数据分析——算法——K-means聚类(天池:汽车产品聚类分析)
K-means聚类
目录
K-means聚类
1 简介
2 Python实战
1 简介
原理:通过计算不同样本间的距离来判断他们的相近关系的,相近的就会放到同一个类别中去。
适用数据:数值数据
优点:思想简单,容易实现,可解释度比较强
缺点:对噪音和异常点比较的敏感。k-means是在做凸优化,因此处理不了非凸的分布,对于条形或不规则形状的数据,效果较差。如果两个类别距离比较近,k-means的效果也不会太好。初始中心点的选择以及k值的选择对结果影响较大,可能每次聚类结果都不一样。结果可能只是局部最优而不是全局最优
2 Python实战
数据集:天池学习赛数据集——汽车产品聚类分析(有兴趣的同学可以直接参赛学习一下)
任务:对该汽车数据进行聚类分析,并找到vokswagen汽车的相应竞品。
数据介绍:car_price.csv,数据包括了205款车的26个字段
| 1 | Car_ID | Unique id of each observation (Interger) |
|---|---|---|
| 2 | Symboling | Its assigned insurance risk rating, A value of +3 indicates that the auto is risky, -3 that it is probably pretty safe.(Categorical) |
| 3 | carCompany | Name of car company (Categorical) |
| 4 | fueltype | Car fuel type i.e gas or diesel (Categorical) |
| 5 | aspiration | Aspiration used in a car (Categorical) |
| 6 | doornumber | Number of doors in a car (Categorical) |
| 7 | carbody | body of car (Categorical) |
| 8 | drivewheel | type of drive wheel (Categorical) |
| 9 | enginelocation | Location of car engine (Categorical) |
| 10 | wheelbase | Weelbase of car (Numeric) |
| 11 | carlength | Length of car (Numeric) |
| 12 | carwidth | Width of car (Numeric) |
| 13 | carheight | height of car (Numeric) |
| 14 | curbweight | The weight of a car without occupants or baggage. (Numeric) |
| 15 | enginetype | Type of engine. (Categorical) |
| 16 | cylindernumber | cylinder placed in the car (Categorical) |
| 17 | enginesize | Size of car (Numeric) |
| 18 | fuelsystem | Fuel system of car (Categorical) |
| 19 | boreratio | Boreratio of car (Numeric) |
| 20 | stroke | Stroke or volume inside the engine (Numeric) |
| 21 | compressionratio | compression ratio of car (Numeric) |
| 22 | horsepower | Horsepower (Numeric) |
| 23 | peakrpm | car peak rpm (Numeric) |
| 24 | citympg | Mileage in city (Numeric) |
| 25 | highwaympg | Mileage on highway (Numeric) |
| 26 | price(Dependent variable) | Price of car (Numeric) |
数据集以及源码下载:链接:https://pan.baidu.com/s/1yGpMJIu_vS31GjM8mc_8UA 提取码:5n6x
代码以及结果展示:
import pandas as pd
# 数据加载
data = pd.read_csv('./car_price.csv')
data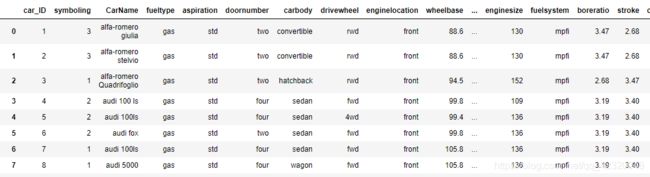
# 使用KMeans进行聚类,导入库
from sklearn.cluster import KMeans
#预处理
from sklearn import preprocessing
from sklearn.preprocessing import LabelEncoder
import pandas as pd
#矩阵运算
import numpy as np# 建立训练集
train_x = data[["car_ID","symboling","CarName", "fueltype", "aspiration", "doornumber",
"carbody", "drivewheel", "enginelocation", "wheelbase", "carlength","carwidth",
"carheight", "curbweight", "enginetype", "cylindernumber", "enginesize","fuelsystem",
"boreratio", "stroke", "compressionratio", "horsepower", "peakrpm","citympg",
"highwaympg", "price"]]
train_x#将非数值字段转化为数值
le = LabelEncoder()
columns = ['CarName','fueltype','aspiration','doornumber','carbody','drivewheel','enginelocation','enginetype','cylindernumber','fuelsystem']
for column in columns:
#LabelEncoder().transform将标签转换为归一化的编码。fit_transform安装标签编码器并返回编码的标签。
train_x[column] = le.fit_transform(train_x[column])
train_x
# 规范化到 [0,1] 空间
min_max_scaler=preprocessing.MinMaxScaler()
#MinMaxScaler()将每个要素缩放到给定范围,拟合数据,然后对其进行转换。
train_x=min_max_scaler.fit_transform(train_x)
pd.DataFrame(train_x).to_csv('temp.csv', index=False)#选择聚类组数
import matplotlib.pyplot as plt
sse = []
for k in range(1, 11):
kmeans = KMeans(n_clusters=k)
kmeans.fit(train_x)
# 计算inertia簇内误差平方和
sse.append(kmeans.inertia_)
x = range(1, 11)
#将图像嵌入在结果中
%matplotlib inline
plt.xlabel('K')
plt.ylabel('SSE')
plt.plot(x, sse, 'o-')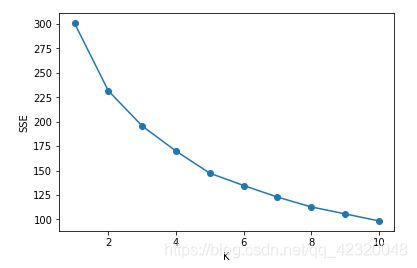
# 使用KMeans聚类,分成4类
kmeans = KMeans(n_clusters=5)
kmeans.fit(train_x) # 也可以直接fit+predict
#predict计算聚类中心并预测每个样本的聚类索引。
predict_y = kmeans.predict(train_x)
predict_y

# 合并聚类结果,插入到原数据中,axis: 需要合并链接的轴,0是行,1是列
result = pd.concat((data,pd.DataFrame(predict_y)),axis=1)
# 将结果列重命名为'聚类结果'
result.rename({0:u'聚类结果'},axis=1,inplace=True)
result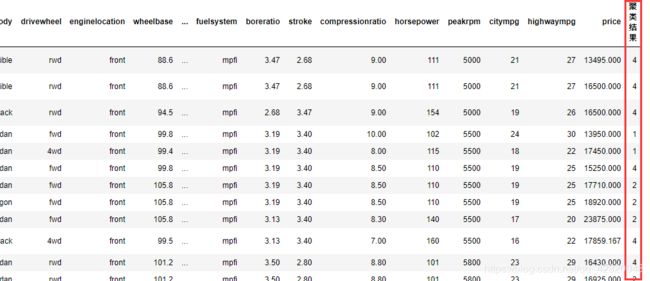
# 找出vokswagen汽车的聚类结果
label = result[result.CarName.str.contains('vokswagen')]['聚类结果']
label
#以下此段仅为练习,可忽略。多个关键词搜索,join() 方法用于将序列中的元素(必须是str)以指定的字符连接生成一个新的字符串。
List = ['vokswagen','volkswagen']
mask = result.CarName.str.contains('|'.join(List))
selected_data = result[mask]
selected_data![]()
# Vokswagen 轿车 竞品按价格排序
#lambda 是为了减少单行函数的定义而存在的,lambda作为一个表达式,定义了一个匿名函数,上例的代码x为入口参数,x['聚类结果']==3and 'sedan' in x['carbody']为函数体,
#将函数应用到由各列或行形成的一维数组上。DataFrame的apply方法可以实现此功能。默认情况下会以列为单位,axis = 1以行为单位
#[[]]选择多列时用双括号
result[result.apply(lambda x : x['聚类结果'] ==3 and 'sedan' in x['carbody'],axis = 1)][['CarName',"wheelbase", "price",'horsepower','carbody','fueltype','聚类结果']].sort_values('price',ascending = False)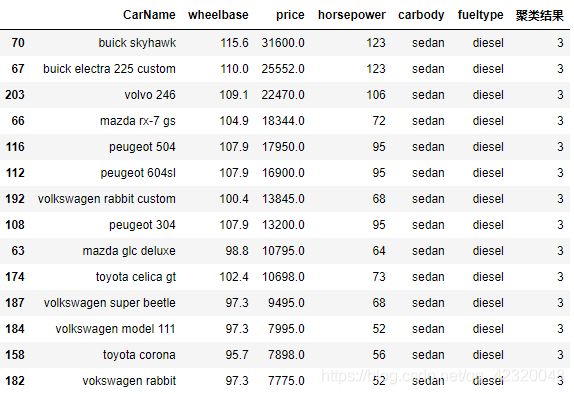
# Vokswagen wagon 竞品按价格排序
result[result.apply(lambda x : x['聚类结果'] ==3 and 'wagon' in x['carbody'],axis =1)][['CarName',"wheelbase", "price",'horsepower','carbody','fueltype','聚类结果']].sort_values('price',ascending = False)
#显示竞品车总体聚类结果
benchmark = result[result['聚类结果']==3].CarName
print("竞品车如下所示")
print(benchmark)
注明:以上代码仅为学习,代码参考比赛论坛的某帖子,实名感谢,另外还有很多不完善的地方,大家可以提出,一起探讨。