Python中的数据可视化工具与方法——常用的数据分析包numpy、pandas、statistics的理解实现和可视化工具matplotlib的使用
Python中的数据可视化工具与方法
本文主要总结了:
1、本人在初学python时对常用的数据分析包numpy、pandas、statistics的学习理解以及简单的实例实现
2、可视化工具matplotlib的学习与使用
使用编程软件为pycharm
一、什么是数据可视化
数据可视化就是把数据从冰冷的数字转换成图形,一个好的可视化,能够带给人们不仅仅是视觉上的冲击,还能够揭示蕴含在数据中的规律和道理。
1、 数据可视化的概念:
狭义上的数字可视化指的是将数据用统计图表方式呈现,广义上数据可视化是信息可视化其中一类,因为信息是包含了数字和非数字的。使用计算机创建图形图表,可视化提取出来的数据,将数据的各种属性和变量呈现出来。我们熟悉的那些饼图、直方图、散点图、柱状图等就是最原始的统计图表,它们是数据可视化的最基础和常见的应用。数据可视化一般包括数据的采集、分析、治理、管理、挖掘在内的一系列复杂数据处理,然后由设计师设计一种表现形式,是立体的、二维的、动态的、实时的还是允许交互的。然后由工程师创建对应的可视化算法及技术实现手段。包括建模方法、处理大规模数据的体系架构、交互技术、放大缩小方法等。动画工程师考虑表面材质、动画渲染方法等,交互设计师也会介入进行用户交互行为模式的设计。
2、 数据可视化的应用
同一份数据可以可视化成多种看起来截然不同的形式,数据可视化的开发是根据需求、数据维度或属性进行筛选:
(1) 有的可视化目标是为了观测、跟踪数据,所以就要强调实时性、变化、运算能力,一般就会生成一份不停变化、可读性强的图表。
(2) 有的为了分析数据,所以要强调数据的呈现度、可能就会生成一份可以检索、交互式的图表
(3) 有的为了发现数据之间的潜在关联,可能会生成分布式的多维的图表。
(4) 有的为了帮助普通用户或商业用户快速理解数据的含义或变化,会利用漂亮的颜色、动画创建生动、明了,具有吸引力的图表。
(5) 还有的被用于教育、宣传或政治,被制作成海报、课件,出现在街头、广告手持、杂志和集会上。这类可视化拥有强大的说服力,使用强烈的对比、置换等手段,可以创造出极具冲击力自指人心的图像。在国外许多媒体会根据新闻主题或数据,雇用设计师来创建可视化图表对新闻主题进行辅助。
3、 数据可视化的目标
传统的可视化可以大致分为探索性可视化和解释性可视化
按照应用来分,可视化有多个目标:
(1) 有效呈现重要特征
(2) 揭示客观规律
(3) 辅助理解事物概念和过程
(4) 对模拟和测量进行质量监控
(5) 提高科研开发效率
(6) 促进沟通交流和合作
4、 数据可视化的功能
按照宏观的角度看,可视化的三个功能:
(1) 信息记录
(2) 信息推理和分析
(3) 信息传播与协同
二、python中常用的数据分析包
1、numpy
(1) 功能
numpy全称numeric python,是一个由多维数组对象和用于处理数组的例程集合组成的库,是python数据分析中最基础的工具。可以对大数组的数据进行高效处理。NumPy是在一个连续的内存块中存储数据,独立于其他Python内置对象,如此便可以加速数据索引的速度。其次,NumPy调用了大量的用C语言编写的算法库,使得其可以直接操作内存,不必进行Python动态语言特性所含有的前期类型检查工作,从而大大提高了运算速度。最后,NumPy所有独有的可以在整个数组上执行复杂的计算也能够大幅提高运算效率(基于NumPy的算法要比纯Python快10到100倍,甚至会快更多)。利用numpy,可以轻松地使用python达到matlab中的矩阵、线性代数等等运算。
(2) numpy中常用的分析方法及举例
① 生成数组
用 Numpy 创建数组有多种方法。首先,Numpy 中的 array方法可以直接将 Python 的 list 类型转化为Numpy 的数组类型 ndarray。
(a)创建一个一维数组:
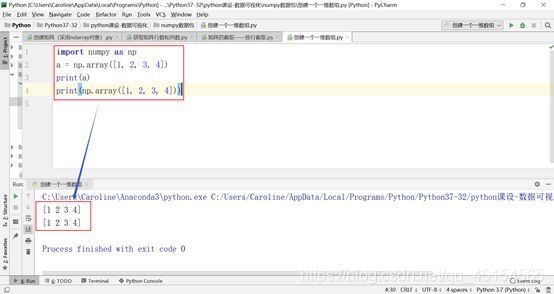
(b)创建一个二维数组:
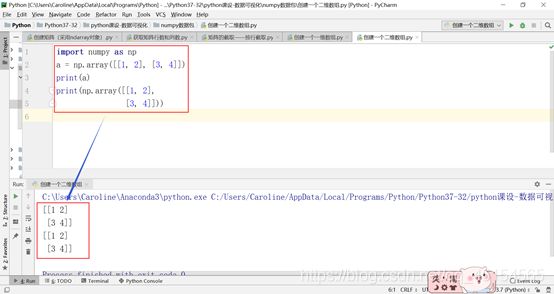
注意,array方法中小括号中要包括一个中括号数组,而不能直接写成 np.array(1, 2, 3, 4)。
(c)Numpy中的zeros方法可以创建元素值全为 0的矩阵, ones方法可以创建元素值全为 1 的矩阵,而 empty方法可以创建一个元素值任意的一个空矩阵。

输出结果:

(d)Numpy 中的 arange函数可以生成一个等差数列的数组

输出结果:

(e)另外一个类似的函数为 linespace,不同的地方在于:arange 函数中第三个参数表示等差数组的步长,而 linespace 函数第三个参数表示一共生成的元素个数。若生成一系列等差的浮点数,则用 linespace 更好些。
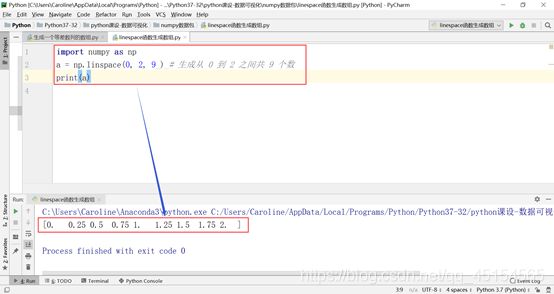
② 数组索引与切片
(a)对于一维数组,Numpy 的索引切片类似 Python list 类型的索引切片

输出结果:

(b)对于多维数组,Numpy数组的索引和切片用逗号分隔不同维度

输出结果:

③ 数组运算
Numpy 可以对数组进行加减,幂运算,判断大小等
(a) 一维数组的运算

输出结果:

(b) Numpy 也支持二维数组的一些运算,包括矩阵的转置,逆矩阵,矩阵的乘积等

输出结果:

④ 随机抽样(numpy.random模块)
(a) np.random.rand() --> 生成指定维度的的[0,1)范围之间的随机数,输入参数为维度
具体实例:

Shape为[4,3,2]的意思就是生成四个三行两列的[0,1]之间随机数组
输出结果:

(b) np.random.randn() --> 生成指定维度的服从标准正态分布的随机数,输入参数为维度
具体实例:

上述代码中的(2,4)也表示两行四列。
(c) np.random.randint(low, high = None, size = None,dtype = ‘l’)–> 返回随机数或者随机数组成的array
参数:
low,high(范围区间为[low,high)),low不可以>=high
size,
dtype(默认为int)
具体实例:

(d) np.random.random(size = (2,2))–>生成随机浮点数阵列
具体实例:
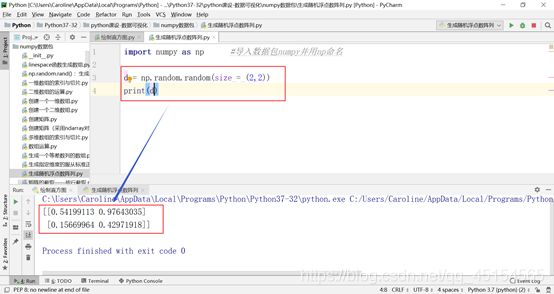
Size = (2,2)ó两行两列
(e) np.random.choice(a, size = None, replace = True, p = None) --> 从给定数组a中随机选择,p可以指定a中每个元素被选择的概率
具体实例:
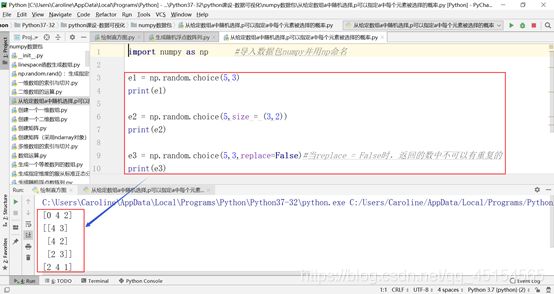
(f) np.random.seed() -->使随即数据可预测,对于同一个seed,生成的随机数相同
具体实例:

得到的结果:

2、pandas
(1)功能:
pandas 这个名称来源于panel data(面板数据),从而可见其要处理的数据是多维度的而非单维度。pandas
含有使数据清洗和分析工作变得更快更简单的数据结构与操作工具。pandas功能特性广泛,其包含的函数类型也众多,数据结构有Series与DataFrame,函数类型有索引函数、汇总函数、加载以及保存众多文件格式函数、与数据库交互函数、字符串处理函数、缺失数据处理函数、合并重塑轴向旋转表格型数据函数、简单的绘图函数、数据聚合(groupby)分组运算(apply)函数、透视表交叉表函数以及时间序列处理方面的各种函数。pandas可以读取较多类型的文件格式,从简单的txt、csv、json到excel,hdf5、pickle再到sas、sql、stata等等文件格式都有得以支持。在读取数据时,函数会使用到若干技术将数据转换成DataFrame格式,如索引、类型推断和数据转换、日期解析、迭代与不规整数据问题等。
(2)pandas的数据结构分为两种:
①Series -序列:储存任意类型的一维数组
②DataFrame -数据框:储存不同类型数据的二维数组
(3)pandas中常用的分析方法及举例:
① Pandas 文件读写

② 生成数据表
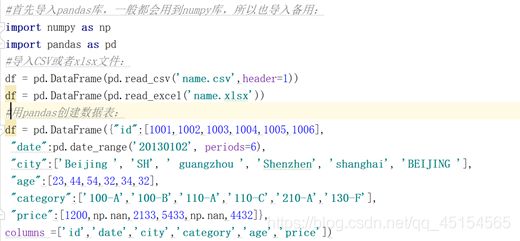
③ 数据表信息查看


④ 数据表清洗


⑤ 数据预处理



⑥ 数据输出
分析后的数据可以输出为xlsx格式和csv格式

3、statistics包
(1)功能:
我们在统计分析和建模的过程中,大致可以分为数据获取和处理、数据分析和建模及预测、结果可视化这三个步骤。statsmodels是统计建模分析的核心工具包,其包括了几乎所有常见的各种回归模型、非参数模型和估计、时间序列分析和建模以及空间面板模型等,其功能是很强大的,使用也相当便捷。
(2)statistics中常用的分析方法即举例:
①mean(data)函数
mean(data) 函数用于计算一组数字的平均值,参数 data 可以是多种形式的,比如 int 型数组或 decimal 型数组等。
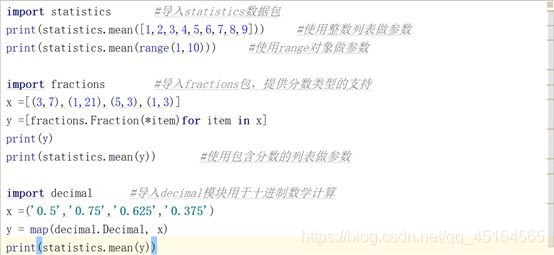
输出结果:

②harmonic_mean(data)函数
调和平均数又称倒数平均数,是平均数的一种。 harmonic_mean(data) 函数用于求调和平均数,是总体各统计变量倒数的算术平均数的倒数。
![]()
输出结果:
![]()
③中位数函数median()、median_low()、median_high()、median_grouped()

输出结果:

⑤ pstdev()函数
pstdev()函数返回总体标准差。

输出结果:
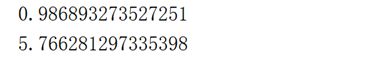
⑥ pvariance()函数
pvariance()函数返回总体方差或二次矩。

输出结果:

⑦ mode()函数
mode()函数返回最常见数据或出现次数最多的数据。
(a)无法确定出现次数最多的唯一元素

(b)可以确定出现次数最多的唯一元素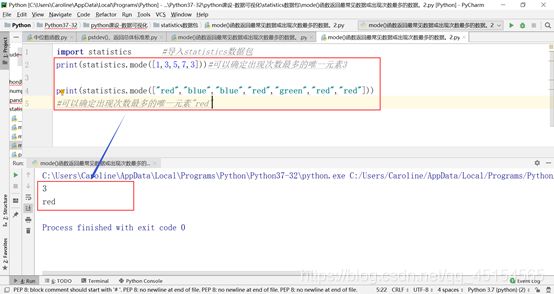
三、可视化工具matplotlib
1、功能
Python中的matplotlib可以快速绘图,并形成文件。matplotlib是基于Python语言的开源项目,旨在为Python提供一个数据绘图包。使用matplotlib能够非常简单的可视化数据,在matplotlib中使用最多的模块就是pyplot。matplotlib的pyplot子库提供了和matlab类似的绘图API,方便用户快速绘制2D图表。可以实现:创建图表、绘图区域、画线、添加图示标签等。
2、具体画图操作举例
(1)绘制直线图
plt.plot() 函数可以用来绘制线型图
基本用法:
plt.plot(x,y) ó指定x和y;
plt.plot(y)ó 没有给定 x 的值,默认参数x的取值为 0~N-1
具体实例:

画出的图形:
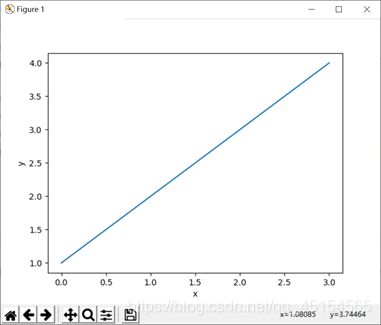
因为在此处就没有给出x的取值,只给出了y的取值为[1,2,3,4],所以x的默认取值为[0,1,2,3],就画出了如上图所示的线型图
(2)绘制折线图
![]()
画出的图形:
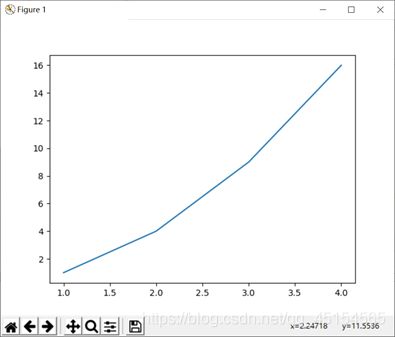
在此处就给出了x的取值为[1,2,3,4],y的取值为[1,4,9,16], 就画出了如上图所示的线型图
PS:字符参数:
和 MATLAB 中类似,可以用字符来指定绘图的格式。
表示颜色的字符参数有:
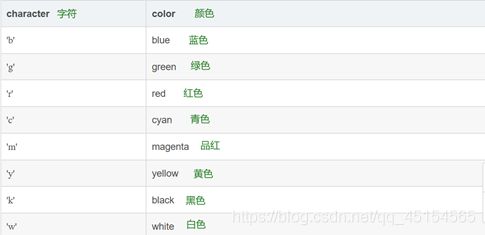
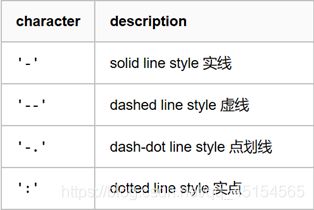
表示线条类型的字符参数有:

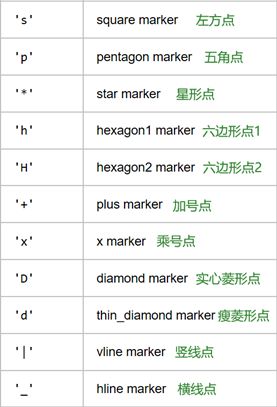
表示标记类型的字符参数有:

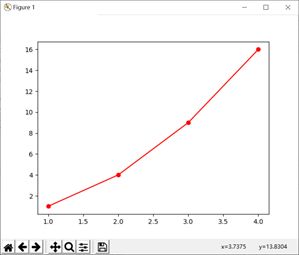
具体实例:
(a) 画出红色圆点连成的折线图

其中字符“r”表示用“红色”,字符“o”表示用圆点,字符“-”表示用实线连接各点
画出的图形:
规定显示范围:
与 MATLAB 类似,可以使用 axis()函数指定坐标轴显示的范围:
函数形式:plt.axis([xmin, xmax, ymin, ymax])
比如有时希望图中的各个数据点不在图像的边缘,希望它们尽量均匀分布时会有道这个指定坐标轴范围的函数axis()。
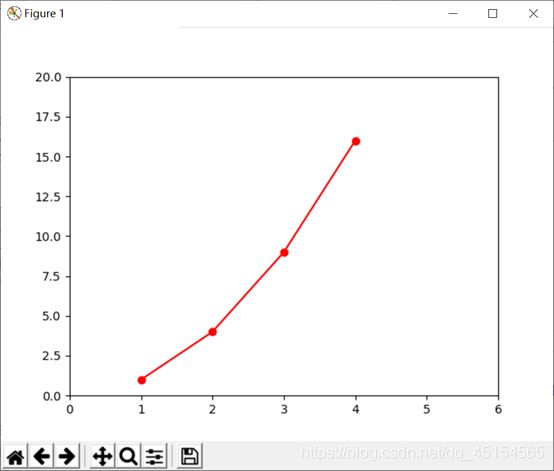
具体实例:

上述程序就是将x轴的坐标设置为06,y轴的坐标设置为020;就画出了下面的图像。
输出的图像:
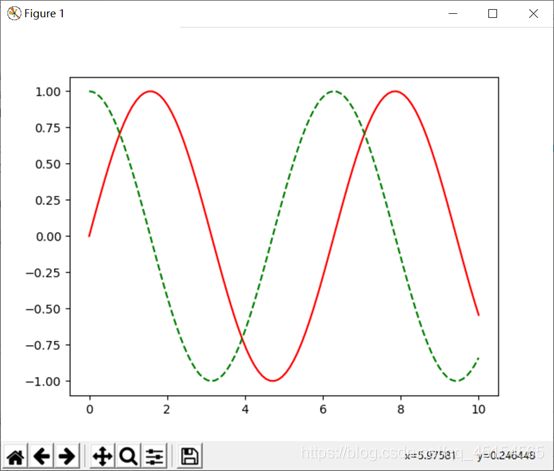
(3)绘制曲线图
具体实例:
绘制sin和cos函数

(4)生成子图
一个"Figure"意味着用户交互的整个窗口。在这个figure中容纳着"subplots"。
(a)figure() 函数会产生一个指定编号为 num 的图:
使用格式:plt.figure(num,figsize,…)
参数:
num:这个参数是一个可选参数,即可以给参数也可以不给参数。可以将该num理解为窗口的属性id,即该窗口的身份标识。如果不提供该参数,则创建窗口的时候该参数会自增,如果提供的话则该窗口会以该num为Id存在。
figsize:可选参数。整数元组,默认是无。提供整数元组则会以该元组为长宽,若不提供,默认为 rc fiuguer.figsize。例如(4,4)即以长4英寸 宽4英寸的大小创建一个窗口
这里,figure(1) 其实是可以省略的,因为默认情况下 plt 会自动产生一幅图像。
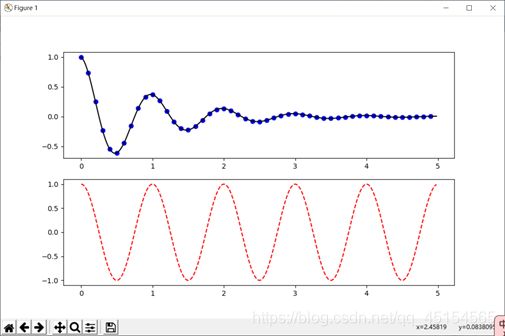
(b)使用 subplot()函数可以在一副图中生成多个子图:
用subplot来产生子图,子图都是在一个figure里面
matlab中subplot()的作用,就是在同一画面中创建和控制多个图形位置。
使用格式:plt.subplot(numrows, numcols, fignum)
第一个参数代表子图的行数;第二个参数代表该行图像的列数;
第三个参数代表每行的第几个图像。
当 numrows * numcols < 10 时,中间的逗号可以省略,如:plt.subplot(211)
就相当于 plt.subplot(2,1,1)
具体演示:
(a)


上图所示的代码就是figure() 函数和subplot()函数具体实现的例子
画出的图形为:
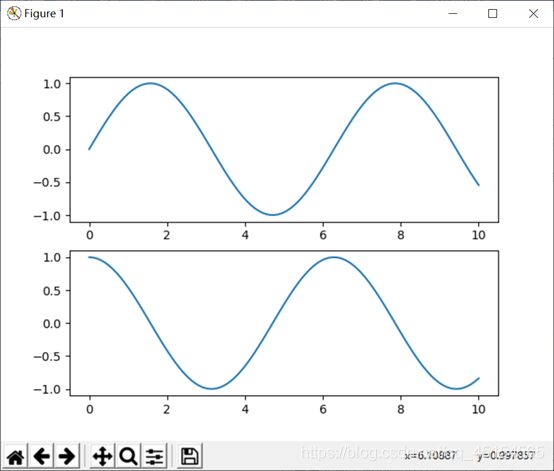
(b)

画出的图形:
(5)保存图表:
用savefig来保存图表,plt.figure产生一张图的实例。
后面再在图上绘制。但是有一点要注意,先show再保存是会报错的。
实例演示:

画出与保存的图像:

(6)绘制柱状图
柱状图(bar chart),是一种以长方形的长度为变量的表达图形的统计报告图,由一系列高度不等的纵向条纹表示数据分布的情况,用来比较两个或以上的价值(不同时间或者不同条件),只有一个变量,通常利用于较小的数据集分析。柱状图亦可横向排列,或用多维方式表达。
用函数bar()
条形图与直方图的区别:
首先,条形图(柱状图)是用条形的长度表示各类别频数的多少,其宽度(表示类别)则是固定的;直方图是用面积表示各组频数的多少,矩形的高度表示每一组的频数或频率,宽度则表示各组的组距,因此其高度与宽度均有意义。
其次,由于分组数据具有连续性,直方图的各矩形通常是连续排列,而条形图则是分开排列。
最后,条形图主要用于展示分类数据,而直方图则主要用于展示数据型数据
具体实例:
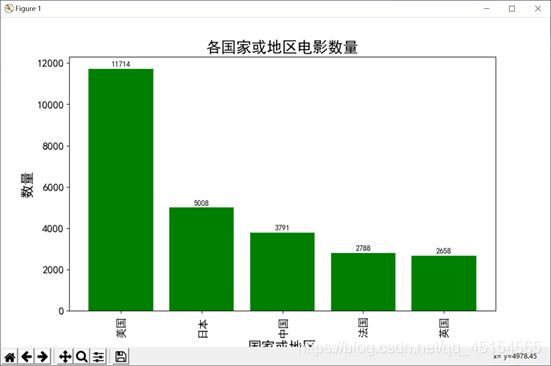
(a)基本普通柱状图
绘制每个国家或地区的电影数量的柱状图:


画出的图形:
(b)多个系列y值的柱状图
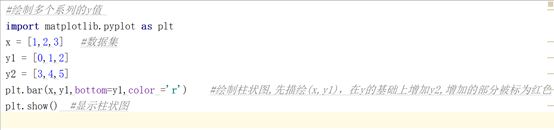
得到的柱状图:

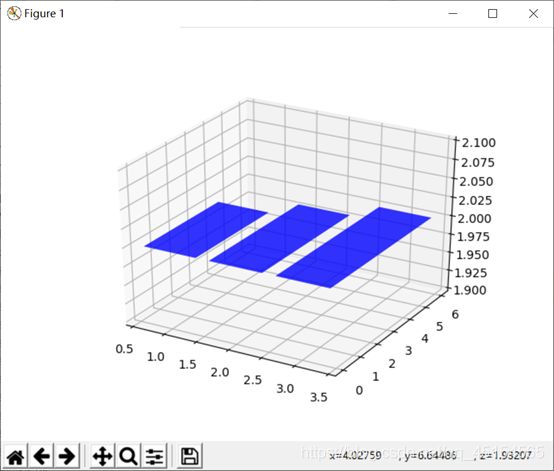
(b) z值只有一个的三维柱状图

画出的三维柱状图:
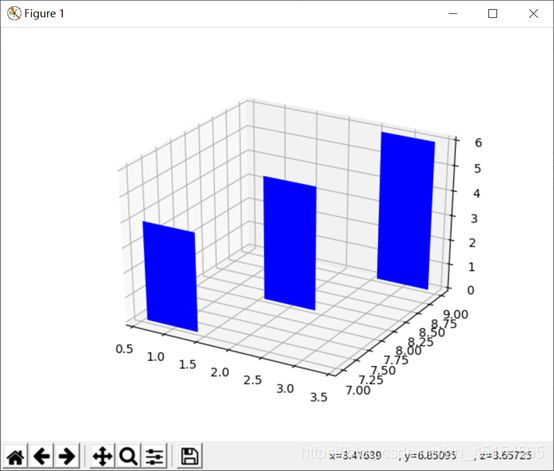
(c) 立体3D柱状图

画出的三维立体柱状图:
(7)点图
具体实例:
画出蓝色星型图
![]()
其中字符“b”表示用“蓝色”,字符“*”表示用星形点,没有用于连接的表示线的参数,故图形是孤立的四个点
画出的图形:

(a)普通的点图的绘制也是通过plot函数,只需要将‘-’改成‘.’即可
实例演示:

画出的图形:
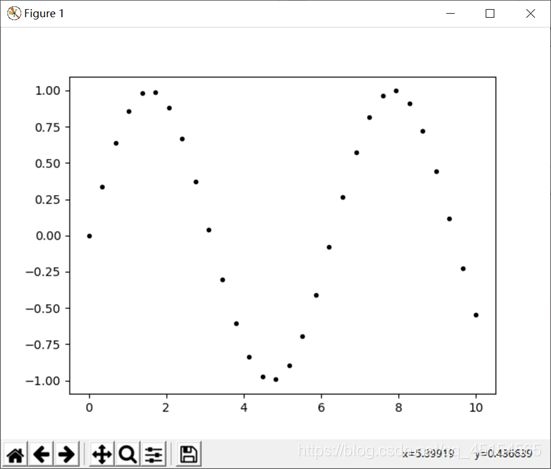
传入numpy参数
前面所演示的代码传给 plot()函数的参数都是列表,但事实上,向plot()函数中传入 numpy 数组是更常用的做法。
事实上,如果传入的是列表,matplotlib 会在内部将它转化成数组再进行处理。
具体实例:

使用上图中所示的代码显示出三条不同的线
np.arange()方法的具体用法可以参照二 -> ① -> (d)
输出的图像:
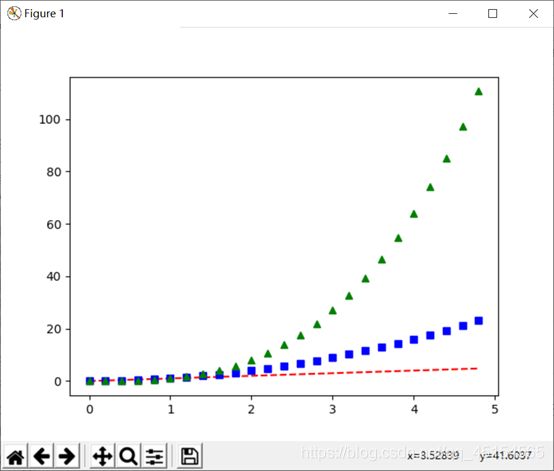
(8)绘制散点图
用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式。
散点图将序列显示为一组点。值由点在图表中的位置表示。类别由图表中的不同标记表示。散点图通常用于比较跨类别的聚合数据。
用函数scatter()
参数:
x:指定 X 轴数据。
y:指定 Y 轴数据。
s:指定散点的大小。
c:指定散点的颜色。
alpha:指定散点的透明度。
linewidths:指定散点边框线的宽度。
edgecolors:指定散点边框的颜色。
marker:指定散点的图形样式。应参数支持’.’(点标记)、’,’(像素标记)、‘o’(圆形标记)、‘v’(向下三角形标记)、’^’(向上三角形标记)、’<’(向左三角形标记)、’>’(向右三角形标记)、‘1’(向下三叉标记)、‘2’(向上三叉标记)、‘3’(向左三叉标记)、‘4’(向右三叉标记)、‘s’(正方形标记)、‘p’(五地形标记)、’*’(星形标记)、‘h’(八边形标记)、‘H’(另一种八边形标记)、’+’(加号标记)、‘x’(x标记)、‘D’(菱形标记)、‘d’(尖菱形标记)、’|’(竖线标记)、’_’(横线标记)等值。
点的样式和形状大小都是可以改变的,可以通过参数来控制。
matplotlib用scatter函数绘制散点图,散点图用的比较多,它允许我们绘制不规则的多个点,参数color和size控制颜色和大小
实例演示:
画出的散点图:

(c)



画出的散点图:
(9)绘制饼图
饼图英文学名为Sector Graph, 有名Pie Graph。常用于统计学模块。2D饼图为圆形。仅排列在工作表的一列或一行中的数据可以绘制到饼图中。饼图显示一个数据系列中各项的大小与各项总和的比例,数据点显示为整个饼图的百分比。
函数原型:
pie(x,
explode=None, labels=None, colors=None, autopct=None,
pctdistance=0.6,shadow=False, labeldistance=1.1, startangle=None, radius=None)
参数:
X: (每一块)的比例,如果sum(x) > 1会使用sum(x)归一化
explode :(每一块)离开中心距离
labels :(每一块)饼图外侧显示的说明文字
colors:(每一块)的颜色
autopct: 控制饼图内百分比设置,可以使用format字符串或者format function
pctdistance: 类似于labeldistance,指定autopct的位置刻度
shadow:表示是否阴影
labeldistance:label绘制位置,相对于半径的比例, 如<1则绘制在饼图内侧
startangle 起始绘制角度,默认图是从x轴正方向逆时针画起,如设定=90则从y轴正方向画起
radius:控制饼图半径
返回值:
如果没有设置autopct,返回(patches, texts),如果设置autopct,返回(patches, texts, autotexts)
实例演示:
(a)
画出的饼图:
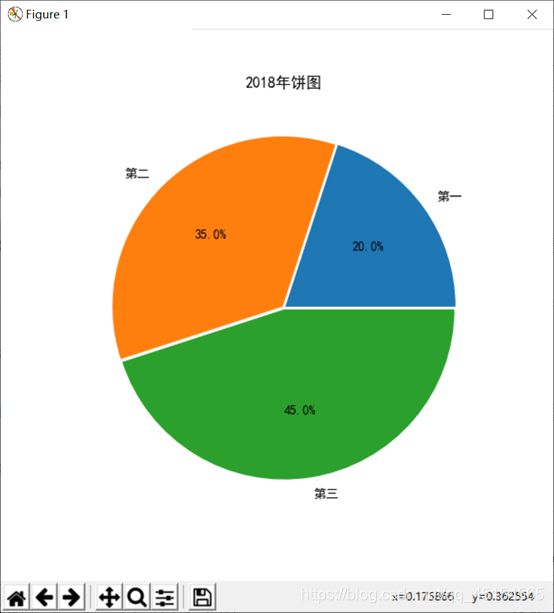
(b)
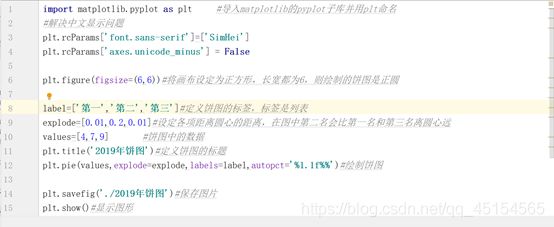
画出的饼图为:

(11)绘制直方图
直方图(Histogram)又称质量分布图。是一种统计报告图,由一系列高度不等的纵向条纹或线段表示数据分布的情况。一般用横轴表示数据类型,纵轴表示分布情况。
直方图是数值数据分布的精确图形表示。这是一个连续变量(定量变量)的概率分布的估计,并且被卡尔·皮尔逊(Karl Pearson)首先引入。它是一种条形图。
为了构建直方图,第一步是将值的范围分段,即将整个值的范围分成一系列间隔,然后计算每个间隔中有多少值。这些值通常被指定为连续的,不重叠的变量间隔。间隔必须相邻,并且通常是(但不是必须的)相等的大小。直方图也可以被归一化以显示“相对”频率。然后,它显示了属于几个类别中的每个案例的比例,其高度等于1。
使用hist函数函数画图;
调用方式:n, bins, patches = plt.hist(arr, bins=50,
normed=1, facecolor=‘green’, alpha=0.75)
参数:hist的参数非常多,但常用的就这五个,只有第一个是必须的,后面四个可选
arr: 需要计算直方图的一维数组
bins: 直方图的柱数,可选项,默认为10
normed: 是否将得到的直方图向量归一化。默认为0
facecolor: 直方图颜色
alpha: 透明度
返回值 :
n: 直方图向量,是否归一化由参数设定
bins: 返回各个bin的区间范围
patches: 返回每个bin里面包含的数据,是一个list
具体实例:
(a)最最基本不同的直方图

np.random.randn()函数的具体使用方法参照一、-> (2) -> ④ -> (b)
画出的直方图:

(b)调节具体参数

画出的直方图:
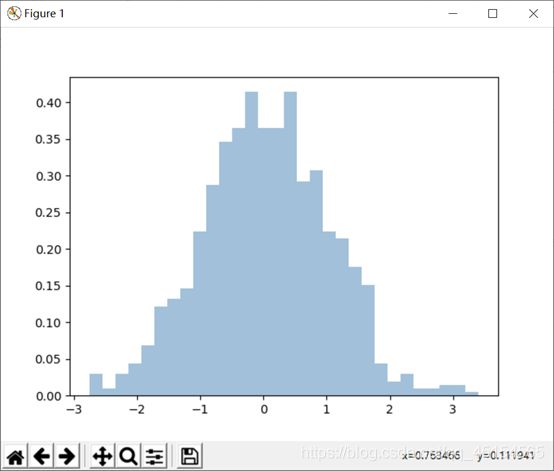
(d) 对多组数据画直方图

画出的图形:

(12)等高线图
等高线图经常用来表示一个二元函数z=f(x,y),我们可以形象的用一张网格图上面的点的函数值来描述。
实例演示:
(a)

可以看到x为长50的向量,y为长40的向量,经过np.meshgrid处理后,形成X,Y大小都为(40,50)的二维数组,这样每一个网格点上都有一组(x,y)来赋值。
画出的等高线图:
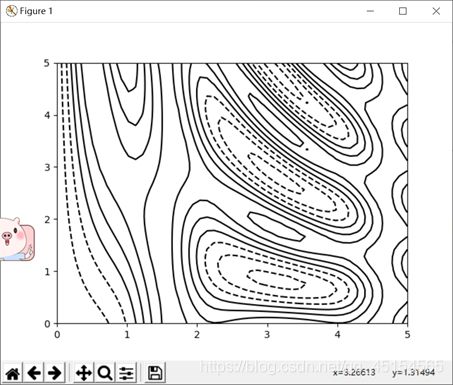
得到的图需要注意:使用单一颜色时,负值由虚线表示,正值由实线表示。
(b)还可以控制线的密度和颜色的显示

画出的图形:

三、总结
1、对三个数据包的总结
在经过此次的课程设计后,对numpy、pandas、statistics三个 python中常用的数据包有了一定的了解,其中的基本常用方法也几乎都练过手,收获颇多,下面是我在使用后对这三个数据包自即的概括:
(1)numpy数据包:
Python中是没有提供数组功能的,虽然在我已学的知识中列表也可以完成基本的数组功能,但它其实并不是真正的数组,而且数据量较大时,使用列表的速度就会非常慢慢。所以在我经过此次课程设计后,才发现Numpy提供了真正的数组功能,以及很多快速处理的函数。Numpy内置函数处理数据的速度事非常非常快的,因此在编写程序的时候,应当尽量使用内置函数,这样更是可以大大提高效率。
(2)Pandas数据包:
Pandas是Python下最强大的数据分析和探索工具。这句话我在这次的课程设计中深有感触,有很多高级的数据结构和精巧的工具,使得在Python中处理数据非常快速和简单。 Pandas功能非常强大,支持增删改查,并且带有丰富的数据处理函数;支持时间序列分析功能;支持灵活处理缺失数据等。但也是这些优点使得它有太多的太多的知识需要掌握,所以我觉得这也是我以后需要慢慢积累和训练的。
(3)statistics数据包:
statistics模块主要是提供了用于计算数字数据的数理统计量的函数。像一组数的平均值、中位数、众数、最大值、标准差、方差等用于统计的数据量,将繁琐的工作简单化。
2、对可视化工具matplotlib的总结
Matplotlib是一个Python2D绘图库和一些基本的3D图表,可以生成各种格式图片。在任何绘图之前,需要一个Figure对象,可以理解成需要一张画板才能开始绘图。在Matplotlib中,整个图像为一个Figure 对象。Figure对象中可以包含一个或者多个Axes对象,每个Axes 对象都是一个拥有自己坐标系统的绘图区域。在拥有Figure对象之后,在作画前还需要轴,没有轴的话就没有绘图基准,所以需要添加Axes。也可以理解成为真正可以作画的纸。Matplotlib下, 一个 Figure 对象可以包含多个子图(Axes),可以使用 subplot() 快速绘制。