看完肯定会系列之——CentOS7下安装和配置Hadoop以及Hadoop集群
文章目录
-
- 一、事前准备
-
-
- 1、CentOS虚拟机
- 2、虚拟机安装好JDK
- 3、Hadoop相关压缩包(包含Zookeeper、HBase、Hive,本篇文章只下载Hadoop即可)
-
- 二、一些事前配置
-
-
- 1、关闭防火墙
- 2、修改主机名和主机列表
- 3、配置免密登录
-
- 三、解压安装Hadoop
- 四、修改配置文件
- 五、修改环境变量
- 六、格式化HDFS
- 六、Hadoop的启动与关闭
- 七、Hadoop集群的搭建
-
-
- 1、关闭虚拟机
- 2、复制虚拟机
- 3、修改虚拟机配置
-
- 1、修改ip地址
- 2、修改主机名
- 3、修改主机列表
- 4、配置所有机器之间的免密登录
- 5、修改Hadoop配置文件
- 6、启动集群
-
一、事前准备
1、CentOS虚拟机
可以参考:VMware创建CentOS7虚拟机并使用MobaXterm连接
2、虚拟机安装好JDK
可以参考:CentOS7下安装JDK
3、Hadoop相关压缩包(包含Zookeeper、HBase、Hive,本篇文章只下载Hadoop即可)
提取码fg2h
二、一些事前配置
1、关闭防火墙
1、看防火墙状态
systemctl status firewalld
2、关闭防火墙
systemctl stop firewalld
3、禁用防火墙
systemctl disable firewalld
2、修改主机名和主机列表
1、改主机名为hadoop1
hostnamectl set-hostname hadoop1
2、查看是否成功(也可以直接用这个命令修改)
vi /etc/hostname
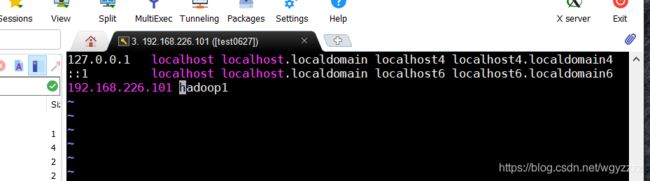
3、修改主机列表
vi /etc/hosts
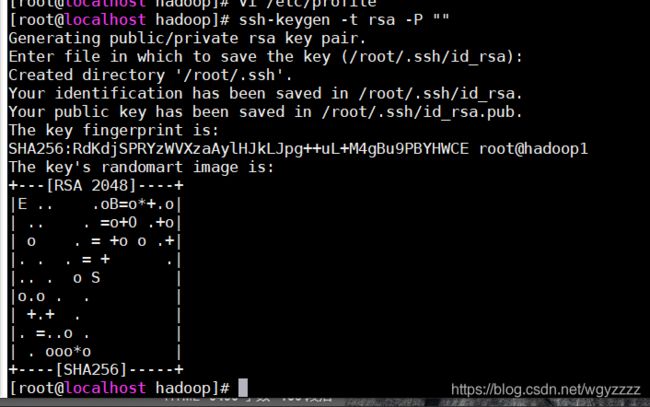
3、配置免密登录
1、生成私钥
ssh-keygen -t rsa -P ""(注意这里是两个英文双引号)
回车后需要再按一次回车
2、复制到授权密钥
cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys
三、解压安装Hadoop
打开Moba连上虚拟机,进入software目录下(没有可以mkdir /software新建一个用来放安装包)
拖入hadoop相关安装包
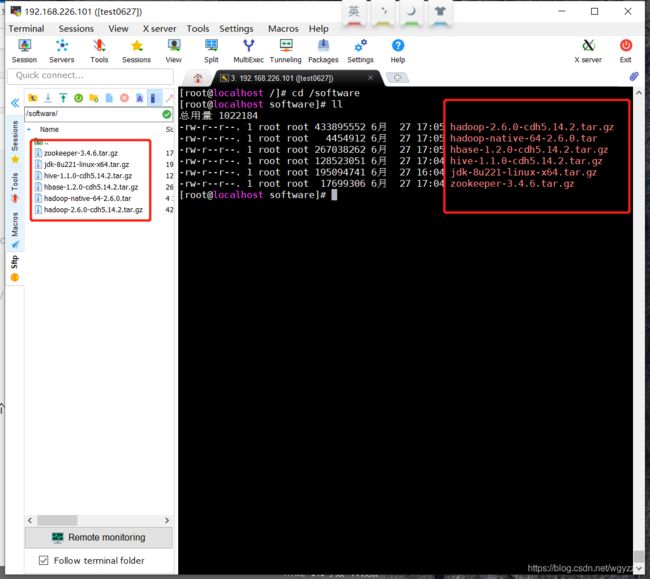 安装包不算JDK一共有5个,hadoop和hadoop集群的安装配置只需要用到hadoop-2.6.0-cdh5.14.2.tar.gz,不过其他四个后面还是要学习的,所以解压改名这块一起操作了
安装包不算JDK一共有5个,hadoop和hadoop集群的安装配置只需要用到hadoop-2.6.0-cdh5.14.2.tar.gz,不过其他四个后面还是要学习的,所以解压改名这块一起操作了
依次执行下面命令将文件解压至/opt目录下
tar -zxvf hadoop-2.6.0-cdh5.14.2.tar.gz -C /opt/
tar -zxvf hbase-1.2.0-cdh5.14.2.tar.gz -C /opt/
tar -zxvf hive-1.1.0-cdh5.14.2.tar.gz -C /opt/
tar -zxvf zookeeper-3.4.6.tar.gz -C /opt/
tar -xvf hadoop-native-64-2.6.0.tar -C /opt/hadoop-2.6.0-cdh5.14.2/lib/native/
cp /opt/hadoop-2.6.0-cdh5.14.2/lib/native/libh* /opt/hadoop-2.6.0-cdh5.14.2/lib/
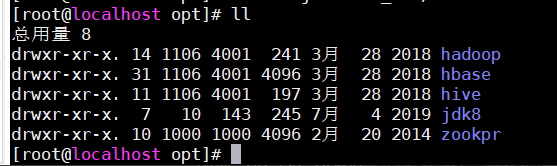
进入opt目录并给这些文件改名(JDK上一篇改过了)
cd /opt
mv hadoop-2.6.0-cdh5.14.2/ hadoop
mv hbase-1.2.0-cdh5.14.2/ hbase
mv hive-1.1.0-cdh5.14.2/ hive
mv zookeeper-3.4.6/ zookpr
四、修改配置文件
opt目录下
cd hadoop/etc/hadoop
vi hadoop-env.sh
export JAVA_HOME=/opt/jdk8
vi core-site.xml
fs.defaultFS
hdfs://192.168.226.101:9000
hadoop.tmp.dir
/opt/hadoop/tmp
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
vi hdfs-site.xml
dfs.replication
1
dfs.namenode.secondary.http-address
192.168.226.101:50090
将文件mapred-site.xml.template改名为mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
192.168.226.101:10020
mapreduce.jobhistory.webapp.address
192.168.226.101:19888
vi yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.hostname
hadoop1
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
vi slaves
将内容改为主机名hadoop1
配置文件修改完毕
五、修改环境变量
vi /etc/profile
修改为:
export JAVA_HOME=/opt/jdk8
export CLASSPATH=.:$JAVA_HOME/rt.jar:$JAVA_HOME/tools.jar:$JAVA_HOME/dt.jar
export JRE_HOME=$JAVA_HOME/jre
export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$HBASE_HOME/bin:$HIVE_HOME/bin
export HADOOP_HOME=/opt/hadoop
export HBASE_HOME=/opt/hbase
export HIVE_HOME=/opt/hive
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
其中hbase、hive等的环境变量暂时用不到,先配上方便以后使用
完成后
source /etc/profile
六、格式化HDFS
hadoop namenode -format

*注意,这里如果安装的时候多次初始化,会导致错误,解决方法是删除/opt/hadoop目录下的tmp文件(就是上面配置文件core-site.xml中需要注意的地方)
六、Hadoop的启动与关闭
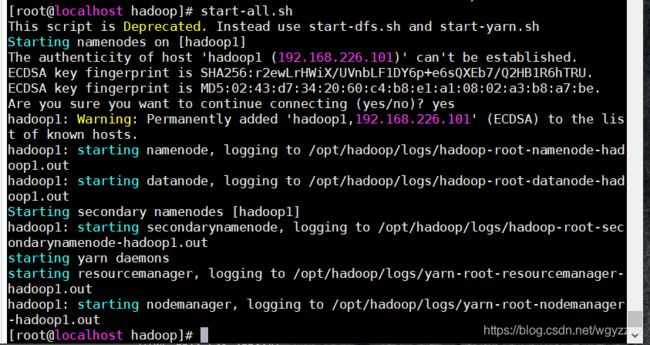
启动服务
start-all.sh
第一次启动需要输入yes确认密钥
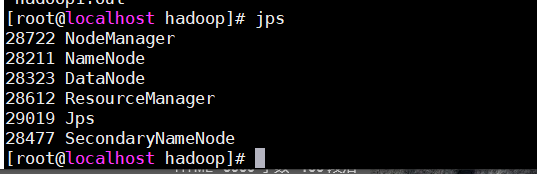
 输入命令jps查看进程是否为六个
输入命令jps查看进程是否为六个
启动历史服务(开不开没关系)
mr-jobhistory-daemon.sh start historyserver
再次输入jps

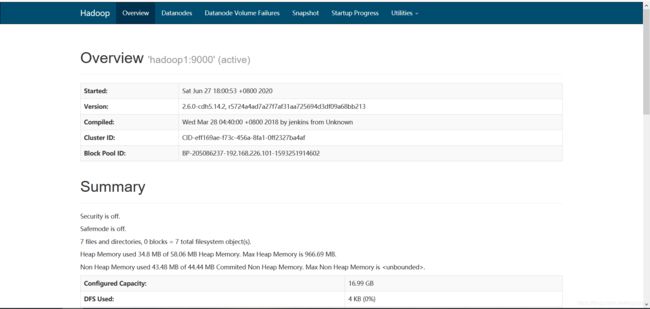
或者通过浏览器来判断服务是否开启成功
hdfs:
192.168.226.101:50070
 yarn:
yarn:
192.168.226.101:8088
 历史服务:
历史服务:
192.168.226.101:19888
 关闭服务
关闭服务
stop-all.sh
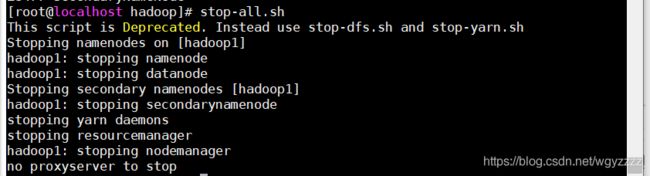
关闭历史服务
mr-jobhistory-daemon.sh stop historyserver

jps查看没有进程表示关闭完成

至此,单机hadoop安装配置完成
七、Hadoop集群的搭建
1、关闭虚拟机
配置集群之前
关闭虚拟机
Moba中输入poweroff或者直接VMware关机
2、复制虚拟机
这里重新创建虚拟机也可以,不过其中的操作大多是重复性操作,所以这里我们直接复制虚拟机,然后修改一些配置就可以了
在虚拟机关闭的情况下克隆

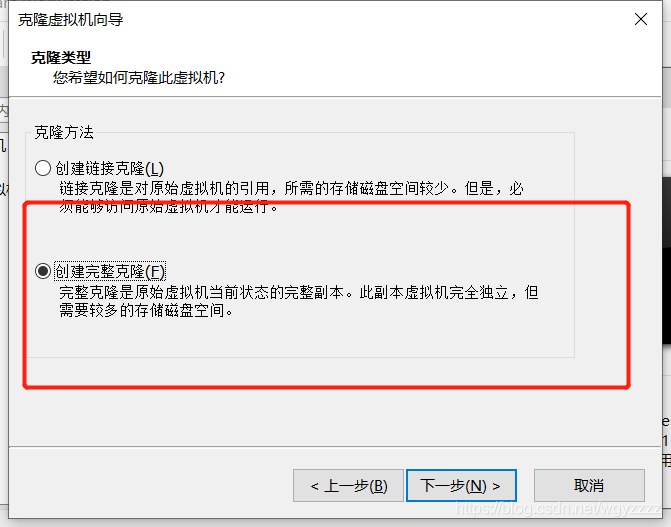
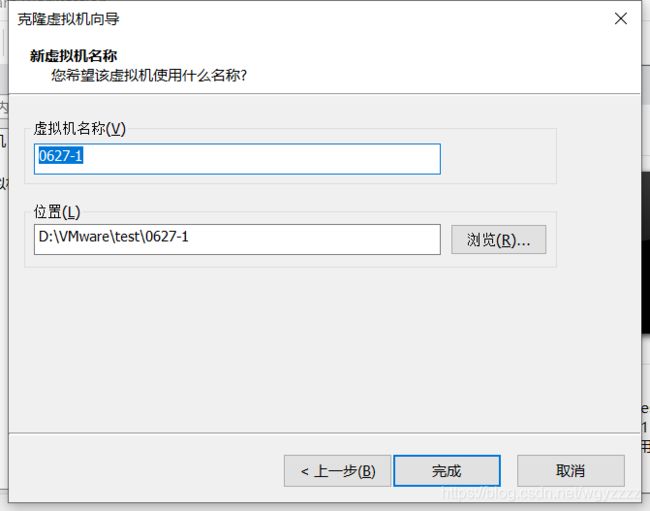
用同样的方法克隆两个
克隆完成之后的虚拟机要先将MAC地址重新生成一下,不然后面Moba连不上
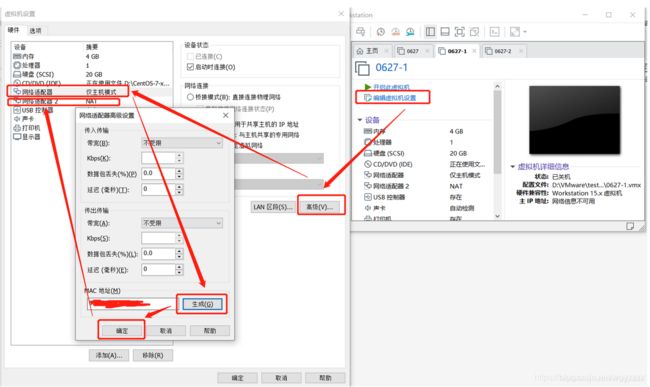
网络适配器2也进行同样操作
两个虚拟机都操作好之后可以运行虚拟机
三个虚拟机同时运行
3、修改虚拟机配置
1、修改ip地址
vi /etc/sysconfig/network-scripts/ifcfg-ens33
两台机器修改IPADDR为102和103

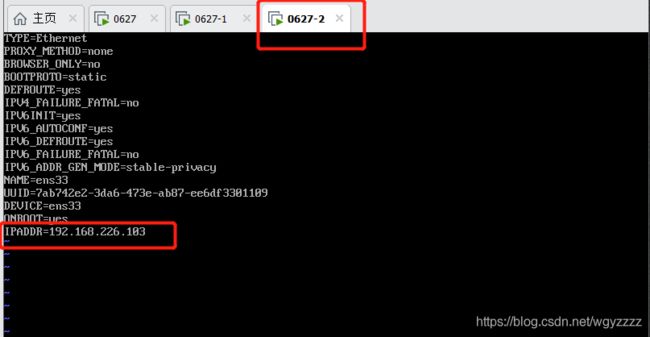 两台虚拟机重新激活配置
两台虚拟机重新激活配置
systemctl restart network
都完成后可以用Moba连接,参照之前的步骤再创建两个连接,因为是复制来的root用户和密码相同,就不用在Moba上新建用户了,用之前创建的那个就行

下面用101,102,103简称
2、修改主机名
102:hostnamectl set-hostname hadoop2
103:hostnamectl set-hostname hadoop3
修改完之后并不会立刻改变,可以输入命令exit先断开连接,在R重连就可以显示修改后的名字
3、修改主机列表
101/102/103:vi /etc/hosts
三个虚拟机同样操作

4、配置所有机器之间的免密登录
三台虚拟机上先执行之前同样的操作
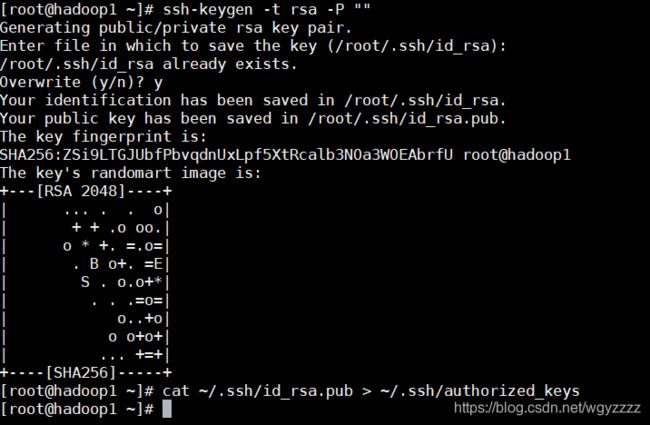
ssh-keygen -t rsa -P ""

提示是否Overwrite的时候输入y
cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys
*这里要使用一个“>”表示覆盖,重写,两个“>”表示追加
 接下来三天机器操作的命令有些差别,复制的时候小心使用
接下来三天机器操作的命令有些差别,复制的时候小心使用
101:将授权密钥发给102,103
ssh-copy-id -i /root/.ssh/id_rsa.pub -p22 [email protected]
ssh-copy-id -i /root/.ssh/id_rsa.pub -p22 [email protected]
102:将授权密钥发给101,103
ssh-copy-id -i /root/.ssh/id_rsa.pub -p22 [email protected]
ssh-copy-id -i /root/.ssh/id_rsa.pub -p22 [email protected]
103:将授权密钥发给101,102
ssh-copy-id -i /root/.ssh/id_rsa.pub -p22 [email protected]
ssh-copy-id -i /root/.ssh/id_rsa.pub -p22 [email protected]
操作的时候需要输入一次yes和一次密码
 配置好之后进行用户切换测试(@后面用ip和别名都可以)
配置好之后进行用户切换测试(@后面用ip和别名都可以)
101:
ssh -p 22 root@hadoop2
第一次连接却要输入yes确认,以后不用 切换用户之后可以使用命令exit登出
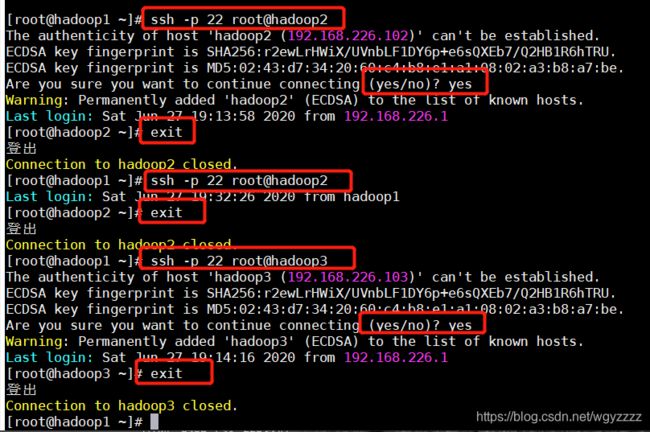 101验证登录102和103,同理102和103也要进行登录验证
101验证登录102和103,同理102和103也要进行登录验证
5、修改Hadoop配置文件
101/102/103三台虚拟机都要改:
cd /opt/hadoop/etc/hadoop
vi hdfs-site.xml
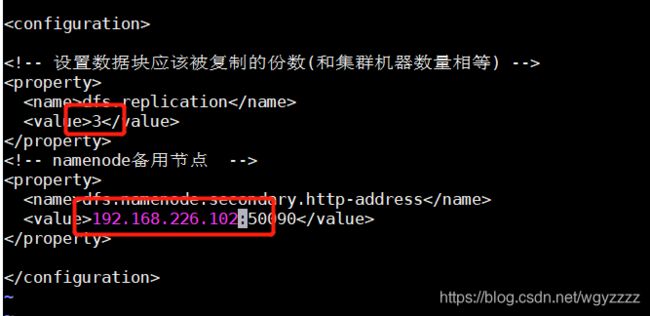
vi slaves
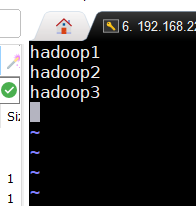
102/103两台虚拟机:
vi mapred-site.xml

6、启动集群
先将三台虚拟机下的tmp目录删除
cd /opt/hadoop/
rm -rf tmp/
101机器初始化hdfs
hadoop namenode -format
如果出现无法找到命令,就重新激活一下配置文件

在101机器下启动服务
start-all.sh
mr-jobhistory-daemon.sh start historyserver
启动后分别输入jps查看启动进程
101:

102:
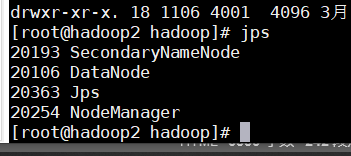
103:
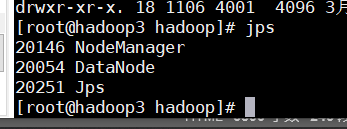
至此,Hadoop集群搭建完成