哈希表 HashTable
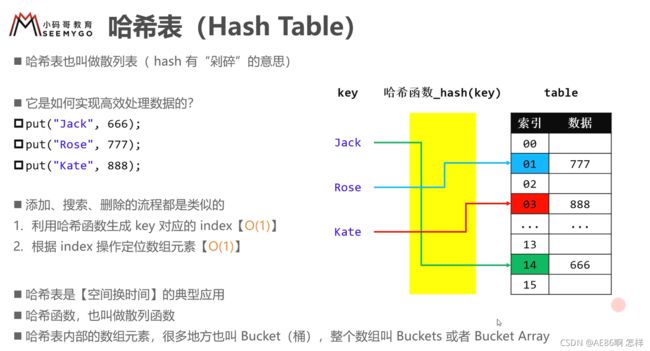
(1)哈希表底层存储结构也是线性表
(2)哈希表的核心在于哈希函数,哈希函数用于获取index值,决定了将元素放在哪个位置
(3)hash表的增删查时间复杂度都是O(1)
可以根据hash函数直接定位元素,进行增删查
(4)hash表是空间换时间
因为hash表的容量是事先申请的,会造成一定空间的浪费
(5)桶: hash表中arr[index]叫做桶,因为一个桶中可以存放多个hash值相同的元素
hash冲突
hash冲突本质上就是不同的元素根据hash函数得到相同的结果:
- key1 != key2 && hash(key1) == hash(key2)
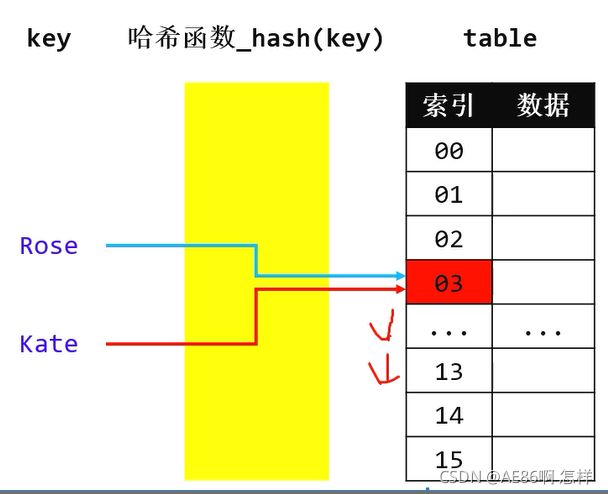
常见解决hash冲突的方法:
(1)开放地址法
按照一定的规则探测其他地址,直到遇到空地址
(2)Re-Hashing
设计多个哈希函数
(3)链地址法
通过链表将同一index的元素串联起来
JDK1.8 中的哈希表是使用 链表+红黑树 解决哈希冲突

哈希函数和index
哈希函数是获取index的辅助函数;
获取一个key所对应的index经过两个过程:
(1)hash(key)获取key的哈希值,哈希值必须为整数
(2)哈希值和数组大小进行相关运算,生成一个索引值index
相关运算
相关运算有两种解决方案,其目的都是相同的,确保数组所有的index都有机会被放入元素,并且将index的范围锁定在[0,size-1]
(1)取模 hash(key) % table.length
(2)与运算 hash(key) & (table.lenth - 1)
与运算要求数组的长度必须为2的幂次方
Java常见数据类型key的生成方式
key 的常见种类可能有
整数、浮点数、字符串、自定义对象
- 不同种类的 key ,哈希值的生成方式不一样,但目标是一致的
- 尽量让每个 key 的哈希值是唯一的
- 尽量让 key 的所有信息参与运算
在Java中,HashMap 的 key 必须实现 hashCode、equals 方法,也允许 key 为 null
1.Integer
将自身值作为哈希值
2.Float
将浮点数底层存储的二进制格式转为整数值,将此整数值作为哈希值
3.Long

高32bit 和 低32bit异或计算出 32bit 的哈希值
充分利用所有信息计算出哈希值
4.Double
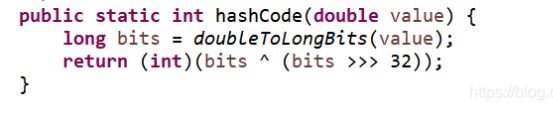
5.String
字符串是由若干个字符组成的
参考https://blog.csdn.net/weixin_43734095/article/details/104809788
6.自定义对象
1.自定义类
public class Person {
private int age;
private float height;
private String name;
public Person(int age, float height, String name) {
super();
this.age = age;
this.height = height;
this.name = name;
}
}
(1)不重写hashCode
Object类的hashcode计算方式和对象的内存地址有关,内存地址相同才有相同的哈希值
因此在不重写hashCode也不重写equals的情况下,虽然自定义对象的属性值都是相等的,但是计算出来的哈希值不一样
(2)重写hashCode
在 Person.java 内部重写了hashCode方法,使用了 Person 类所有的信息来计算哈希值
ublic class Person {
private int age;
private float height;
private String name;
public Person(int age, float height, String name) {
super();
this.age = age;
this.height = height;
this.name = name;
}
@Override
public int hashCode() {
int hashCode = Integer.hashCode(age);// *31是因为JVM内部优化
hashCode = hashCode * 31 + Float.hashCode(height);
hashCode = hashCode * 31 + (name!=null ? name.hashCode() : 0);
return hashCode;
}
}
重写hashCode的情况下,只要自定义对象的属性值都是相等的,计算出来的哈希值也是相等的。
(3)重写hashCode方法和equals方法
hashCode方法的作用上面已经说过了,这里主要看一下 equals 方法
equals方法重写规则:
1.自反性
对于任何非 null 的 x
x.equals(x) 必须返回 true
2.对称性
对于任何非 null 的 x、y
如果y.equals(x)返回 true
x.equals(y)必须返回 true
3.传递性
对于任何非 null 的 x、y、z
如果x.equals(y)、y.equals(z)返回 true
那么x.equals(z)必须返回 true
4.一致性
对于任何非 null 的 x、y
只要 equals 的比较操作在对象中所用的信息没有被修改
x.equals(y)的结果就不会变
hashCode和eqauls方法说明:
hashCode只用于决定一个元素存储在哪个位置
equals方法用于判断两个元素是否一致,如果元素相同就覆盖,不相同,就放进桶中
public class Person {
private int age;
private float height;
private String name;
public Person(int age, float height, String name) {
super();
this.age = age;
this.height = height;
this.name = name;
}
@Override
/**
* 比较两个对象是否相等
*/
public boolean equals(Object obj) {
if(this == obj) return true;
if(obj == null || obj.getClass() != getClass()) return false;
Person person = (Person)obj;
return person.age == age
&& person.height == height
&& person.name==null ? name==null : person.name.equals(name);
// 传入name若为空,则当前对象name也必须为空才为 true
// 传入name若不为空,则调用equals方法比较即可
}
@Override
public int hashCode() {
int hashCode = Integer.hashCode(age);
hashCode = hashCode * 31 + Float.hashCode(height);
hashCode = hashCode * 31 + (name!=null ? name.hashCode() : 0);
return hashCode;
}
}
(4) hashCode和 equals总结
其实搞明白hashCode和equals的作用就行了,二者的功能不同,这两个方法是决定了如何将一个元素存储到HashMap这种结构中;
- HashMap是线性表,hashCode决定了元素存放的index;
- equals决定了两个元素是否相同;
1.若只重写 hashCode
如果只重写hashCode,当两个相同的kv对放入map,k1、k2 哈希值必然相等,则放入同一个桶中,然后会用equals方法比较 key内容是否相同;由于equals 默认比较地址,k1、k2地址不同,不为同一 key,因此 map放入了两个内容相同的key;
2.若只重写 equals
没有重写 hashCode,两个相同的kv放入map,k1、k2 哈希值大概率不相等(有极小可能相等)
一般情况下,k1、k2哈希值不相等,都不用比较内容了,就直接放进map了
所以:
同时重写hashCode和equals这两个方法就是为了保障哈希表中不存在key相同的元素!