Yolov1训练笔记
24类心理卡牌检测
1、使用标注工具对图像(W,H)进行标注:标注的数据是目标的左上和右下角坐标(xmin,ymin,xmax,ymax)
2、对已标注的数据进行转换,转换为目标的中心坐标及宽高(x,y,w,h)并归一化
转化:x=(xmax+xmin)/2;y=(ymax+ymin)/2;w=xmax-xin;h=ymax-ymin
归一化:(x/W,y/H,w/W,h/H)
for file in train_file:
sp = file.split('/')[1]
sp = sp.split('.')[0]
out_file = open('./data/input/CardDetection/labels/%s.txt' % (sp), 'w')
img = cv2.imread(DATA_PATH + '/CardDetection/' + file)
h, w = img.shape[:2]
dw = 1.0 / w
dh = 1.0 / h
for i in range(len(data)):
if file==data.iloc[i,0]:
# img=cv2.imread(DATA_PATH+'/CardDetection/'+file)
# cv2.imshow('test',img)
# cv2.waitKey()
# print(data.iloc[i,0])
xc=(data.iloc[i,4]+data.iloc[i,2])/2.0
yc=(data.iloc[i,5]+data.iloc[i,3])/2.0
new_w=data.iloc[i,4]-data.iloc[i,2]
new_h=data.iloc[i,5]-data.iloc[i,3]
xc*=dw
yc*=dh
new_w*=dw
new_h*=dh
out_file.write(str(data.iloc[i,1])+" "+str(xc)+" "+str(yc)+" "+str(new_w)+" "+str(new_h)+'\n') 3、加载数据:图像-标签(一一对应)
训练之前将所有图像尺寸调整为(448*448)
首先图像的宽高需要进行增广,即选取max(W,H),沿着宽或高补0,将图像尺寸先调整为(max(W,H),max(W,H))以便进行缩放。
h,w=img.shape[:2]
input_size=448
#图像增广
padwh=(max(w,h)-min(w,h))//2
if h>w:
img=np.pad(img,((0,0),(padwh,padwh),(0,0)),'constant',constant_values=0)
elif h 微调pad后的图像的所有box信息。
#增广后(max(w,h),max(w,h))微调x,y,w,h
if h>w:
bbox[i * 5 + 1] = (bbox[i * 5 + 1] * w+ padwh) / h
bbox[i * 5 + 3] = (bbox[i * 5 + 3] * w) / h
elif w>h:
bbox[i * 5 + 2] = (bbox[i * 5 + 2] * h+ padwh) / w
bbox[i * 5 + 4] = (bbox[i * 5 + 4] * h) / w
将已增广的图像进行尺寸缩放为(448*448)
对比原始、pading及缩放后图像(截取)中目标的标注框:
原始图像W/H(1920*2560)标注(x,y,w,h) padding后图像max(W,H)(2560*2560)标注(x1,y1,w1,h1)

resize后图像NW*NW(448*448)标注(x2,y2,w2,h2)
框的相对坐标信息没有改变主要是中心点及宽高(归一化)相对整张图的未发生改变。
可以通过计算得出:x2=x1*max(W,H)*(NW/max(W,H))/NW=x1
构建标签:
labels转化为向量(fp,fp,bbox_con_cls)对应最终的fp形式
归一化的中心点*fpsize取整可以获得该中心点落在特征图fp上的哪行哪列负责当前ground truth的预测,置信度和对应类别概率均置为1
其中bbox[0]整数代表当前box所属类别
最终labels多维矩阵形式:[gridpx,gridpy,w,h,con,(p1,p2...pn)] 如:([2,1,2,3,1,(0,0,1,...)])
4、网络骨架

YOLOv1网络有24个卷积层,后面是2个全连接层,最后输出层用线性函数做激活函数,其它层激活函数都是Leaky ReLU。
pytorch的torchvision中提供了ResNet34的预训练模型,训练集也是ImageNet,节省特征提取部分的训练时间。然后,除去ResNet34的最后两层,再连接上2个卷积层和3个全连接层,作为训练的网络结构。
class Net(nn.Module):
def __init__(self):
super().__init__()
resnet=tvmodel.resnet34(pretrained=True)
resnet_out_channel=resnet.fc.in_features
self.resnet=nn.Sequential(*list(resnet.children()))[:-2]
self.convlayer=nn.Sequential(
nn.Conv2d(resnet_out_channel,1024,3,padding=1),
nn.BatchNorm2d(1024),
nn.LeakyReLU(),
nn.Conv2d(1024,1024,3,stride=2,padding=1),
nn.BatchNorm2d(1024),
nn.LeakyReLU()
)
self.fclayer=nn.Sequential(
nn.Linear(7*7*1024,4096),
nn.LeakyReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096,4096),
nn.LeakyReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 7 * 7 * 34),
nn.Sigmoid()
)
def forward(self,out):
out=self.resnet(out)
out=self.convlayer(out)
out=out.view(out.size()[0],-1)
out=self.fclayer(out)
return out.reshape(-1,(5*box_NUM+classNum),7,7)
5、损失函数
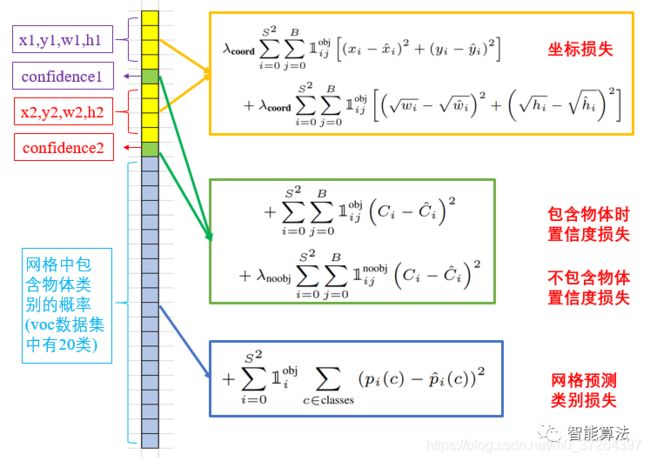
图片来源
通过将输入(img)送入CNN中训练,获得最终的fp形式预测数据ypred pred:batch,[x1,y1,w1,h1,conf1,x2,y2,w2,h2,conf2,cls1,cls2....cls24],m,n
该数据ypred与实际标签lables矩阵进行求解损失(其中输入的图像与ypred及labels是一一对应的)
从ypred中解析2个box的左上右下坐标,从labels中解析ground truth左上右下坐标
分别求解预测的box与GTbox的iou,选择预测box中iou大的那个作为预测框:重叠面积占比
计算预测框的坐标损失(中心点及宽高)采用差的平方和 lxywh=sum(ypred-label)^2
计算置信度损失:有目标lc=(置信度-iou1)^2 无目标loc=(置信度-iou2)^2
计算类别损失:lp(预测类-label中的类)^2
整体损失:loss=lxywh+lc+loc+lp
因为按批次处理图像:平均损失loss/batch
6、模型的保存与评估
save,map(后补)
7、测试模型
将预测的ypred进行变形提取当中的每个box 一个ypred是7*7*34 有98个box
变形:98*29(xc,yc,w,h,cls1,...cls24)
由于预测一张图片可能出现许多框,这些box情况有:
同一类同一位置目标有多个box;同一类有多个不同位置目标与其对应的box,多个类有多个不同位置目标对应的box。。。
但是我只要其中的一个作为最终的检测结果,那么就会选择一个算法剔除多余的框而选择最优的框
非极大值抑制:非局部最大值被抑制,换句话说就是取局部最大值,所以nms的意义主要在于把一个区域里交叠的很多框选一个最优
采用非极大值抑制(NMS)进行筛选框:因为pred会得到98个bbox信息,而其中大部分是没用的,由于没标签可供参照,只能用别的算法来去除无效的bbox。
设置两个阈值:置信度与iou阈值
将低于置信度阈值的bbox忽略,根据iou进行非极大值抑制
计算:将同一类别下的所有box两两进行iou计算,保留超过阈值的iou
使用24类心理卡牌检测代码:https://github.com/Silenceing/CardDetection_yolov1
未完待续。。。。。。
参考:
YOLO v1深入理解:https://www.jianshu.com/p/cad68ca85e27
一文看懂YOLO v1:https://zhuanlan.zhihu.com/p/60413634
动手学习深度学习pytorch版——从零开始实现YOLOv1:https://blog.csdn.net/weixin_41424926/article/details/105383064
pytorch简单实现yolo v1:https://zhuanlan.zhihu.com/p/139713442
非极大值抑制:https://www.cnblogs.com/makefile/p/nms.html
YOLO v1的详解与复现
https://www.cnblogs.com/xiongzihua/p/9315183.html
https://github.com/abeardear/pytorch-YOLO-v1