Python自动化处理和分析Excel数据的基本方法
Python作为一门解释性编程语言应用越来越广泛。这篇文章主要介绍用python处理和分析excel数据的基本方法。到年底了,各公司都需要对今年的工作做一些总结,分析数据必不可少。Excel虽有很多技巧可以用来提高效率,但也需要人工完成。用python自动化处理数据,简单轻松高效。
1. 安装python
现在基本上都安装python3,官网上可以免费下载:https://www.python.org/downloads/
2. 安装python编译器pycharm(可选)
此步骤为可选,一般用python自带的IDLE就可以了。如果打算以后深入学习一下,可以安装pycharm编译器(付费但可以试用)。
安装python和pycharm可以参考下面链接中的文章:
Pycharm及python安装详细教程:https://www.cnblogs.com/shizhijie/p/7768973.html
3. 安装数据分析处理所需要的相关库
在写代码前我们需要安装下面6个库(或者称为模块):
xlrd:用于pandas读取excel文件中的数据
xlwt:用于将数据写入新excel(xls)文件,不能对已有的excel文件修改(可选,pandas可以独立完成写excel的操作)
xlutils:可以对已有的excel(xls)文件修改(可选,pandas可以独立完成修改excel的操作)
openpyxl:可以对已有或者新建的excel(xlsx)进行读写修改(可选,pandas可以独立完成修改excel的操作)
pandas:访问和处理数据(类似我们手动操作excel)
numpy:主要是数据矩阵的计算,在处理excel数据的时候一般很少用到,只是在定义pandas中的DataFrame的时候会用到。
3.1 采用IDLE编译的用户安装库的方法
运行cmd,会弹出windows命令行窗口:
c:\user\admin>
依次输入下面的命令进行安装:
pip install xlrd
pip install xlwt
pip install xlutils
pip install openpyxl
pip install pandas
pip install numpy
3.2 采用Pycharm编译的用户安装模块的方法
打开Pycharm,file->settings->Project: Py_Project->project interpreter->'+'(添加模块)
在左边的搜索框中输入需要安装的模块,比如'xlrd'进行安装。
详细的可以参考:https://baijiahao.baidu.com/s?id=1608962838978631456&wfr=spider&for=pc
4. 打开IDLE或者pycharm编译器写代码
对excel数据的处理基本可以套用下面的模板:
# 1. 导入相关的模块
import pandas as pd
import numpy as np
from pandas import DataFrame as df
# 2. 读取待分析的excel数据到pandas的变量中,变量是DataFrame的格式。
df_source = pd.read_excel('D:\python_file\待分析数据.xlsx', sheet_name='sheet3')
# 3. 新建一个DataFrame格式的变量,用于存放数据分析之后的结果
df_result = pd.DataFrame(np.zeros((8, 6)), dtype=int,
columns=['语文', '数学', '英语', '物理', '化学', ‘生物’],
index=['郭靖', '黄蓉', '杨康', '穆念慈', '黄药师', '欧阳锋', '段智兴', '洪七公'] )
# 4. 对df_source进行处理,和人工操作excel方法类似,只不过现在是电脑CPU去完成。处理的结果保存到df_result中。这里面处理比较灵活,下面会具体介绍。
# 5. df_result输出到新的excel成为我们最终启期待的分析结果。
writer = pd.ExcelWriter('数据分析结果.xlsx', encoding='utf-8-sig')
df_result.to_excel(writer, sheet_name='sheet1', startrow=0)
writer.save()4.1 导入相关的模块
将pandas模块导入到我们的运行库中,采用:
import pandas为了方便后续代码编写,一般采用:
import pandas as pd这样后面在用到pandas时都可以用pd代替。
更进一步我们可以:
from pandas import DataFrame as df这样我们可以将pandas这个大模块中的DataFrame这个小模块导入运行库中,并且用df加以代替。
4.2 读取待分析的excel数据
这部分时将待分析的excel数据复制到pandas的变量中,变量是DataFrame的格式
df_source = pd.read_excel('D:\python_file\待分析数据.xlsx', sheet_name='二班')其中read_excel是pandas模块中的一个函数(或者成为”方法“)。函数的目的是将路径D:\python_file 下的“待分析数据.xlsx”文件中的名为”二班“的表格读取复制到格式为DataFrame的变量df_source中。
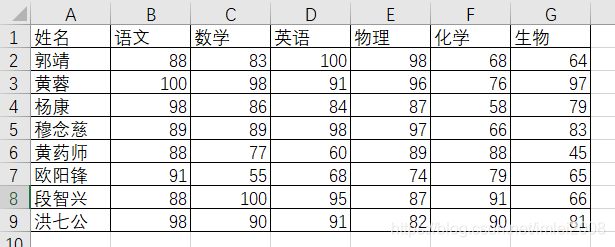
我们可以将df_source打印出来如下:
>>> import pandas as pd
>>> import numpy as np
>>> from pandas import DataFrame as df
>>> df_source = pd.read_excel('D:\python_file\待分析数据.xlsx', sheet_name='二班')
>>> print(df_source)
姓名 语文 数学 英语 物理 化学 生物
0 郭靖 88 83 100 98 68 64
1 黄蓉 100 98 91 96 76 97
2 杨康 98 86 84 87 58 79
3 穆念慈 89 89 98 97 66 83
4 黄药师 88 77 60 89 88 45
5 欧阳锋 91 55 68 74 79 65
6 段智兴 88 100 95 87 91 66
7 洪七公 98 90 91 82 90 81可以看到打印出来的格式和excel表格一样,后面我们直接对这个df_source进行操作就可以了。
4.3 新建变量存储分析之后的结果
新建一个DataFrame格式的变量,可以用于存放数据分析之后的结果。
>>> df_result = pd.DataFrame(np.zeros((8, 7)), dtype=int,
columns=['语文', '数学', '英语', '物理', '化学', '生物', '总分'],
index=['张三丰', '宋远桥', '俞莲舟', '俞岱岩', '张松溪', '张翠山', '殷梨亭', '莫声谷'] )
>>> print(df_result)
语文 数学 英语 物理 化学 生物 总分
张三丰 0 0 0 0 0 0 0
宋远桥 0 0 0 0 0 0 0
俞莲舟 0 0 0 0 0 0 0
俞岱岩 0 0 0 0 0 0 0
张松溪 0 0 0 0 0 0 0
张翠山 0 0 0 0 0 0 0
殷梨亭 0 0 0 0 0 0 0
莫声谷 0 0 0 0 0 0 0a) df_result = pd.DataFrame(...)是新建一个dataframe变量df_result,
b) 函数的参数np.zeros((8, 6)是一个8行6列的矩阵,
c) dtype=int表示矩阵元素的类型为整数类型,当然后面我们可以改成浮点型或者字符型后者其他更复杂的类型都可以,主要是根据实际的需求。
d) columns表示各列的标题
e) index表示各行的标题
4.4 根据对df_source进行处理
下面介绍几种常用的dataframe的操作。
4.4.1 访问表格元素
>>> df_source.loc[1] # 通过 idx=1 访问第一行,如果表格是标题索引的,用'标题'访问
姓名 黄蓉
语文 100
数学 98
英语 91
物理 96
化学 76
生物 97
Name: 1, dtype: object
>>> df_source.iloc[1] # 通过 idx=1 访问第一行,表格是从第0行开始的
姓名 黄蓉
语文 100
数学 98
英语 91
物理 96
化学 76
生物 97
>>> df_source.loc[:,'语文'] # 通过 标题 访问“语文”这一列
0 88
1 100
2 98
3 89
4 88
5 91
6 88
7 98
Name: 语文, dtype: int64
>>> df_source.iloc[:,0] # 通过idx=0访问“姓名”这一列
0 郭靖
1 黄蓉
2 杨康
3 穆念慈
4 黄药师
5 欧阳锋
6 段智兴
7 洪七公
Name: 姓名, dtype: object
>>> df_source.loc[[2,6],['语文','物理', '生物']] # 提取指定的行列
语文 物理 生物
2 98 87 79
6 88 87 66
>>> df_new = df_source.loc[[2,6],['语文','物理', '生物']] # 提取指定的行列保存到新的dataframe中
>>> df_new
语文 物理 生物
2 98 87 79
6 88 87 66
>>> df_source.loc[df_source['物理']>=85] # 筛选满足要求的行(物理分数>=85)
姓名 语文 数学 英语 物理 化学 生物
0 郭靖 88 83 100 98 68 64
1 黄蓉 100 98 91 96 76 97
2 杨康 98 86 84 87 58 79
3 穆念慈 89 89 98 97 66 83
4 黄药师 88 77 60 89 88 45
6 段智兴 88 100 95 87 91 66
>>> df_source.loc[(df_source['物理']>=85) & ((df_source['化学']>=85))]
姓名 语文 数学 英语 物理 化学 生物
4 黄药师 88 77 60 89 88 45
6 段智兴 88 100 95 87 91 66元素的访问经常会和for循环语句联合使用,比如下面统计各科及格的人数。
# 新建一个dataframe用于存放数据处理结果
>>> df_result2 = pd.DataFrame(np.zeros((1, 6)), dtype=int,
columns=['语文', '数学', '英语', '物理', '化学', '生物'],
index=['及格人数'])
>>> for j in df_source.columns:
for i in df_source.index:
if(j != '姓名'):
if(df_source.loc[i, j] >= 80):
df_result2.loc['及格人数', j]+=1
>>> df_result2
语文 数学 英语 物理 化学 生物
及格人数 8 6 6 7 3 3dataframe很可能有现成的函数实现上面这段代码的功能,如果找不到,自己实现也很简单。
4.4.2 简单求和操作
首先看按列对某一行的求和:
# 计算各列数据总和并作为新列添加到末尾
>>> df_source['个人总分'] = df_source.loc[:,'语文':'生物'].apply(lambda x: x.sum(), axis=1)
>>> df_source
姓名 语文 数学 英语 物理 化学 生物 个人总分
0 郭靖 88 83 100 98 68 64 501
1 黄蓉 100 98 91 96 76 97 558
2 杨康 98 86 84 87 58 79 492
3 穆念慈 89 89 98 97 66 83 522
4 黄药师 88 77 60 89 88 45 447
5 欧阳锋 91 55 68 74 79 65 432
6 段智兴 88 100 95 87 91 66 527
7 洪七公 98 90 91 82 90 81 532a) df_source.loc[:,'语文':'生物']是从列“语文”到“生物”组成的新的dataframe。
b) apply就是对“df_source.loc[:,'语文':'生物']”这个dataframe求和,怎么求和要看axis,=1就是按列求和,0或者缺省则是按行求和。
c) 最后赋值到df_source['个人总分']中,它是在原df_source的最后添加的一列
再看按行对某一列的求和:
>>> df_result2.loc['各科总分'] = df_source.loc[:,'语文':'生物'].apply(lambda x: x.sum())
>>> df_result2
语文 数学 英语 物理 化学 生物
及格人数 8 6 6 7 3 3
各科总分 740 678 687 710 616 5804.4.3 简单的排序
>>> df_sorted = df_source.sort_values(["个人总分", "语文"], inplace=False, ascending=[True, True])
>>> df_sorted
姓名 语文 数学 英语 物理 化学 生物 个人总分
5 欧阳锋 91 55 68 74 79 65 432
4 黄药师 88 77 60 89 88 45 447
2 杨康 98 86 84 87 58 79 492
0 郭靖 88 83 100 98 68 64 501
3 穆念慈 89 89 98 97 66 83 522
6 段智兴 88 100 95 87 91 66 527
7 洪七公 98 90 91 82 90 81 532
1 黄蓉 100 98 91 96 76 97 558a) sort_values()函数实现对df_source的排序
b) ["个人总分", "语文"],首先是根据“个人总分”排,然后根据“语文”排。
c) ascending=[True, True], Ture就是升序,False就是降序,两个分别对应b)中的2个参数。
上面的代码是根据2个参数来排序,当然我们也可以根据更多的参数来排。
4.4.4 设置写入到excel表示个数据的格式
这里的格式主要指的是浮点,整型,字符串等类型。字符串和整型都简单,我们主要学习一下浮点型的格式。浮点型输出到excel表格中由于小数点的位数不一样导致整张表不是很好看,就是下面的平均分。
>>> df_result2.loc['各科平均分'] = df_source.loc[:,'语文':'生物'].apply(lambda x: x.mean())
>>> df_result2
语文 数学 英语 物理 化学 生物
及格人数 8.0 6.00 6.000 7.00 3.0 3.0
各科总分 740.0 678.00 687.000 710.00 616.0 580.0
各科平均分 92.5 84.75 85.875 88.75 77.0 72.5我们可以保留2小数点的位数:
>>> df_result2 = df_result2.applymap("{0:.2f}".format)
>>> df_result2
语文 数学 英语 物理 化学 生物
及格人数 8.00 6.00 6.00 7.00 3.00 3.00
各科总分 740.00 678.00 687.00 710.00 616.00 580.00
各科平均分 92.50 84.75 85.88 88.75 77.00 72.50我们发现上面的df_result2都是浮点型,其实及格人数和各科总分不需要是浮点类型的(至少显示的时候小数不显示)。
>>> df_result2.loc['各科平均分'] = df_result2.loc['各科平均分'].map("{0:.2f}".format)
>>> print(df_result2)
语文 数学 英语 物理 化学 生物
及格人数 8 6 6 7 3 3
各科总分 740 678 687 710 616 580
各科平均分 92.50 84.75 85.88 88.75 77.00 72.50map函数值操作了‘各科平均分’这一行,但是其他的行也变回了整型,这可能与数据定义的时候原本是整型有关。
有时候还有输出“%”的需要:
>>> df_result2.loc['及格人数比例'] = 100*df_result2.loc['及格人数']/8
>>> df_result2.loc['及格人数比例'] = df_result2.loc['及格人数比例'].map("{0:.2f}%".format)
>>> print(df_result2)
语文 数学 英语 物理 化学 生物
及格人数 8 6 6 7 3 3
各科总分 740 678 687 710 616 580
各科平均分 92.50 84.75 85.88 88.75 77.00 72.50
及格人数比例 100.00% 75.00% 75.00% 87.50% 37.50% 37.50%4.4.5 插入列行操作
插入列:
>>> df_time = pd.read_excel('D:\python_file\待分析数据.xlsx', sheet_name='时间')
>>> df_time
Unnamed: 0 开始时间 结束时间
0 郭靖 2019-05-17 09:12:47 2019-05-17 09:46:18
1 黄蓉 2019-05-17 09:46:18 2019-05-17 17:59:42
2 杨康 2019-05-17 17:59:42 2019-08-09 16:27:15
3 穆念慈 2019-08-09 16:27:15 2019-08-09 16:28:42
4 黄药师 2019-08-09 16:28:42 2019-08-12 16:35:01
5 欧阳锋 2019-08-12 16:35:01 2019-08-12 16:40:23
6 段智兴 2019-08-12 16:40:23 2019-08-12 16:47:33
7 洪七公 2019-08-12 16:47:33 2019-08-12 17:00:39
>>> df_time_start = df_time.pop('开始时间') #将开始时间这一列赋值到df_time_start
>>> df_time_end = df_time.pop('结束时间')
>>> df_source.insert(7, '开始时间', df_time_start) #将df_time_start插入到第7列,列名设置为“开始时间”
>>> df_source.insert(8, '结束时间', df_time_end)
姓名 语文 数学 英语 物理 化学 生物 开始时间 结束时间 个人总分
0 郭靖 88 83 100 98 68 64 2019-05-17 09:12:47 2019-05-17 09:46:18 501
1 黄蓉 100 98 91 96 76 97 2019-05-17 09:46:18 2019-05-17 17:59:42 558
2 杨康 98 86 84 87 58 79 2019-05-17 17:59:42 2019-08-09 16:27:15 492
3 穆念慈 89 89 98 97 66 83 2019-08-09 16:27:15 2019-08-09 16:28:42 522
4 黄药师 88 77 60 89 88 45 2019-08-09 16:28:42 2019-08-12 16:35:01 447
5 欧阳锋 91 55 68 74 79 65 2019-08-12 16:35:01 2019-08-12 16:40:23 432
6 段智兴 88 100 95 87 91 66 2019-08-12 16:40:23 2019-08-12 16:47:33 527
7 洪七公 98 90 91 82 90 81 2019-08-12 16:47:33 2019-08-12 17:00:39 532插入行:
插入行没有特别好的方法,不过我们可以利用先增加一行,再增加一列,最后按列排序的方法实现:
>>> df_result2.loc['年级平均分'] = [0, 0, 0, 0, 0, 0] # 添加一行到最后
>>> df_result2['index'] = [0 ,1, 2, 3, 2] # 最后一个数字=2,即表明需要将当前行插入到目前第二行的后面
>>> df_result2
语文 数学 英语 物理 化学 生物 index
及格人数 8 6 6 7 3 3 0
各科总分 740 678 687 710 616 580 1
各科平均分 92.50 84.75 85.88 88.75 77.00 72.50 2
及格人数比例 100.00% 75.00% 75.00% 87.50% 37.50% 37.50% 3
年级平均分 0 0 0 0 0 0 2
>>> df_result2.sort_values(["index"], inplace=True, ascending=[True])
>>> df_result2
语文 数学 英语 物理 化学 生物 index
及格人数 8 6 6 7 3 3 0
各科总分 740 678 687 710 616 580 1
各科平均分 92.50 84.75 85.88 88.75 77.00 72.50 2
年级平均分 0 0 0 0 0 0 2
及格人数比例 100.00% 75.00% 75.00% 87.50% 37.50% 37.50% 3
>>> df_result2.drop(columns='index',inplace=True)
>>> df_result2
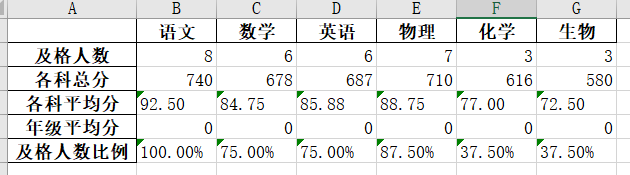
语文 数学 英语 物理 化学 生物
及格人数 8 6 6 7 3 3
各科总分 740 678 687 710 616 580
各科平均分 92.50 84.75 85.88 88.75 77.00 72.50
年级平均分 0 0 0 0 0 0
及格人数比例 100.00% 75.00% 75.00% 87.50% 37.50% 37.50%
4.4.6 时间相关操作
在许多情况下我们都需要计算事物处理的效率,那么肯定需要先计算处理完事物所花费的总时间。一般时间在excel文件中以这样的格式存储:
开始时间:2019/6/12 14:01:03 结束时间:2019/7/31 14:34:51
我们需要计算的时间差。DaraFrame中有对应的变量格式进行存储。
>>> time_duration = df_source.loc[0, '结束时间'] - df_source.loc[0, '开始时间']
>>> time_duration
Timedelta('0 days 00:33:31')
>>> time_dur_days = time_duration.days + time_duration.seconds/(3600*24) # 转化为天为单位
>>> time_dur_days
0.023275462962962963上面的代码时转化成天给单位的,我们也可以根据自己的需求转化成小时或者分钟等等。
4.5 结果输出到新的excel
>>> writer = pd.ExcelWriter('数据分析结果.xlsx', encoding='utf-8-sig')
>>> df_source.to_excel(writer, sheet_name='成绩1', startrow=0)
>>> df_result2.to_excel(writer, sheet_name='成绩2', startrow=0)
>>> writer.save()excel结果如下:
成绩1:
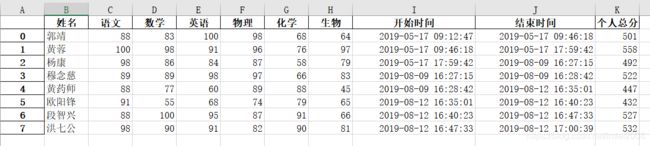
成绩2:
前面的介绍都只设计到了pandas dataframe的基本操作,是一个基本的非常简单的例子,但是可以应付我们大多数情况下的操作。还有很多现有的方法都可以加快我们对数据的分析,下面时pandas dataframe的手册网址路径:
https://pandas.pydata.org/pandas-docs/stable/reference/frame.html