yolov5笔记(2)——训练自己的数据模型(随5.0更新)
个人体验yolov5最大的感觉就是惬意舒适。
比起object_detection
一个训练花费我10小时,一个只有1.1个小时(都是迁移训练)
一个检测速度等待了十几秒,一个只需0.01秒(一张图)
一个使用找资料教程忙活了一个月把,一个只有GitHub的官方教程(tf1与tf2无法通用搞得人头大)
1. 安装yolov5
首先来到github下载代码库https://github.com/ultralytics/yolov5
安装过git的可以直接输下面的代码
最新适配pytorch1.7版本的yolov5 4.0版本官方在2021.1.5更行了,所以你如果是在这之后下载的yolov5和下一个笔记中的tensorrtx,请仔细检查所有相关程序与模型是否支持4.0版本的yolov5
git clone https://github.com/ultralytics/yolov5
安装所需的库
来到yolov5文件夹下输入下面代码就能把下面的库都安装好。
pip install -r requirements.txt # install dependencies
在win10下安装pycocotools库会报错,所以如果你出现了这个库的报错信息请不用紧张这是正常情况,后面的内容我有写如何忽略整个报错。
3. 运行yolov5
运行命令
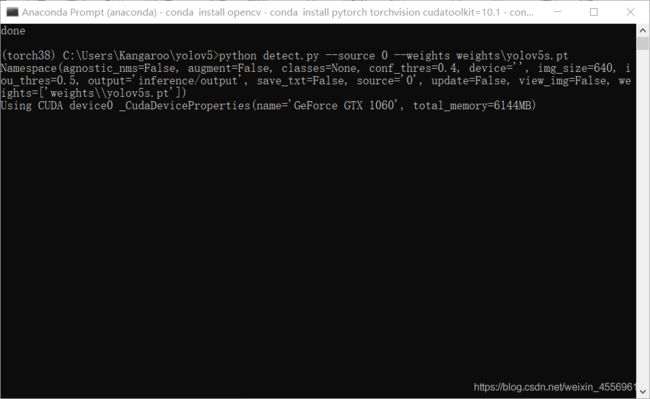
安装好后,来到yolov5/ 文件夹下运行
python detect.py
运行此命令它会自动帮你下载yolov5s.pt文件并运行检测inference/images下地图片。
不过我们还可以通过别的途径
python detect.py --source 0 --weights yolov5l.pt
如果没有yolov5l.pt文件,程序会帮你下载。(会下载最新的文件)
x和m文件依此类推。
但问题就在于国内下载太慢了
下载权重文件
这里说一下,如果你是现在从官网下载的yolov5,那应该会是3.0版本的yolov5。
对于3.0版本的yolov5,最好是使用3.0的权重数据。否则会有意想不到的报错:
torch.nn.modules.module.ModuleAttributeError: 'Detect' object has no attribute 'm'
torch.nn.modules.module.ModuleAttributeError: ‘BatchNorm2d‘ object has no attribute
其实github上官方有给,但是要还是百度云好了。
2021.1.5日官方更新了4.0版本的yolov5和附带的模型,新的模型使用了nn.SiLU()激活取代了整个模型中的nn.LeakyReLU(0.1)和nn.Hardswish()激活,简化了体系结构。实测使用4.0版本的yolov5必须使用1.7版本的pytorch。
下面是4.0版本的yolov5(内包含常用模型在weights文件夹里)
链接:https://pan.baidu.com/s/1ip3Peg6U659MiwZkkIvNzw
提取码:7hsl
命令
安装好后,来到yolov5/ 文件夹下运行
python detect.py --source 0 --weights weights/yolov5s.pt
# --weights 调用权重文件,默认yolov5s.pt
# --source 输入来源,默认inference/images,0为指定摄像头0号,也可是网址,具体可看GitHub上的介绍
# --output 输出位置,默认inference/output,也可不输出保存
# --img 统一输入图像规模,默认640
# --device 训练的设备(CPU or GPU),默认无
这样就是通过调用自己电脑的摄像头,用yolov5s.pt的模型来进行对象检测
我自己的实测是0.012s左右一张图,帧率能达到80左右,amazing了。
国内摄像头一般是25帧,我目前的水平跑这个是绰绰有余的。
而x的模型,精度能高s模型0.3左右的置信度,同样是摄像头检测,0.060s左右一张图,也是十分地强大。
4.0版本detect.py也会检查pycocotools的版本,同样的也是把检查版本的代码注释掉就好了。详细情况也跳到下面有一块专门讲4.0版本的不同之处。

官方教程:https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
2. 标注数据
标注文件参考我之前的文章2020年tensorflow定制训练模型笔记(2)——制作标签中的第二步“2.labelimg”
注意
有一点不一样!
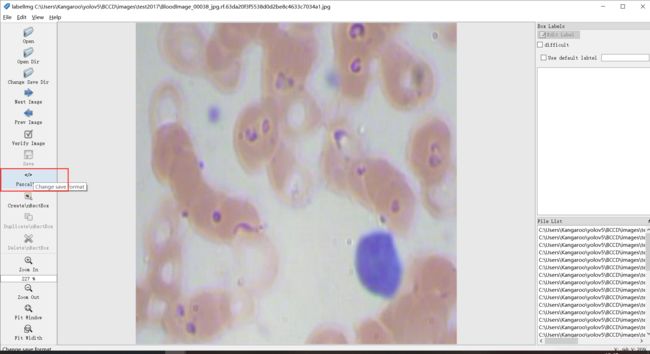
之前我们的数据保存的是xml格式,而yolo支持的是txt格式。
所以我们在保存的时候要点击下图红色选框,这样就能保存为txt格式。
还有要注意的是,图片和标注的命名不要出现中文!!!
图片的格式并无太大的要求,实测jpg、jpeg、png混标没有问题。
还有一个很关键的点,许多人训练出来的识别对象会出现固定的标签不符合的现象。这是因为在训练过程中,yolo网络是不认识你的标签名的,网络只按照特定的标签名顺序将他们理解为0、1、2、3······(通过下面会提到一份yaml文件)
在标注的文件夹里有个data文件夹

我之前搞了垃圾识别的项目,按图所示,从上往下分别会被理解为0~4
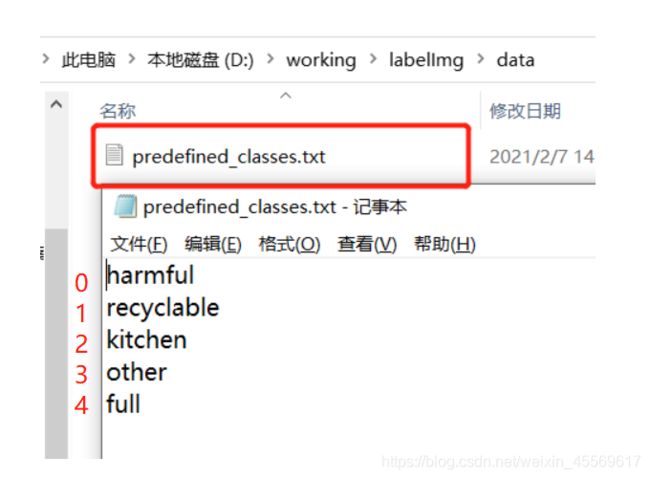
这要和下面要输入网络的data.yaml文件相对应。这样就可以确保识别出的标签会被对应上。

数据格式
基本上所有的yolov5教程都会讲这个txt格式那我也就讲一讲

我用一个表格去列一下上面的数据
| 标签名 | 中心点x的相对坐标 | 中心点y的相对坐标 | 宽度的相对坐标 | 高度的相对坐标 |
|---|---|---|---|---|
| 2 | 0.7406 | 0.7614 | 0.1843 | 0.2562 |
| 1 | 0.3203 | 0.8791 | 0.1562 | 0.1375 |
| ``` |
相对坐标就是x值相对于整张照片的大小,官方有张图能很好的解释这个

3. 配置文件
配置文件路径
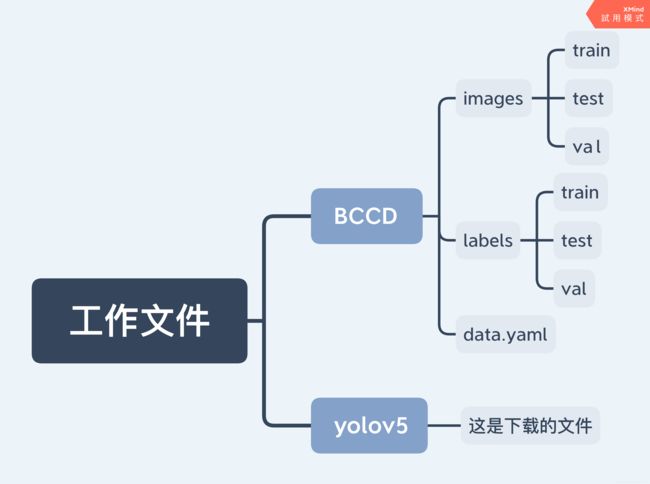
假设我现在要识别的是血红细胞,文件夹取名为“BCCD”,按图片方式放置好文件。
照片放在images对应的文件夹下,标签放在labels对应的文件夹下。
BCCD文件夹需与下载的yolov5文件夹同级。
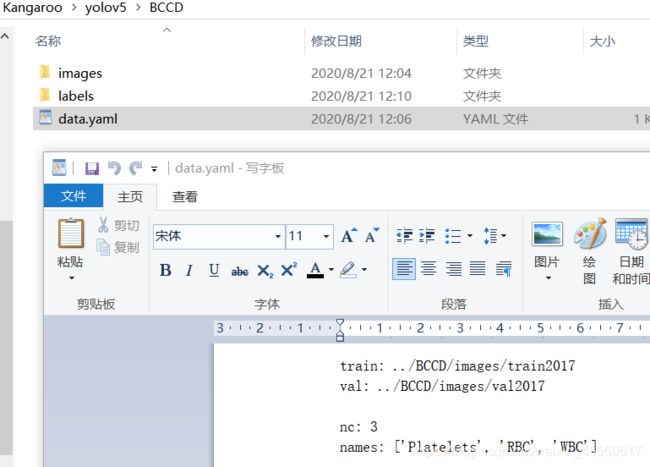
配置数据的yaml文件
在yolov5/data/ 复制一份yaml文件放到BCCD下,这就是上图的data.yaml文件。
打开以后修改对应的照片路径,以及nc(标签个数)、name(标签名)
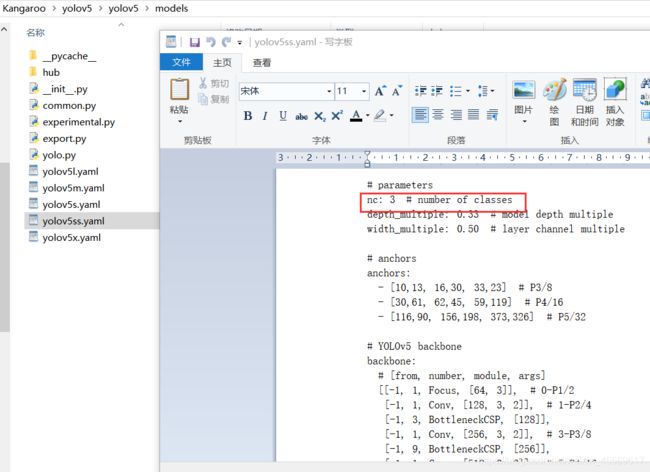
配置模型的yaml文件
来到yolov5/models/
选择你想训练的模型文件,修改他的nc个数
4.0版本的不同之处
使用4.0版本会要求增加一个pandas的库,这个大家直接用conda或者pip安装一下就好了。
但另外一个问题就比较难搞,它会检查pycocotools的2.0版本级及以上是否存在。

win10安装pycocotools是十分不友好的,下面的方法用于解决这个问题。linux系统的可以绕过下面的内容。
方法一:安装pycocotools
这一种方法我以前是成功的,但我在现在这个环境中失败了,大家可以尝试一下,也许能成功。
具体方法我在我的第一篇博客中有提过2020年tensorflow定制训练模型笔记(1)——object detection的安装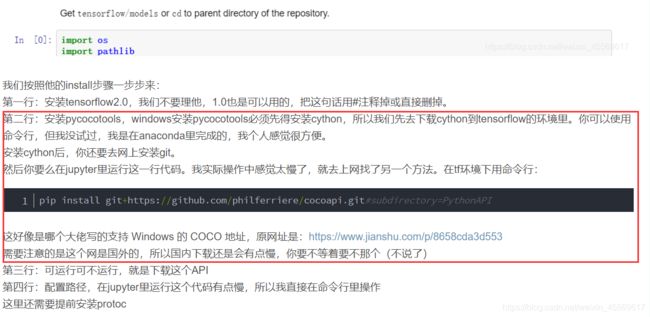
大家按照那个博客中给的教程和网址尝试一下,因为我当时的确是靠那个网址的方法成功在win10上安装了pycocotools,现在不知道为什么不行。
方法二:注释掉报错语句
上一种办法行不通可以试试这个。
从上图中可以看出,问题出在train.py的第475行的检查环境配置的内容上,所以直接注释掉他。
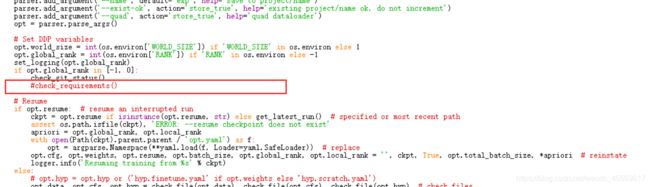
实测可以成功训练。
在可以成功训练时还有可能报下面的错:

这是seaborn的版本不对,升级一下就好了。
wandb可视化
除此之外,4.0版本还增加了一个wandb库用于更直观的训练可视化,大家可以在训练过程中安装并使用。
安装过wandb后,运行train.py会出现这么一行,我这里直接输入1.
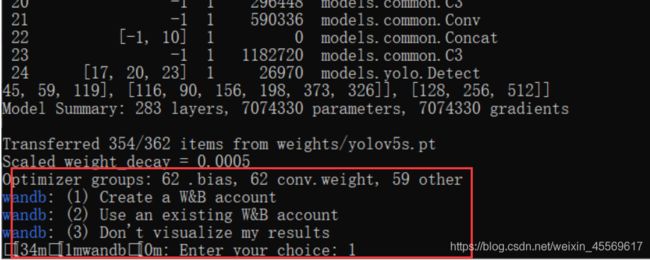
随后会出现下面这几行,来到浏览器输入红框的网址。
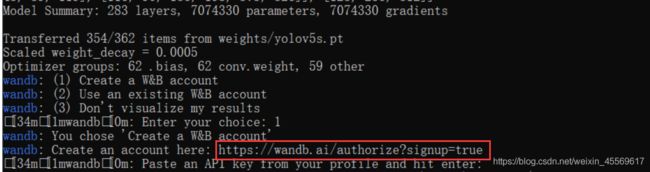
这个网址上会有个API key,复制他粘贴到命令行即可,这个key在命令行中是不可见的。
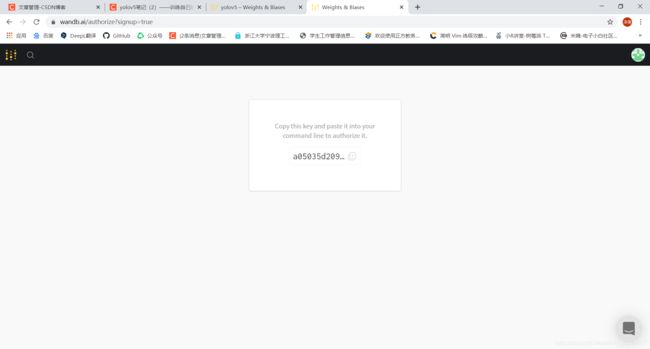
我其实中途去wandb的官网注册了一个账户,直接与github的账户注册的,在运行命令行时也没有关掉账户,不知道有没有影响。
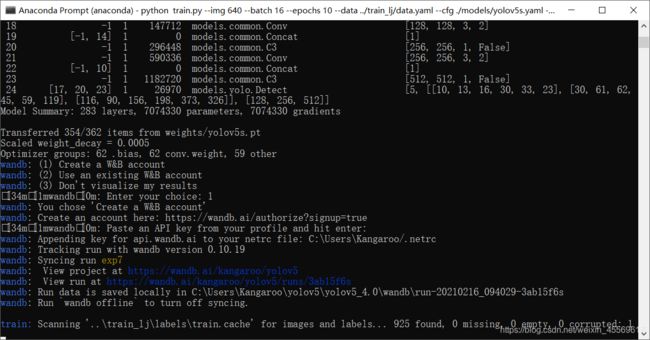
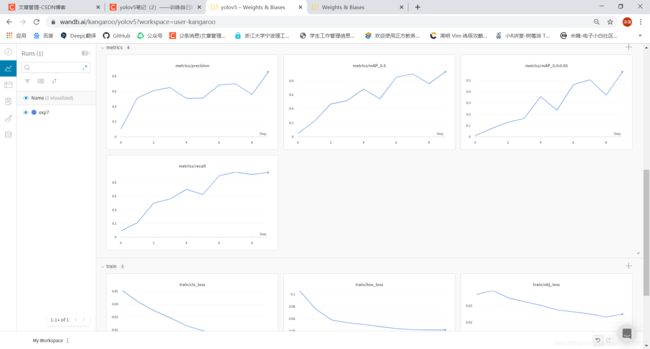
待训练程序跑起来,我们可以刷新wandb官网便可以看到可视化的结果。
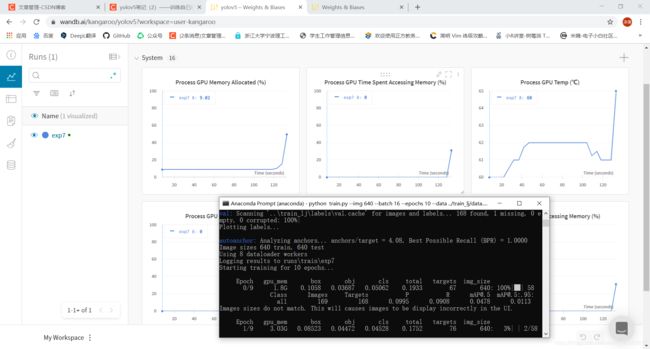
训练完后的wandb可视化部分图片展示
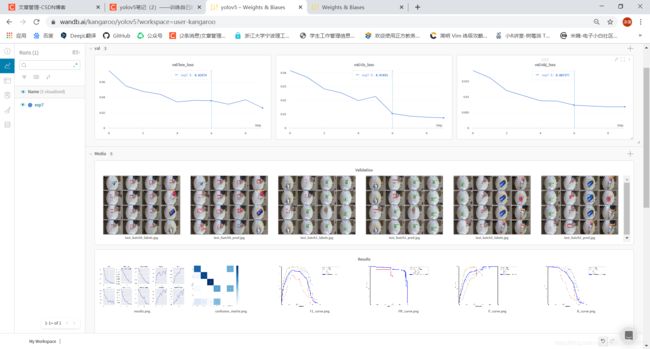
我这次实验的是一个垃圾分类的模型,这是验证集的输出。


5.0版本的不同之处
增加了P6模型,拥有四个输出层(P3,P4,P5,P6),具体理解可以去看这个博客Yolov3&Yolov4&Yolov5模型权重及网络结构图资源下载中的这张图
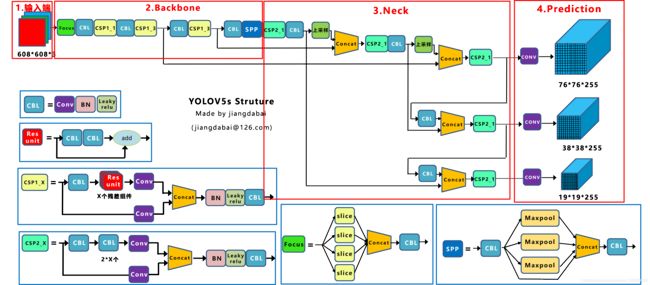
就是prediction这个位置的三个输出层下面再添加一层输出层,当然backbone也会有所变化。
P6模型包括一个额外的P6 / 64输出层,用于检测较大的物体,并且可以通过更高分辨率的训练获得最大的收益。
预训练模型中,所有P5的size为640,所有P6的size为1280。
预训练模型去这里下载一下就好了预训练模型
data文件放在了model下的hub中,官方似乎已经在测试transformer的集成了。
程序的运行上,除了还是要屏蔽检查pycocotools的代码,还要下载thop的库。直接pip install thop就好。
4. 开始训练
运行
在yolov5文件夹下运行
python train.py --img 640 --batch 16 --epochs 100 --data ../BCCD/data.yaml --cfg ./models/yolov5s.yaml --weights ''
# --img 统一输入图像规模
# --batch 每次网络训练输入图像的数量,最底性能为1
# --epochs 训练次数
# --data 数据yaml文件的相对位置
# --cfg 模型yaml文件的位置
# --weights 预训练模型(上一节下载的权重文件)位置,从头开始训练如上所示
# --device 训练的设备(CPU or GPU)
可以从官方给的四个模型中挑选一个合适的速度精度模型来作迁移训练
python train.py --img 640 --batch 16 --epochs 100 --data ../BCCD/data.yaml --cfg ./models/yolov5s.yaml --weights weights/yolov5s.pt
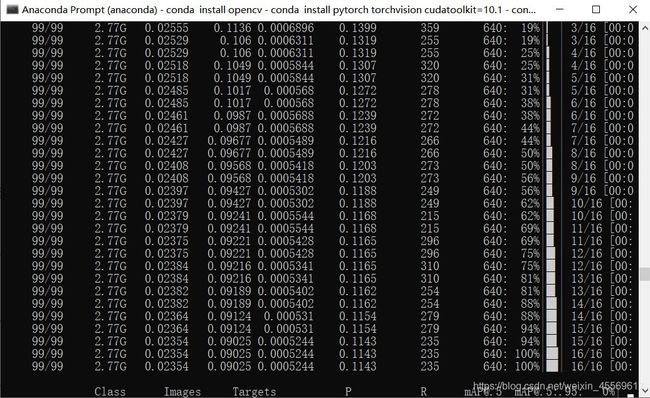
运行时CPU的情况
运行时GPU的情况
tensorboard
训练好的模型在runs文件夹下对应的exp文件夹
tensorboard --logdir=runs/exp0
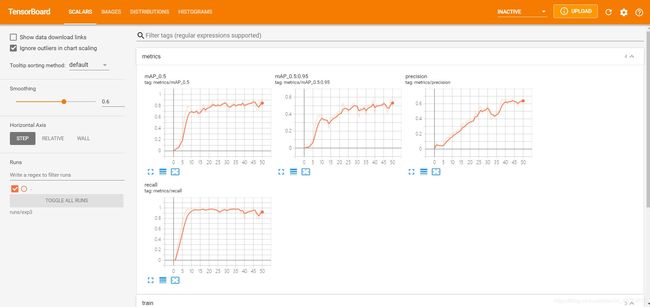
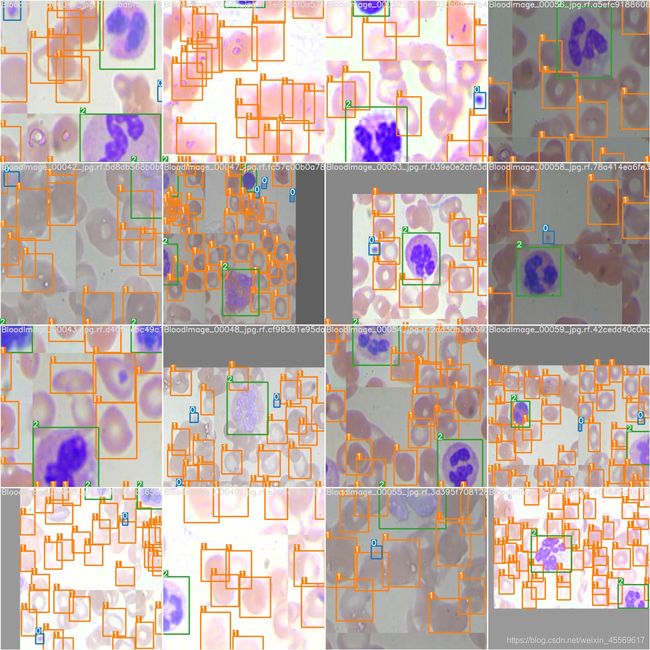
训练结果反馈
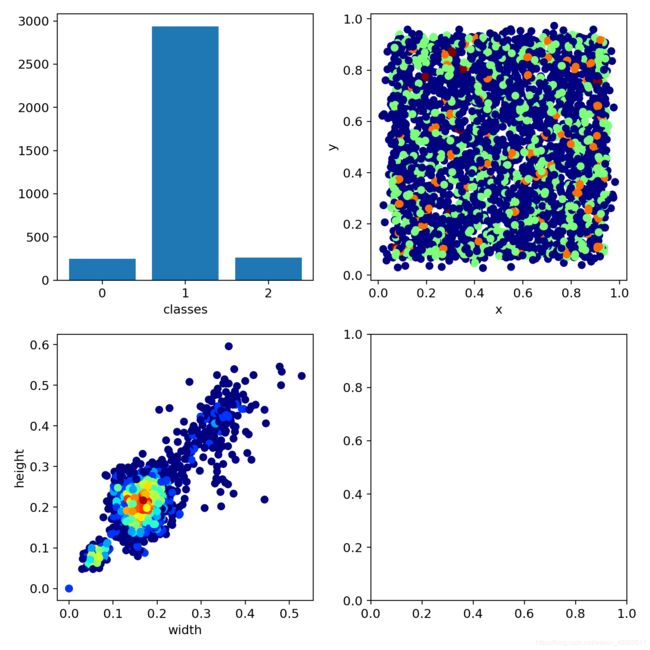
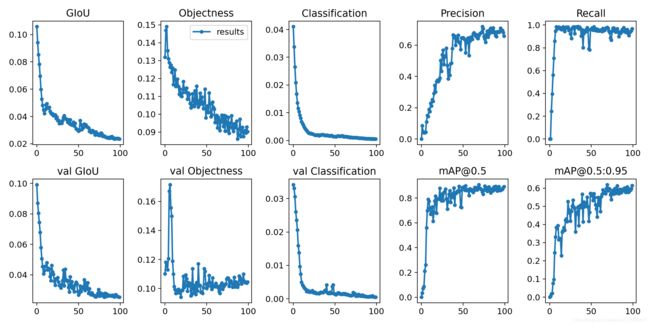
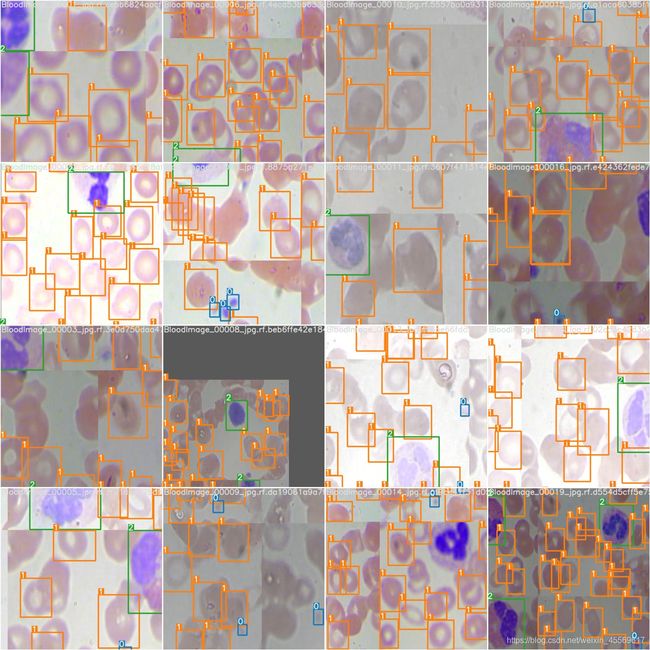
5. 测试
用detct.py文件测试训练好的模型
训练好的模型在runs/exp0/weights 文件夹下
可以看到一些数据:100次训练耗时1.191小时,权重模型大小只有14.8mb(挺小的了,移动端部署应该没啥问题),mAP值为0.893(越接近1越好)
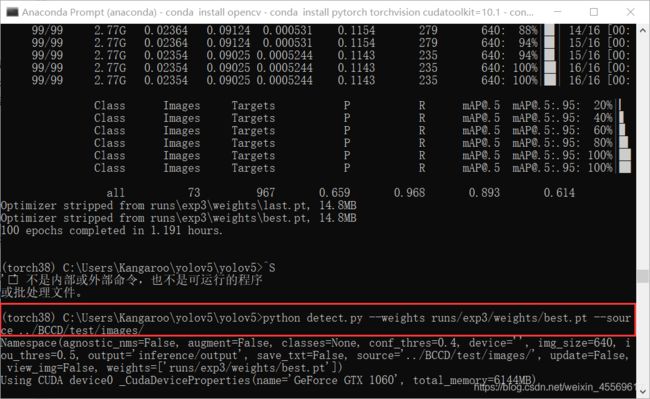
测试结果放在inference/output 下
可以看到0.016s下张图,速度是相当的快了!
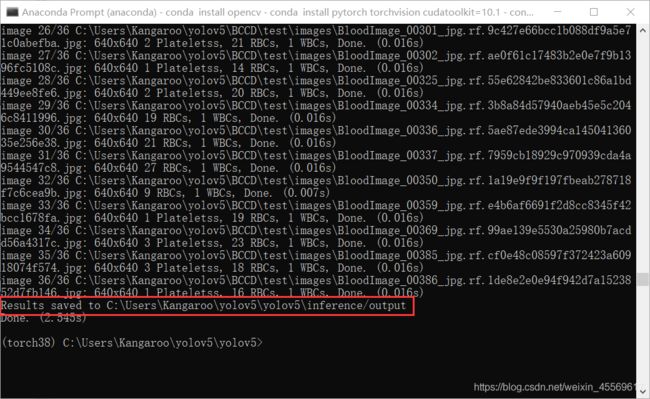
测试结果

yolov5笔记(1)——安装pytorch_GPU(win10+anaconda3)
yolov5笔记(2)——训练自己的数据模型(随5.0更新)
yolov5笔记(3)——移动端部署自己的模型(随5.0更新)