用fme提取图斑特征值用knn邻近算法构造训练模型,实现按照图斑形状相似度分类
作者:努力的悟空
目录
前言
一、图形形状相似度分类案例
二、需要环境和步骤
1.用fme进行数据特征值提取
2.读入数据
3.数据分割
4.特征工程预处理
5.实例化估计器,和交叉网格验证
6.模型训练
7.模型评估
8.输入值测试模型效果
总结
前言
随着人工智能的不断发展,机器学习这门技术也越来越重要,机器学习的基本原理都是通过提取需要训练对象的一系列的特征值,然后提前设定好分类目标值,通过投喂大量的数据来完成模型的建立。之后就只需要通过该模型的计算得出数据的预测值。本文主要采用了机器学习的knn算法来完成模型搭建,什么是knn算法呢,大概意思就是通过一个n维向量建立的kd树,输入的数据只需要查找到距离最近的那一个点,然后就会选择和那个点一样的类别。接下来我们直接进入实战来展示knn算法的运用。
一、图形形状相似度分类案例

我们以这些图形为案例,通过肉眼判断,我们可以将这些图形按形状类型分为8种形状,那么我们就需要提前把目标结果手动输入进去,作为我们的训练样本。训练出模型之后随便导入一个图形,模型就会计算出最接近的形状给出预测结果。
二、需要环境和步骤
1.用fme进行数据特征值提取


我们需要尽可能多的抓取能提现图形形状的数据参数,这里我选取了8个数据:环洞个数,各种内角角度个数,界址点个数,面积,周长等。由于本文主要是展示knn算法的实现过程,所以数据提取的步骤不做详解,需要了解数据提取的小伙伴可以私聊。
2.读入数据
首先我们需要把fme的数据格式转换为pandas的datafrom格式因为fmeobj的特性,我们需要在init函数实例化变量,注意一定要在变量前加self(这是因为class类的原因,每一个变量前加一个self代表类本身)然后我们将字段导入进sheet数组,在用pandas把格式转换。
class FeatureProcessor(object):
def __init__(self):
self.aa=[]
self.bb=[]
self.sheet1=()
self.sheet2=()
pass
def input(self,feature):
#获取数据集
self.aa.append([feature.getAttribute('面积'),feature.getAttribute('周长'),feature.getAttribute('钝角个数'),feature.getAttribute('锐角个数'),feature.getAttribute('直角个数'),feature.getAttribute('凹角个数'),feature.getAttribute('边界框面积'),feature.getAttribute('JZDH.total_count'),feature.getAttribute('环洞个数')])
self.sheet1=pd.DataFrame(self.aa,columns=['面积','周长','钝角','锐角','直角','凹角','边界框','界址','环洞'])
self.bb.append([feature.getAttribute('目标值')])
self.sheet2=pd.DataFrame(self.bb,columns=['目标'])3.数据分割
我们需要把数据按训练比例进行分割,一般来说是百分之20作为测试集,百分之80作为训练集。
我这里是因为训练数据量太少了,测试集只区了百分之15.
x = self.sheet1[['面积','周长','钝角','锐角','直角','凹角','边界框','界址','环洞']]
y = self.sheet2["目标"]
print(x)
print('---------'*30)
print(y)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.15)4.特征工程预处理
为什么要进行这一步,是因为我们的数据量大小不一致,如不进行标准差处理的话,有些字段比如面积基数很大,但是界址点个数很小,那么面积的权重就会占比很大从而导致测试的不准确,sklearn模块自带了特征值方差求解的api,所以我们只需要一行代码就可以搞定。
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)5.实例化估计器,和交叉网格验证
为了让被评估的模型更加准确可信我们需要添加交叉验证:将拿到的训练数据,分为训练和验证集。比如我们将数据分成4份,其中一份作为验证集。然后经过4次(组)的测试,每次都更换不同的验证集。即得到4组模型的结果,取平均值作为最终结果。又称4折交叉验证。这里我cv就是验证次数param_grid就是网格网格搜索的k值。
estimator = KNeighborsClassifier()
param_grid = {"n_neighbors": [1, 3, 5,7,9]}
estimator = GridSearchCV(estimator, param_grid=param_grid, cv=5, n_jobs=1)6.模型训练
将训练集投入
estimator.fit(x_train, y_train)7.模型评估
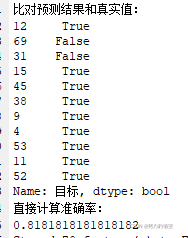
y_predict = estimator.predict(x_test)
score = estimator.score(x_test, y_test)我们将以上两个参数,打印出来可以看到模型的以及构造成功,并对测试集进行的测试,如果测试完没问题,我们就只需要保存模型就可以了。
8.输入值测试模型效果
我们重新找来3个全新的样本,来测试我们构建的模型是否正确

我们将上一步的模型导入进来
estimator = joblib.load(r"F:\人工智能全套资料\阶段5-人工智能经典算法编程\第6节 K-近邻算法\test.pkl")用之前的fme构建的模板重新获取特征值

然后调用训练的模型进行训练,最后将训练的结果保存为字段
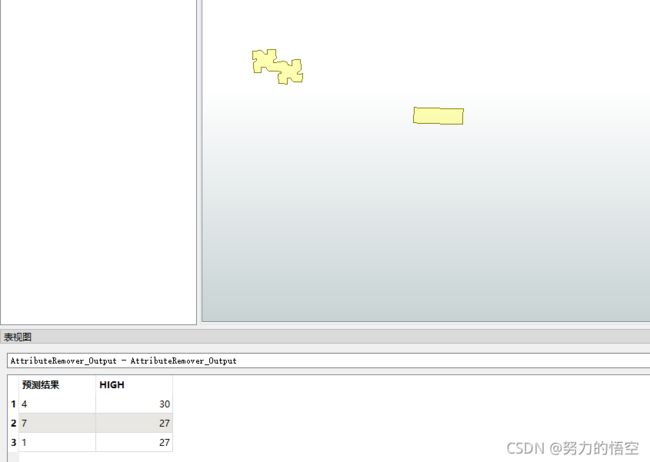
可以看到输入的3个新图形已经自动完成了预测结果分类。
总结
前前后后大概学习了两个月的机器学习,以上展示的只是机器学习的其中一个算法的api调用,其中蕴含的真正的算法,原理并没有做详细的赘述。aid 学习路线实在是非常枯燥,涉及的数学知识之多,高数、统计学、线性代数,如果不了解原理只是学会调用api 配置参数,那么只能说机器学习还未能入门,但是一直怼基础原理又会非常枯燥,这里也是完全开源给大家分享一个实操案例,感兴趣的小伙伴可以手动敲一下代码,模型构建和模型评估还是很有意思的。