Ubuntu18 Win10搭建Caffe训练识别mnist手写数字demo
ubuntu 系统下的Caffe环境搭建
对于caffe的系统一般使用linux系统,当然也有windows版本的caffe,不过如果你一开始使用了windows下面的caffe,后面学习的过程中,会经常遇到各种错误,网上下载的一些源码、模型也往往不能快速的跑起来,因为貌似caffe的官方只提供了linux版本,而且caffe在不断的快速迭代更新中,如果不使用原版的话,后面编译出现什么问题,自己怎么错的,自己都不知道。本篇博文主要讲解快速搭建caffe环境:
电脑系统:ubuntu 14.04
显卡:GTX 850
在ubuntu下要完整的搭建caffe,个人感觉最难的一步就是cuda的安装了,特别是对于双显卡的电脑来说,很容易黑屏、无法登陆图形界面,这个我安装了n久,都没装成功,因为我的电脑笔记本双显卡,每次装完cuda就黑屏,网上的教程一大堆,但都中看不中用,导致我重装了二三十次的系统,最后才成功。这里为了讲caffe的安装,我们先不使用GPU,进行安装测试,因为没有GPU我们依旧可以跑caffe,只是速度比较慢而已。
1、安装caffe所需要的依赖库
命令:
sudo apt-get install libatlas-base-dev
sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libboost-all-dev libhdf5-serial-dev
sudo apt-get install libgflags-dev libgoogle-glog-dev liblmdb-dev protobuf-compiler这些库要安装挺久的,请耐心等待。
2、下载caffe。
到github上下载caffe:https://github.com/BVLC/caffe。下载完成后,解压caffe源码包。解压后,我们打开文件,可以看到caffe的源码包如下:
3、配置Make.config 文件。caffe文件解压后,文件夹下面有一个Makefile.config.example文件,我们需要对这个文件进行重命名为:Make.config 。也就是去掉后缀example。然后我们打开这个文件,可以看到如下内容:
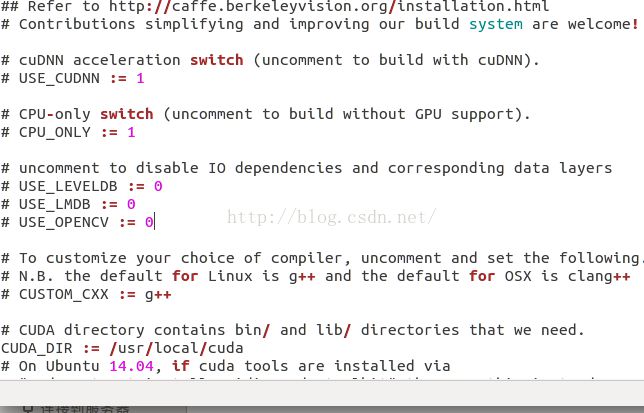
然后我们把:#CPU_ONLY:=1,那一行的注释符号去掉:CPU_ONLY:=1。这是因为我们没有安装CUDA,还不能使用gpu,所以我们把配置改为只使用cpu。
4、编译caffe。
方案一:
(1)在完成Make.config配置后,我们输入命令:
make all进行caffe源码编译.这一步有可能遇到如下错误:
caffe/proto/caffe.pb.h: No such file or directory如果出现这个错误,那么输入命令:
protoc src/caffe/proto/caffe.proto --cpp_out=.
mkdir include/caffe/proto
mv src/caffe/proto/caffe.pb.h include/caffe/proto然后在进行make all 就可以了
(2)编译完成后,在安装python接口,输入命令:
make pycaffe这个如果不使用python接口,调用caffe模型的话也可以不用安装,不过建议还是搞一下,就一句话的事。完事后,我们会发现caffe源码目录下,多了一个build文件,这个文件下面有个tools,打开这个文件夹:

这个文件夹下面的工具可是个好东西啊,以后我们会经常用到这些可执行文件,最常用的就是可执行文件:caffe,我们只要调用这个工具,就可以进行训练。
(3)接着编译test文件夹下面的源码。命令如下:
make test
make runtest采用这种方案一般没问题,不过我在使用c++调用的时候,会使用到链接库:libcaffe.so.1.0.0-rc3,这种方法编译后没有生成这个文件;经过google查找,发现采用cmake编译,才会生成libcaffe.so文件
方案二:直接采用cmake:
mkdir build
cd build
cmake ..
make all -j85、测试阶段
安装完了,自然要测试一下能不能用咯。首先cd到caffe目录,然后输入命令:
sh data/mnist/get_mnist.sh
sh examples/mnist/create_mnist.sh
vim examples/mnist/lenet_solver.prototxt把lenet_solver.prototxt里面的solver_mode 改为 CPU。因为我们还没装GPU,暂时只使用CPU就好了。
然后我们运行脚本:
./examples/mnist/train_lenet.sh这个时候,如果成功的话,就会开始跑起来:
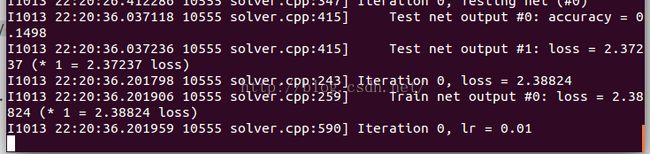
说明:如果在使用caffe、或者编译安装caffe过程中,出现如下错误:
CXX/LD -o .build_release/tools/convert_imageset.bin
.build_release/lib/libcaffe.so: undefined reference tocv::imread(cv::String const&, int)'.build_release/lib/libcaffe.so: undefined reference tocv::imencode(cv::String const&, cv::_InputArray const&, std::vector >&, std::vector > const&)'
那么请修改上面的Makefile文件(不是Makefile.config):
LIBRARIES += glog gflags protobuf leveldb snappy \
lmdb boost_system hdf5_hl hdf5 m \
opencv_core opencv_highgui opencv_imgproc opencv_imgcodecs也就是在libraries后面,加上opencv的相关库文件。
接着就开始caffe搞起吧,推荐个caffe模型网站:https://github.com/BVLC/caffe/wiki/Model-Zoo。本来个人不是很喜欢caffe的,就是因为这个网站吸引了我,这个网站可以搞到好多caffe模型、源码,非常适合于我们学习。
二、在Eclipse中使用编译调试caffe
1、首先就是安装Eclipse,然后安装c++开发插件,这个可以百度搜一下,eclipse下面怎么进行c++开发。
2.导入caffe makefile工程到eclipse (由于是英文版,下面描述也用英文,省的翻译,方便大家调试)
(1)File→New→Project→C/C++ →Makefile Project with Existing Code.
(2)Create a new Makefile Project from existing code
Projectname: caffe-master
Existing code location:/home/user/caffe-workspace/caffe-master
Language: choose C and C++
Toolchain:choose Linux GCC
(3)Then click on caffe-master in Project Explorer (set Window→Open Perspective → C/C++).
(4)Now go File → Properties → Run/Debug settings.Click New.., and choose C/C++ application
(5)Fill launch configurationproperties
· Arguments:
fill train –solver=examples/mnist/lenet_solver.prototxt
and change working directory from default to /home/user/caffe-workspace/caffe-master(change to your own directory)
(6)Now you can use debug caffe code: Run-> Debug
三、C++函数调用相关路径,makefile
CC=g++
CXXFLAGS = -O2 -Wall -D__STDC_CONSTANT_MACROS
INCLUDE = -I/usr/local/cuda/include -I. -I/usr/local/cuda/include -I/home/hjimce/caffe/include/ -I/home/hjimce/caffe/src/
LIBRARY = -L/usr/local/x86_64-linux-gnu/ -lprotobuf \
-L/usr/lib/x86_64-linux-gnu/ -lglog \
-L/usr/local/cuda/lib64/ -lcudart -lcublas -lcurand \
-L/usr/local/lib/ -lm -lpthread -lavutil -lavformat -lavcodec -lswscale -lopencv_core -lopencv_imgproc -lopencv_highgui \
-L/usr/lib/python2.7/config-x86_64-linux-gnu/ -lpython2.7 \
-L/sur/lib32/ -lrt \
-L../../caffe/build/lib/ -lcaffe
all:
$(CC) $(INCLUDE) $(OBJS) testcpp.cpp -o exercise $(LIBRARY)windows下的caffe环境搭建
最近在ubuntu搞了一个月的caffe,总感觉很不爽,因为ubuntn下面的c++集成开发工具,eclipse用起来没有vs爽,因为对caffe的函数名不是很熟悉,所以需要借助vs的c++助手。然后前一个月大部分也是调用pycaffe,但是最近感觉需要对caffe的c++函数比较熟悉,才能把自己的能力进一步提高,于是就开始搞起了windows 下的caffe,借助vs的强大功能,快速学习caffe。一开始采用vs2012,最后各种错误,最后改成vs2013很容易就编译成功了。
一、安装编译环境
1、 Visual studio2013
这个比较简单,不写步骤了。
2、python 2.7.6
为了能使用python调用Caffe,首先需要安装python,这个也简单,问度娘很多。注意两点:
①安装的时候记得勾选pip,这个工具很nice,可以为你省很多不必要的麻烦;
②安装完后设置好环境变量。可以再cmd命令中输入python检查,如果不报错,则恭喜。
接下来利用pip工具安装这几个包:numpy、scipy、matplotlib、scikit-image、protobuf
在cmd命令行内输入:pip install numpy即可,其他几个类似。
3、matalb
这个安装过程比较慢,也没什么需要注意的,这里直接略去。
二、安装caffe
1、caffe源码包
下载地址:https://github.com/Microsoft/caffe
2、编译配置
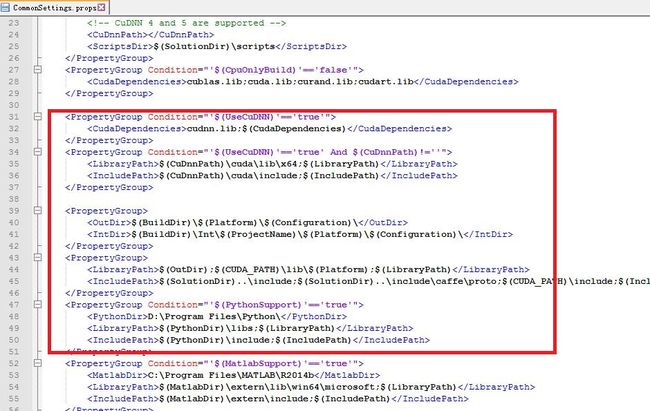
将下载的caffe-windows.zip进行解压,并进入其根目录下的windows目录,把这个CommonSettings.props.example文件复制到源目录一份,然后重命名为CommonSettings.props。打开并修改其中的配置项。有几个需要注意的地方:
①是否只是用cpu。如果你的电脑显卡支持GPU编程(是否支持可以去英伟达官网查询),那么可以配置为false。否则CpuOnlyBuild = true
②是否使用cudnn加速
③是否使用python和matalb,根据需要配置
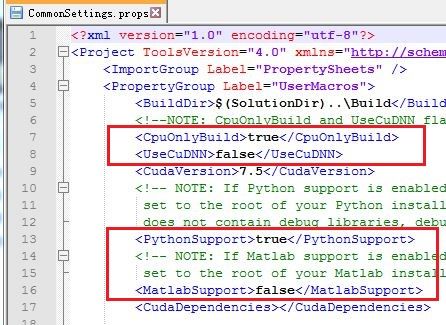
④如果配置了python和matlab,这里需要把修改软件目录为自己电脑上的实际安装目录
⑤如果有cuda,则把CudaVersion修改为自己电脑的cuda版本
3、项目编译
用Visual studio2013打开caffe-master\windows下的Caffe.sln文件,进去后如下图(共16个项目):
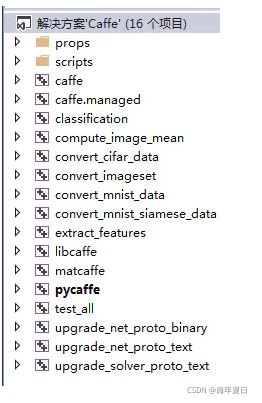
(1)先生成【libcaffe】,右键生成;这里由于别的模块用到了libcaffe,所以,首先生成libcaffe
(2)再选择【解决方案Caffe】进行生成,这里时间比较久,因为Nuget会提示下载一些东西,包括boost,opencv2.4.10,gflags,glog,hdf5,lmdb,LevelDB,OpenBLAS,protobuf等预编译的依赖包。过程有点慢,多等会就ok。下载完成后会在caffe 的同级目录生成NugetPackages的文件。
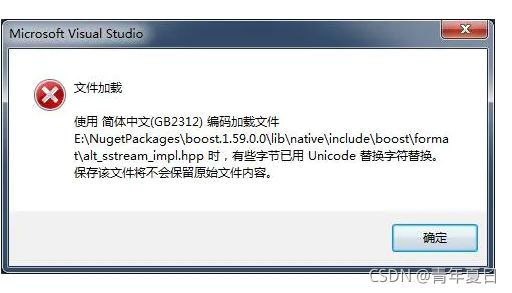
如果中途编译失败,出现错误,不用紧张,双击出现如下对话框,确定然后保存,重新编译即可。
4、运行
右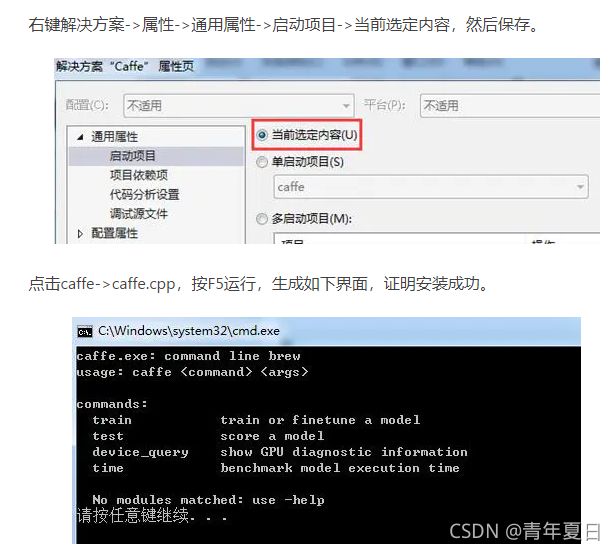
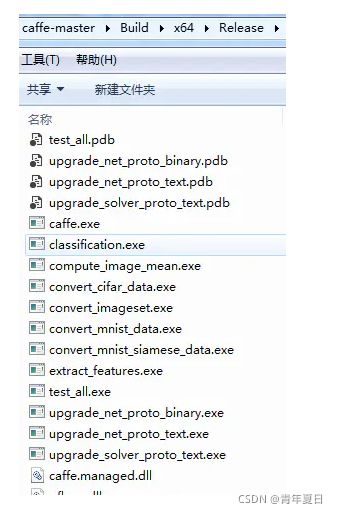
同时在Build\x64\下生成了很多exe和dll文件。这些工具在后面训练网络、测试时候很有用。
三、体验深度学习
终于到这了,我们通过一个caffe自带的简单例子来体验一下caffe的网络训练和预测。
deep-learning属于有监督学习的一种,一般步骤分为:准备数据、训练模型和测试模型。我们下边也通过这三步来测试一个基于LeNet网络的学习模型。
1、准备训练数据
mnist数据集下载地址:http://yann.lecun.com/exdb/mnist/
下载后解压到caffe-master目录中的\data\mnist内。分别在cmd下输入以下命令
.\Build\x64\Release\convert_mnist_data.exe .\data\mnist\mnist_train_lmdb\train-images.idx3-ubyte .\data\mnist\mnist_train_lmdb\train-labels.idx1-ubyte .\examples\mnist\mnist_train_lmdb
.\Build\x64\Release\convert_mnist_data.exe .\data\mnist\mnist_test_lmdb\t10k-images.idx3-ubyte .\data\mnist\mnist_test_lmdb\t10k-labels.idx1-ubyte .\examples\mnist\mnist_test_lmdb
将数据转化为caffe需要的输入格式。
2、训练模型
①修改模型参数
修改examples\mnist\lenet_solver.prototxt,将最后一行改为solver_mode:CPU,
修改examples\mnist\lenet_train_test.prototxt,如下所示,左面为原始的,右面为修改后的。
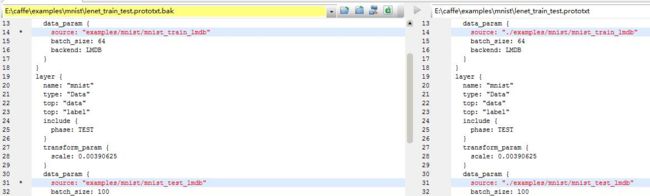
②训练模型,训练完毕后会得到相应的准确率和损失率。
.\Build\x64\Release\caffe.exe train --solver=.\examples\mnist\lenet_solver.prototxt
3、测试模型
最终训练的模型全职文件保存在example\minst\lenet_iter_10000.caffemodel文件中,训练状态保存在example\minst\lenet_iter_10000.solverstate中。这两个文件都是PrototxtBuffer二进制格式。
利用训练好的模型权值文件可以测试数据集。运行如下命令:
.\Build\x64\Release\caffe.exe test -model examples\mnist\lenet_train_test.prototxt -weights examples\mnist\lenet_iter_10000.caffemodel -iterations 100
到这,整个caffe在windows上就安装完成了。下一节写Ubuntu下caffe的配置。
谢谢!
博客有任何错误或者疑问,请加VX:1755337994,及时告知!万分感激!