数据分析面试题
文章目录
- 1 数理统计
-
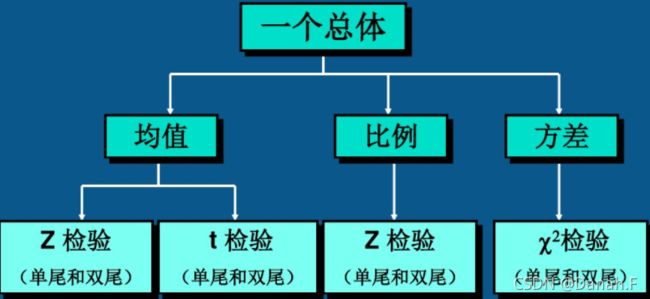
- 1.1.T检验和ANOVA都是用来看样本之间均值是否相等,但是两者又有什么区别呢?
- 1.2 说一个简单的场景,问用什么统计检验方法可以比较两个样本的均值是不是不同
- 1.3 有什么统计检验方法
- 1.4 假设检验流程描述
- 1.5 样本量n如何确定(需要啥数据)
- 1.6 男生点击率增加,女生点击率增加,总体为何减少?
- 1.7 参数估计与假设检验
- 1.8 置信度、置信区间
- 1.9 协方差与相关系数的区别和联系
- 1.10 中心极限定理
- 1.11 p值的含义
- 1.12 大数定律(Law of Largr Number)
- 1.13 PCA为什么要中心化?PCA的主成分是什么?
- 1.14 特征工程
- 1.15 假设检验结果判定的3种方式
- 1.16 方差齐性检验
- 1.17 t检验
- 1.18 查准率和查全率
- 1.19 相关系数的计算方法
- 1.20 切比雪夫定理
- 1.21 经验法则
- 1.22 极大似然估计
- 1.23 常见分布的期望与方差
- 1.24 正态总体参数的区间估计
- 2. 业务
-
- 2.1 介绍一下A/B测试
- 2.2 每周要提交周report,但建模可能不会每周都有结果,在没有成果的周,你的report要怎么写
- 2.3 数据挖掘项目怎么做的用户分类
- 2.4 如何判断滴滴出行业务的好坏
- 2.5 假设今天比昨天完单量下降10%,找到原因
- 2.6 询问打车app用的多还是外卖app用的多,如何预测
- 2.7 为微信设计日报 说完 那顺序应该如何排布
- 2.8 女装销量下降了分析原因(拆解+定位原因)
- 2.9 不用任何公开参考资料,估算今年新生儿出生数量。
- 2.10 类比到头条的收益,头条放多少广告可以获得最大收益,不需要真的计算,只要有个思路就行。
- 2.11 PP激活量的来源渠道很多,怎样对来源渠道变化大的进行预警?
- 2.12 某业务部门在上周结束了为期一周的大促,作为业务对口分析师,需要你对活动进行一次评估,你会从哪几方面进行分析?
- 2.13 现在有一个游戏测试的环节,游戏测试结束后需要根据数据提交一份PPT,这个PPT你会如何安排?包括什么内容?
- 2.14 怎么做恶意刷单检测?
- 2.15 app最重要的3-5个指标
- 2.16 微信的哪些指标重要
- 2.17 假如要策划一个暑期档活动,前期你会从哪些方面做准备呢?
- 2.18 怎么复盘一个项目
- 2.19 假如最近要上线一个电视剧,你能策划出什么推广活动
- 2.20 如何理解产品经理
- 2.21 归因分析
- 2.22 数据分析步骤
- 2.23 数据分析的作用
- 2.24 数据分析报告
- 2.25 用户画像怎么做,选择什么属性
- 2.26 熟悉什么模型,讲一下(RFM模型)
- 2.27 Python基础数据类型有哪些
- 2.28 数据分析能力
- 2.29 数据分析思维
- 2.30新用户流失和老用户流失有什么不同
- 2.31 识别作弊用户
- 2.32 常用模型
- 2.33 贝壳如果去新的城市扩张,需要看哪些指标
- 2.34 若贝壳要进入一个新的城市要如何去估计这个城市的需求量
- 2.35 滴滴数据和贝壳数据的区别
- 2.36 为客户推荐房源应该怎么分析
- 2.37 估计某月某地区二手房的成交量
- 2.38 ‘三孩’政策对房地产的影响
- 2.39 AB测试的流程
- 2.40 如果订单页面卡顿怎么定位问题
- 2.41 A/B测试的流程
- 3. 机器学习
-
- 3.1 知道哪些机器学习算法
-
- 线性回归
- 逻辑回归
- KNN分类
- 支持向量机
- SVM算法的优缺点
- 人工神经网络
- K-means聚类
- K-means的k如何选择
- 递归神经网络(RNN)
- 线性判别分析
- 朴素贝叶斯
- 集成学习
- 决策树(Decision Tree)
- 随机森林(Random Rorest)
- Bagging
- Boosting
- GBDT
- XGBoost与GBDT的区别
- AdaBoost(Adaptive Boosting,自适应增强)
- GBM与XGBoost的区别
- SVM/GBM/XGBoost的共同点和比较
- XGBoost与GBDT的有什么不同
- XGBoost为什么可以并行训练?
- 随机森林(RF)和GBDT的区别
- XGBoost防止过拟合的方法?
- XGBoost为什么这么快?
- GBDT如何用于分类
- 3.2 R和Python中有哪些机器学习包
- 3.3 针对类别不平衡要怎么处理
- 3.4 用过什么激活函数
- 用过什么损失函数
- 数据的准备过程完整性真实性
- 特征工程指标选取降维
- 4. BI和Excel工具
-
- 4.1 BI
-
- 4.1.1 Tableau和Power BI是自己学的还是实习用到,你觉得这两种有什么优缺点
- 4.1.3 怎么搭建报表体系
- 4.2 Excel
- 4.3 SPSS
-
- 4.3.1 SPSS有哪些功能
- 5. python
-
- 5.1 python用什么库实现矩阵乘法(numpy里面的不同库对比一下,matmul,dot等
- 5.2 python内存管理
- 5.3 C++和python的区别
- 5.4 C++、Java的联系与区别,包括语言特性、垃圾回收、应用场景等(java的垃圾回收机制)
- 5.5 面向对象的三大特性
- 5.6 深拷贝和浅拷贝的区别(举例说明深拷贝的安全性)
- 5.7 调试程序的方法
- 5.5 在Python中如何实现多线程
- 5.6 在Python中是如何管理内存的
- 5.7 请解释使用args和*kwargs的含义
- 5.8 Python中的实例方法、静态方法和类方法有什么区别
- 5.9 你最喜欢Python的哪个库
- 5.10 你在Python中使用了哪些ORM
- 5.11 any()和all()如何工作
- 5.12 .什么是lambda函数?它有什么好处?
- 5.13 Python里面如何拷贝一个对象?(赋值,浅拷贝,深拷贝的区别)
- 5.14 Python中pass语句的作用是什么?
- 5.15 如何用Python来进行查询和替换一个文本字符串?
- 5.16 Python里面match()和search()的区别?
- 5.17 Python里面如何生成随机数?
- 5.18 单引号,双引号,三引号的区别
- 5.19 什么是__init__?
- 5.20 如何在Python中实现多线程?
- 5.21 python列表解析式,取0到100之间可以整除3的数
- 5.22 Pyhton apply 和map的区别
- 5.23 字典值的获取
- 5.24 and、or和&、|
- 5.25 数组和链表的区别
- 5.26 数组和列表的区别
- 5.27 栈和队列的区别
- 5.28 用栈怎么实现一个队列?
- 5.29 进程、线程和协程
- 5.30 zip函数
- 5.31 python2和python3的区别
- 6. SQL
-
- 6.1 主键和索引的区别
- 6.2 短索引的使用场景
- 6.3 数据库的索引类型
- 6.4 数据库的索引优缺点(重点)
- 6.5 什么时候使用索引,什么时候不能使用索引(重点)
- 6.6 MySQL怎么建立索引,怎么建立主键索引,怎么删除索引?
- 6.7 数据库中事务的ACID
- 6.8 事务的并发问题
- 6.9 数据库事务、隔离级别
- 6.10 索引的底层实现(为什么要用B+树,为什么不用红黑树和B树)
- 6.11 最左前缀匹配
- 6.12 MySQL的存储引擎
- 6.13 数据的锁的种类
- 6.14 什么是共享锁和排他锁
- 6.15 乐观锁和悲观锁
- 6.16 MySQL的优化,高并发的解决方案(高频,索引优化,性能优化)
- 6.16 MySQL中查询所有数据库
- 6.17 数据库连接池的作用
- 6.18 数据库的聚合函数有哪些?
- 6.19 数据库里如果select A, B from 表 group by A 可以么?
- 6.20 union和union all的区别
- 6.21 limit 2,1和limit 2 offset 1的区别是什么?
- 6.22 sql中过滤条件放在on和where中的区别
- 6.23 普通聚合函数vS窗口函数
- 6.24数据库里同时对两个字段排序,一个升序一个降序,可以么。
- 6.25 N层满二叉树(完全二叉树)的节点个数是多少?
- 6.26 关系型和非关系型数据库的区别(低频)
- 6.27 数据库的范式
- 6.28 in和exists的区别
- 6.29 增删查改
- 6.30 模糊查询与通配符
- 6.31 select * from employees; 和 select * from employees where commission_pct like '%%' and last_name like '%%';结果是否一样?并说明原因。
- 6.32 字符、时间、流程控制函数
- 6.33 SQL语句分类
- 6.34 常用的三种插入数据的语句
- 6.35 经典面试题:delete pk truncate
- 6.36 MyISAM 与 InnoDB 区别:
- 6.37 计算中位数
- 6.38 水平切分、垂直切分
- 6.39 索引失效的情况
- 6.40 数据库索引结构
- 6.41 B+树
- 6.42 数据库的分页
- 6.43 数据库的分表
- 6.44 数据拷贝,复制
- 6.45 数据库存储过程
- 6.46 在用户量不断增加,点击次数或查询次数非常大且越来越大时,设计数据库应该怎么考虑
- 6.47 如果正常按索引查询结果发现数据库依然是逐个比较查询的,可能是什么原因呢
- 6.48 sql查询慢的原因
- 6.49 索引的设计原则
- 6.50 mysql执行计划
- 6.51 MySQL中int(10)和char(10)的区别?
- 6.52 truncate、delete与drop区别?
- 6.53 sql执行过程
- 7. 数据挖掘
- 8. linux
-
- 8.1 Linux 压缩和打包命令
-
- 打包和压缩
-
- 解压
- 8.2 查看文件
- 8.3 查看后台进程
- 8.4 删除当前文件夹下2018年-2019年文件命令
- 8.5 修改文件权限命令、有哪些权限
- 9.计算机网络
-
- 9.1 http协议与TCP的区别与联系
- 9.2 http的状态码403 201等等是什么意思
- 9.3 http和https的区别,由http升级为https需要做哪些操作
- 9.4 一个机器能够使用的端口号上限是多少,为什么?可以改变吗?那如果想要用的端口超过这个限制怎么办?
- 9.5 单条记录高并发访问的优化
- 9.6 一个ip配置多个域名,靠什么识别?
- 9.7 OSA七层协议和五层协议,分别有哪些
- 10. 大数据
-
- 10.1 介绍一下Hadoop
- 10.2 说一下MapReduce的运行机制
- 10.3 介绍一下spark
- 11. 智力题
-
- 11.1 100层楼,只有2个鸡蛋,想要判断出那一层刚好让鸡蛋碎掉,给出策略(滴滴笔试中两个铁球跟这个是一类题)
- 11.2 毒药问题,1000瓶水,其中有一瓶可以无限稀释的毒药,要快速找出哪一瓶有毒,需要几只小白鼠
- 11.3 先手必胜策略问题:100本书,每次能够拿1-5本,怎么拿能保证最后一次是你拿
- 11.4 放n只蚂蚁在一条树枝上,蚂蚁与蚂蚁之间碰到就各自往反方向走,问总距离或者时间。
- 11.5 瓶子换饮料问题:1000瓶饮料,3个空瓶子能够换1瓶饮料,问最多能喝几瓶
- 11.6 有一个天平,九个砝码,一个轻一些,用天平至少几次能找到轻的?
- 11.7 有十组砝码每组十个,每个砝码重10g,其中一组每个只有9g,有能显示克数的秤最少几次能找到轻的那一组砝码?
- 11.8 在24小时里面时针分针秒针可以重合几次
- 11.9 赛马
- 11.10 烧 香/绳子/其他
- 11.11 掰巧克力问题NM块巧克力
- 11.12 生成随机数问题
- 12. HR面
5、6、7、8、9 里面有很多是开发才会考的,只是积累,可根据需要查看。
1 数理统计
1.1.T检验和ANOVA都是用来看样本之间均值是否相等,但是两者又有什么区别呢?
卡方检验是用来看分类变量之间有没有相关性。

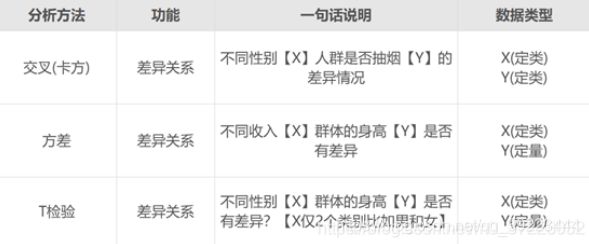
- 其实核心的区别在于:数据类型不一样。如果是定类和定类,此时应该使用卡方分析;如果是定类和定量,此时应该使用方差或者T检验。
- 方差和T检验的区别在于,对于T检验的X来讲,其只能为2个类别比如男和女。如果X为3个类别比如本科以下,本科,本科以上;此时只能使用方差分析。
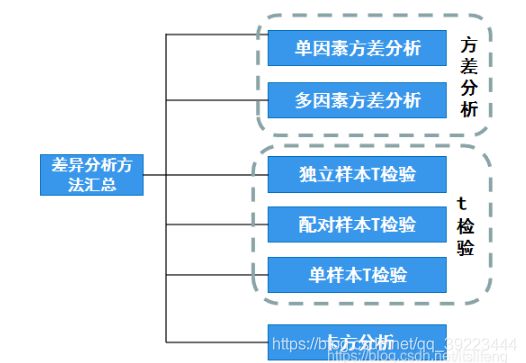
方差分析
从理论上讲,方差分析有两个前提条件,一是因变量Y需要满足正态性要求,二是满足方差齐检验。
方差不齐时可使用‘非参数检验’,同时还可使用welch 方差,或者Brown-Forsythe方差,非参数检验是避开方差齐问题
1.2 说一个简单的场景,问用什么统计检验方法可以比较两个样本的均值是不是不同
t 检验,两样本的 t 检验,可以检验两样本所代表的总体均数是否相等。
1.3 有什么统计检验方法
t 检验,方差分析和卡方检验
1.4 假设检验流程描述
- 建立假设统计量,给出拒绝域的形式
- 确定检验水准
- 计算p值
- 得出结论
1.5 样本量n如何确定(需要啥数据)

确定样本量:
- 知道被测试的参数分布吗?知道,均值是一个还是两个?一个,知道方差,正态分布;不知道,t分布。均值是两个,知道方差吗?知道,独立,正态分布,不独立,也是正态分布;不知道,独立,很难找到,不独立,t分布。
- 不知道被测试的分布,如果参数的先验可以得到或者可以估计,就估计参数,均值之类的。
1.6 男生点击率增加,女生点击率增加,总体为何减少?
- 因为男女的点击率可能有较大差异,同时低点击率群体的占比增大。
- 如原来男性20人,点击1人;女性100人,点击99人,总点击率100/120。
- 现在男性100人,点击6人;女性20人,点击20人,总点击率26/120。
- 即那个段子“A系中智商最低的人去读B,同时提高了A系和B系的平均智商。”
1.7 参数估计与假设检验
- 用样本统计量去估计总体的参数。
- 参数估计和假设检验是统计推断的两个组成部分,它们都是利用样本对总体进行某种推断,但推断的角度不同。
- 参数估计讨论的是用样本估计总体参数的方法,总体参数μ在估计前是未知的。
- 而在假设检验中,则是先对μ的值提出一个假设,然后利用样本信息去检验这个假设是否成立。
1.8 置信度、置信区间
- 置信区间是我们所计算出的变量存在的范围, 置信度就是我们对于这个数值存在于我们计算出的这个范围的可信程度。
- 举例来讲,有95%的把握,真正的数值在我们所计算的范围里。
- 在这里,95%是置信水平,而计算出的范围,就是置信区间。
- 如果置信度为95%, 则抽取100个样本来估计总体的均值,由100个样本所构造的100个区间中,约有95个区间包含总体均值。
1.9 协方差与相关系数的区别和联系
协方差: 协方差表示的是两个变量的总体的误差,这与只表示一个变量误差的方差不同。如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值,另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值。如果两个变量的变化趋势相反, 即其中一个大于自身的期望值,另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。
![]()
相关系数: 研究变量之间线性相关程度的量,取值范围是[-1,1]。相关系数也可以看成协方差: 一种剔除了两个变量量纲影响、标准化后的特殊协方差。
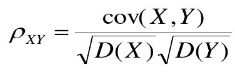
1.10 中心极限定理
定理: 假设从均值为 μ \mu μ,方差为 σ 2 \sigma^2 σ2的有限的任意一个总体中抽取样本量为n的样本,当n充分大时,样本的均值的抽样分布就会服从均值为 n μ n\mu nμ,方差为 n σ 2 n\sigma^2 nσ2的正态分布。
在分析领域,我们每天都会遇到各种各样的数据,而源数据的分布并不总是被我们所知道的,但是,因为我们了解中心极限定理,所以我们甚至不需要关心源数据的分布,因为我们总是可以得到正态分布。
中心极限定理的作用:用样本数据估计总体参数(区间估计)。
均值正态分布的实际含义:
- 我们可以用均值的正态分布来分配置信区间。
- 我们可以进行T检验(即两个样本均值之间是否存在差异)
- 我们可以进行方差分析(即3个或更多样本的均值之间是否存在差异)
1.11 p值的含义
基本原理只有3个:1、一个命题只能证伪,不能证明为真 2、在一次观测中,小概率事件不可能发生 3、在一次观测中,如果小概率事件发生了,那就是假设命题为假
证明逻辑就是:我要证明命题为真->证明该命题的否命题为假->在否命题的假设下,观察到小概率事件发生了->否命题被推翻->原命题为真->搞定。
结合这个例子来看:证明A是合格的投手→证明“A不是合格投手”的命题为假 →观察到一个事件(比如A连续10次投中10环),而这个事件在“A不是合格投手”的假设下,概率为p, 小于0.05->小概率事件发生,否命题被推翻。
可以看到p越小→这个事件越是小概率事件→否命题越可能被推翻→原命题越可信
1.12 大数定律(Law of Largr Number)
大数定律:每次从总体中随机抽取1个样本,这样抽取很多次后,样本的均值会趋近于总体的期望。也可以理解为:从总体中抽取容量为n的样本,样本容量n越大,样本的均值越趋近于总体的期望。当样本容量极大时,样本均值
![]()
1.13 PCA为什么要中心化?PCA的主成分是什么?
因为要算协方差。
单纯的线性变换只是产生了倍数缩放,无法消除量纲对协方差的影响,而协方差是为了让投影后方差最大。
在统计学中,主成分分析(PCA)是一种简化数据集的技术。它是一个线性变换。这个变换把数据变换到一个新的坐标系统中,使得任何数据投影的第一大方差在第一个坐标(称为第一主成分)上,第二大方差在第二个坐标(第二主成分)上,依次类推。
主成分分析经常用减少数据集的维数,同时保持数据集的对方差贡献最大的特征。这是通过保留低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面。但是,这也不是一定的,要视具体应用而定。
主成分分析的原理是设法将原来变量重新组合成一组新的相互无关的几个综合变量,同时根据实际需要从中可以取出几个较少的综合变量尽可能多地反映原来变量的信息的统计方法叫做主成分分析或称主分量分析,也是数学上处理降维的一种方法。主成分分析是设法将原来众多具有一定相关性(比如P个指标),重新组合成一组新的互相无关的综合指标来代替原来的指标。
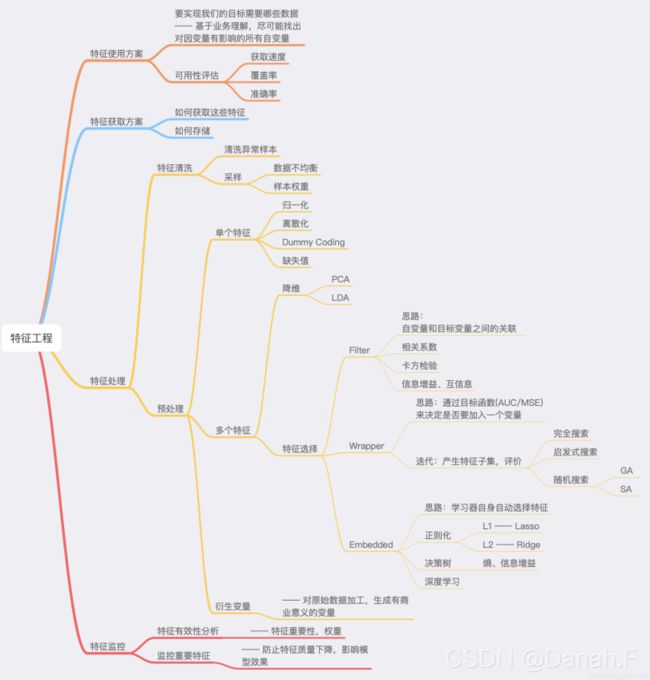
1.14 特征工程
1.15 假设检验结果判定的3种方式
- 计算统计量 z,t,卡方,当检验统计量的值落入拒绝域内时,拒绝原假设
- 计算p值,p<α时拒绝原假设
- 计算1-α的置信区间,均值落入置信区间,接受原假设。
1.16 方差齐性检验
对控制变量不同水平下各观测变量总体方差是否相等进行检验。
1.17 t检验
t检验通常分为三种,分别是单样本t检验、双样本t检验和配对样本t检验。
无论哪种t检验,都有以下的基本前提条件:
样本数据符合正态分布
各个样本之间是独立的
步骤:
提出原假设和备择假设
构造t统计量
计算t统计量
对于得到的p值进行分析,p大于0.05则接受原假设,反之接受备择假设。
单样本t检验:对某个样本的均值进行检验,比较是否和总体的均值(自己定)是否存在差异。使用ttest_1samp函数实现,第一个参数为样本数据,第二个参数为总体均值。
双样本t检验:是针对两组不相关样本(各样本量可以相等也可以不相等),检验它们在均值之间的差异。对于该检验方法而言,我们首先要确定两个总体的方差是否相等,如果不等,先利用levene检验,检验两总体是否具有方差齐性,再使用stats.ttest_ind(A,B,equal_var=True) 进行独立样本t检验
配对t检验:是针对同一组样本在不同场景下均值之间的差异。检验的是两配对样本差值的均值是否等于0,如果等于0,则认为配对样本之间的均值没有差异,否则存在差异。选择实现配对样本t检验的stats.ttest_rel(A0,A1) 函数(两组样本作为输入)
1.18 查准率和查全率
查准率(Precision ratio,简称为P),是指检出的相关文献数占检出文献总数的百分比。查准率反映检索准确性,其补数就是误检率。查全率(Recall ratio,简称为R),是指检出的相关文献数占系统中相关文献总数的百分比。查全率反映检索全面性,其补数就是漏检率。
查全率=(检索出的相关信息量/系统中的相关信息总量)*100%。查准率=(检索出的相关信息量/检索出的信息总量)*100%。利用这两个量化指标,也可以对信息检索系统的性能水平进行评价。要评价信息检索系统的性能水平,就必须在一个检索系统中进行多次检索。每进行一次检索,都计算其查准率和查全率,并以此作为坐标值,在平面坐标图上标示出来。通过大量的检索,就可以得到检索系统的性能曲线。
实验证明,在查全率和查准率之间存在着相反的相互依赖关系–如果提高输出的查全率,就会降低其查准率,反之亦然。对查全率和查准率之间的关系理解,如果提高了查全率,也就说明中间的阴影部分变大了同时系统中的相关文献总量应该不变。但准确率提高跟检出的总数相关,实际是要想查到更多相关的,那么检出的不相干也更多,即图中浅蓝色部分也变大,导致准确率变低。
1.19 相关系数的计算方法
- 斯皮尔曼等级相关系数(spearman相关系数)
Cov(X,Y)为X与Y的协方差,Var[X]为X的方差,Var[Y]为Y的方差
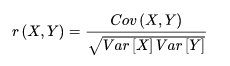
2. 马修斯相关系数(Matthews correlation coefficient)
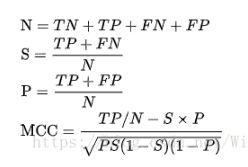
马修斯相关系数是问题及其对偶的回归系数的几何平均数。
1.20 切比雪夫定理
切比雪夫定理(Chebyshev’s theorem):适用于任何数据集,而不论数据的分布情况如何。
所有数据中,至少有3/4(或75%)的数据位于平均数2个标准差范围内。
所有数据中,至少有8/9(或88.9%)的数据位于平均数3个标准差范围内。
所有数据中,至少有24/25(或96%)的数据位于平均数5个标准差范围内
1.21 经验法则
经验法则(Empirical Rule):需要数据符合正态分布。
大约68%的数据值与平均数的距离在1个标准差之内;
大约95%的数据值与平均数的距离在2个标准差之内;
几乎所有的数据值与平均数的距离在3个标准差之内;
1.22 极大似然估计
利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。
1.23 常见分布的期望与方差

1.24 正态总体参数的区间估计


2. 业务
2.1 介绍一下A/B测试
AB测试,是验证假设的好方法。
大家在实验中常用到实验思维,根据实验思维,我们要更好的进行归因实验,通常要满足以下条件:
* 对照:有其他对照组作为对比,就能真正看出来效果。而且不同组间的效果差异要足够明显,才能验证我们的判断
* 随机:为了排除实验条件以外的干扰因素,我们需要确保两个组的用户是随机选取的,这是为了排除用户差异对实验结果的影响
* 大样本:这里的样本量是指数据量,包括用户、行为和时间跨度,样本量越大,越容易排除个体差异的影响,也更容易验证统计上的显著性
应用时要注意平台,不同平台的环境、用户、产品特点不同,要结合实际。
**实践:**
在企业里,一般做AB测试有3块工作要做。分别是流量分配、实验设计和数据统计。
**流量分配**
产品快速迭代时,会有很多AB测试需要同时做,而产品的流量又是有限的,因此我们需要进行充分的流量切分。分流的逻辑如下图所示:
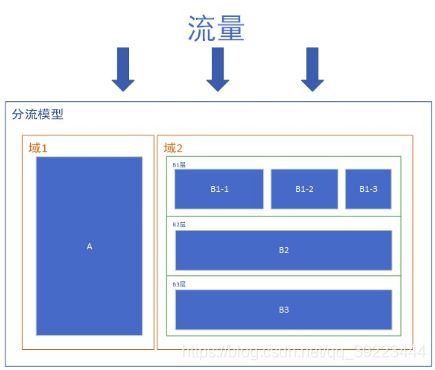

域: 域是指整体流量的分区,域之间是互斥的。比如按照用户ID尾号奇偶性,将整体流量分为了1、2两个域,这个时候域1+域2=100%的流量,不同域之间的流量不会重叠。划分域的目的,是为了进行完全纯净的分区,更好的进行互不干扰的实验测试。
层: 层是指某个域内全部流量的一个观测角度。比如对同一个域内流量,你可以按照用户ID尾号进行细分,也可以按照用户ID首号码进行细分。不同的细分方法,对应的也就是不同的层。不难理解,层与层之间的关系是正交的,即彼此互不影响,相互独立。
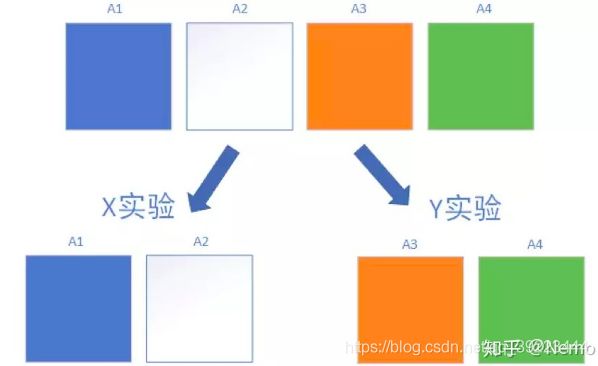
桶: 在每个层中,我们使用独立的Hash函数对用户进行取模,将用户均匀的分配至N个实验桶中。桶与桶之间是互斥的。如下图所示,在A层中有A1/A2/A3/A4这4个桶,他们彼此互斥,互不重叠,彼此加和后等于层内的全部流量。我们可以用A1/A2进行X实验,同时用A3/A4进行Y实验
实验设计:
1.单因素实验设计
所谓单因素实验设计,是指实验中只有一个影响因素变量,其他的内容都保持不变的实验方法。举个例子,两个实验组,一组用广告图A,一组用广告图B,这两个组进行实验对比,最后发现A组比B组效果好,那么我们就可以认为这是A广告图的作用。
2.多因素实验设计
多因素实验设计,是指实验中有多个影响因素变量。比如你想同时测试广告图(AB)和广告弹出方式(AB)对转化率的影响,这里面有两个变量,对应的有4种组合条件:
广告A,弹出方式A
广告A,弹出方式B
广告B,弹出方式A
广告B,弹出方式B
多因素实验设计的好处在于,除了可以检测同一个变量、不同实验条件之间的差异之外,还能对变量之间的交互效果进行检验。用上个例子做说明,如果在单因素AB实验里,我们发现广告A比广告B的效果好,弹出方式A比弹出方式B的效果好,但是广告A+弹出方式A的组合情况却不是最好的,因为他们之间的组合,产生了化学作用。这种情况下,就必须使用多因素实验设计来做。
数据分析:
1.考虑空跑期差异
一个不用统计的简单分析方法,是考虑空跑期差异。所谓空跑期,就是指什么策略也不做,纯看两个组本身的固有差异,作为判断的基础。而后用实验期的差异减去空跑期差异,就得到了实验的真实收益。具体来说分这么几个步骤:
看两个组在空跑期的数据差异(百分比),判断组间差异基础
看两个组在实验期的数据差异(百分比),判断实验差异
用实验期的差异减去空跑期的差异,得到实验真实收益
2.统计检验:
不考虑空跑期差异,而是直接看实验期里两个组的明细数据,输入到统计软件中进行统计分析,看是否显著(P<0.05)。如果显著,说明两组有明显差异
常用的统计分析有两种:
独立样本T检验
方差分析


5%就是在统计学里称作 α , 它代表着我们这个试验结果的置信水平。与这个置信水平相对应的就是置信区间的置信度,由 1- α 得出,所以你在这里看到如果 α 是0.05,那置信度就是0.95,也就是说,如果我们容许自己出错的几率是5%,那我们将得到一个有 95% 的可能性包含真实的总体均值区间范围,如果你把这个 α 调整成0.07,那你的置信区间的置信度将变成93%。
由于 α 是我们自己设置的,那么当然需要通过数据去验证一下,这个通过计算出来的值就是 p-value , p 的定义就是,如果两个版本无差异的前提下,我们得到这个试验数据的概率。
p <= α 则意味着我们的测试得到了统计显著的结果, 因为只有我们得到的这个 p 的概率越小,我就可以越有信心的地根据小概率事件不会发生的判断依据,从而推翻原假设,接受备择假设。
计算比例,用z检验。
2.2 每周要提交周report,但建模可能不会每周都有结果,在没有成果的周,你的report要怎么写
分析没有结果的原因。
2.3 数据挖掘项目怎么做的用户分类
用户划分这样的分类问题的知识和理解
2.4 如何判断滴滴出行业务的好坏
2.5 假设今天比昨天完单量下降10%,找到原因
- 首先采用“两层模型”分析:对用户进行细分,包括新老、渠道、活动、画像等多个维度,然后分别计算每个维度下不同用户的次日留存率。通过这种方法定位到导致留存率下降的用户群体是谁。
- 对于目标群体次日留存下降问题,具体情况具体分析。具体分析可以采用“内部-外部”因素考虑。
-
a:内部因素分为获客(渠道质量低、活动获取非目标用户)、满足需求(新功能改动引发某类用户不满)、提活手段(签到等提活手段没达成目标、产品自然使用周期低导致上次获得的大量用户短期内不需要再使用等);
-
b:外部因素采用PEST分析(宏观经济环境分析),政治(政策影响)、经济(短期内主要是竞争环境,如对竞争对手的活动)、社会(舆论压力、用户生活方式变化、消费心理变化、价值观变化等偏好变化)、技术(创新解决方案的出现、分销渠道变化等)。
-
2.6 询问打车app用的多还是外卖app用的多,如何预测
2.7 为微信设计日报 说完 那顺序应该如何排布
2.8 女装销量下降了分析原因(拆解+定位原因)
销量=用户*付费
划分维度,定位到真正发生变化的位置,
SWOT:天气变化,竞品优惠,外部渠道变化,用户偏好变化;自身产品,近期是否举办了活动。
新老用户,老用户消费了,新用户没有吸引到。
用户、产品、渠道
首先要定位到现象真正发生的位置,到底是谁的销售额变低了?这里划分的维度有: a. 用户(画像、来源地区、新老、渠道等) b. 产品或栏目 c. 访问时段
定位到发生位置后,进行问题拆解,关注目标群体中哪个指标下降导致网站销售额下降: a. 销售额=入站流量x下单率x客单价 b. 入站流量 = Σ各来源流量x转化率 c. 下单率 = 页面访问量x转化率 d. 客单价 = 商品数量x商品价格
确定问题源头后,对问题原因进行分析,如采用内外部框架: a. 内部:网站改版、产品更新、广告投放 b. 外部:用户偏好变化、媒体新闻、经济环境、竞品行为等.
2.9 不用任何公开参考资料,估算今年新生儿出生数量。
采用两层模型(人群画像x人群转化):新生儿出生数=Σ各年龄层育龄女性数量*各年龄层生育比率
从数字到数字: 如果有前几年新生儿出生数量数据,建立时间序列模型(需要考虑到二胎放开的突变事件)进行预测,找先兆指标,如婴儿类用品的新增活跃用户数量X表示新生儿家庭用户。Xn/新生儿n为该年新生儿家庭用户的转化率,如X2007/新生儿2007为2007年新生儿家庭用户的转化率。该转化率会随平台发展而发展,可以根据往年数量推出今年的大致转化率,并根据今年新增新生儿家庭用户数量推出今年估计的新生儿数量。
2.10 类比到头条的收益,头条放多少广告可以获得最大收益,不需要真的计算,只要有个思路就行。
收益 = 出价x流量x点击率x有效转化率 ,放广告的数量会提高流量,但会降低匹配程度,因此降低点击率。最大收益是找到这个乘积的最大值,是一个有约束条件的最优化问题。
- 提高单位溢价的方法:
(1)品牌打造获得长期溢价,但缺陷是需要大量前期营销投入;
(2)价格歧视,根据价格敏感度对不同用户采用不同定价。
- 销售量=流量x转化率,上述提高单位溢价的方法可能对流量产生影响,也可能对转化率产生影响。
收益 = 单价x流量x转化率,短期内能规模化采用的应该是进行价格歧视,如不同时间、不同商圈的价格不同,采取高定价,然后对价格敏感的用户提供优惠券等。
2.11 PP激活量的来源渠道很多,怎样对来源渠道变化大的进行预警?
如果渠道使用时间较长,认为渠道的app激活量满足一个分布,比较可能是正态分布。求平均值和标准差,对于今日数值与均值差大于3/2/1个标准差的渠道进行预警。
对于短期的新渠道,直接与均值进行对比。
2.12 某业务部门在上周结束了为期一周的大促,作为业务对口分析师,需要你对活动进行一次评估,你会从哪几方面进行分析?
(1) 确定大促的目的:拉新?促活?清库存?
(2) 根据目的确定核心指标。
(3) 效果评估:
a. 自身比较:活动前与活动中比较
b. 与预定目标比
c. 与同期其它活动比
d. 与往期同类活动比
(4)持续监控:
a. 检查活动后情况,避免透支消费情况发生
b. 如果是拉新等活动,根据后续数据检验这批新客的质量
2.13 现在有一个游戏测试的环节,游戏测试结束后需要根据数据提交一份PPT,这个PPT你会如何安排?包括什么内容?
这里可以套AARRR模型:
获取:我们的用户是谁?用户规模多大?
激活:游戏是否吸引玩家?哪个渠道获取的用户有质量(如次日留存高、首日停留时间长等)?
留存:用户能否持续留存?哪些用户可以留存?
转化:用户的游戏行为如何?能否进行转化?能否持续转化?
自传播:用户是否会向他人推荐该游戏?哪种方式能有效鼓励用户推荐该游戏?传播k因子是否大于1?
2.14 怎么做恶意刷单检测?
分类问题用机器学习方法建模解决,我想到的特征有:
商家特征:商家历史销量、信用、产品类别、发货快递公司等
用户行为特征:用户信用、下单量、转化率、下单路径、浏览店铺行为、支付账号
环境特征(主要是避免机器刷单): 地区、ip、手机型号等
异常检测: ip地址经常变动、经常清空cookie信息、账号近期交易成功率上升等
评论文本检测: 刷单的评论文本可能套路较为一致,计算与已标注评论文本的相似度作为特征
图片相似度检测: 同理,刷单可能重复利用图片进行评论
2.15 app最重要的3-5个指标
- 留存率
保留率是用户在初始安装后,在特定时间范围内,返回到APP的用户所占的百分比,保留率也是衡量应用程序“粘性”的指标之一。 您的应用程序对用户的价值越高,您的应用程序使用的频率就越高(被删除的可能性就越小)。在这些用户流失之前想办法提高他们的积极性。 - 流失率
衡量的是在指定时间段内(通常是每月测量)APP失去用户的比率。结合使用app的渠道原因,分析他们离开的原因。 - LTV(用户终身价值)
LTV可以说是所有数据指标中最重要的指标,因为它让你知道,你到底花了多少钱来获得一位新的用户。
要计算用户的LTV,这里有几个数据点,需要我们知道和了解一下。
收入: 这是一个简单的指标,即APP产生的所有收入,无论是APP广告,应用内购买,付费下载或订阅
活跃用户数: 这是对积极用户所用的定义。 这其中个人认为应该包括,用户在活跃了一段时间后处于非活动状态用户和尚未在APP中购买高级内容的用户。
每用户平均收入(ARPU): 跟踪ARPU是很容易做到的,因为它只是收入的生成,ARPU注重的是一个时间段内运营商从每个用户所得到的利润。很明显,高端的用户越多,ARPU越高。计算时,只需将收入除以给定时间段内的活跃用户数。 - 真实用户数
获取用户是推广的第一步。这个阶段你需要做的是①让App在十几秒内抓住你的用户②通过应用市场下载③通过广告渠道④找到适合自己的推广渠道。 - 盈利:目前国内开发者被证实可行的盈利方式包括应用内付费和依靠合作者的运营支付和广告平台这两种,做好了这些,平均转化成本和回报率提高了,盈利就实现了。
- 后续传播指数 后续传播的一个典型媒介就是社交网络,如果产品自身足够好,有很好的口碑。从自传播到再次获取新用户,应用运营会形成了一个螺旋式上升的轨道。而那些优秀的应用就很好地利用了这个轨道,不断扩大自 己的用户群体。
2.16 微信的哪些指标重要
- 文章初次打开率= 会话阅读渠道图文页阅读人数 / 全部图文页阅读人数
阅读人数可能包括转发分享阅读的人数,初次打开率除了可以衡量文章是否吸引人之外,还可以衡量粉丝的活跃度。如果初次打开率持续低于3%以下,可以视为粉丝活跃度极低。 - 转发分享率=分享转发次数 / 全部图文阅读人数
统计所有阅读过文章的人,有多大比例分享出去了。可以衡量文章内容质量。比较合理的转发分享率应该持续超过10%以上。 - 转发拉粉率 = 粉丝净增人数 / 分享转发次数
衡量每次转发能带来多少粉丝,优化的好,可以超过100%,如果低于20-30%,算是拉粉能力很差。 - 二次传播率=(转发阅读人数+朋友圈阅读人数) / 总阅读人数
二次传播率意味着文章通过朋友、群组、朋友圈的传播能力。如果二次传播率始终低于50%,说明用户对公众号的忠诚度很低。
2.17 假如要策划一个暑期档活动,前期你会从哪些方面做准备呢?
- 明确活动主题和目标
大概是首先要明确目标用户是谁,针对这个群体的行为习惯和爱好策划活动。 - 市场分析
竞争对手当前的活动行为分析,有没有推出类似的活动,思考如何创新 - 网站自身情况
网站本身的实际情况(包括活动的时间、预期投入的费用等),活动策划所需相关的宣传资源,人力资源,物力资源,包括涉及到的部门和人员。 - 吸收历史经验
此外可以向同事了解往年公司类似活动的方案和最终效果,吸取经验。
2.18 怎么复盘一个项目
取得了什么成果
有没有达到预期成果
那个环节好,之后可以借鉴,哪个环节还可以改进
- 回顾目标
当初行动的意图是什么?事件想要达到的目标是什么? - 评估结果
在这一步中,主要回答以下问题:
实际发生了什么事?
在什么情况下,是怎么发生的?
与目标相比,哪些地方做得好?哪些未达预期?
具体:(新用户:多少人注册、多少人付费、转化率
老用户:多少人回购、多少人流失、转化率) - 分析原因
这一步要回答的问题包括以下几个:
实际情况与预期有无差异?
如果实际情况与预期有差异,那么,为什么会出现这些差异?是由哪些因素造成?根本原因是什么?
如果实际情况与预期无差异,那么,成功的关键因素是什么? - 总结经验
这一步主要回答以下问题:
我们从过程中学到了什么新东西?
如果有人进行同样的行动,我会给他什么建议?
接下来我们该做什么?哪些是可以直接行动的?
2.19 假如最近要上线一个电视剧,你能策划出什么推广活动
- 电视剧买点:演员、导演;剧情,结合主旋律;
- 短视频平台宣传(剧集爆料,演员炒作、情节恶搞),软文(新闻、论坛、豆瓣),社交类(微信、微博、qq看点),搜索类,
- 主页宣传,卖点提炼
前期的分析:剧集内容的调研、受众人群的分析、类似题材或者频道的数据分析等;
策略的提出:分几个阶段推广、推广的步骤是什么、具体的要求有哪些等;
创意的策划:策划能增加人气的话题创意、视频创意、活动创意、事件创意等;
平台的选择:应该选择哪些渠道进行推广、哪些渠道搭配最好等;
效果的预估:预计能达到什么效果、多少受众观看、网页展示曝光如何等;
风险的评估:如果推广过程中出现意外(收视目标达不到、渠道出问题等)该怎么补救;
2.20 如何理解产品经理
一个互联网产品的出现,一定是要满足一部分人的需求、需要,一个不能解决用户需求、需要的产品,只能是昙花一现,所以说,产品的核心在于需求。很多时候,用户的需求并不明显,往往表露出来的仅是表面需要,这个时候,我们需要一个人站出来,挖掘这个需求,把表面需求中的隐含需求找出来,形成可以用于软件设计、软件开发的文档,而我们需要的这个人,就是产品经理。
一个普通产品经理的核心能力,就是需求挖掘。那么产品经理仅仅是要做需求挖掘吗?显然不是的,需求挖掘只是核心能力,不同团队中的产品经理,可能会遇到的情况是不同的。大公司的产品经理,还要兼有团队管理能力,市场分析,销售策略,盈利预测等。
2.21 归因分析
如何将用户行为的‘贡献’合理地分配到每一个渠道,这就是归因分析要解决的问题,通过渠道归因来衡量渠道的效果,反过来可以指导业务人员在渠道投放时合理分配投入。
对于归因分析而言,一个很重要的命题即是,针对当前的场景和目标,怎么把“贡献”合理分配到每一个坑位上。下面我们就以站内归因为例,普及一下几种常见的归因分析计算思路。假设一个用户一天内使用APP的行为顺序如下:
首先,启动APP,进入首页,先行搜索,在搜索结果列表页看到了商品A,浏览了商品A的详情,觉得不错,但是并未购买,退出APP。然后,再次启动APP,看到首页顶部Banner,点击进入活动分会场,浏览过程中再次看到商品A,点击再次查看商品A详情。接着,直接退出到了首页,底部推荐列表中推荐了一篇商品A的用户评论,点击进入,再次查看商品A的详细信息。最后,下定决心,购买了商品A。
2.22 数据分析步骤
数据抓取 → \rightarrow → 数据清洗 → \rightarrow → 数据分析 → \rightarrow → 业务决策
产生数据: 内部获取、第三方交易、数据爬取
数据清洗: 缺失值处理(前后数字不全、平均值等、删除)、数据格式内容等一致性处理、逻辑错误处理(重复值、不合理值)
数据分析: 描述性分析(What)、诊断性分析(Why)、预测性分析(Will)、规范性分析(How)
业务决策: 通过利用对已发生事件的理解和事件发生的原因,以及各种可能发生的情况分析来帮助确定可采取的最佳行动方案。指导性分析通常是各类分析的组合。
2.23 数据分析的作用
精准营销 :网站推荐
精细化运营:拉新、留存、推送
产品设计:优化步骤提高转化率
2.24 数据分析报告
明确分析目标
确定分析方案
数据获取、数据清洗、统计分析
产生业务洞察
分析报告
2.25 用户画像怎么做,选择什么属性
基础属性(人口统计特征:年龄、性别、教育情况、收入情况)、兴趣属性(浏览内容、收藏内容、阅读咨询、购买物品偏好等)、行为属性(访问时间、浏览路径等用户在网站的行为日志数据)、社交属性(用户社交相关数据)、位置与场景(用户所处城市、所处居住区域、用户移动轨迹等)、消费属性、业务属性、资产属性、设备属性(使用的终端特征)
2.26 熟悉什么模型,讲一下(RFM模型)
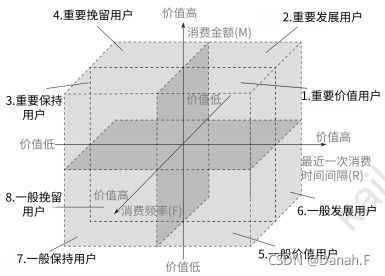
RFM模型:
Recency:最近一次消费时间间隔
Frequency:消费频次、一段时间内的消费次数
Monetary:消费金额,一段时间内的消费金额
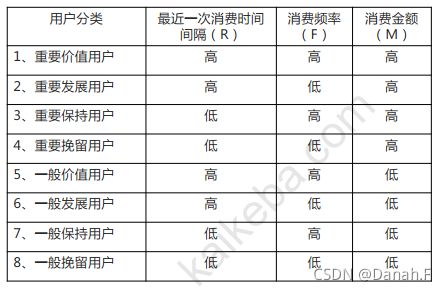
消费时间间隔越长,用户价值越低;消费总频次/总金额越高,用户价值越高。
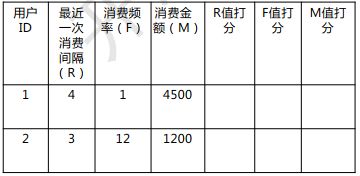
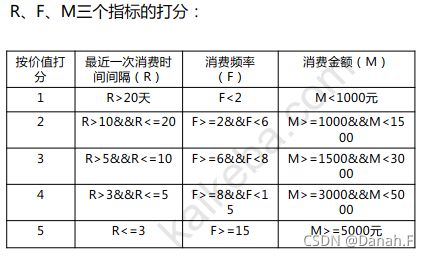
RFM指标计算:
Step1:计算用户的R、F、M打分
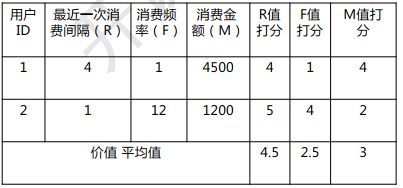
Step2:计算平均值
Step3:用户分类
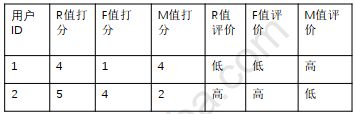
Step4:对应表格,找到用户分类
![]()
重要价值用户:保持长期关注,重点关注,可考虑vip等活动
重要发展客户:办理会员卡等方式提升客户消费频次
重要保持客户:给予优惠券等促销活动,吸引用户回流
重要挽留客户:定时消息推送及促销优惠
2.27 Python基础数据类型有哪些
不可变数据:Number(数字)、String (字符串)、Bool (布尔)、Tuple (元组)
可变数据:List(列表)、Dictionary(字典)、Set(集合)。
2.28 数据分析能力

2.29 数据分析思维
数据+模型=分析结果
数据分析思维:漏斗思维,分类思维,平衡思维,A/B test等
2.30新用户流失和老用户流失有什么不同
来自【面经】数据分析岗_面试题整理总结(持续更新中…)
新用户流失:原因可能有非目标用户(刚性流失)、产品不满足需求(自然流失)、产品难以上手(受挫流失)和竞争产品影响(市场流失)。
新用户要考虑如何在较少的数据支撑下做流失用户识别,提前防止用户流失,并如何对有效的新用户进行挽回。
老用户流失:原因可能有到达用户生命周期衰退期(自然流失)、过度拉升arpu导致低端用户驱逐(刚性流失)、社交蒸发难以满足前期用户需求(受挫流失)和竞争产品影响(市场流失)。
老用户有较多的数据,更容易进行流失用户识别,做好防止用户流失更重要。当用户流失后,要考虑用户生命周期剩余价值,是否需要进行挽回。
2.31 识别作弊用户
分类问题可以用机器学习的方法去解决
(1)渠道特征:渠道、渠道次日留存率、渠道流量以及各种比率特征
(2)环境特征:设备(一般伪造假用户的工作坊以低端机为主)、系统(刷量工作坊一般系统更新较慢)、wifi使用情况、使用时间、来源地区、ip是否进过黑名单
(3)用户行为特征:访问时长、访问页面、使用间隔、次日留存、活跃时间、页面跳转行为(假用户的行为要么过于一致,要么过于随机)、页面使用行为(正常用户对图片的点击也是有分布的,假用户的行为容易过于随机)
(4)异常特征:设备号异常(频繁重置idfa)、ip异常(异地访问)、行为异常(突然大量点击广告、点赞)、数据包不完整等
2.32 常用模型
用户画像
漏斗模型
用户行为路径分析
产品基础指标:UV:独立访客数(unique visitor),PV:页面浏览量(Page View),新用户数。
流量质量指标:跳出率:浏览单页就跳出。用户访问时间。留存率。回访率。
产品营收指标:
客单价(ARPU):客单价=支付有效金额/支付用户数
转化率:订单转化率=有效订单用户数/UV
用户支付金额(GMV):支付金额即产品某段时间的流水。
销售额=访客数×成交转化率×客单价
销售额=曝光次数×点击率×成交转化率×客单价;
2.33 贝壳如果去新的城市扩张,需要看哪些指标
人:房屋需求量
买房:常住人口/每户人口数*百分比,约3人
租房:流动人口
货:
房源,房价
场:市场环境
2.34 若贝壳要进入一个新的城市要如何去估计这个城市的需求量
城市发展水平,关系到有多少人会留在本地,住房买房
现有人口和未来五年的增量人口。
2.35 滴滴数据和贝壳数据的区别
滴滴和贝壳都是双边市场的交易平台,包括供给端和需求端额增长、供需两侧交易匹配效率提升、交易平台服务保障。
滴滴是高频低客单价业务,对交易匹配的时效性更高,交付的服务相对标准化,重效率,快速迭代;买卖房是低频高客单价业务,交易周期长,服务个性化要求更高,重形式。
房地产行业革新较慢,也是局部性的。
滴滴:
供给端增长,司机拉新、持续激励;
需求端增长,乘客营销、会员体系;
交易匹配效率,包括设计定价模式(高峰加价、平峰降价)、司乘匹配模式(就近派单、乘客排队、司机抢单)等
平台服务保障,保证交易正常进行。
贝壳:
供给端增长,拉动更多业主报盘,尤其是优质房源和重点楼盘;
需求端增长,通过线上线下渠道,获得更多买房咨询客户,通过经纪人持续维护,让他们成为买房成交客户。
交易保障服务,房屋信息透明、资产安全、交易流程透明、异常情况赔付等。
2.36 为客户推荐房源应该怎么分析
用户画像,根据用户在平台上的搜索浏览记录分析用户偏好,是更注重距离、价格、周边设施还是其他。推荐算法。
2.37 估计某月某地区二手房的成交量
首先确定一些可参考的数据,比如上月或去年的成交量,在此基础上看是否有一些因素会对成交量产生影响
人货场三个角度,人的角度看涉及经纪人、买房者、业主,货指房屋,比如房价变化,在售房源数等等,场指外部大环境,比如疫情影响之类的。
2.38 ‘三孩’政策对房地产的影响
影响房地产的最直接的三大要素为:人口、土地、金融,长期看人口,中期看土地,短期看金融
人口:三孩会刺激提升人口增长率,进一步挖掘人口红利,增加未来潜在购房人数。
房地产:改善住房的户型,未来学区房的竞争压力会增大,政府工作人员购房者比例会增加,马太效应,刚需房购买难度增加,未来二线城市需求会增加。不过对多孩家庭可能会有购房的相关政策。
2.39 AB测试的流程

分析现状:针对当前产品情况,根据业务数据,提出优化方案(一般由数据分析师和产品经理确定)。
确定评估指标:确定衡量优化效果的指标(如:CTR,停留时长等)。
设计与开发:确定优化版本的设计原型,并完成技术实现(通常与数据分析师无关)。
分配流量:确定实验分层分流方案,以及实验需要切分多少流量,一般根据最小样本量确定。
确定实验有效天数:实验的有效天数即为实验进行多少天能达到流量的最小样本量。
采集并分析数据:提取实验数据,对实验结果进行分析。
根据试验结果,确定是否推广到全量或者是调整之后继续实验。
2.40 如果订单页面卡顿怎么定位问题
2.41 A/B测试的流程
- 沟通测试需求
- 讨论观测指标
- 选择投放目标
- 配置实验策略
- 评估数据结果
3. 机器学习
3.1 知道哪些机器学习算法
线性回归
输出是连续值,用于研究输入与输出的关系,可基于线性回归方程进行预测
逻辑回归
输出是离散值,即0或1,二分类方法
y = 1 / (1+ e-x) sigmoid函数
逻辑回归与线性回归类似,两者的目标都是找出每个输入变量的权重值。不同的是逻辑回归模型是通过特殊的非线性函数来计算输入变量的加权和,逻辑函数或S形函数运行结果,以产生输出y。值小于0.5,类别为0,大于0.5,类别为1.
KNN分类
K最近邻(KNN)分类的目的是将数据分为不同的类别,我们可以基于相似性度量(例如距离函数)对它们进行分类。
(1)计算测试数据与各个训练数据之间的距离
(2)按照递增关系进行排序
(3)选取距离最小的K个点
(4)确定前K个点所在类别的出现频率
(5)返回前K个点中出现频率最高的类别作为测试数据的类别
支持向量机
支持向量机(SVM)最初是用于数据分析。首先一组训练实例被输入到SVM算法中,它们分别属于一类别或另一个类别。然后,根据这些数据该算法建一个模型,然后将新的测试数据分配给它在训练阶段学习到的类别之一。它的基本模型是在特征空间中寻找间隔最大化的分离超平面的线性分类器。
支持向量机是创建一个超平面,将该超平面作为类别之间的分界,新的测试数据出现在哪一侧就属于哪一类。
1)当训练样本线性可分时,通过硬间隔最大化,学习一个线性分类器,即线性可分支持向量机;
2)当训练数据近似线性可分时,引入松弛变量,通过软间隔最大化,学习一个线性分类器,即线性支持向量机;
3)当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机。
SVM算法的优缺点
优点:
1、可以有效解决高维特征的分类和回归问题
2、无需依赖全体样本,只依赖支持向量
3、有大量的核技巧可以使用,从而可以应对线性不可分问题
4、样本量中等偏小照样有较好的效果
缺点:
1、如果特征维度远大于样本个数,SVM表现一般
2、SVM在样本巨大且使用核函数时计算量很大
3、非线性数据的核函数选择依旧没有标准
4、SVM对缺失和噪声数据敏感
5、特征的多样性导致限制了SVM的使用,因为SVM本质上是属于一个几何模型,这个模型需要去定义 instance之间的 kernel或者 similarity(线性SM中的内积),而我们无法预先设定一个很好的 similarity.这样的数学模型使得SM更适合去处理“同性质”的特征。
人工神经网络
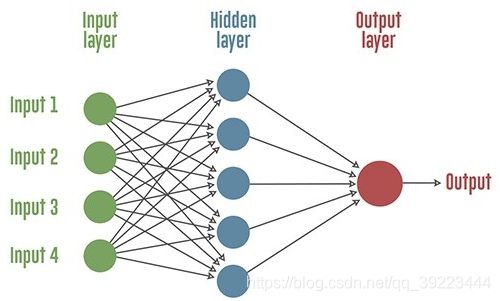
K-means聚类
输入是样本集D={x1,x2,…xm},聚类的簇树k,最大迭代次数N
输出是簇划分C={C1,C2,…Ck}
1)从数据集D中随机选择k个样本作为初始的k个质心向量: {μ1,μ2,…,μk}
2)对于n=1,2,…,N
a) 将簇划分C初始化为Ct=∅,t=1,2…k
b) 对于i=1,2…m,计算样本xi和各个质心向量μj(j=1,2,…k)的距离:dij=||xi−μj||22,将xi标记最小的为dij所对应的类别λi。此时更新Cλi=Cλi∪{xi}
c) 对于j=1,2,…,k,对Cj中所有的样本点重新计算新的质心μj=1|Cj|∑x∈Cjx
e) 如果所有的k个质心向量都没有发生变化,则转到步骤3)
3) 输出簇划分C={C1,C2,…Ck}
K-means的k如何选择
对kmeans聚类如何选择k
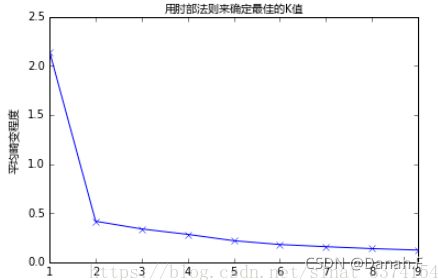
- 肘部法则(Elbow Method)
k-means是以最小化样本与质点平方误差作为目标函数,将每个簇的质点与簇内样本点的平方距离误差和称为畸变程度。对于一个簇,它的畸变程度越低,代表簇内成员越紧密,畸变程度会随着类别的增加而降低,但对于有一定区分度的数据,在达到某个临界点时畸变程度会得到极大改善,之后缓慢下降,这个临界点就可以考虑为聚类性能较好的点。 基于这个指标,我们可以重复训练多个k-means模型,选取不同的k值,来得到相对合适的聚类类别。
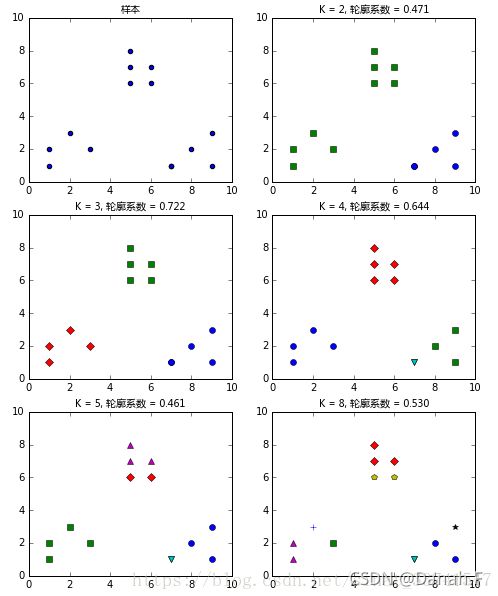
- 轮廓系数(Silhouette Coefficient)
对于一个聚类任务,我们希望得到的簇中,簇内尽量紧密,簇间尽量远离,轮廓系数便是类的密集与分散程度的评价指标,公式表达如下: s(i) = (b(i) – a(i))/max{a(i),b(i)}。a代表同簇样本到彼此间距离的均值,b代表样本到除自身所在簇外的最近簇的样本的均值,s取值在[-1, 1]之间。 如果s接近1,代表样本所在簇合理,若s接近-1代表s更应该分到其他簇中。 同样,利用上述指标,训练多个模型,对比选取合适的聚类类别:
3. 根据需要确定
4. 对于低维度的数据可以观察得到
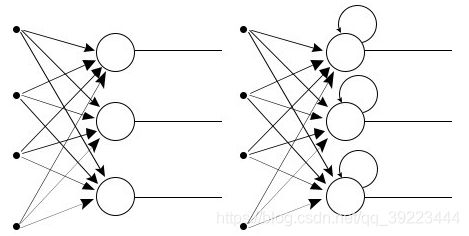
递归神经网络(RNN)
RNN本质上是一种神经网络,它在每个节点上都有一个存储器,这使得处理顺序数据变得容易,即一个数据单元依赖于前一个数据单元。
一种解释RNN优于常规神经网络的优势的方法是,我们应该逐个字符地处理一个单词。如果单词是" trading”,则正常的神经网络节点会在移动到“d”时忘记字符“t”,而递归神经网络会记住该字符,因为它具有自己的记忆。
线性判别分析
传统的逻辑回归仅限于二分类问题。 如果你有两个以上的类,那么线性判别分析算法(Linear Discriminant Analysis,简称LDA)是首选的线性分类技术。
LDA的表示非常简单。 它由你的数据的统计属性组成,根据每个类别进行计算。 对于单个输入变量,这包括:
1.每类的平均值。
2.跨所有类别计算的方差。
3.计算类内类外矩阵
4.求最大的几个特征值和特征向量,得到投影矩阵W
5.对样本中的每一个样本,转化为新的样本Wx。
朴素贝叶斯
朴素贝叶斯是一种简单但极为强大的预测建模算法。
该模型由两种类型的概率组成,可以直接从你的训练数据中计算出来:1)每个类别的概率; 2)给定的每个x值的类别的条件概率。 一旦计算出来,概率模型就可以用于使用贝叶斯定理对新数据进行预测。 当你的数据是数值时,通常假设高斯分布(钟形曲线),以便可以轻松估计这些概率。
集成学习
RF、GBDT和XGBoost都属于集成学习(Ensemble Learning),集成学习的目的是通过结合多个基学习器的预测结果来改善单个学习器的泛化能力和鲁棒性。
根据个体学习器的生成方式,目前的集成学习方法大致分为两大类:即个体学习器之间存在强依赖关系、必须串行生成的序列化方法,以及个体学习器间不存在强依赖关系、可同时生成的并行化方法;前者的代表就是Boosting、Adaboost、GBDT(Gradient Boosting Decision Tree)、Xgboost,后者的代表是Bagging和“随机森林”(Random Forest)。
决策树(Decision Tree)

决策树通过把样本实例从根节点排列到某个叶子节点来对其进行分类。树上的每个非叶子节点代表对一个属性取值的测试,其分支就代表测试的每个结果;而树上的每个叶了节点均代表一个分类的类别,树的最高层节点是根节点。
决策树架用自顶向下的递归方式,从树的根节点开始,在它的内部节点上进行属性值的澳l试比较。然后按照给定实例的属性伯确定对应的分支,最后在决策树的叶子节点得到结论。这个过程在以新的节点为根的了树上重复。
简单来说:类似树的结构将输入数据根据不同分类标准进行分类,层层划分。
优点:
- 决策树容易理解和实现。
- 对于决策树,数据的准备往往是比较简单或者是不必要的。其它技术往往要求先把数据归一化,比如去掉多余的或者空白的属性。
- 能够同时处理数据型和常规型属性。其它的技术往往要求数据属性的单一。
- 是一个白盒模型。如果给定一个观察的模型,那么根据所产生的决策树很容易推出相应的逻辑表达式。
缺点:
- 对于各类别样本数量不一致的数据,在决策树当中信息增益的结果偏向于那些具有更多数值的特征.
- 决策树内部节点的判别具有明确性,这种明确性可能会带来误导。
- 决策树的缺点是由于其固有的设计结构而易于过度拟合。
随机森林(Random Rorest)
一个随机森林算法旨在解决一些决策树泛化能力弱的缺点。
随机森林由决策树组成,决策树是代表决策过程或统计概率的决策图。这些多个树映射到单个树,称为分类或回归(CART)模型。
随机森林算法基于Bootstrap方法重采样,产生多个训练集。不同的是,随机森林算法在构建决策树的时候,采用了随机选取分裂网性集的方法。
随机森林是最流行和最强大的机器学习算法之一。它是一种被称为Bootstrap Aggregation或Bagging的集成机器学习算法。
bootstrap是一种强大的统计方法,用于从数据样本中估计某一数量,例如平均值。它会抽取大量样本数据,计算平均值,然后平均所有平均值,以便更准确地估算真实平均值。
在bagging中用到了相同的方法,但最常用到的是决策树,而不是估计整个统计模型。它会训练数据进行多重抽样,然后为每个数据样本构建模型。当你需要对新数据进行预测时,每个模型都会进行预测,并对预测结果进行平均,以更好地估计真实的输出值。
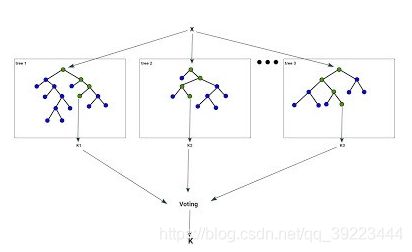
随机森林在bagging的基础上更进一步,引入了随机特征选择:
-
样本的随机:从样本集中用Bootstrap随机选取n个样本
-
特征的随机:从所有属性中随机选取K个属性,选择最佳分割属性作为节点建立CART决策树(泛化的理解,这里面也可以是其他类型的分类器,比如SVM、Logistics)
-
重复以上两步m次,即建立了m棵CART决策树
-
这m个CART形成随机森林,通过投票表决结果,决定数据属于哪一类(投票机制有一票否决制、少数服从多数、加权多数)
随机选择特征是指在树的构建中,会从样本集的特征集合中随机选择部分特征,然后再从这个子集中选择最优的属性用于划分,这种随机性导致随机森林的偏差会有稍微的增加(相比于单棵不随机树),但是由于随机森林的‘平均’特性,会使得它的方差减小,而且方差的减小补偿了偏差的增大,因此总体而言是更好的模型。
RF的重要特性是不用对其进行交叉验证或者使用一个独立的测试集获得无偏估计,它可以在内部进行评估,也就是说在生成的过程中可以对误差进行无偏估计,由于每个基学习器只使用了训练集中约63.2%的样本,剩下约36.8%的样本可用做验证集来对其泛化性能进行“包外估计”。
RF和Bagging对比:RF的起始性能较差,特别当只有一个基学习器时,随着学习器数目增多,随机森林通常会收敛到更低的泛化误差。随机森林的训练效率也会高于Bagging,因为在单个决策树的构建中,Bagging使用的是‘确定性’决策树,在选择特征划分结点时,要对所有的特征进行考虑,而随机森林使用的是‘随机性’特征数,只需考虑特征的子集。
随机森林的优点较多,简单总结:1、在数据集上表现良好,相对于其他算法有较大的优势(训练速度、预测准确度);2、能够处理很高维的数据,并且不用特征选择,而且在训练完后,给出特征的重要性;3、容易做成并行化方法。
RF的缺点:在噪声较大的分类或者回归问题上回过拟合。
Bagging
放回抽样,多数表决(分类)或简单平均(回归),同时Bagging的基学习器之间属于并列生成,不存在强依赖关系。
Bagging 步骤:
另原始数据集为D(n个样本),
1.for i=1 to T
2.从D中独立随机抽取m个数据(m
3.用 m i m_i mi训练一个分类器
4.end
5.所有分类器的判决结果投票决定最终的分类结果
关于调参:
1.如何选取K,可以考虑有N个属性,取K=根号N
2.最大深度(不超过8层)
3.棵数
4.最小分裂样本树
5.类别比例
Boosting
Boosting是一种从一些弱分类器中创建一个强分类器的集成技术。 它先由训练数据构建一个模型,然后关注被已有分类器错分的那些数据来获得新的分类器,不断添加模型,直到训练集完美预测或已经添加到数量上限,Boosting分类的结果是基于所有分类器的加权求和结果的,分类器权重并不相等,每个权重代表对应的分类器在上一轮迭代中的成功度。
GBDT
GBDT与传统的Boosting区别较大,它的每一次计算都是为了减少上一次的残差,而为了消除残差,我们可以在残差减小的梯度方向上建立模型,所以说,在GradientBoost中,每个新的模型的建立是为了使得之前的模型的残差往梯度下降的方法,与传统的Boosting中关注正确错误的样本加权有着很大的区别。
在GradientBoosting算法中,关键就是利用损失函数的负梯度方向在当前模型的值作为残差的近似值,进而拟合一棵CART回归树。
GBDT的会累加所有树的结果,而这种累加是无法通过分类完成的,因此GBDT的树都是CART回归树,而不是分类树(尽管GBDT调整后也可以用于分类但不代表GBDT的树为分类树)。
GBDT的性能在RF的基础上又有一步提升,因此其优点也很明显,1、它能灵活的处理各种类型的数据;2、在相对较少的调参时间下,预测的准确度较高。
当然由于它是Boosting,因此基学习器之前存在串行关系,难以并行训练数据。
XGBoost与GBDT的区别
XGBoost的性能在GBDT上又有一步提升,XGBoost最大的认知在于其能够自动地运用CPU的多线程进行并行计算,同时在算法精度上也进行了精度的提高。
由于GBDT在合理的参数设置下,往往要生成一定数量的树才能达到令人满意的准确率,在数据集较复杂时,模型可能需要几千次迭代运算。但是XGBoost利用并行的CPU更好的解决了这个问题。
xgboost与gbdt比较大的不同就是目标函数的定义。
优点:
1、传统的GBDT以CART树作为基学习器,XGBoost还支持线性分类器,这个时候XGBoost相当于L1和L2正则化的逻辑斯蒂回归(分类)或者线性回归(回归);
传统的GBDT在优化的时候只用到一阶导数信息,XGBoost则对代价函数进行了二阶泰勒展开,得到一阶和二阶导数;
2、XGBoost在代价函数中加入了正则项,用于控制模型的复杂度。从权衡方差偏差来看,它降低了模型的方差,使学习出来的模型更加简单,防止过拟合,这也是XGBoost优于传统GBDT的一个特性;
3、shrinkage(缩减),相当于学习速率(XGBoost中的eta)。XGBoost在进行完一次迭代时,会将叶子节点的权值乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。(GBDT也有学习速率)
4、列抽样。XGBoost借鉴了随机森林的做法,支持列抽样,不仅防止过 拟合,还能减少计算;
5、对缺失值的处理。对于特征的值有缺失的样本,XGBoost还可以自动 学习出它的分裂方向;
6、XGBoost工具支持并行。
缺点:
1、level-wise 建树方式对当前层的所有叶子节点一视同仁,有些叶子节点分裂收益非常小,对结果没影响,但还是要分裂,加重了计算代价。
2、预排序方法空间消耗比较大,不仅要保存特征值,也要保存特征的排序索引,同时时间消耗也大,在遍历每个分裂点时都要计算分裂增益(不过这个缺点可以被近似算法所克服)
AdaBoost(Adaptive Boosting,自适应增强)
AdaBoost是为二分类开发的第一个真正成功的Boosting算法,同时也是理解Boosting的最佳起点。 目前基于AdaBoost而构建的算法中最著名的就是随机梯度boosting。
它的自适应在于:前一个基本分类器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个基本分类器。同时,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数。
整个Adaboost 迭代算法就3步:
- 初始化训练数据的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权值:1/N。
- 训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权值就被降低;相反,如果某个样本点没有被准确地分类,那么它的权值就得到提高。然后,权值更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
- 将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
AdaBoost常与短决策树一起使用。 在创建第一棵树之后,每个训练实例在树上的性能都决定了下一棵树需要在这个训练实例上投入多少关注。难以预测的训练数据会被赋予更多的权重,而易于预测的实例被赋予更少的权重。 模型按顺序依次创建,每个模型的更新都会影响序列中下一棵树的学习效果。在建完所有树之后,算法对新数据进行预测,并且通过训练数据的准确程度来加权每棵树的性能。
GBM与XGBoost的区别
- xgboost采用的是level-wise的分裂策略,而lightGBM采用了leaf-wise的策略,区别是xgboost对每一层所有节点做无差别分裂,可能有些节点的增益非常小,对结果影响不大,但是xgboost也进行了分裂,带来了无必要的开销。 leaft-wise的做法是在当前所有叶子节点中选择分裂收益最大的节点进行分裂,如此递归进行,很明显leaf-wise这种做法容易过拟合,因为容易陷入比较高的深度中,因此需要对最大深度做限制,从而避免过拟合。
- lightgbm使用了基于histogram的决策树算法,这一点不同与xgboost中的 exact 算法,histogram算法在内存和计算代价上都有不小优势。
- lightgbm支持直接输入categorical 的feature
在对离散特征分裂时,每个取值都当作一个桶,分裂时的增益算的是”是否属于某个category“的gain。类似于one-hot编码。 - 多线程优化
SVM/GBM/XGBoost的共同点和比较
XGBoost与GBDT的有什么不同
- GBDT是机器学习算法,XGBoost是该算法的工程实现。
- 在使用CART作为基础分类器时,XGBoost显示地加入了正则项来控制模型的复杂度,有利于防止过拟合,从而提高模型的泛化能力。
- GBDT在模型训练时只使用了损失函数的—阶导数信息, XGBoost对代价函数进行二阶泰克展开,可以同时使用—阶和二阶导数。
- 传统的GBDT采用CART作为基础分类器,XGBoost支持多种类型的基础分类器,比如线性分类器。
- 传统的GBDT在每轮迭代时使用全部的数据,XGBoost则支持对数据进行采样。
- 传统的GBDT没有涉及对缺失值进行处理,XGBoost能够自动学习出缺失值的处理策略。
- XGBoost还支持并行计算,XGBoost的并行是基于特征计算的并行,将特征列排序后以block的形式存储在内存中,在后面的迭代中重复使用这个结构。
XGBoost为什么可以并行训练?
注意:xgboost的并行不是tree粒度的并行, xgboost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t1次迭代的预测值)
xgboost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点, xgboost在训练之前,预先对数据进行了排序,然后保存为 block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个 block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以xgboost还提出了一种可并行的直方图算法,用于高效地生成候选的分割点。
随机森林(RF)和GBDT的区别
- 随机森林采用的bagging思想,而GBDT采用boosting的思想
- 组成随机森林的树可以并行生成;而GBDT只能是串行生成。
- 随机森林对异常值不敏感;GBDT对异常值非常敏感。
- 随机森林对训练集—视同仁:GBDT对训练集中预测错误的样本给予了更多关注。
- 随机森林是通过减少模型方差提高性能:GBDT是通过减少模型偏差提高性能。
- 对于最终的输出结果而言,随机森林采用多数投票等;而GBDT则是将所有结果累加起来,或者加权累加起来。
- 组成随机森林的树可以是分类树,也可以是回归树;而GBDT只能由回归树组成。
XGBoost防止过拟合的方法?
- 数据
- 样本采样一在生成每颗树的时候可以对数据进行随机采样。
- 特征采样一而且还可以在生成每棵树的时候,每棵树生成每一层子节点的时候,以及在每次做节点分裂的时候,选择是否对特征进行采样。
- 模型
- 限制树的深度,树的深度越深模型越复杂。
- 设置叶子节点上样本的最小数量,这个值越小则树的枝叶越多模型越复杂;相反如果这个值越大,则树的枝叶越少,模型越简单。这个值太小会导致过拟合,太大会导致欠拟合。
- 正则化
- L1和L2正则化损失项的权重
- 叶子节点数量惩罚项的权重值
XGBoost为什么这么快?
- 同时采用了损失函数的一阶导数和二阶导数,使得目标函数收敛更快。
- 在进行节点分类时采用的贪心算法和直方图算法,大大加速了节点分裂的计算过程。
- 工程优化,使得模型训练时可进行并行计算
GBDT如何用于分类
GBDT在做分类任务时与回归任务类似,所不同的是损失函数的形式不同。我们以二分类的指数损失函数为例来说明:
我们定义损失函数为:
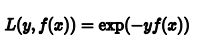
3.2 R和Python中有哪些机器学习包
Numpy数值计算工具包,底层由C实现,计算速度快
matplotlib绘图工具包
pandas 提供了高性能、易用的数据结构及数据分析工具,能像SQL那样对数据进行控制,python版的excel
scikit-learn 机器学习Python包 ,包含了大部分的机器学习算法。
XGBoost/LightGBM | Gradient Boosting 算法的两种实现框架。
PyTorch/TensorFlow/Keras | 常用的深度学习框架。
Scipy科学计算包
3.3 针对类别不平衡要怎么处理
是否能收集更多数据:我们首先想到的应该是如何能够收集到更多的数据,往往更多的数据能够战胜更好的算法。
重采样(过采样和欠采样):欠采样就是一个随机删除一部分多数类(数量多的类型)数据的过程,这样可以使多数类数据数量可以和少数类(数量少的类型)相匹配。第二种重采样技术叫过采样,这个过程比欠采样复杂一点。它是一个生成合成数据的过程,试图学习少数类样本特征随机地生成新的少数类样本数据。
人工生成数据集:对于典型的分类问题,有许多方法对数据集进行过采样,最常见的技术是SMOTE(Synthetic Minority Over-sampling Technique,合成少数类过采样技术)。简单地说,就是在少数类数据点的特征空间里,根据随机选择的一个K最近邻样本随机地合成新样本。
过采样之后特征相关性更明显了。在解决不平衡问题之前,大多数特征并没有显示出相关性,这肯定会影响模型的性能。除了会关系到整个模型的性能,特征性相关性还会影响ML模型的性能,因此修复类别不平衡问题非常重要。
尝试不同的分类算法:不同的算法对数据的敏感度不同,决策树在不平衡数据集处理上有较好的表现。
尝试对模型进行惩罚:你可以使用相同的分类算法但是使用一个不同的角度,比如说你的任务是识别小类,那么可以对分类器的小类样本数据增加权重,降低大类样本的权值(这张方法实际产生了新的数据分布)。如penalized-SVM、penalized LAD
尝试改变评价指标:当我的数据集是不平衡数据集时,准确率作为衡量指标往往会产生误导作用。机器学习之评价指标
尝试新的角度:把小样本看成异常点检测。
创新思维把大类化成小类,小类当做异常点
3.4 用过什么激活函数
常见的激活函数:sigmoid,Tanh,ReLU,leaky ReLU
Sigmoid将回归问题的结果转换到(0,1的范围,图像成中间窄两边宽的结构;即大部分的时候sigmoid的值集中的在两边。Sigmoid函数提供了一个很好的适用于二分类的问题的输出结果,以及非线性表达。但是它的缺点也是非常明显的:
1.前向传播和反向传播都要做指数计算计算耗费资源较多。
2. Sigmoid函数梯度饱和导致神经网络反向传播时出现梯度消失的现象。当神经元的激活在接近0或1处时会饱和,在这些区域梯度几乎为0,这就会导致梯度消失,几乎就有没有信号通过传回上一层。
3. Sigmoid函数的输出不是零中心的。因为如果输入神经元的数据总是正数那么关于w的梯度在反向传播的过程中,将会要么全部是正数,要么全部是负数这将会导致梯度下降权重更新时出现z字型的下降(ZigZag现象)
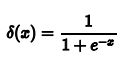
Tanh有函数梯度饱和问题,计算复杂
![]()
ReLu激活相较于sigmoid和tanh函数来说对于随机梯度下降收敛有巨大的作用,很好地解决了梯度消失的问题;同时函数的前向和反向传播计算计算效率也高。
但是RLU存在以下缺点:
1.ReL的输出不是零中心的,所以梯度下降时存在ZigZag现象。
2.ReLU函数存在小于等于0侧,神经元坏死的现象。
leakyRelu,其中通常取很小的值比如0.01,这样可以确保负数信息没有全部丢失。解决了ReLU神经元坏死的问题:并且一定程度上缓解了数据均值不为0导致的Zigzag现象。
用过什么损失函数
平方损失函数:经常应用于回归问题
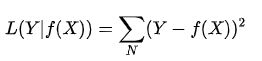
指数损失函数:对离群点、噪声非常敏感。经常用在AdaBoost算法中。
![]()
Hinge损失函数:
![]()
hinge损失函数表示如果被分类正确,损失为0,否则损失就1-yf(x)。SVM就是使用这个损失函数。
交叉熵损失函数 (Cross-entropy loss function):常用与分类问题中
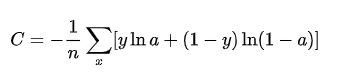
当使用sigmoid作为激活函数的时候,常用交叉熵损失函数而不用均方误差损失函数,因为它可以完美解决平方损失函数权重更新过慢的问题,具有“误差大的时候,权重更新快;误差小的时候,权重更新慢”的良好性质。
数据的准备过程完整性真实性
特征工程指标选取降维
4. BI和Excel工具
4.1 BI
4.1.1 Tableau和Power BI是自己学的还是实习用到,你觉得这两种有什么优缺点
Tableau是国际知名的BI工具。可视化功能是Tableau的王牌功能,可以通过单击或拖动感兴趣的维度(通常是离散的类别或特征)和度量值(值)来构建Tableau可视化效果。缺点就是价格太贵,而且国外的产品在国内往往由外包商承包实施。
Power BI包括用于Azure托管服务的Web界面和用于Windows桌面的power bi桌面应用程序。它的价格比竞争对手便宜得多,对于注重性价比的公司来说,它是一个不错的选择。对于某些数据源,Power BI具有预定义的图表、仪表盘和报表,这对用户来说比较方便。它的缺点是数据分析能力或图表控制力不如FineBI或tableau。数据分析师之BI工具对比
4.1.3 怎么搭建报表体系
4.2 Excel
4.3 SPSS
4.3.1 SPSS有哪些功能
SPSS 18.0由17个功能模组组成:
Base System基础程式
Advanced Models高等统计模组(GEE/GLM/存活分析)
Regression Models进阶回归模组
Custom Tables多变量表格
Forecasting时间序列分析
Categories类别资料分析/多元尺度方法
Conjoint联合分析
Exact Tests精确检定
Missing Value Analysis遗漏值分析
Neural Networks类神经网络
Decision Trees决策树
Data Preparation资料准备
Complex Samples抽样计划
Direct Marketing直销行销模组
Bootstrapping拔靴法
Data collection Data Entry资料收集
Programmability Extension扩充程式码能力
5. python
5.1 python用什么库实现矩阵乘法(numpy里面的不同库对比一下,matmul,dot等

5.2 python内存管理
答:从三个方面来说,一对象的引用计数机制,二垃圾回收机制,三内存池机制
一、对象的引用计数机制
Python内部使用引用计数,来保持追踪内存中的对象,所有对象都有引用计数。
引用计数增加的情况:
1,一个对象分配一个新名称
2,将其放入一个容器中(如列表、元组或字典)
引用计数减少的情况:
1,使用del语句对对象别名显示的销毁
2,引用超出作用域或被重新赋值
sys.getrefcount( )函数可以获得对象的当前引用计数
多数情况下,引用计数比你猜测得要大得多。对于不可变数据(如数字和字符串),解释器会在程序的不同部分共享内存,以便节约内存。
二、垃圾回收
1,当一个对象的引用计数归零时,它将被垃圾收集机制处理掉。
2,当两个对象a和b相互引用时,del语句可以减少a和b的引用计数,并销毁用于引用底层对象的名称。然而由于每个对象都包含一个对其他对象的应用,因此引用计数不会归零,对象也不会销毁。(从而导致内存泄露)。为解决这一问题,解释器会定期执行一个循环检测器,搜索不可访问对象的循环并删除它们。
三、内存池机制
Python提供了对内存的垃圾收集机制,但是它将不用的内存放到内存池而不是返回给操作系统。
1,Pymalloc机制。为了加速Python的执行效率,Python引入了一个内存池机制,用于管理对小块内存的申请和释放。
2,Python中所有小于256个字节的对象都使用pymalloc实现的分配器,而大的对象则使用系统的malloc。
3,对于Python对象,如整数,浮点数和List,都有其独立的私有内存池,对象间不共享他们的内存池。也就是说如果你分配又释放了大量的整数,用于缓存这些整数的内存就不能再分配给浮点数。
5.3 C++和python的区别
包括但不限于:
- python是一种脚本语言,是解释执行的,而C++是编译语言,是需要编译后在特定平台运行的。python可以很方便的跨平台,但是效率没有C++高。
- python使用缩进来区分不同的代码块,C++使用花括号来区分
- C++中需要事先定义变量的类型,而python不需要,python的基本数据类型只有数字,布尔值,字符串,列表,元组等等
- python的库函数比C++的多,调用起来很方便
5.4 C++、Java的联系与区别,包括语言特性、垃圾回收、应用场景等(java的垃圾回收机制)
包括但不限于:
- C++和Java都是面向对象的语言,C++是编译成可执行文件直接运行的,JAVA是编译之后在JAVA虚拟机上运行的,因此JAVA有良好的跨平台特性,但是执行效率没有C++高。
- C++的内存管理由程序员手动管理,JAVA的内存管理是由Java虚拟机完成的,它的垃圾回收使用的是标记-回收算法
- C++有指针,Java没有指针,只有引用
- JAVA和C++都有构造函数,但是C++有析构函数但是Java没有
5.5 面向对象的三大特性
面向对象的三大特性是:封装,继承和多态。
- 封装隐藏了类的实现细节和成员数据,实现了代码模块化,如类里面的private和public;
- 继承使得子类可以复用父类的成员和方法,实现了代码重用;
- 多态则是"一个接口,多个实现",通过父类调用子类的成员,实现了接口重用,如父类的指针指向子类的对象。
5.6 深拷贝和浅拷贝的区别(举例说明深拷贝的安全性)
- 浅拷贝就是将对象的指针进行简单的复制,原对象和副本指向的是相同的资源。
- 而深拷贝是新开辟一块空间,将原对象的资源复制到新的空间中,并返回该空间的地址。
- 深拷贝可以避免重复释放和写冲突。例如使用浅拷贝的对象进行释放后,对原对象的释放会导致内存泄漏或程序崩溃。
5.7 调试程序的方法
(1)通过设置断点进行调试
(2)打印log进行调试
(3)打印中间结果进行调试
5.5 在Python中如何实现多线程
5.6 在Python中是如何管理内存的
5.7 请解释使用args和*kwargs的含义
5.8 Python中的实例方法、静态方法和类方法有什么区别
首先,这三种方法都定义在类中。下面我先简单说一下怎么定义和调用的。(PS:实例对象的权限最大。)
实例方法
定义:第一个参数必须是实例对象,该参数名一般约定为“self”,通过它来传递实例的属性和方法(也可以传类的属性和方法);
调用:只能由实例对象调用。
类方法
定义:使用装饰器@classmethod。第一个参数必须是当前类对象,该参数名一般约定为“cls”,通过它来传递类的属性和方法(不能传实例的属性和方法);
调用:类和实例对象都可以调用。
静态方法
定义:使用装饰器@staticmethod。参数随意,没有“self”和“cls”参数,但是方法体中不能使用类或实例的任何属性和方法;
调用:类和实例对象都可以调用。
5.9 你最喜欢Python的哪个库
5.10 你在Python中使用了哪些ORM
5.11 any()和all()如何工作
any(iterables)和all(iterables)对于检查两个对象相等时非常实用,但是要注意,any和all是python内置函数,同时numpy也有自己实现的any和all,功能与python内置的一样,只不过把numpy.ndarray类型加进去了。因为python内置的对高于1维的ndarray没法理解,所以numpy基于的计算最好用numpy自己实现的any和all。
本质上讲,any()实现了或(OR)运算,而all()实现了与(AND)运算。
对于any(iterables),如果可迭代对象iterables中任意存在每一个元素为True则返回True。特例:若可迭代对象为空,比如空列表[],则返回False。
对于all(iterables),如果可迭代对象iterables中所有元素都为True则返回True。特例:若可迭代对象为空,比如空列表[],则返回True
5.12 .什么是lambda函数?它有什么好处?
答:lambda 表达式,通常是在需要一个函数,但是又不想费神去命名一个函数的场合下使用,也就是指匿名函数,是一个短小的函数
a=lambdax,y:x+y
a(3,11)
5.13 Python里面如何拷贝一个对象?(赋值,浅拷贝,深拷贝的区别)
赋值(=),就是创建了对象的一个新的引用,修改其中任意一个变量都会影响到另一个。
浅拷贝:创建一个新的对象,但它包含的是对原始对象中包含项的引用(如果用引用的方式修改其中一个对象,另外一个也会修改改变){1,完全切片方法;2,工厂函数,如list();3,copy模块的copy()函数}
深拷贝:创建一个新的对象,并且递归的复制它所包含的对象(修改其中一个,另外一个不会改变){copy模块的deep.deepcopy()函数}
5.14 Python中pass语句的作用是什么?
pass语句不会执行任何操作,一般作为占位符或者创建占位程序,whileFalse:pass
5.15 如何用Python来进行查询和替换一个文本字符串?
答:可以使用re模块中的sub()函数或者subn()函数来进行查询和替换,
格式:sub(replacement, string[,count=0])(replacement是被替换成的文本,string是需要被替换的文本,count是一个可选参数,指最大被替换的数量)
import re
p=re.compile(‘blue|white|red’)
print(p.sub(‘colour’,'blue socks and red shoes’))
# colour socks and colour shoes
print(p.sub(‘colour’,'blue socks and red shoes’,count=1))
# colour socks and red shoes
5.16 Python里面match()和search()的区别?
答:re模块中match(pattern,string[,flags]),检查string的开头是否与pattern匹配。
re模块中research(pattern,string[,flags]),在string搜索pattern的第一个匹配值。
>>>print(re.match(‘super’, ‘superstition’).span())
(0, 5)
>>>print(re.match(‘super’, ‘insuperable’))
None
>>>print(re.search(‘super’, ‘superstition’).span())
(0, 5)
>>>print(re.search(‘super’, ‘insuperable’).span())
(2, 7)
5.17 Python里面如何生成随机数?
答:random模块
随机整数:random.randint(a,b):返回随机整数x,a<=x<=b
random.randrange(start,stop,[,step]):返回一个范围在(start,stop,step)之间的随机整数,不包括结束值。
随机实数:random.random( ):返回0到1之间的浮点数
random.uniform(a,b):返回指定范围内的浮点数。
5.18 单引号,双引号,三引号的区别
答:单引号和双引号是等效的,如果要换行,需要符号(\),三引号则可以直接换行,并且可以包含注释
5.19 什么是__init__?
__init__是Python中的方法或者结构。在创建类的新对象/实例时,将自动调用此方法来分配内存。所有类都有__init__方法。
5.20 如何在Python中实现多线程?
Python有一个多线程库,但是用多线程来加速代码的效果并不是那么的好,
Python有一个名为Global Interpreter Lock(GIL)的结构。GIL确保每次只能执行一个“线程”。一个线程获取GIL执行相关操作,然后将GIL传递到下一个线程。
虽然看起来程序被多线程并行执行,但它们实际上只是轮流使用相同的CPU核心。
所有这些GIL传递都增加了执行的开销。这意味着多线程并不能让程序运行的更快。
5.21 python列表解析式,取0到100之间可以整除3的数
5.22 Pyhton apply 和map的区别
apply是作用的DataFrame上的,用于对row和column进行计算;applymap是作用到每个元素。map是作用到serise的元素级别,作用到每个元素上。
5.23 字典值的获取
- 一个是通过键值对,即dict[‘key’],另一个就是dict.get()方法
dict.get(key, default=None)
key – 字典中要查找的键。
default – 如果指定键的值不存在时,返回该默认值。 - items()
items()方法把字典中每对key和value组成一个元组,并把这些元组放在列表中返回。

5.24 and、or和&、|
(&,|)和(and,or)是两组比较相似的运算符,用在“与”/ “或”上,在用法上有些许区别。
如果a,b是数值变量, 则&, |表示位运算, and,or则依据是否非0来决定输出
如何a, b是逻辑变量, 则两类的用法基本一致
Dataframe中在多个逻辑条件下,用& 或者|,
5.25 数组和链表的区别
来自数组和链表的区别

5.26 数组和列表的区别
数组和列表有相同的存储数据方式
数组的元素必须是一致的,列表可以包含任何数据类型元素
5.27 栈和队列的区别
5.28 用栈怎么实现一个队列?
5.29 进程、线程和协程
进程: 一个运行的程序就是一个进程,进程是系统资源分配的最小单元,进程拥有自己独立的内存空间,所有进程之间数据不共享,开销大。
线程: cpu调度执行的最小单位,不能独立存在,依赖进程存在,一个进程至少有一个线程,叫主线程,而多个线程共享内存,从而极大地提高了程序的运行效率。
协程: 是一种用户态的轻量级线程,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。协程调度时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁地访问全局变量,所以上下文的切换非常快。
5.30 zip函数
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
>>> a = [1,2,3]
>>> b = [4,5,6]
>>> c = [4,5,6,7,8]
>>> zipped = zip(a,b) # 打包为元组的列表
[(1, 4), (2, 5), (3, 6)]
>>> zip(a,c) # 元素个数与最短的列表一致
[(1, 4), (2, 5), (3, 6)]
>>> zip(*zipped) # 与 zip 相反,*zipped 可理解为解压,返回二维矩阵式
[(1, 2, 3), (4, 5, 6)]
5.31 python2和python3的区别
参考Python 2 和 Python 3 有哪些主要区别?
- print
在 Python 2 中,print 是一条语句,而 Python3 中作为函数存在。虽然python2也看到带括号的情况,但是本质是不一样的。
前者是把 (“hello”)当作一个整体,而后者 print()是个函数,接收字符串作为参数。
# python2
>>> print('a','b')
('a','b')
# python3
>>> print('a','b')
a b
- 编码
python2的默认编码是ascii编码,导致2经常遇到编码问题。python3默认采用UTF-8作为默认编码。
# python2
>>> sys.getdefaultencoding()
'ascii'
# python2
>>> sys.getdefaultencoding()
'utf-8'
-
字符串
在python2中,字符串有两个类型,一个是unicode,一个是str,前者表示文本字符串,后者表示字节序列,不过两者没有明显界限。在python3中做了严格区别,str表示字符串,byte表示字节序列,任何写入文本或者网络传输的数据都只接受字节序列,从源头组织了编码错误的问题。 -
True 和False
True和False在python2中是两个全局变量,在数值上分别对于1和0,既然是变量,就可以指向其他对象。但是这也造成了混乱,所以在python3中修正了这个缺陷,True和False变成了两个关键字,永远指向两个固定的对象,不允许再被赋值。 -
迭代器
在python2中的很多返回列表的内置函数和方法zaipython3中都改成了返回类似于迭代器的对象。python2中的range和xrange函数合并成了range。 -
nonlocal
在python2中在函数里面可以用关键字global声明某个变量为全局变量,但是在嵌套函数中,想要给一个变量声明为非局部变量是没法实现的,在python3,新增了关键字nonlocal,使得非局部变量成为可能。 -
很多内建模块也做了大量调整,python3中的模块组织更加清洗,类更加先进,还引入了一步IO等等
6. SQL
6.1 主键和索引的区别
1、应用范畴不同:
主键属于索引的一种。在数据库关系图中为表定义主键将自动创建主键索引,主键索引是唯一索引的特定类型。该索引要求主键中的每个值都唯一。当在查询中使用主键索引时,它还允许对数据的快速访问。
2、种类不同:
根据数据库的功能,可以在数据库设计器中创建三种索引:唯一索引、主键索引和聚集索引。而,主键只是其中的一种。
3、创建方式不同:
当创建或更改表时可通过定义 PRIMARY KEY 约束来创建主键。一个表只能有一个 PRIMARY KEY 约束,而且 PRIMARY KEY 约束中的列不能接受空值。由于 PRIMARY KEY 约束确保唯一数据,所以经常用来定义标识列。经常在WHERE子句中的列上面创建索引。
6.2 短索引的使用场景
对串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个CHAR(255)的 列,如果在前10 个或20 个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
如果一个索引中包含了数据类型为字符串的,那么可以为这一列指定长度。因为,对于很多的字符串来说,前几个就可以确定该字符是唯一的了。
6.3 数据库的索引类型
数据库的索引类型分为逻辑分类和物理分类
逻辑分类:
- 主键索引 当关系表中定义主键时会自动创建主键索引。每张表中的主键索引只能有一个,要求主键中的每个值都唯一,即不可重复,也不能有空值。
- 唯一索引 数据列不能有重复,可以有空值。一张表可以有多个唯一索引,但是每个唯一索引只能有一列。如身份证,卡号等。
- 组合索引 在表中的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用,使用组合索引时遵循最左前缀原则。
- 普通索引 一张表可以有多个普通索引,可以重复可以为空值。
- 全文索引 只有在MyISAM引擎上才能使用,只能在CHAR,VARCHAR,TEXT类型字段上使用全文索引。
物理分类:
6. 聚集索引(聚簇索引) 数据在物理存储中的顺序跟索引中数据的逻辑顺序相同,比如以ID建立聚集索引,数据库中id从小到大排列,那么物理存储中该数据的内存地址值也按照从小到大存储。一般是表中的主键索引,如果没有主键索引就会以第一个非空的唯一索引作为聚集索引。一张表只能有一个聚集索引。
7. 非聚集索引 数据在物理存储中的顺序跟索引中数据的逻辑顺序不同。非聚集索引因为无法定位数据所在的行,所以需要扫描两遍索引树。第一遍扫描非聚集索引的索引树,确定该数据的主键ID,然后到主键索引(聚集索引)中寻找相应的数据。
6.4 数据库的索引优缺点(重点)
索引是帮助MySQL高效获取数据的排好序的数据结构
优点: 创建索引可以大大提高系统的性能。
- 通过创建唯—性索引,可以保证数据库表中每—行数据的唯—性。
- 可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
- 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
- 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
- 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
缺点
6. 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
7. 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
8. 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
6.5 什么时候使用索引,什么时候不能使用索引(重点)
- 经常搜索的列上建索引
- 作为主键的列上要建索引
- 经常需要连接的列上
- 经常需要排序的列
- 经常需要范围(where子句)查找的列
哪些列不适合建索引?
6. 很少查询的列。
7. 更新很频繁的列
8. 数据值的取值比较少的列(比如性别)
9. 表记录较少的列
6.6 MySQL怎么建立索引,怎么建立主键索引,怎么删除索引?
MySQL建立索引有两种方式:用alter table或者create index。
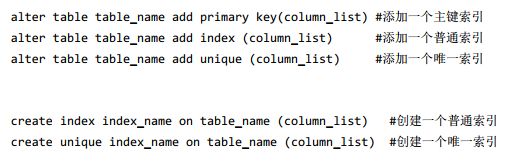
Mysql删除索引同样也有两种方式: alter table 和 drop index

6.7 数据库中事务的ACID
A: atom原子性
数据库事务的原子性是指:事务是一个不可分割的工作单位,这组操作要么全部发生,要么全部不发生。
c: consistency一致性
数据库事务的一致性是指:在事务开始以前,数据库中的数据有一个一致的状态。在事务完成后,数据库中的事务也应该保持这种一致性。事务应该将数据从一个一致性状态转移到另一个一致性状态。比如在银行转账操作后两个账户的总额应当不变。
l: isolation隔离性
数据库事务的隔离性要求数据库中的事务不会受另一个并发执行的事务的影响,对于数据库中同时执行的每个事务来说,其他事务要么还没开始执行,要么已经执行结束,它都感觉不到还有别的事务正在执行。
D: durability 持久性
数据库事务的持久性要求事务对数据库的改变是永久的,哪怕数据库发生损坏都不会影响到已发生的事务。
如果事务没有完成,数据库因故断电了,那么重启后也应该是没有执行事务的状态,如果事务已经完成后数据库断电了,那么重启后就应该是事务执行完成后的状态。
6.8 事务的并发问题

不可重复读与脏读的不同之处在于,脏读是读取了另一个事务没有提交的脏数据,不可重复读是读取了已经提交的数据,实际上并不是一个异常现象。
不可重复度和幻读的不同之处在于,幻读是多次读取的结果行数不同,不可重复度是读取结果的值不同。
避免不可重复读需要锁行,避免幻读则需要锁表。
6.9 数据库事务、隔离级别
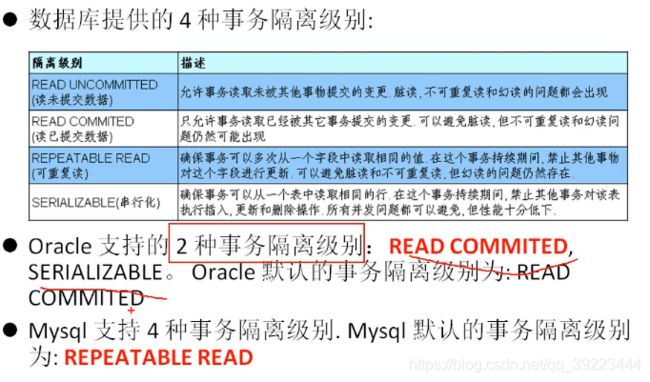
事务的隔离级别:
| 脏读 | 不可重复读 | 幻读 | |
|---|---|---|---|
| read uncommitted | √ | √ | √ |
| read committed | × | √ | √ |
| repeatable read | × | × | √ |
| serializable | × | × | × |
6.10 索引的底层实现(为什么要用B+树,为什么不用红黑树和B树)
数据库的索引是使用B+树来实现的。
B+树是一种特殊的平衡多路树,是B树的优化改进版本,它把所有的数据都存放在叶节点上,中间节点保存的是索引。这样一来相对于B树来说,减少了数据对中间节点的空间占用,使得中间节点可以存放更多的指针,使得树变得更矮,深度更小,从而减少查询的磁盘IO次数,提高查询效率。另一个是由于叶节点之间有指针连接,所以可以进行范围查询,方便区间访问。
而红黑树是二叉的,它的深度相对B+树来说更大,更大的深度意味着查找次数更多,更频繁的磁盘IO,所以红黑树更适合在内存中进行查找。
6.11 最左前缀匹配
b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+树是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道第一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。
联合索引:
假如我们对a b c三个字段建立了联合索引,在联合索引中,从最左边的字段开始,任何连续的索引都能匹配上,当遇到范围查询的时候停止。比如对于联合索引index(a,b,c),能匹配a,ab,abc三组索引。并且对查询时字段的顺序没有限制,也就是a,b,c; b,a,c; c,a,b; c,b,a都可以匹配。
最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。=和in可以乱序。
6.12 MySQL的存储引擎
- InnoDB : InnoDB是mysql的默认引擎,支持事务和外键,支持容灾恢复。适合更新频繁和多并发的表行级锁,是为处理巨大数据量的最大性能设计。InnoDB的数据文件本身就是索引文件,InnoDB支持MVCC
- MylSAM:插入和查询速度比较高,支持大文件,但是不支持事务,适合在web和数据仓库场景下使用表级锁,不支持MVCC
- MEMORY : memory将表中的数据保存在内存里,适合数据比较小而且频繁访问的场景
- Archive:如果只有INSERT和SELECT操作,可以选择Archive,Archive支持高并发的插入操作,但是本身不是事务安全的。Archive非常适合存储归档数据,如记录日志信息可以使用Archive
来自Mysql 存储引擎的区别和比较
InnoDB :如果要提供提交、回滚、崩溃恢复能力的事务安全(ACID兼容)能力,并要求实现并发控制,InnoDB是一个好的选择
InnoDB 和 MyISAM之间的区别:
1>.InnoDB支持事物,而MyISAM不支持事物
2>.InnoDB支持行级锁,而MyISAM支持表级锁
3>.InnoDB支持MVCC, 而MyISAM不支持
4>.InnoDB支持外键,而MyISAM不支持
5>.InnoDB不支持全文索引,而MyISAM支持。(X)
MyISAM:如果数据表主要用来插入和查询记录,则MyISAM(但是不支持事务)引擎能提供较高的处理效率
Memory:如果只是临时存放数据,数据量不大,并且不需要较高的数据安全性,可以选择将数据保存在内存中的Memory引擎,MySQL中使用该引擎作为临时表,存放查询的中间结果。数据的处理速度很快但是安全性不高。
Archive:如果只有INSERT和SELECT操作,可以选择Archive,Archive支持高并发的插入操作,但是本身不是事务安全的。Archive非常适合存储归档数据,如记录日志信息可以使用Archive
使用哪一种引擎需要灵活选择,一个数据库中多个表可以使用不同引擎以满足各种性能和实际需求,使用合适的存储引擎,将会提高整个数据库的性能
6.13 数据的锁的种类
以MYSQL为例,
- 按照类型来分有乐观锁和悲观锁
- 根据粒度来分有行级锁,页级锁,表级锁(粒度一个比一个大)(仅BDB,Berkeley Database支持页级锁)
- 根据作用来分有共享锁(读锁)和排他锁(写锁)。
6.14 什么是共享锁和排他锁
SELECT 的读取锁定主要分为两种方式:共享锁和排他锁。
select * from table where id<6 lock in share mode;--共享锁
select * from table where id<6 for update;--排他锁
这两种方式主要的不同在于LOCK IN SHARE MODE多个事务同时更新同一个表单时很容易造成死锁。
申请排他锁的前提是,没有线程对该结果集的任何行数据使用排它锁或者共享锁,否则申请会受到阻塞。在进行事务操作时,MySQL会对查询结果集的每行数据添加排它锁,其他线程对这些数据的更改或删除操作会被阻塞(只能读操作),直到该语句的事务被commit语句或rollback语句结束为止。
- 共享锁是读操作的时候创建的锁,一个事务对数据加上共享锁之后,其他事务只能对数据再加共享锁,不能进行写操作直到释放所有共享锁。
- 排他锁是写操作时创建的锁,事务对数据加上排他锁之后其他任何事务都不能对数据加任何的锁(即其他事务不能再访问该数据)
SELECT... FOR UPDATE 使用注意事项:
for update 仅适用于Innodb,且必须在事务范围内才能生效。
根据主键进行查询,查询条件为 like或者不等于,主键字段产生表锁。
根据非索引字段进行查询,name字段产生表锁。
6.15 乐观锁和悲观锁
一般的数据库都会支持并发操作,在并发操作中为了避免数据冲突,所以需要对数据上锁,乐观锁和悲观锁就是两种不同的上锁方式。
- 悲观锁假设数据在并发操作中一定会发生冲突,所以在数据开始读取的时候就把数据锁住。
- 而乐观锁则假设数据一般情况下不会发生冲突,所以在数据提交更新的时候,才会检测数据是否有冲突。
6.16 MySQL的优化,高并发的解决方案(高频,索引优化,性能优化)
高频访问:
- 分表分库:将数据库表进行水平拆分,减少表的长度。
- 增加缓存:在web和DB之间加上一层缓存层,将高频访问的数据存入缓存中,减少数据库的读取负担(放进redis中缓存)
- 增加数据库的索引:在合适的字段加上索引,解决高频访问的问题
- 使用Myisam存储引擎会记录表记录数量(针对select count(*) 慢的问题)
并发优化: - 主从读写分离:只在主服务器上写,从服务器上读
- 负载均衡集群:通过集群或者分布式的方式解决并发压力
6.16 MySQL中查询所有数据库
MySQL中查询所有数据库
show databases;
MySQL数据库中查询所有表
show tables;
查看其他库的表:
show tables from 库名;
查看当前库:
select database();
查看表结构
desc 表名;
6.17 数据库连接池的作用
对于一个简单的数据库应用,由于对于数据库的访问不是很频繁。这时可以简单地在需要访问数据库时,就新创建一个连接,用完后就关闭它,这样做也不会带来什么明显的性能上的开销。但是对于一个复杂的数据库应用,情况就完全不同了。频繁的建立、关闭连接,会极大的减低系统的性能,因为对于连接的使用成了系统性能的瓶颈。
通过建立一个数据库连接池以及一套连接使用管理策略,使得一个数据库连接可以得到高效、安全的复用,避免了数据库连接频繁建立、关闭的开销。
数据库连接池的基本原理是在内部对象池中维护一定数量的数据库连接,并对外暴露数据库连接获取和返回方法。如:
外部使用者可通过getConnection 方法获取连接,使用完毕后再通过releaseConnection方法将连接返回,注意此时连接并没有关闭,而是由连接池管理器回收,并为下一次使用做好准备。
作用:
1. 资源重用
由于数据库连接得到重用,避免了频繁创建、释放连接引起的大量性能开销。在减少系统消耗的基础上,另一方面也增进了系统运行环境的平稳性(减少内存碎片以及数据库临时进程/线程的数量)。
2. 更快的系统响应速度
数据库连接池在初始化过程中,往往已经创建了若干数据库连接置于池中备用。此时连接的初始化工作均已完成。对于业务请求处理而言,直接利用现有可用连接,避免了数据库连接初始化和释放过程的时间开销,从而缩减了系统整体响应时间。
3. 新的资源分配手段
对于多应用共享同一数据库的系统而言,可在应用层通过数据库连接的配置,实现数据库连接池技术,某一应用最大可用数据库连接数的限制,避免某一应用独占所有数据库资源。
4. 统一的连接管理,避免数据库连接泄漏
在较为完备的数据库连接池实现中,可根据预先的连接占用超时设定,强制收回被占用连接。从而避免了常规数据库连接操作中可能出现的资源泄漏。
6.18 数据库的聚合函数有哪些?
sum 求和、avg 平均值、max 最大值 、min 最小值 、count 计算个数
MYISAM存储引擎下 ,COUNT(*)的效率高
INNODB存储引擎下,COUNT(*)和COUNT(1)的效率差不多,比COUNT(字段)要高一些
6.19 数据库里如果select A, B from 表 group by A 可以么?
SQL的grop by 语法为:
select 选取分组中的列+聚合函数 from 表名称 group by 分组的列
从语法格式来看,是先有分组,再确定检索的列,检索的列只能在参加分组的列中选。
所以group by 后的 a,b,c是先确定的,select后的a,b,c才是可以变的。即
在返回集字段中,这些字段要么就要包含在Group By语句的后面,作为分组的依据;要么就要被包含在聚合函数中。

6.20 union和union all的区别
MySQL中不支持全连接
每种join都有on,on的是左表和右表中都有的字段。join之前要确保关联键是否去重,是不是刻意保留非去重结果。
两张表数据的字段一样,想合并起来,怎么办?–union
union和union all均基于列合并多张表的数据,所合并的列格式必须完全一致。union的过程中会去重并降低效率,union all直接追加数据。
6.21 limit 2,1和limit 2 offset 1的区别是什么?
limit 2,1为跳过2条取出1条数据,limit后面是从第2条开始读,读取1条信息,即读取第3条数据
limit 2 offset 1从第1条(不包括)数据开始取出2条数据,limit后面跟的是2条数据,offset后面是从第1条开始读取,即读取第2,3条。
6.22 sql中过滤条件放在on和where中的区别
inner join:结果没有区别
- 前者是先求笛卡尔积然后按照on后面的条件进行过滤
- 后者是先用on后面的条件过滤,再用where的条件过滤。
- 但是两者的结果是一样的
left join、right join:使用left join(right join)时on后面的条件只对右表(左表)有效。
- join过程可以这样理解: where的执行顺序在join之后,on执行在join之中。
- 由于join要求索引列保留,所以对于left join来说on对右表生效
- 但是在左连接之后使用where,就能明显看到起到了过滤作用\
6.23 普通聚合函数vS窗口函数
本质上说,窗口函数还是聚合运算。只不过它更具灵活性。它对数据的每一行,都使用与该行相关的行进行计算并返回计算结果
二者区别:
聚合函数是将多条记录聚合为一条;
而窗口函数是每条记录都会执行,有几条记录执行完还是几条。
聚合函数也可以用于窗口函数
6.24数据库里同时对两个字段排序,一个升序一个降序,可以么。
6.25 N层满二叉树(完全二叉树)的节点个数是多少?
- n层二叉树的第n层最多为2^(n-1)个
- 一个深度为n的完美二叉树的总结点数 2 n − 1 2^n-1 2n−1
- 深度为n的完全二叉树至少有 2 n − 1 2^n−^1 2n−1 个结点,最多有 2 n − 1 2^n-1 2n−1个结点
- 具有n个节点的完全二叉树的深度为 l o g 2 n + 1 log_2 n+1 log2n+1
- 二叉树节点计算公式 N = n 0 + n 1 + n 2 N = n_0 + n_1 + n_2 N=n0+n1+n2, N = n 1 + 2 n 2 + 1 N=n_1+2n_2+1 N=n1+2n2+1,度为0的叶子节点比度为2的节点数多一个。
若总结点数为999这样的奇数,999/2 = 499.5 ,那么叶子结点就有500个,度为2的节点为499个,度为1的节点为0个。
若总结点数为1500这样的偶数,1500/2 = 750 ,那么叶子节点就有750个,度为2的节点就有749个,度为1的节点为1个
6.26 关系型和非关系型数据库的区别(低频)
关系型数据库的优点
- 容易理解。因为它采用了关系模型来组织数据。
- 可以保持数据的一致性。
- 数据更新的开销比较小。
- 支持复杂查询(带where子句的查询)
非关系型数据库的优点
- 不需要经过sql层的解析,读写效率高。
- 基于键值对,数据的扩展性很好。
- 可以支持多种类型数据的存储,如图片,文档等等。
适合使用非关系型数据库的场景: 1. 日志系统 2. 地理位置存储 3. 数据量巨大 4. 高可用
6.27 数据库的范式
- 第一范式(确保每列保持原子性)
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。 - 第二范式(确保表中的每列都和主键相关)
在满足第一范式的前提下,(主要针对联合主键而言)第二范式需要确保数据库表中的每一列都和主键的所有成员直接相关,由整个主键才能唯一确定,而不能只与主键的某一部分相关或者不相关。
比如一张学生信息表,由主键(学号)可以唯一确定一个学生的姓名,班级,年龄等信息。但是主键(学号,班级)与列姓名,班主任,教室就不符合第二范式,因为班主任跟部分主键(班级)是依赖关系 - 第三范式(确保非主键的列没有传递依赖)
在满足第二范式的前提下,第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。非主键的列不能确定其他列,列与列之间不能出现传递依赖。
比如一张学生信息表,主键是(学号)列包括姓名,班级,班主任就不符合第三范式,因为非主建的列中班主任依赖于班级
6.28 in和exists的区别
- in()适合B表比A表数据小(或者in内是固定项)的情况
- exists()适合B表比A表数据大的情况
- 当A表数据与B表数据一样大时,in与exists效率差不多,可任选一个使用.优先使用exists,因为exists能使用索引。
exists()结果集的内容并不重要,重要的是结果集中是否有记录,如果有则返回true,没有则返回false.
6.29 增删查改
DML:
select * from 表名; 【查】
insert into 表名 (列1,列2) values(值1,值2);【增】
insert into 表名 set 列名=值【增】
update danah set name=‘rose’ where id=2; 【改】
delete from 表名 where id=1; 【删】
DDL:
库
create database [if not exists]库名 [character set 字符集名];【库的创建】
ALTER DATABASE books CHARACTER SET gbk; 【库的修改】
DROP DATABASE IF EXISTS books; 【库的删除】
表
create table 表名(
列名 列的类型【(长度) 约束】,
列名 列的类型【(长度) 约束】,
列名 列的类型【(长度) 约束】,
...
列名 列的类型【(长度) 约束】)
1.添加列
alter table 表名 add column 列名 类型 【first|after 字段名】;
2.修改列的类型或约束
alter table 表名 modify column 列名 新类型 【新约束】;
3.修改列名
alter table 表名 change column 旧列名 新列名 类型;
4 .删除列
alter table 表名 drop column 列名;
5.修改表名
alter table 表名 rename 【to】 新表名;
6.修改字段缺省值
ALTER TABLE 表名 ALTER i SET DEFAULT 1000;
DROP TABLE IF EXISTS book_author;
#1.仅仅复制表的结构
CREATE TABLE copy LIKE author;
#2.复制表的结构+数据
CREATE TABLE copy2
SELECT * FROM author;
6.30 模糊查询与通配符
like
特点:一般和通配符搭配使用,可以判断字符型或数值型。
通配符:
% 任意多个字符,包含0个字符
_ 任意单个字符
6.31 select * from employees; 和 select * from employees where commission_pct like ‘%%’ and last_name like ‘%%’;结果是否一样?并说明原因。
不一样。如果判断的字段有null值,结果就不一样,如果没有null值,就一样。
6.32 字符、时间、流程控制函数
- concat 拼接字符串 concat(a,b)
- substr、substring截取从指定索引处指定字符长度的字符substr(字符串,1,3)
- instr 返回子串第一次出现的索引,如果找不到返回0
instr(字符串,字符) - trim 去掉首尾字符
- now 返回当前系统日期+时间
SELECT NOW(); - str_to_date 将字符通过指定的格式转换成日期
- date_format 将日期转换成字符
IF(10<5,'大','小')
6.33 SQL语句分类
DQL:数据查询语言,用于对数据进行查询,如select
DML:数据操作语言,对数据进行增加、修改、删除,如insert、udpate、delete
TPL:事务处理语言,对事务进行处理,包括begin transaction、commit、rolback
DDL:数据定义语言,进行数据库、表的管理等,如create、drop
6.34 常用的三种插入数据的语句
- insert into表示插入数据,数据库会检查主键,如果出现重复会报错;
- replace into表示插入替换数据,若表中有PrimaryKey,或者unique索引,如果数据库已经存在数据,则用新数据替换,如果没有数据效果则和insert into一样;
- insert ignore表示,如果中已经存在相同的记录,则忽略当前新数据;
6.35 经典面试题:delete pk truncate
1.delete 可以加where 条件,truncate不能加
2.truncate删除,效率高一丢丢
3.假如要删除的表中有自增长列,
如果用delete删除后,再插入数据,自增长列的值从断点开始,
而truncate删除后,再插入数据,自增长列的值从1开始。表结构被删除。
4.truncate删除没有返回值,delete删除有返回值
5.truncate删除不能回滚,delete删除可以回滚.
6.36 MyISAM 与 InnoDB 区别:
- InnoDB 支持事务,MyISAM 不支持,这一点是非常之重要。事务是一种高级的处理方式,如在一些列增删改中只要哪个出错还可以回滚还原,而 MyISAM就不可以了;
- MyISAM 适合查询以及插入为主的应用,InnoDB 适合频繁修改以及涉及到安全性较高的应用;
- InnoDB 支持外键,MyISAM 不支持;
- 对于自增长的字段,InnoDB 中必须包含只有该字段的索引,但是在 MyISAM表中可以和其他字段一起建立联合索引;
- 清空整个表时,InnoDB 是一行一行的删除,效率非常慢。MyISAM 则会重建表;
6.37 计算中位数
# 仅计算位置
select id,
company,
salary
from(select
id,
company,
salary,
cast(row_number() over(partition by company order by salary asc, id asc) as signed) as 'id1',
cast(row_number() over(partition by company order by salary desc, id desc) as signed) as 'id2'
from employee) as newtable
where abs(id1-id2)=1 or
id1=id2;
# 仅计算位置
SELECT job,
floor(( count(*) + 1 )/ 2 ) AS "start",
ceil(( count(*) + 1 )/ 2 ) AS 'end'
FROM grade
GROUP BY job
ORDER BY job
6.38 水平切分、垂直切分
水平拆分:可以通过地区、年份,索引取模等进行拆分
水平拆分的优点:
◆表关联基本能够在数据库端全部完成;
◆不会存在某些超大型数据量和高负载的表遇到瓶颈的问题;
◆应用程序端整体架构改动相对较少;
◆事务处理相对简单;
◆只要切分规则能够定义好,基本上较难遇到扩展性限制;
水平切分的缺点:
◆切分规则相对更为复杂,很难抽象出一个能够满足整个数据库的切分规则;
◆后期数据的维护难度有所增加,人为手工定位数据更困难;
◆应用系统各模块耦合度较高,可能会对后面数据的迁移拆分造成一定的困难。
垂直拆分:指数据表列的拆分,把一张列比较多的表拆分为多张表。表的记录并不多,但是字段却很长,表占用空间很大,检索表的时候需要执行大量的IO,严重降低了性能。这时需要把大的字段拆分到另一个表,并且该表与原表是一对一的关系。
通常我们按以下原则进行垂直拆分:
1,把不常用的字段单独放在一张表;,
2,把text,blob等大字段拆分出来放在附表中;
3,经常组合查询的列放在一张表中;
垂直切分的优点
◆ 数据库的拆分简单明了,拆分规则明确;
◆ 应用程序模块清晰明确,整合容易;
◆ 数据维护方便易行,容易定位;
垂直切分的缺点
◆ 部分表关联无法在数据库级别完成,需要在程序中完成;
◆ 对于访问极其频繁且数据量超大的表仍然存在性能平静,不一定能满足要求;
◆ 事务处理相对更为复杂;
◆ 切分达到一定程度之后,扩展性会遇到限制;
◆ 过读切分可能会带来系统过渡复杂而难以维护。
6.39 索引失效的情况
- mysql中like查询是以%开头,索引会失效变成全表扫描,覆盖索引
- mysql中,如果条件中有or,即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因)。要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引
- mysql中,字符串不加单引号索引会失效
- 如果mysql使用全表扫描要比使用索引快,则不会使用到索引
- mysql中使用is not null 或者 is null会导致无法使用索引
- 在索引列上做任何操作(计算,函数,(自动或者手动)类型装换),会导致索引失效而导致全表扫描
- 对于多列索引,不是使用的第一部分(第一个),则不会使用索引
6.40 数据库索引结构
二叉树: 二叉树是一种比顺序结构更加高效地查找目标元素的结构,它可以从第一个父节点开始跟目标元素值比较,如果相等则返回当前节点,如果目标元素值小于当前节点,则移动到左侧子节点进行比较,大于的情况则移动到右侧子节点进行比较,反复进行操作最终移动到目标元素节点位置。
在大部分情况下,我们设计索引时都会在表中提供一个自增整形字段作为建立索引的列,在这种场景下使用二叉树的结构会导致我们的索引总是添加到右侧,在查找记录时跟没加索引的情况是一样的。
红黑树: 在二叉树的基础上多了树平衡,也叫二叉平衡树,它不仅继承了二叉树的优点,而且解决了上面二叉树遇到的自增整形索引的问题,不像二叉树那样极端的情况会往一个方向发展。
红黑树会左旋、右旋对结构进行调整,始终保证左子节点数 < 父节点数 < 右子节点数的规则。
数据量大的时候,深度也很大
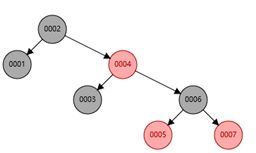
同样我们查找6,在二叉树中我们需要经过6个节点才能找到(1-2-3-4-5-6),红黑树中我们只需要3个节点(2-4-6),但是mysql索引的数据结构并不是红黑树,因为如果数据量大了之后,树的高度就会很大。因为每个节点只能存在两个子节点
B树: 既然红黑树存在缺点,那么我们可以在红黑树的基础上构思一种新的储存结构。解决的思路也很简单,既然觉得树的深度太长,就只需要适当地增加每个树节点能存储的数据个数即可,但是数据个数也必须要设定一个合理的阈值,不然一个节点数据个数过多会产生多余的消耗。
- 度(Degree)-节点的数据存储个数,每个树节点中数据个数大于 15/16*Degree(未验证) 时会自动分裂,调整结构
- 叶节点具有相同的深度,左子树跟右子树的深度一致
- 叶节点的指针为空
- 节点中的数据key从左到右递增排列
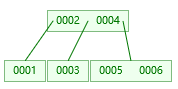
特别说明:BTree的结构里每个节点包含了索引值和表记录的信息,我们可以按照Map集合这样理解:key=索引,value=表记录,如下图所示:
弥补红黑树的缺点,解决数据量过大时整棵树的深度过长的问题。相同数量的数据只需要更少的层,相同深度的树可以存储更多的数据,查找的效率自然会更高。
从上面得知,在查询单条数据是非常快的。但如果范围查的话,BTree结构每次都要从根节点查询一遍,效率会有所降低。
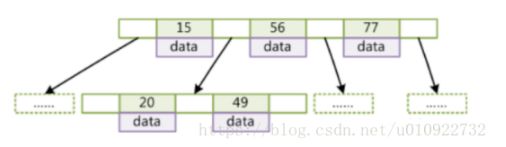
B+树: B+树只有叶子节点存储数据,只在最下层的叶子节点存储数据,上层的非叶子节点只存放索引信息,这样的结构可以让单个节点放下更多索引值,增大度degree的值,提高命中目标记录的几率。
这样的结构会在上层非叶子节点存储一部分冗余数据,但是这样的缺点是可以容忍的,因为荣誉的都是索引数据,不会对内存造成太大的负担,
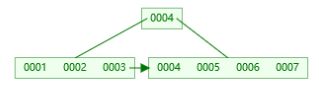
而B+树则不同,它只会在叶子节点上面挂载数据,非叶子节点不会存放数据,数据只会存在叶子节点上面,非叶子节点只存放索引列的数据
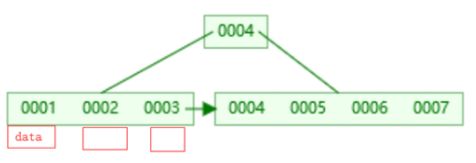
6.41 B+树
索引是一个为了加快查询速度而使用的数据结构。mySql中通过B+树实现了索引。
B+树的一个特点是数据只保存在叶子节点中,而且叶子节点间形成一个单链表,适合进行区间查找。mySql根据这个特性,将叶子节点和非叶节点保存在不同的段中,而每个段包含多个区,每个区以数据块形式保存,这样在实际查询数据时可以使用顺序io而非随机io。
6.42 数据库的分页
当要显示的数据,一页显示不全,需要分页提交sql请求
limit 【offset,】size;
offset要显示条目的起始索引(起始索引从0开始)
size 要显示的条目个数
limit (page-1)*size,size;
6.43 数据库的分表
什么情况下分表合适?
针对存储了百万级乃至千万级条记录的大表。数据库在查询和插入的时候耗时太长,可通过分表,将大表拆分成小表,提升数据库性能。
分表的原则:
对于数据量不大的表,在满足现有性能的前提下,能不拆分就不拆分。
针对不同的业务,采取合适的拆分准则。对于大表特定列之间业务耦合性低,可采用垂直分表。对大表列数耦合性高,或者列数不多行数多的情况下,可按照某个字段的某种规则来分散到多个表之中。
6.44 数据拷贝,复制
insert into table1 select * from table2
create table tablename1 like database.tablename2
6.45 数据库存储过程
类似于方法,一组预先编译好的SQL语句的集合,成批处理数据
提高代码的重用性,简化操作,减少了编译次数并且减少了和数据库的连接次数,提高效率,可以有一个返回,也可以有多个返回,适合批量插入、批量更新
6.46 在用户量不断增加,点击次数或查询次数非常大且越来越大时,设计数据库应该怎么考虑
6.47 如果正常按索引查询结果发现数据库依然是逐个比较查询的,可能是什么原因呢
6.48 sql查询慢的原因
1、没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷)
2、I/O吞吐量小,形成了瓶颈效应。
3、没有创建计算列导致查询不优化。
4、内存不足
5、网络速度慢
6、查询出的数据量过大(可以采用多次查询,其他的方法降低数据量)
7、锁或者死锁(这也是查询慢最常见的问题,是程序设计的缺陷)
8、sp_lock,sp_who,活动的用户查看,原因是读写竞争资源。
9、返回了不必要的行和列
10、查询语句不好,没有优化
优化:
1、把数据、日志、索引放到不同的I/O设备上,增加读取速度,以前可以将Tempdb应放在RAID0上,SQL2000不在支持。数据量(尺寸)越大,提高I/O越重要.
2、纵向、横向分割表,减少表的尺寸(sp_spaceuse)
3、升级硬件
4、根据查询条件,建立索引,优化索引、优化访问方式,限制结果集的数据量。
5、提高网速;
6、扩大服务器的内存
6.49 索引的设计原则
- 索引列的区分度越高,索引的效果越好
- 尽量使用短索引,对于较长的字符串进行索引时应该指定一个较短的前缀长度,因为较小的索引涉及到的磁盘I/O较少,并且索引高速缓存中的块可以容纳更多的键值,会使得查询速度更快。
- 索引不是越多越好,每个索引都需要额外的物理空间,维护也需要花费时间。
- 利用最左前缀原则
6.50 mysql执行计划
通过 explain 命令获取 select 语句的执行计划,了解 select 语句以下信息:
表的加载顺序
sql 的查询类型
可能用到哪些索引,实际上用到哪些索引
读取的行数
6.51 MySQL中int(10)和char(10)的区别?
int(10)中的10表示的是显示数据的长度,而char(10)表示的是存储数据的长度。
6.52 truncate、delete与drop区别?
相同点:
truncate和不带where子句的delete、以及drop都会删除表内的数据。
drop、truncate都是DDL语句(数据定义语言),执行后会自动提交。
不同点:
truncate 和 delete 只删除数据不删除表的结构;drop 语句将删除表的结构被依赖的约束、触发器、索引;
一般来说,执行速度: drop > truncate > delete。
6.53 sql执行过程
查询语句的执行流程如下:权限校验、查询缓存、分析器、优化器、权限校验、执行器、引擎。
举个例子,查询语句如下:
select * from user where id > 1 and name = '大彬';
首先检查权限,没有权限则返回错误;
MySQL以前会查询缓存,缓存命中则直接返回,没有则执行下一步;
词法分析和语法分析。提取表名、查询条件,检查语法是否有错误;
两种执行方案,先查 id > 1 还是 name = ‘大彬’,优化器根据自己的优化算法选择执行效率最好的方案;
校验权限,有权限就调用数据库引擎接口,返回引擎的执行结果。
7. 数据挖掘
见数据挖掘相关算法
8. linux
很多参考这篇博客Linux常用命令,真的很好,推荐去看
8.1 Linux 压缩和打包命令
打包和压缩
Windows的压缩文件的扩展名 .zip/.rar
linux中的打包文件:aa.tar
linux中的压缩文件:bb.gz
linux中打包并压缩的文件:.tar.gz
Linux中的打包文件一般是以.tar结尾的,压缩的命令一般是以.gz结尾的。
而一般情况下打包和压缩是一起进行的,打包并压缩后的文件的后缀名一般.tar.gz。
命令:tar -zcvf 打包压缩后的文件名 要打包的文件
其中:z:调用gzip压缩命令进行压缩
c:打包文件
v:显示运行过程
f:指定文件名
示例:打包并压缩/usr/tmp 下的所有文件 压缩后的压缩包指定名称为xxx.tar
tar -zcvf ab.tar aa.txt bb.txt 或:tar -zcvf ab.tar *
解压
命令:tar [-zxvf] 压缩文件
其中:x:代表解压
示例:将/usr/tmp 下的ab.tar解压到当前目录下
tar -zxvf ab.tar
将/usr/tmp 下的ab.tar解压到根目录/usr下
tar -xvf ab.tar -C /usr ------C代表指定解压的位置
8.2 查看文件
- cat 与 tac
cat的功能是将文件从第一行开始连续的将内容输出在屏幕上。当文件大,行数比较多时,屏幕无法全部容下时,只能看到一部分内容。
cat语法: cat [-n] 文件名 (-n:显示时,连行号一起输出)
tac的功能是将文件从最后一行开始倒过来将内容数据输出到屏幕上。我们可以发现,tac实际上是cat反过来写。这个命令不常用。
tac语法: tac 文件名。
- more和less(常用)
more的功能是将文件从第一行开始,根据输出窗口的大小,适当的输出文件内容。当一页无法全部输出时,可以用“回车键"向下翻行,用“空格键”向下翻页。退出查看页面,请按“q”键。另外,more还可以配合管道符“|”(pipe)使用,例如: ls -al | more
Linux下查看文件内容的命令
more的语法: more 文件名
Enter向下n行,需要定义,默认为1行
ctrl f 向下滚动一屏
空格键 向下滚动一屏
Ctrl b 返回上一屏
= 输出当前行的行号
:f输出文件名和当前行的行号
v 调用vi编辑器
! 命令调用Shell,并执行命令
q退出more
less的功能和more相似,但是使用more无法向前翻页,只能向后翻。
less可以使用【pageup】和【pagedown】键进行前翻页和后翻页,这样看起来更方便。
less的语法: less 文件名
- head和tail
head和tail通常使用在只需要读取文件的前几行或者后几行的情况下使用。
head的功能是显示文件的前几行内容
head的语法: head [n number] 文件名(number 显示行数)
tail的功能恰好和head相反,只显示最后几行内容
tail的语法: tail [-n number] 文件名
- nl
nl的功能和cat -n一样,同样是从第一行输出全部内容,并且把行号显示出来
nl的语法:nl 文件名
8.3 查看后台进程
- jobs
查看当前控制台的后台进程
想要停止后台进程,使用jobs命令查看其进程号(比如为num),然后kill %num即可 - ps
查看后台进程 - top
查看所有进程和资源使用情况,类似Windows中的任务管理器
停止进程:界面是交互式的,在窗口输入k之后输入PID,会提示输入停止进程模式 有SIGTERM和SIGKILL,如果留空不输入,就是SIGTERM(优雅停止)
退出top:输入q即可
8.4 删除当前文件夹下2018年-2019年文件命令
rm -rf 文件名
8.5 修改文件权限命令、有哪些权限
rwx:r代表可读,w代表可写,x代表该文件是一个可执行文件,如果rwx任意位置变为-则代表不可读或不可写或不可执行文件。
示例:给aaa.txt文件权限改为可执行文件权限,aaa.txt文件的权限是-rw- --- ---
第一位:-就代表是文件,d代表是文件夹
第一段(3位):代表拥有者的权限
第二段(3位):代表拥有者所在的组,组员的权限
第三段(最后3位):代表的是其他用户的权限
421 421 421
- rw- --- ---
代表拥有者可读可写,不可执行,组员和其他用户没有任何权限
9.计算机网络
9.1 http协议与TCP的区别与联系
联系: Http协议是建立在TCP协议基础之上的,当浏览器需要从服务器获取网页数据的时候,会发出一次Http请求。Http会通过TCP建立起一个到服务器的连接通道,当本次请求需要的数据传输完毕后,Http会立即将TCP连接断开,这个过程是很短的。
区别:HTTP和TCP位于不同的网络分层。TCP是传输层的协议,定义的是数据传输和连接的规范,而HTTP是应用层的,定义的是数据的内容的规范。
建立一个TCP请求需要进行三次握手,而由于http是建立在tcp连接之上的,建立一个http请求通常包含请求和响应两个步骤。
9.2 http的状态码403 201等等是什么意思
常见的状态码有:
- 200 -请求成功
- 301 -资源(网页等)被永久转移到其它URL
- 404-请求的资源(网页等)不存在
- 500–内部服务器错误
- 400-请求无效
- 403-禁止访问
9.3 http和https的区别,由http升级为https需要做哪些操作
http是超文本传输协议,信息是明文传输,https 则是具有安全性的ssl加密传输协议
http和 https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443
http的连接很简单,是无状态的; HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http 协议安全。
https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用
9.4 一个机器能够使用的端口号上限是多少,为什么?可以改变吗?那如果想要用的端口超过这个限制怎么办?
65536.因为TCP的报文头部中源端口号和目的端口号的长度是16位,也就是可以表示2^16=65536个不同端口号,因此TCP可供识别的端口号最多只有65536个。但是由于0到1023是知名服务端口,所以实际上还要少1024个端口号。
而对于服务器来说,可以开的端口号与65536无关,其实是受限于Linux可以打开的文件数量,并且可以通过MaxUserPort来进行配置。
9.5 单条记录高并发访问的优化
服务器端:
- 使用缓存,如redis等
- 使用分布式架构进行处理
- 将静态页面和静态资源存储在静态资源服务器,需要处理的数据使用服务器进行计算后返回。将静态资源尽可能在客户端进行缓存
- 采用ngnix进行负载均衡( nginx读作恩静埃克斯= Engine X)
数据库端:
- 数据库采用主从赋值,读写分离措施。
- 建立适当的索引
- 分库分表
9.6 一个ip配置多个域名,靠什么识别?
靠host主机名区分
靠端口号区分
9.7 OSA七层协议和五层协议,分别有哪些

10. 大数据
10.1 介绍一下Hadoop
Hadoop是一套大数据解决方案,提供了一套分布式的系统基础架构,包括HDFS,MapReduce和YARN。
- HDFS提供分布式的数据存储.
- MapReduce负责进行数据运算
- YARN负责任务调度
HDFS是主从架构的,包括namenode,secondarynamenode和datanode。datanode负责存储数据,namenode负责管理HDFS的目录树和文件元信息。
MapReduce包括jobtracker,tasktracker和client。Jobtracker负责进行资源调度和作业监控。tasktracker会周期性的通过心跳向jobtracker汇报资源使用情况。
10.2 说一下MapReduce的运行机制
MapReduce包括输入分片、map阶段、combine阶段、shuffle阶段和reduce阶段。分布式计算框架包括client,jobtracker和tasktracker和调度器。
- 输入分片阶段,mapreduce会根据输入文件计算分片,每个分片对应一个map任务
- map阶段会根据mapper方法的业务逻辑进行计算,映射成键值对
- combine阶段是在节点本机进行一个reduce,减少传输结果对带宽的占用
- shuffle阶段是对map阶段的结果进行分区,排序,溢出然后写入磁盘。将map端输出的无规则的数据整理成为有一定规则的数据,方便reduce端进行处理,有点像洗牌的逆过程。
- educe阶段是根据reducer方法的业务逻辑进行计算,最终结果会存在hdfs上。
10.3 介绍一下spark
spark是一个通用内存并行计算框架。它可以在内存中对数据进行计算,效率很高,spark的数据被抽象成RDD(弹性分布式数据集)并且拥有DAG执行引擎,兼容性和通用性很好。可以和Hadoop协同工作。
11. 智力题
大厂常考
11.1 100层楼,只有2个鸡蛋,想要判断出那一层刚好让鸡蛋碎掉,给出策略(滴滴笔试中两个铁球跟这个是一类题)
- (给定了楼层数和鸡蛋数的情况)二分法+线性查找从100/2=50楼扔起,如果破了就用另一个从0扔起直到破。如果没破就从50/2=25楼扔起,重复。
- 动态规划
11.2 毒药问题,1000瓶水,其中有一瓶可以无限稀释的毒药,要快速找出哪一瓶有毒,需要几只小白鼠
用二进制的思路解决问题。2的十次方是1024,使用十只小鼠喝一次即可。方法是先将每瓶水编号,同时10个小鼠分别表示二进制中的一个位。将每瓶水混合到水瓶编号中二进制为1的小鼠对应的水中。喝完后统计,将死亡小鼠对应的位置为1,没死的置为0,根据死亡小鼠的编号确定有毒的是哪瓶水,如0000001010表示10号水有毒。
11.3 先手必胜策略问题:100本书,每次能够拿1-5本,怎么拿能保证最后一次是你拿
寻找每个回合固定的拿取模式。最后一次是我拿,那么上个回合最少剩下6本。那么只要保持每个回合结束后都剩下6的倍数,并且在这个回合中我拿的和对方拿的加起来为6(这样这个回合结束后剩下的还是6的倍数),就必胜。关键是第一次我必须先手拿(100%6=4)本(这不算在第一回合里面)。
11.4 放n只蚂蚁在一条树枝上,蚂蚁与蚂蚁之间碰到就各自往反方向走,问总距离或者时间。
碰到就当没发生,继续走,相当于碰到的两个蚂蚁交换了一下身体。其实就是每个蚂蚁从当前位置一直走直到停止的总距离或者时间。
11.5 瓶子换饮料问题:1000瓶饮料,3个空瓶子能够换1瓶饮料,问最多能喝几瓶
拿走3瓶,换回1瓶,相当于减少2瓶。但是最后剩下4瓶的时候例外,这时只能换1瓶。所以我们计算1000减2能减多少次,直到剩下4.(1000-4=996,996/2=498)所以1000减2能减498次直到剩下4瓶,最后剩下的4瓶还可以换一瓶,所以总共是1000+498+1=1499瓶。
11.6 有一个天平,九个砝码,一个轻一些,用天平至少几次能找到轻的?
至少2次:第一次,一边3个,哪边轻就在哪边,一样重就是剩余的3个;
第二次,一边1个,哪边轻就是哪个,一样重就是剩余的那个;
11.7 有十组砝码每组十个,每个砝码重10g,其中一组每个只有9g,有能显示克数的秤最少几次能找到轻的那一组砝码?
砝码分组1~10,第一组拿一个,第二组拿两个以此类推。。第十组拿十个放到秤上称出克数x,则y =550-x,第y组就是轻的那组。
11.8 在24小时里面时针分针秒针可以重合几次
24小时中时针走2圈,而分针走24圈,时针和分针重合24-2=22次,而只要时针和分针重合,秒针一定有机会重合,所以总共重合22次。(追击问题,环形同向追及,din次相遇,路程差=nS)
11.9 赛马
有25匹马,每场比赛只能赛5匹,至少要赛多少场才能找到最快的3匹马?。第一次,分成5个赛道ABCDE,每个赛道5匹马,每个赛道比赛一场,每个赛道的第12345名记为A1,A2,A3,A4,A5 B1,B2,B3,B4,B5等等,这一步要赛5场。
。第二次,我们将每个赛道的前三名,共15匹。分成三组,然后每组进行比赛。这一步要赛3场。。第三次,我们取每组的前三名。共9匹,第一名赛道的马编号为1a,1b,1c,第二名赛道的马编号为2a,2b,2c,第三名赛道的马编号为3a,3b,3c。这时进行分析,1a表示第一名里面的第一名,绝对是所有马中的第一,所以不用再比了。2c表示第二名的三匹里头的最后一匹,3b和3c表示第三名里面的倒数两匹,不可能是所有马里面的前三名,所以也直接排除,剩下1b,1c,2a,2b,3a,共5匹,再赛跑一次取第一第二名,加上刚筛选出来的1a就是所有马里面的最快3匹了。这一步要赛1场。·所以一共是5+3+1=9场。
11.10 烧 香/绳子/其他
确定时间问题:有两根不均匀的香,燃烧完都需要一个小时,问
怎么确定15分钟的时长?
(说了求15分钟,没说开始的15分钟还是结束的15分钟,这里是可以求最后的15分钟)点燃一根A,同
时点燃另一根B的两端,当另一根B烧完的时候就是半小时,这是再将A的另一端也点燃,从这时到A燃
烧完就正好15分钟。
11.11 掰巧克力问题NM块巧克力
每次掰一块的一行或一列,掰成1*1的巧克力需要多少次?(1000个人参加辩论赛,1V1,输了就退出,需要安排多少场比赛)
每次拿起一块巧克力,掰一下(无论横着还是竖着)都会变成两块,因为所有的巧克力共有NM块,所以要掰NM-1次,-1是因为最开始的一块是不用算进去的。
每一场辩论赛参加两个人,消失一个人,所以可以看作是每一场辩论赛减少一个人,直到最后剩下1个人,所以是1000-1=999场。
11.12 生成随机数问题
给定生成1到5的随机数Rand5(),如何得到生成1到7的随机数函数Rand7()?
思路:由大的生成小的容易,比如由Rand7()生成Rand5(),所以我们先构造一个大于7的随机数生成函数。
记住下面这个式子:
RandNN= N( RandN()-1 ) + RandN() ;// 生成1到N^2之间的随机数
可以看作是在数轴上撒豆子。N是跨度/步长,是RandN()生成的数的范围长度,RandN()-1的目的是生成0到N-1的数,是跳数。
比如 Rand25= 5( Rand5()-1 ) + Rand5()可以生成1到25之间的随机数。我们可以只要1到21(3*7)之间的数字,所以可以这么写
int rand7( ){
int x=INT_MAX;
while(x>21){
x=5*(rand5()-1)+rand5();
}
return x%7+1;
}
12. HR面
- 自我介绍
HR面试的自我介绍可以侧重软实力部分,项目技术方面介绍可以适当少一些 - 项目中遇到的最大难点
- 在项目中曾经遇到了新的框架不知道该如何上手的问题,以及面对新的概念,新的技术不知道从何学起。解决的办法是在官网寻找说明文档和demo,按照说明文档上的内容一步步了解,以及咨询身边有用过这个框架的同学,或者在CSDN上寻找相关博客。
- 项目的时间比较紧迫,没有那么多的时间可以用。解决方法是把还没有完成的项目分一个轻重缓急,在有限的时间里,先做重要而且紧急的,然后完成紧急的,再做重要的。利用轻重缓急做一个取舍。
- 项目中的收获
- 一个是了解了相关框架的使用方法(比如Dataframe的使用,xgboost的使用等等),这些框架或者技术可以在以后的开发中使用到。和对自己开发能力的锻炼。
- 一个是锻炼了与他人的交流能力,因为在团队项目里经常会跟别人汇报自己的想法和进度,同时也会跟其他成员沟通模块之间的交互,所以在这个过程中对自己的表达能力和理解能力都是一个很大的提升。
- 你的优缺点是什么
- 我的缺点是容易在一些细节的地方花费太多的时间,有时候过分追求细节。并且我的实习经验比较缺乏,对于实际项目的业务流程和工作流程不是很了解。(所以我打算通过实习来熟悉实际的软件开发的流程和技术。)
- 我的优点是责任心比较强,做事比较负责,在校期间我负责的大创项目进展很顺利,我经常组织组员们进行讨论和推进项目的开发,最后这个项目得到了92的评分,在同级别里面是比较高的。
-
看过最好的一本书是什么
技术类:编程之美 机器学习西瓜书 STL源码剖析 剑指offer
非技术类:明朝那些事儿香水(聚斯金德)解忧杂货店人类简史沉默的大多数与时间做朋友(李笑来)千年历史千年诗 -
怎么看待加班
我觉得任何一家单位都有可能要加班。如果自己的工作没有按时完成,那自觉加班是理所当然的,当然,自己要不断提高工作效率,避免这种原因导致的加班。如果遇到紧急任务或者突发状况时,为了顺利配合团队完成任务,我会尽自己所能加班共同完成。 -
职业规划
- 在工作的第一个阶段,先尽快适应工作的环境,包括开发环境开发工具和工作流程等,把自己负责的部分快速的完成,不能出差错。
- 第二个阶段要熟悉整个项目的业务流程,所有模块的结构和依赖关系,知道每个模块为什么要这么设计,以及它们的实现细节。培养从业务到技术的分解拆分及整体思想
- 第三个阶段要培养独立设计一个项目的能力,可以独立或者在别人的协作下设计项目的模块分工和架构。
在工作和项目中多写博客或者笔记,积累技术影响力,将经验总结成文档。同时与同事搞好关系,尝试培养领导能力和组织能力。
-
你最大的优势和劣势是什么
优势:做事情有主动性,不拖沓,有责任心。举个例子:在做论文课题的时候,几乎都是我自己找老师汇报进度和找老师讨论问题,很少有被老师催的时候。每一次跟老师讨论之后都会将讨论的内容和老师提出的意见进行详细记录。在项目汇报中,主动承担答辩ppt的制作,并且每次排练之后都迅速对ppt的修改意见进行落实修改,前前后后改了十几版。
劣势:有时候做事情比较急躁,容易导致粗心。 -
用两个词形容自己
踏实 认真 -
当你在工作中和同事意见不同,你会如何处理?
-
如果你是面试官,你会雇佣一个严格遵守规则但表现平平的人吗?
-
请分享一段你成功说服别人的经历?你用了什么方法?
-
谈谈你做过的最有挑战的项目和工作,你是如何克服各种挫折或者失败达成目标的?请分享一个具体的案例。
-
请分享一个你与他人发生较大意见分歧的真实案例,你是如何与对方沟通最终达成多赢局面的。
参考链接:一文看懂AB测试
机器学习的常见算法有哪些
一文教你如何处理不平衡数据集
机器学习-不平衡数据集
为什么要使用数据库连接池 、好处是什么
教你一秒钟得出 N个节点的完全二叉树有多少个叶子节点 / 度为1或2的节点个数
Linux下查看文件内容的命令
Linux常用命令
python中any()和all()如何使用
Python numpy库中dot()、matmul()、multiply、*、@的异同
Python 实例方法、类方法、静态方法的区别与作用
案例:通过空气质量指数AQI学习统计分析并进行预测(上)
RF、GBDT、XGBoost、lightGBM原理与区别
app三个最重要的指标
活动策划前期需要做哪些准备工作
https://www.zhihu.com/question/422205636/answer/2009767834