「数据科学」使用 seaborn 进行数据可视化
使用 seaborn 进行数据可视化
- seaborn 简介
- 布局风格
-
- 样式控制:axes_style() and set_style()
- 边框控制:despine()
- 绘图元素:plotting_context() 和 set_context()
- 绘图
-
- 可视化统计关系 relplot
-
- 散点图
- 线图
- 可视化数据集的分布 distplot
-
- 直方图
- 可视化分类数据 catplot
-
- 分类散点图
- 分类分布图
- 分类估计图
- 一些参数
seaborn 简介
上一篇文章介绍了使用 matplotlib 进行数据可视化
「数据科学」使用 seaborn 进行数据可视化
seaborn 是一种基于matplotlib的图形可视化python libraty。它提供了一种高度交互式界面,便于用户能够做出各种有吸引力的统计图表。
seaborn 其实是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,在大多数情况下使用 seaborn 就能做出很具有吸引力的图,而使用matplotlib就能制作具有更多特色的图。应该把 seaborn 视为 matplotlib 的补充,而不是替代物。同时它能高度兼容 numpy 与 pandas 数据结构以及 scipy 与 statsmodels 等统计模式。掌握 seaborn 能很大程度帮助我们更高效的观察数据与图表,并且更加深入了解它们。

其有如下特点:
- 计算多变量间关系的面向数据集接口
- 可视化类别变量的观测与统计
- 可视化单变量或多变量分布并与其子数据集比较
- 控制线性回归的不同因变量并进行参数估计与作图
- 对复杂数据进行易行的整体结构可视化
- 对多表统计图的制作高度抽象并简化可视化过程
- 提供多个内建主题渲染 matplotlib 的图像样式
- 提供调色板工具生动再现数据
seaborn 框架旨在以数据可视化为中心来挖掘与理解数据。它提供的面向数据集制图函数主要是对行列索引和数组的操作,包含对整个数据集进行内部的语义映射与统计整合,以此生成富于信息的图表。
布局风格
import seaborn as sns
sns.set()
设置画图空间为 seaborn 默认风格。
seaborn默认的灰色网格底色灵感来源于 matplotlib 却更加柔和。大多数情况下,图应优于表。seaborn 的默认灰色网格底色避免了刺目的干扰,对于多个方面的图形尤其有用,是一些更复杂的工具的核心。
样式控制:axes_style() and set_style()
sns.set_style( strStyle )
设置画图空间为指定风格,分别有:
- darkgrid 黑色网格(默认)
- whitegrid 白色网格
- dark 黑色背景
- white 白色背景
- ticks 四周都有刻度线的白背景
with sns.axed_style( strStyle ) :
临时设定图形样式,此背景风格设置只对冒号后对应缩进内画的图有效,其他区域不变。
边框控制:despine()
sns.despine(fig=None, ax=None, top=True, right=True, left=False, bottom=False, offset=None, trim=False)
参数 top, bottom, left, right: True表示删除该边框,False表示保留。默认情况下使用 despine 方法删除上方和右方边框。
参数offset: 设置图与轴线的距离。
white 和 ticks 参数的样式,都可以删除上方和右方坐标轴上不需要的边框,这在 matplotlib 中是无法通过参数实现的,却可以在 seaborn 中通过 despine() 函数轻松移除他们。
绘图元素:plotting_context() 和 set_context()
sns.set_context( strContext, rc )
设置绘图元素的规模,按相对尺寸的顺序(线条越来越粗),分别有:
- paper
- notebook (默认)
- talk
- poster
with sns.plotting_context( strContext ) :
临时设定绘图元素的规模,此设置只对冒号后对应缩进内画的图有效,其他区域不变。
绘图

import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
可视化统计关系 relplot
统计分析是了解数据集中的变量如何相互关联以及这些关系如何依赖于其他变量的过程。可视化是此过程的核心组件,这是因为当数据被恰当地可视化时,人的视觉系统可以看到指示关系的趋势和模式。
relplot(kind=‘scatter’) 将 FacetGrid() 与 scatterplot() 和 lineplot() 组合在一起。
散点图
参数hue: 色调语义,对点进行着色来将另一个维度添加到绘图中。
参数style: 标记样式,为了强调类别之间的差异并提高可访问性。
参数size: 改变每个点的大小。
tips = sns.load_dataset("tips")
sns.relplot(x="total_bill", y="tip", size="size", hue="smoker", style="time", data=tips);

线图
fmri = sns.load_dataset("fmri")
sns.relplot(x="timepoint", y="signal", kind="line", data=fmri)

可视化数据集的分布 distplot
在处理一组数据时,通常要做的第一件事就是了解变量的分布情况。
distplot() 将会绘制直方图 histogram 并拟合(内核密度估计) kernel density estimate(KDE)。
直方图
参数bins: 直方的数量
参数kde: 是否使用核密度估计
参数rug: 删除密度曲线并添加一个 rug plot,它在每个观察值上画一个小的垂直刻度
x = np.random.normal(size=100)
sns.distplot(x, bins=20, kde=True, rug=True, hist=True);

可视化分类数据 catplot
可视化统计关系中,我们专注于两个数值变量之间的主要关系。如果其中一个主要变量是“可分类的”(能被分为不同的组),那么我们可以使用更专业的可视化方法。
catplot(kind=‘strip’) 可以绘制分类数据图,包含三个家族:分类散点图stripplot、swarmplot,分类分布图boxplot、violinplot、boxenplot,分类估计图pointplot、barplot、countplot。
分类散点图
在 seaborn 中有两种不同的分类散点图,它们采用不同的方法来表示分类数据。 其中一种是属于一个类别的所有点,将沿着与分类变量对应的轴落在相同位置。另一种方法使用防止它们重叠的算法沿着分类轴调整点。
stripplot
参数jitter: 控制抖动的大小,可禁用
sns.set(style="ticks")
sns.catplot(x="day", y="total_bill", jitter=False, data=tips);

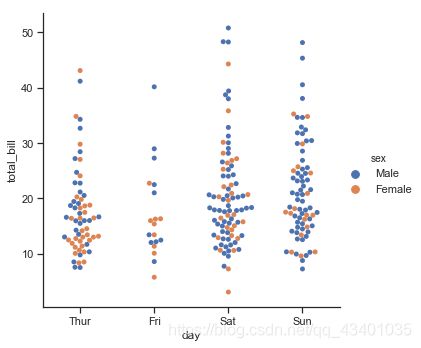
swarmplot
参数hue: 向分类图添加另一维,改变点颜色
参数order: 控制排序
sns.catplot(x="day", y="total_bill", hue="sex", kind="swarm", data=tips);
分类分布图
随着数据集的大小增加,分类散点图中每个类别可以提供的值分布信息受到限制。当发生这种情况时,有几种方法可以总结分布信息,以便于我们可以跨分类级别进行简单比较。
箱线图 boxplot
它可以显示分布的三个四分位数值以及极值。“胡须”延伸到位于下四分位数和上四分位数的 1.5 IQR 内的点,超出此范围的观察值会独立显示。这意味着箱线图中的每个值对应于数据中的实际观察值。
参数hue: 语义变量的每个级别的框沿着分类轴移动,因此它们将不会重叠
sns.catplot(x="day", y="total_bill", hue="smoker", kind="box", data=tips);

boxenplot
diamonds = sns.load_dataset("diamonds")
sns.catplot(x="color", y="price", kind="boxen",
data=diamonds.sort_values("color"));

小提琴图 violinplot
它将箱线图与核密度估算程序结合起来。
参数hue: “拆分”violins
sns.catplot(x="day", y="total_bill", hue="sex",
kind="violin", inner="stick", split=True,
palette="pastel", data=tips);

分类估计图
你可能希望显示值的集中趋势估计,而不是显示每个类别中的分布。
条形图 barplot
在完整数据集上运行并应用函数来获取估计值(默认情况下取平均值)。当每个类别中有多个观察值时,它还使用自举来计算估计值周围的置信区间,并使用误差条绘制:
titanic = sns.load_dataset("titanic")
sns.catplot(x="sex", y="survived", hue="class", kind="bar", data=titanic);

countplot
条形图的一个特例是,当你想要显示每个类别中的观察数量而不是计算第二个变量的统计数据时。这类似于分类而非定量变量的直方图。
sns.catplot(x="deck", kind="count", palette="ch:.25", data=titanic);

点图 pointplot
连接来自相同 hue 类别的点。我们可以很容易的看出主要关系如何随着色调语义的变化而变化,因为人类的眼睛很擅长观察斜率的差异:
sns.catplot(x="class", y="survived", hue="sex",
palette={
"male": "g", "female": "m"},
markers=["^", "o"], linestyles=["-", "--"],
kind="point", data=titanic);

一些参数
参数:x, y:data中的变量名
输入数据的变量;数据必须为数值型。
hue: data中的名称,可选
将会产生具有不同颜色的元素的变量进行分组。这些变量可以是类别变量或者数值型变量,尽管颜色映射在后面的情况中会有不同的表现。
style:data中的名称,可选
将会产生具有不同风格的元素的变量进行分组。这些变量可以为数值型,但是通常会被当做类别变量处理。
data:DataFrame
长格式的 DataFrame,每列是一个变量,每行是一个观察值。
row, col:data中的变量名,可选
确定网格的分面的类别变量。
col_wrap:int, 可选
以此宽度“包裹”列变量,以便列分面跨越多行。与
row分面不兼容。
row_order, col_order:字符串列表,可选
以此顺序组织网格的行和/或列,否则顺序将从数据对象中推断。
palette:色盘名,列表,或者字典,可选
用于
hue变量的不同级别的颜色。应当是color_palette()可以解释的东西,或者将色调级别映射到 matplotlib 颜色的字典。
hue_order:列表,可选
指定
hue变量层级出现的顺序,否则会根据数据确定。当hue变量为数值型时与此无关。
hue_norm:元组或者 Normalize 对象,可选
当
hue变量为数值型时,用于数据单元的 colormap 的标准化。如果hue为类别变量则与此无关。
legend:“brief”, “full”, 或者 False, 可选
用于决定如何绘制坐标轴。如果参数值为“brief”, 数值型的
hue以及size变量将会被用等间隔采样值表示。如果参数值为“full”, 每组都会在坐标轴中被记录。如果参数值为“false”, 不会添加坐标轴数据,也不会绘制坐标轴。
kind:string, 可选
绘制图的类型,与 seaborn 相关的图一致。
height:标量, 可选
每个 facet 的高度(英寸)。参见
aspect。
aspect:标量, 可选
每个 facet 的长宽比,因此“长宽比*高度”可以得出每个 facet 的宽度(英寸)。
facet_kws:dict, 可选
以字典形式传给
FacetGrid的其他关键字参数.
kwargs:键值对
传给后续绘制函数的其他关键字参数。
返回值:g:FacetGrid
返回包含图像的
FacetGrid对象,图像可以进一步调整。