本文(简要地)介绍进程的内存镜像,以及 malloc 的实现。
如无特别说明,本文代码均在 Ubuntu16 下运行,gcc 版本为 9.0,使用 -m32 参数编译。
Process in Memory
预备知识:
- 进程的虚拟地址空间 (Virtual Address Space)
- 打印各个 segment 的地址
Virtual Address Space
一张经典的图片:进程的虚拟地址空间 (Virtual Address Space) ,在 32 位机器下:
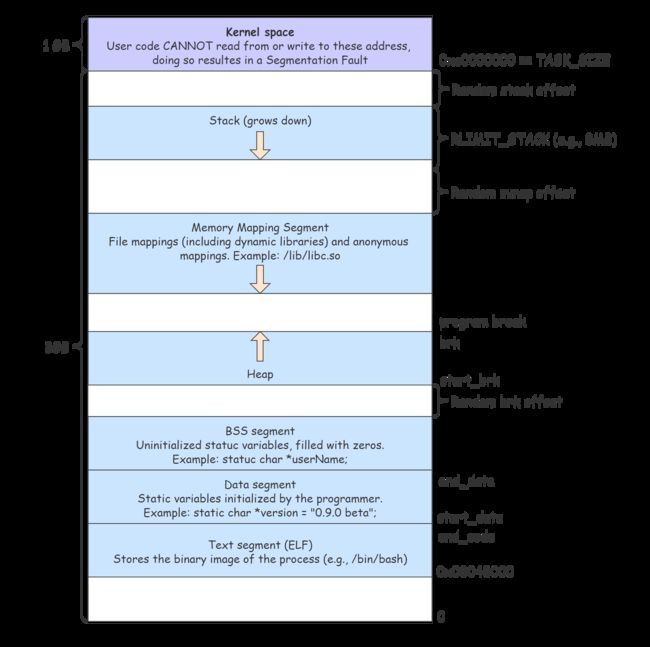
- 可执行代码 (ELF, Excutable and Linkable Format) 放在
.text段,32 位机器下,起始地址是0x8048000(64 位机器下是0x400000)。 .data段存放已初始化的static变量和已初始化的全局变量。.bss(Block Started by Symbol) 段存放未初始化的static变量和未初始化的全局变量。
为什么需要区分
.bss段和.data段,统一把.bss的变量清零,然后合并为一个.data段不行吗?区分可执行文件与进程 2 个概念。因为
.bss段中的变量,在可执行文件中,只记录变量名(实质上是一个地址,并且是可重定向的地址),而不会分配真实的磁盘空间,这一点可降低可执行文件的大小。但在实际的进程当中,OS 会将.bss所有变量清零,并分配内存,即在进程中,.bss的变量依旧占用内存(但在可执行文件中,不占用磁盘)。
- 注意到有 2 个偏移
Random brk offset和Random stack offset,可执行文件加载到内存时,代码段和数据段的大小都是固定的,为什么需要加入随机的偏移呢?
参考 linux memory management - how to get "Random xxx offset"?
The randomization is just to make it harder to hack, so the hacker doesn't know exactly where to look to read things from your stack or heap.
- 对于栈和堆中间的地址,用于各种动态链接库的映射,或者调用
mmap()申请共享内存用于 IPC。
如果一个进程的 PID = 17137,那么可以通过
cat /proc/17137/maps查看映射的内容:> cat /proc/17137/maps 08048000-08049000 r-xp 00000000 08:01 56623614 /home/sinkinben/a.out 08049000-0804a000 r--p 00000000 08:01 56623614 /home/sinkinben/a.out 0804a000-0804b000 rw-p 00001000 08:01 56623614 /home/sinkinben/a.out 090df000-09101000 rw-p 00000000 00:00 0 [heap] f74d6000-f74f3000 r--p 00000000 08:01 49283078 /lib32/libc-2.31.so f74f3000-f764b000 r-xp 0001d000 08:01 49283078 /lib32/libc-2.31.so f764b000-f76bb000 r--p 00175000 08:01 49283078 /lib32/libc-2.31.so f76bb000-f76bd000 r--p 001e4000 08:01 49283078 /lib32/libc-2.31.so f76bd000-f76bf000 rw-p 001e6000 08:01 49283078 /lib32/libc-2.31.so f76bf000-f76c1000 rw-p 00000000 00:00 0 f76d6000-f76d8000 rw-p 00000000 00:00 0 f76d8000-f76db000 r--p 00000000 00:00 0 [vvar] f76db000-f76dd000 r-xp 00000000 00:00 0 [vdso] f76dd000-f76de000 r--p 00000000 08:01 49283074 /lib32/ld-2.31.so f76de000-f76fc000 r-xp 00001000 08:01 49283074 /lib32/ld-2.31.so f76fc000-f7707000 r--p 0001f000 08:01 49283074 /lib32/ld-2.31.so f7708000-f7709000 r--p 0002a000 08:01 49283074 /lib32/ld-2.31.so f7709000-f770a000 rw-p 0002b000 08:01 49283074 /lib32/ld-2.31.so ffd5e000-ffd7f000 rw-p 00000000 00:00 0 [stack]其实我们的
prinf函数就是通过链接libc.so来调用的。
Segment
先看一段代码:
#include
extern end;
extern edata;
extern etext;
int I;
static int inited = -1;
int main(int argc, char **argv)
{
int i;
int *ii;
printf("&etext = 0x%lx\n", &etext);
printf("&edata = 0x%lx\n", &edata);
printf("&end = 0x%lx\n", &end);
printf("\n");
ii = (int *) malloc(sizeof(int));
printf("main = 0x%lx\n", main);
printf("&I = 0x%lx\n", &I);
printf("&i = 0x%lx\n", &i);
printf("&argc = 0x%lx\n", &argc);
printf("&ii = 0x%lx\n", &ii);
printf("ii = 0x%lx\n", ii);
printf("&inited= 0x%lx\n", &inited);
}
在上述代码中:etext, edata, end 是链接器 ld 保留的字符,它们分别会指向 .text, .data, .bss 这三个 Segment 的结束位置。
因为我们的教材都是讲 32 位机器的,所以我们把它编译位 32 位的机器码:
gcc -m32 testaddr.c
运行结果:
&etext = 0x8048714
&edata = 0x804a02c
&end = 0x804a034
main = 0x8048542
&I = 0x804a030
&i = 0xffec5cc4
&argc = 0xffec5cf0
&ii = 0xffec5cc8
ii = 0xa0165b0
&inited= 0x804a028
可以看出:
argc, i, ii这 3 个变量都是在栈上的,地址偏大。ii指向的位置在堆上。main在.text,因此其地址小于etext。I在.bss,因此其地址大于edata,小于end,在这个例子中,I的结束位置也是end。inited在.data,因此其地址大于etext,小于edata,在这个例子中,inited的结束位置也是edata。
编译为 64 位的可执行文件,结果如下:
&etext = 0x400865
&edata = 0x60104c
&end = 0x601058
main = 0x4006b2
&I = 0x601050
&i = 0x7ffcfeb0cf3c
&argc = 0x7ffcfeb0cf2c
&ii = 0x7ffcfeb0cf40
ii = 0x175d6b0
&inited= 0x601048
众所周知,数据段(bss 和 data)的可读可写,但代码段 text 是只读。
#include
extern end;
extern etext;
int main()
{
char *s;
char c;
printf("&etext = 0x%lx\n", &etext);
printf("&end = 0x%lx\n", &end);
printf("\n");
printf("Enter memory location in hex (start with 0x): ");
fflush(stdout);
scanf("0x%x", &s);
printf("Reading 0x%x: ", s);
fflush(stdout);
c = *s;
printf("%d\n", c);
printf("Writing %d back to 0x%x: ", c, s);
fflush(stdout);
*s = c;
printf("ok\n");
}
比如:
&etext = 0x80487a4
&end = 0x804a038
Enter memory location in hex (start with 0x): 0x80487a0
Reading 0x80487a0: -60
Writing -60 back to 0x80487a0: Segmentation fault (core dumped)
输入一个 text 段的地址,当写回时发生 Segmentation fault 。如果操作的地址是 0x80487a8,它是否能覆盖某个数据段段变量值呢?
&etext = 0x80487a4
&end = 0x804a038
Enter memory location in hex (start with 0x): 0x80487a8
Reading 0x80487a8: 1
Writing 1 back to 0x80487a8: Segmentation fault (core dumped)
很奇怪?这是因为 OS 对进程的内存镜像是按页管理的,因此虽然代码段在 etext 结束,但 etext 后面的一部分内存虽然没用到(此处是 4K 页,即 [etext, 0x8049000) 这一区间),这也属于代码段,上面的地址 0x80487a8 就是属于页对齐范围内的地址。
使用
getconf PAGESIZE可以查看 OS 的内存页大小。
类似地,如果我们对 end 往后的地址写,理论上也是可以的,因为 [end, 0x804b000) 在页对齐之后,都属于数据段。
$ ./a.out
&etext = 0x80487a4
&end = 0x804a038
Enter memory location in hex (start with 0x): 0x804a01c
Reading 0x804a01c: -16
Writing -16 back to 0x804a01c: ok
$ ./a.out
&etext = 0x80487a4
&end = 0x804a038
# 需要注意的是,此处的代码是仅读取一个字节,如果 char *s 改为 int *s, 那么此处也会读失败。
Enter memory location in hex (start with 0x): 0x804afff
Reading 0x804afff: 0
Writing 0 back to 0x804afff: ok
$ ./a.out
&etext = 0x80487a4
&end = 0x804a038
Enter memory location in hex (start with 0x): 0x804b000
Reading 0x804b000: Segmentation fault (core dumped)
Heap
一个进程中,Heap 的结束位置由 Program Break 记录,在 Unix 环境下,我们可以通过 sbrk(0) 去获取该地址。
sbrk(val)的作用是将 Program Break 往上增加val,并返回增加后的结果。brk(addr)的作用是将 Program Break 的值调整为addr, 成功返回 0 ,失败返回 -1 。
例如:
#include
extern end;
extern etext;
int main()
{
char *s;
char c;
printf("&etext = 0x%lx\n", &etext);
printf("&end = 0x%lx\n", &end);
printf("sbrk(0)= 0x%lx\n", sbrk(0));
printf("&c = 0x%lx\n", &c);
printf("\n");
printf("Enter memory location in hex (start with 0x): ");
fflush(stdout);
scanf("0x%x", &s);
printf("Reading 0x%x: ", s);
fflush(stdout);
c = *s;
printf("%d\n", c);
printf("Writing %d back to 0x%x: ", c, s);
fflush(stdout);
*s = c;
printf("ok\n");
}
运行结果:
&etext = 0x8048814
&end = 0x804a03c
sbrk(0)= 0x990b000
&c = 0xffe299a7
为什么 sbrk(0) 和 end 差这么多呢?这是由于加入了上述的 Random Brk Offset 的结果。
Stack
使用 ulimit -a 可以看到 OS 给每个进程默认分配的栈大小:
> ulimit -a
...
stack size (kbytes, -s) 8192
...
此处是 8MB ,如果我们在栈上的局部变量过大,那么会引发 Segmentation fault ,例如下面代码:
#include
int main()
{
char data[8192 * 1024] = {'\0'};
}
运行命令:
> cat /proc/{pid}/maps
...
ffd42000-ffd63000 rw-p 00000000 00:00 0 [stack]
可以发现 [0xffd42000, 0xffd63000) 这一区间是上述程序的初始栈,大小为 0x21000 = 33 * 4096 。为什么不是 8MB 呢?个人理解是因为初始状态并不需要预分配 8MB / 4096 = 2048 这么多个页。 [0xffd42000, 0xffd63000) 这个虚拟地址区间应该对应 33 个在内存中的物理页。
Malloc
glibc 的 malloc 的源代码:
- https://code.woboq.org/userspace/glibc/malloc/malloc.c.html#1059
- https://code.woboq.org/userspace/glibc/malloc/memusage.c.html#malloc
malloc 的实现策略与 OS 和采用的 C 标准库有关,但一般而言,可以归结为:
- 预分配若干个 PAGE ,初始化空闲链表和已使用链表。
- 分配的单位是一个 chuck,一个 chuck 包括
- 每次调用
malloc,取出一块符合要求的 chunk 内存块(「取」的算法视乎 OS 和 C 标准库的具体实现),返回起始地址,并加入已使用链表。 - 调用
free时,将这一块内存加入空闲链表(可能需要与其他空闲内存块进行合并)。
Overview
上一节提到,我们可以通过 sbrk(0) 获取堆的结束位置。
#include
#include
int main()
{
int *i1, *i2;
printf("sbrk(0) before malloc(4): 0x%x\n", sbrk(0));
i1 = (int *) malloc(4);
printf("sbrk(0) after `i1 = (int *) malloc(4)': 0x%x\n", sbrk(0));
i2 = (int *) malloc(4);
printf("sbrk(0) after `i2 = (int *) malloc(4)': 0x%x\n", sbrk(0));
printf("i1 = 0x%x, i2 = 0x%x\n", i1, i2);
}
运行输出:
sbrk(0) before malloc(4): 0x843e000
sbrk(0) after `i1 = (int *) malloc(4)': 0x8460000
sbrk(0) after `i2 = (int *) malloc(4)': 0x8460000
i1 = 0x843e5b0, i2 = 0x843e5c0
可以发现,当第二次调用 malloc 时,并没有改变 sbrk(0) 的值,而是从预分配的 Buffer 中返回 4 字节的内存。预分配内存的大小为 0x8460000 - 0x843e000 = 0x22000 ,一共 34 个 PAGE 。
注意到 i1, i2 之间一共差了 16 个字节,这是由于 Bookeeping 头部信息的结果(后续的内容会提到)。
如果使用 malloc 分配一块很大的内存,根据 OS 和 C 标准库的内存管理策略的不同,可能并不是通过 malloc 去分配,而是通过 memory mapping,例如在 Ubuntu 下:
int main()
{
printf("sbrk(0) = %p\n", sbrk(0));
char *small = (char*)malloc(4);
printf("small = %p\n", small);
printf("sbrk(0) = %p\n", sbrk(0));
char *large = (char *)malloc(0x22000);
printf("large = %p\n", large);
printf("sbrk(0) = %p\n", sbrk(0));
while (1) ;
}
运行输出:
sbrk(0) = 0x8aa3000
small = 0x8aa35b0
sbrk(0) = 0x8ac5000 # 调用 malloc(4) 后, sbrk(0) += 0x22000
large = 0xf74bf010
sbrk(0) = 0x8ac5000 # 调用 malloc(0x22000) 后, sbrk(0) 不变
第二次申请,按道理 malloc 应该会再次申请一个 Buffer,为什么会不变呢?
# PID(a.out) = 19619
> cat /proc/19619/maps
...
08aa3000-08ac5000 rw-p 00000000 00:00 0 [heap]
f74bf000-f74e2000 rw-p 00000000 00:00 0
...
可以看到,虚拟地址 f74bf000-f74e2000 属于 memory mapping 的地址范围,而 large = 0xf74bf010 正好处于这一区间的开始位置,前 16 个字节是该内存块的 Bookeeping 。
Bookeeping
参考:GLIBC malloc implementation bookkeeping
样例代码:
#include
#include
main()
{
int *buf;
int i, sz;
i = 1000;
printf("sbrk(0) = 0x%x\n", sbrk(0));
for (sz = 4; sz < 32; sz += 4) {
buf = (int *) malloc(sz);
buf[0] = i;
i++;
printf("Allocated %d bytes. buf = 0x%x, buf[-1] = %d, buf[-2] = %d, buf[0] = %d\n",
sz, buf, buf[-1], buf[-2], buf[0]);
}
sz = 100;
buf = (int *) malloc(sz);
buf[0] = i;
i++;
printf("Allocated %d bytes. buf = 0x%x, buf[-1] = %d, buf[-2] = %d, buf[0] = %d\n",
sz, buf, buf[-1], buf[-2], buf[0]);
printf("sbrk(0) = 0x%x\n", sbrk(0));
}
运行输出:
sbrk(0) = 0x8f69000
Allocated 4 bytes. buf = 0x8f695b0, buf[-1] = 17, buf[-2] = 0, buf[0] = 1000
Allocated 8 bytes. buf = 0x8f695c0, buf[-1] = 17, buf[-2] = 0, buf[0] = 1001
Allocated 12 bytes. buf = 0x8f695d0, buf[-1] = 17, buf[-2] = 0, buf[0] = 1002
Allocated 16 bytes. buf = 0x8f695e0, buf[-1] = 33, buf[-2] = 0, buf[0] = 1003
Allocated 20 bytes. buf = 0x8f69600, buf[-1] = 33, buf[-2] = 0, buf[0] = 1004
Allocated 24 bytes. buf = 0x8f69620, buf[-1] = 33, buf[-2] = 0, buf[0] = 1005
Allocated 28 bytes. buf = 0x8f69640, buf[-1] = 33, buf[-2] = 0, buf[0] = 1006
Allocated 100 bytes. buf = 0x8f69660, buf[-1] = 113, buf[-2] = 0, buf[0] = 1007
sbrk(0) = 0x8f8b000
为什么是 17, 33, 113 这样「奇怪」的数字呢,直觉上,如果考虑字节对齐,Bookeeping 这样的因素,buf[-1] 理应是一个偶数。为什么会这样呢?
先看 malloc 中,一个 chunk 的数据结构:
struct malloc_chunk {
INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
在这一数据结构当中,除了 mchunk_prev_size, mchunk_size 这 2 个成员,其他 4 个当且仅当这个 chuck 是空闲的时候才有意义。
同时,以上述的 malloc_chunk 作为链表节点, malloc 需要维护已使用链表和空闲链表。
此外,上面的代码 chuck 最小为 16 字节的原因:
Chunks always begin on even word boundaries, so the
memportion (which is returned to the user) is also on an even word boundary, and thus at least double-word (8 bytes) aligned.
Allocated List
对于已使用链表:
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk, if unallocated (P clear) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of chunk, in bytes |A|M|P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| User data starts here... .
. .
. (malloc_usable_size() bytes) .
. |
nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| (size of chunk, but used for application data) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of next chunk, in bytes |A|0|1|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
如果一个 chunk 已被分配出去,那么这时候,mchunk_prev_size 这个成员也不需要了,因此这 4 字节可提供给前一个 chuck 的 User Memory 使用。
AMP 是 3 个标记位,分别表示:
A: non main arena chunk.M: chunk ismmaped.P: previous chunk is in use (i.e. not free).
为什么在上述的代码中,buf[-1] 总是一个奇数呢?这是因为标记位 P = 1 。
在 Bookeeping 一节的代码中,堆内存的状态如下:
+-----------+ 0x8f695a8
| prev size |
|-----------|
| size |
a --> |-----------| 0x8f695b0
| user data |
| |
+-----------+ 0x8f695b8
| prev size |
|-----------|
| size |
b --> |-----------| 0x8f695c0
| user data |
| |
+-----------+ 0x8f695c8
| prev size |
|-----------|
| size |
c --> |-----------| 0x8f695d0
| user data |
| |
+-----------+ 0x8f695d8
| prev size | <-------- used for user data
|-----------| 0x8f695dc
| size |
d --> |-----------| 0x8f695e0
| user data |
| ... |
Free List
对于空闲链表:
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk, if unallocated (P clear) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
`head:' | Size of chunk, in bytes |A|0|P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Forward pointer to next chunk in list |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Back pointer to previous chunk in list |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Unused space (may be 0 bytes long) .
. .
. |
nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
`foot:' | Size of chunk, in bytes |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of next chunk, in bytes |A|0|0|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
每当调用 free 回收内存时,被回收的 chunk 插入空闲链表时,需要填入 forward, back 两个地址,记录前后的空闲 chunk ,如果空闲链表中有多个地址是连续的 chunk,需要合并为一个。
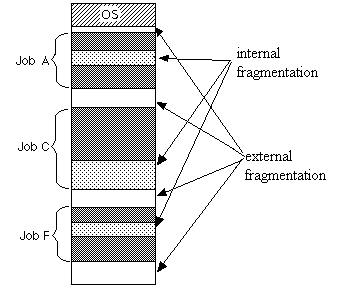
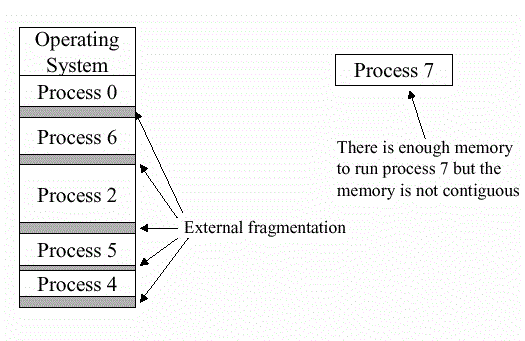
Fragmentation
参考:Internal and external fragmentation
本节的内容是内存碎片 (Fragmentation) ,分为内部碎片 (internal) 和外部碎片 (external) 。
对于上文提及的内容,又涉及 2 个层面的内存管理:
- 库函数
malloc对预申请 Heap Buffer 的内存管理(堆内存管理),这是在用户空间层面的内存管理,在申请与回收堆内存时,会产生 chunk 碎片。 - OS 对真实物理内存的管理,物理内存的分配单位是 PAGE,在申请与回收物理页的过程中,同样会产生页碎片。
不论采用什么样的内存管理策略,碎片的产生都是不可避免的,而 external 和 internal 其实是相对于进程而言的。
假设加载某个进程到内存需要 N 字节,那么需要分配 k = N / PAGE_SIZE + (k % PAGE_SIZE) != 0 个物理页,这时候就会产生 PAGE_SIZE - N % PAGE_SIZE 的碎片,这种叫外部碎片。
而在某个进程的内存中,malloc 预分配一块内存,但又没有被用户申请使用,这些内存是内部碎片。
| Internal | External |
|---|---|
 |
 |
Summary
一些无关重要的总结。
通常「面试八股文」所说的 “内存管理” ,正常人的理解应该是指 Linux 内核层面的内存管理(即 buddy 和 slab 这 2 个算法),一般来说是指:
- Buddy 是对真实的物理内存(即 DRAM)进行管理,管理的单位是 PAGE 。
- 在 Linux 内核中,如果只能按页分配,那么碎片会非常大,假设一个结构体只有 20 bytes , 这时当然希望能够按字节分配,所以才会有 slab allocator 。

对于 buddy 和 slab ,可以参考:
- https://www.kernel.org/doc/gorman/html/understand/understand011.html
- https://hammertux.github.io/slab-allocator
References
- [1] https://web.eecs.utk.edu/~huangj/cs360/lecture_notes.html
- [2] https://manybutfinite.com/post/anatomy-of-a-program-in-memory/
- [3] glibc - malloc