(这里不是测试数据)、
再次调节模型,然后重复这一过程,直到模型达到最佳性能。你应该尝试以下几项。
‰ 添加 dropout。
‰ 尝试不同的架构:增加或减少层数。
‰ 添加 L1 和 / 或 L2 正则化。
‰ 尝试不同的超参数(比如每层的单元个数或优化器的学习率),以找到最佳配置。
‰( 可选)反复做特征工程:添加新特征或删除没有信息量的特征。
请注意:每次使用验证过程的反馈来调节模型,都会将有关验证过程的信息泄露到模型中。如果只重复几次,那么无关紧要;但如果系统性地迭代许多次,最终会导致模型对验证过程过拟合(即使模型并没有直接在验证数据上训练)。这会降低验证过程的可靠性。
一旦开发出令人满意的模型配置,你就可以在所有可用数据(训练数据+ 验证数据)上训练最终的生产模型,然后在测试集上最后评估一次。如果测试集上的性能比验证集上差很多,那么这可能意味着你的验证流程不可靠,或者你在调节模型参数时在验证数据上出现了过拟合。在这种情况下,你可能需要换用更加可靠的评估方法,比如重复的K 折验证。
总结
本文讲述了机器学习的基础概念和基础流程,学完之后读者会对机器学习有一个大致的概念了解。