一、基本信息
论文题目:《DeepWalk: Online Learning of Social Representations》
发表时间: KDD 2014
论文作者: Bryan Perozzi、Rami Al-Rfou、Steven Skiena
论文地址: https://dl.acm.org/citation.cfm?id=2623732
二、前言
本文通过将已经成熟的自然语言处理模型word2vec应用到网络的表示上,做到了无需进行矩阵分解即可表示出网络中的节点的关系。
DeepWalk把对图中节点进行的一串随机游走类比于 word2vec 中对单词的上下文,作为 word2vec 算法的输入,进而把节点表示成向量。输出的结果能够被多种分类算法作为输入应用。
三、介绍
Deepwalk:将一个网络中的每个节点映射成一个低维的向量。说白了就是用一个向量去表示网络中的每个节点,并且希望这些向量能够将网络中的节点中的关系表达出来,即希望在原始网络中关系越紧密的结点对应的向量在其空间中距离越近。

输入的是一个网络,其中颜色相同的结点表示拓扑关系上更为相近的结点。输出的是每个节点的二维向量,每个节点对应的向量关系如图所示。我们可以从这个图看出,越是拓扑结构相近的点,其对应的二维向量在二维空间上距离与近。
我认为最主要的好处,就是便于将一些机器学习的算法应用到网络中。网络数据不同于传统的数据,它不仅包含了节点的信息,还包含了节点间的关系,对于传统的机器学习算法,很难将其应用于网络中。例如网络中的社团发现算法,大多数情况下我们都针对网络做大量的游走,不断改变网络的社团结构,以使网络获得最优的模块度,但是如果我们能将拓扑信息嵌入到低维向量中,那么每个节点我们都可以看做是一个样本,每个维度都可以看做一个 feature,那么只需要跑个聚类算法,就可以得到很好的结果。除了聚类,还有链路预测、推荐等一系列网络中的问题,都可以直接扔到机器学习的相关算法中跑出来。
四、Problem definition
$X \in \mathbb{R}^{|V| \times S} \quad S \ is\ the\ size\ of\ feature\ space $
$E \subseteq(V \times V)$
$Y \in \mathbb{R}^{|V| \times|\mathcal{Y}|} \quad \mathcal{Y} \ is\ the\ size\ of\ labels\ set $
输入
输出:对于一般的机器学习问题,需要学习一个从 $X$ 映射到 $Y$ 的 hypothesis。而本文的任务就是学习得到$X$ 的低维表示。
Goal:Our goal is to learn $X_{E} \in \mathbb{R}^{|V| \times d}$ , where d is small number of latent dimensions. These low-dimensional representations are distributed; meaning each social phenomena is expressed by a subset of the dimensions and each dimension contributes to a subset of the social concepts expressed by the space.
有意思的思考:
原文:We propose a different approach to capture the network topology information. Instead of mixing the label space as part of the feature space,we propose an unsupervised method which learns features that capture the graph structure independent of the labels’ distribution.This separation between the structural representation and the labeling task avoids cascading errors, which can occur in iterative methods.
五、Learning social representations
文中提到,在学习一个网络表示的时候需要注意的几个性质:
-
- Adaptability:网络表示必须能适应网络的变化。网络是一个动态的图,不断地会有新的节点和边添加进来,网络表示需要适应网络的正常演化。
- Community aware:属于同一个社区的节点有着类似的表示。网络中往往会出现一些特征相似的点构成的团状结构,这些节点表示成向量后必须相似。
- Low dimensional:代表每个顶点的向量维数不能过高,过高会有过拟合的风险,对网络中有缺失数据的情况处理能力较差。
- Continuous:低维的向量应该是连续的。
提到网络嵌入,可能会让人联想到NLP中的word2vec,也就是词嵌入(word embedding)。前者是将网络中的节点用向量表示,后者是将单词用向量表示。因为大多数机器学习的方法的输入往往都是一个向量,算法也都基于对向量的处理,从而将不能直接处理的东西转化成向量表示,这样就能利用机器学习的方法对其分析,这是一种很自然的思想。
本文处理网络节点的表示(node representation)就是利用了词嵌入(词向量)的的思想。词嵌入的基本处理元素是单词,对应网络网络节点的表示的处理元素是网络节点;词嵌入是对构成一个句子中单词序列进行分析,那么网络节点的表示中节点构成的序列就是随机游走。
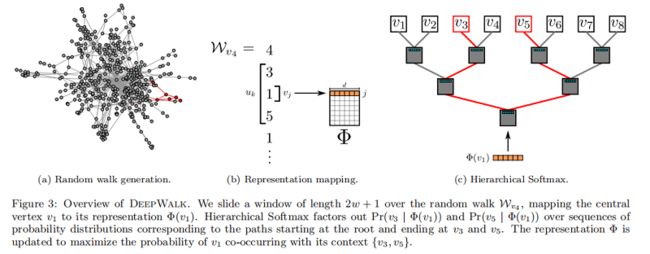
六、Random Walks
所谓随机游走(random walk),就是在网络上不断重复地随机选择游走路径,最终形成一条贯穿网络的路径。从某个特定的端点开始,游走的每一步都从与当前节点相连的边中随机选择一条,沿着选定的边移动到下一个顶点,不断重复这个过程。
关于随机斿走的符号解释: 以 $v_{i}$ 为根节点生成的一条随机游走路径 (绿色) 为 $W_{v_{i}} $ ,其中路径上的点 (蓝色) 分别标记为 $W_{v_{i}}^{1}, W_{v_{i}}^{2}, W_{v_{i}}^{3} \ldots$ , 截断䐈机游走(truncated random walk)实 际上就是长度固定的随机游走。
使用随机游走有两个好处:
- 并行化,随机游走是局部的,对于一个大的网络来说,可以同时在不同的顶点开始进行一定长度的随机游走,多个随机游走同时进行,可以减少采样的时间。
- 适应性,可以适应网络局部的变化。网络的演化通常是局部的点和边的变化,这样的变化只会对部分随机游走路径产生影响,因此在网络的演化过程中不需要每一次都重新计算整个网络的随机游走。
七、Connection: Power laws
文中提到网络中随机游走的分布规律与NLP中句子序列在语料库中出现的规律有着类似的幂律分布特征。那么既然网络的特性与自然语言处理中的特性十分类似,那么就可以将NLP中词向量的模型用在网络表示中,这正是本文所做的工作。

八、语言模型
首先来看词向量模型:
$w_{i}^{u}=\left(w_{0}, w_{1}, w_{2}, \ldots, w_{n}\right)$ 是一个由若干单词组成的序列,其中 $w_{i} \in V( Vocabulary )$,$V$ 是词汇表,也就是所有单词组成的集合。
在整个训练集上需要优化的目标是:
$\operatorname{Pr}\left(w_{n} \mid w_{0}, w_{1}, \ldots, w_{n}-1\right)$
也就是给定 $w_0,w_1,.......,w_{i-1}$ 要求出下一个 $w_{i}$ 出现的概率
将语言模型中的单词映射到图表示上去,单词即对应了图中的节点 $v_i$ ,句子序列对应了网络中的随机游走,那么对于一个随机游走$v_0,v_1,v_2,.......,v_{i-1}$需要优化的目标是:
$\operatorname{Pr}\left(v_{i} \mid\left(v_{0}, v_{1}, \ldots, v_{i-1}\right)\right)$
按照上面的理解就是,当知道 $\left(v_{0}, v_{1}, \ldots, v_{i-1}\right)$ 游走路径后,游走的下一个节点是 $v_{i}$ 的概率是多少? 可是这里的 $v_{i}$ 是顶点本身没法计算,于是引入一个映射函数$\Phi$,它的功能是将顶点映射成向量,转化成向量后就可以对顶点 $v_{i}$ 进行计算了。
$\Phi: v \in V \mapsto \mathbb{R}^{|V| \times d}$
但是怎么计算这个概率呢?同样借用词向量中使用的skip-gram模型
skip-gram模型有这样3个特点:
- 不使用上下文 (context) 预测缺失词 (missing word),而使用缺失词预测上下文。因为 $\left(\left(v_{0}\right),\left(v_{1}\right), \ldots,\left(v_{i}-1\right)\right)$ 这部分太难算了,但是如果只计算一个 $\left(v_{k}\right)$ , 其中 $v_{k}$ 是缺 失词,这就很好算。 和右边 2 个窗口内的节点。
- 不考虑顺序,只要是窗口中出现的词都算进来,而不管它具体出现在窗口的哪个位置。
应用skip-gram模型后,优化目标变成了这样:
$\underset{\Phi}{\operatorname{minimize}} \quad-\log \operatorname{Pr}\left(\left\{v_{i-w}, \cdots, v_{i-1}, v_{i+1}, \cdots, v_{i+w}\right\} \mid \Phi\left(v_{i}\right)\right)$
九、Algorithm: DeepWalk
整个 DeepWalk 算法包含两部分,一部分是随机游走的生成,另一部分是参数的更新。
算法:

第 3 行代表整个过程迭代次,每次为每个节点采样一个随机游走。第 4 行代表对节点进行随机排列,这不是必须的,但是可以加速随机梯度下降的收敛。对于每个随机游走,使用第7行的 SkipGram 进行参数的更新。
十、SkipGram
SkipGram是一种语言模型,它最大化句子中大小的窗口内出现的词的共现概率。算法2 展示了SkipGram在DeepWalk中的应用:
算法2 迭代出现在窗口 $w$(第1-2行)内的随机游走中的所有可能的组合。对于每个顶点,我们将每个顶点 $v_j$ 映射到它当前的表示向量$\Phi\left(v_{j}\right) \in \mathbb{R}^{d}$ (见图3b)。给定 $v_j$ 的表示,我们希望最大限度地提高其邻居在行走中的概率(第3行)。我们可以使用不同的分类器来学习这种后验分布。例如,使用逻辑回归建模前面的问题将导致大量的标签(约 $|V|$ ),可能是数百万或数十亿美元。这样的模型需要大量的计算资源,可以跨越整个计算机集群。为了加快训练时间,可以使用 Hierarchical Softmax 最大来近似概率分布。
十一、Hierarchical Softmax
考虑到 $u_{k} \in V$,在第3行中计算 $\operatorname{Pr}\left(u_{k} \mid \Phi\left(v_{j}\right)\right)$ 是不可行的。计算配分函数(归一化因子)成本昂贵。如果我们将 顶点 分配给二进制树的叶子,预测问题就会变成树中特定路径的概率最大化(见 Figure 3c)。如果到顶点 $u_k$ 的路径是由一系列树节点识别的$\left(b_{0}, b_{1}, \ldots, b_{\lceil\log |V|\rceil}\right)$,$(b_0=root,b_{\lceil\log |V|\rceil}=u_{k})$,那么
$\operatorname{Pr}\left(u_{k} \mid \Phi\left(v_{j}\right)\right)=\prod \limits _{l=1}^{\lceil\log |V|\rceil} \operatorname{Pr}\left(b_{l} \mid \Phi\left(v_{j}\right)\right)$
现在,$\operatorname{Pr}\left(b_{l} \mid \Phi\left(v_{j}\right)\right)$ 可以通过分配给节点 $b_l$ 的父节点的二进制分类器来建模。这降低了计算 $\operatorname{Pr}\left(u_{k} \mid \Phi\left(v_{j}\right)\right)$ 的计算复杂度,从 $O(|V|)$ 降低到 $O(log|V|)$ 。我们可以通过为随机行走中的频繁顶点分配更短的路径来进一步加快训练过程。霍夫曼编码用于减少树中频繁元素的访问时间。
十二、Parallelizability
如图2所示,社交网络随机游动中的顶点和一种语言中的单词的频率分布都遵循幂律。这导致了罕见顶点的长尾,因此,影响Φ的更新本质上是稀疏的。这允许我们在多工作人员的情况下使用异步版本的随机梯度下降(ASGD)的方法。鉴于我们的更新是稀疏的,并且我们没有获得一个锁来访问模型共享参数,ASGD将实现一个最佳的收敛速度[36]。虽然我们在一台机器上使用多个线程运行实验,但已经证明了这种技术具有高度的可伸缩性,并且可以用于非常大规模的机器学习[8]。图4显示了并行化“深度行走”的效果。它显示了随着工作目录的数量增加到8人,博客目录和Flickr网络的处理速度是一致的(图4a)。它还表明,相对于连续运行的DeepWalk,预测性能没有损失(图4b)

上图显示了并行对DeepWalk的影响。图(a)当多个任务同时进行时,算法的速度变快。图(b)表明,并行运行下,DeepWalk的性能没有受到影响。
十三、实验效果展示
数据集
-
- $BlogCatalog$ 是博客作者的社交关系网络。标签代表作者提供的主题类别。
- $Flickr$ 是照片分享网站用户之间的联系网络。标签代表用户的兴趣组,如“黑白照片”。
- $YouTube$ 是流行的视频分享网站用户之间的社交网络。 这里的标签代表喜欢不同类型视频(例如动漫和摔跤)的观众群体。

-
- SpectralClustering:该方法从图 $G$ 的标准化拉普拉斯矩阵 $\widetilde{\mathcal{L}}$ 选择 d-smallest 个特征向量生成 $\mathbb{R}^d $ 的表示。利用$\widetilde{\mathcal{L}}$ 的特征向量隐式地假设图剪切将对分类有用。
- Modularity:该方法从 $G$ 的 Modularity matrix B的 top-d 特征向量生成 $\mathbb{R}^d $ 的表示。B 的特征向量编码了 $G$ 的模图分区信息。使用它们作为特征可以假设模块化图分区对分类很有用。
- EdgeCluster:该方法使用 k-means 聚类对 $G$ 的邻接矩阵进行聚类,它的性能与模块化方法具有比较性,且扩展图太大,无法进行谱分解。
- wvRN:加权投票关系邻居是一个关系分类器。给定顶点 $v_i$ 的邻域 $\mathcal{N}_{i}$,wvRN 用其邻域 ( 即 $\operatorname{Pr}\left(y_{i} \mid \mathcal{N}_{i}\right)=\frac{1}{Z} \sum \limits _{v_{j} \in \mathcal{N}_{i}} w_{i j} \operatorname{Pr}\left(y_{j} \mid \mathcal{N}_{j}\right)$ ) 估计 $\operatorname{Pr}\left(y_{i} \mid \mathcal{N}_{i}\right)$ 。它在真实网络中显示出惊人的良好性能,并被提倡作为一种合理的关系分类基线。
- Majority:这种 naive 方法简单地选择训练集中最频繁的标签。
十四、实验
为了便于我们的方法与相关基线之间的比较,我们使用了与[39,40]中完全相同的数据集和实验程序。具体来说,我们随机抽取标记节点的一部分( $T_R$ ),并将它们作为训练数据。其余的节点被用作测试。我们重复这个过程 10 次,并报告了 $Macro-F1$ 和 $Micro-F1$ 的平均性能。如果可能的话,我们在这里直接报告原始结果[39,40]。对于所有的模型,我们使用由 Lib Linear[10] 实现的 one-vs-rest 进行分类。我们给出了使用( $γ=80,w=10,d=128$ )行走的结果。(光谱聚类、模块化、边缘聚类)的结果使用了 Tang 和 Liu 的首选维数,$d=500$ 。
BlogCatalog
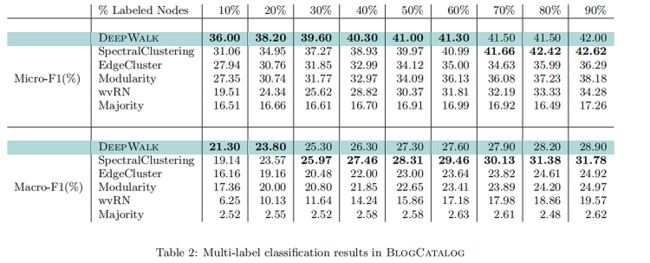
在本实验中,我们将 BlogCatalog 网络上的训练比率( $T_R$ )从 10% 提高到 90% 。我们的结果如 Table 2 所示。粗体中的数字表示每一列中的最高性能。DeepWalk的性能始终优于 EdgeCluster 、Modularity 和 wvRN。事实上,当只使用 20% 的节点进行训练时,DeepWalk 在获得 90% 的数据时比这些方法表现得更好。SpectralClustering 的性能被证明更具竞争力,但当在 $Macro-F_1$ ($ T_R≤20% $) 和 $Micro-F1$(T_R≤60% )上的标记数据稀疏时,DeepWalk的性能仍然优于后者。当图的一小部分被标记时,这种强大的性能是我们方法的核心优势。在接下来的实验中,我们研究了我们的表示在更稀疏标记的图上的性能。
Flickr
在本实验中,我们将 Flickr 网络上的训练比率( $T_R$ )从 $1%$ 变化到 $10%$。这相当于在整个网络中有大约 800 到 8000 个节点被标记出来进行分类。Table 3 显示了我们的结果,这与之前的实验结果一致。与Micro-F1相比,DeepWalk 的性能比所有基线高出至少 $3%$。此外,当只有 $3%$ 的图被标记时,它的 $Micro-F1$ 性能优于所有其他方法,即使它们得到了 $10%$ 的数据。换句话说,DeepWalk 可以比基线的训练数据少 60%。它在 $Macro-F_1$ 中也表现得很好,最初表现接近BlogCatalog,但距离自己提高了 1%。

YouTube
YouTube 网络比我们之前实验过的要大得多,它的大小阻止了我们的两种基线方法(SpectralClustering 和 Modularity )在它上运行。它比我们之前考虑过的更接近一个真实世界的图。训练比例( $T_R$ ) 从 1% 到 10% 的结果如 Table 4 所示。他们表明,DeepWalk 在创建图形表示方面显著优于可伸缩的基线,即边缘集群。当 1% 的标记节点用于测试时,$Micro-F1$ 提高了14%。$Macro-F1$ 显示出相应的 10% 的增长。随着训练数据的增加,这一领先优势逐渐缩小,但DeepWalk 以 $Micro-F1$ 领先 $3% $ 结束,$Macro-F1$ 提高了令人印象深刻的5%。这个实验展示了性能的好处:可以通过使用社会表征学习进行多标签分类而发生。深度行走,可以缩放到大型图形,并且在这样一个稀疏标记的环境中表现得非常好。

Parameter Sensitivity
为了评估 DeepWalk 参数化的变化如何影响其在分类任务上的性能,我们在两个多标签分类任务( Flickr 和 BlogCatalog )上进行了实验。在这个测试中,我们将窗口大小(Window size)和 行走长度(Walk Length) 固定为合理的值( $w=10,t=40$),这应该强调局部结构。然后,我们改变潜在维度(d)的数量、每个顶点开始行走的次数($γ$)和可用的训练数据量( $T_R$ ),以确定它们对网络分类性能的影响。
Effect of Dimensionality
Figure 5a显示了增加我们的模型可用的潜在维度数的影响。
Figure 5a1 和 Figure 5a3 检查了改变维数和训练率的影响。Flickr和博客目录之间的性能非常一致,并表明一个模型的最优维数取决于训练示例的数量。(请注意,1%的 Flickr 拥有的标记例子大约与10%的博客目录一样多)。
Figure 5a2 和 Figure 5a3 检查了改变每个顶点的维数和行走次数的影响。对于不同的 $\gamma $ 值,维度之间的相对性能相对稳定。这些图表有两个有趣的观察结果。首先,大部分好处是通过在两个图中每个节点启动 $\gamma =30$ 行走来实现的。第二,在这两个图中,不同的 $\gamma =30$ 值之间的相对差异是相当一致的。Flickr 比 BlogCatalog 多有一个数量级的边,我们发现这种行为很有趣。
十五、结论
我们提出了 DeepWalk,一种学习顶点潜在社会表征的新方法。利用截断随机游动的局部信息作为输入,我们的方法学习一种编码结构规律的表示。在各种不同的图上进行的实验说明了我们的方法在具有挑战性的多标签分类任务上的有效性。
作为一种 online algorithm,DeepWalk也是可扩展的。我们的结果表明,我们可以为太大的无法运行光谱方法的图创建有意义的表示。在如此大的图上,我们的方法显著优于其他设计来操作稀疏性的方法。我们还展示了我们的方法是可并行化的,允许工作人员同时更新模型的不同部分。
除了有效性和可扩展性外,我们的方法也是语言建模的一个有吸引力的泛化方法。这种联系是互惠互利的。语言建模的进步可能会继续为网络产生改进的潜在表示。在我们看来,语言建模实际上是从一个不可观察到的语言图中采样的。我们相信,从建模可观测图中获得的见解可能反过来会对建模不可观测图产生改进。
看完点个关注呗!!(总结不易)