入门小远学爬虫(二)(二)简单GET型网页爬虫实战——“前程无忧”爬虫岗位信息的爬取之Python requests库的简单使用
文章目录
- 前言
- 一、如何在Pycharm中导入requests库?
- 二、如何使用requests库?
-
- 1、先试试最简单的GET法
- 2、加入请求头
- 小结
前言
这是本系列第一个实战项目的第二课,有关第一课“网页分析”的内容请点击链接
话不多说,开始今天的奋斗
提示:本系列文章均为原创,欢迎转载,但请注明出处谢谢!
网页分析之后就需要Python上场了,今天的主角是Python的requests库。requests是Python实现的最简单易用的HTTP库,适合基础简易的爬虫开发,最关键的是它适合0基础学爬虫的同学上手开发爬虫。
一、如何在Pycharm中导入requests库?
打开或在合适的位置新建项目,比如说博主选择项目路径是
D:\CSDN用\Python爬虫系列
点击 “文件”(File)->“设置”(Setting)
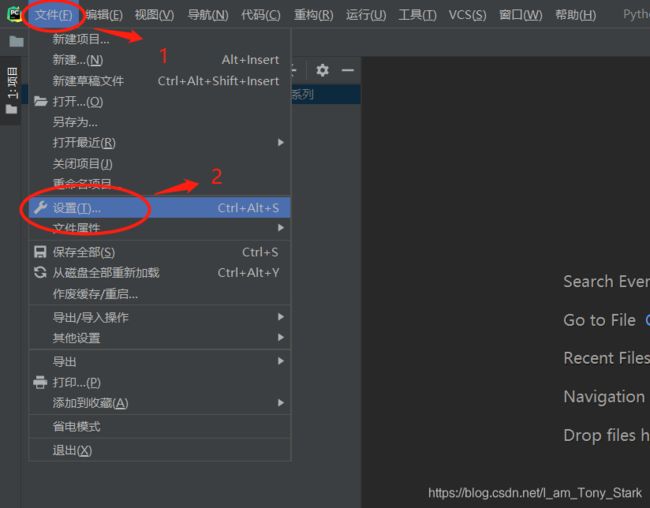
点击“项目(Project):你的项目名称”->“Python解释器”(Project Interpreter)->"+",打开搜索对话框

搜索 “requests”->点击"安装包"(Install Package)
有时因为包的版本太高,代码运行出错,此时需要选中右下角的“指定版本”(Specify version),然后选择想要的版本即可。此处由于PyCharm下的是最新版本,所以不用担心这个问题。

稍等片刻,显示安装成功。点击“确定”,关闭设置窗口。

二、如何使用requests库?
关于requests库的基本使用
1、先试试最简单的GET法
# -*- coding: utf-8 -*-
# @Time: 2020/11/29 14:21
# @Author: 胡志远
# @Software: PyCharm
# 导入requests包
import requests
# 网页链接
url = "https://jobs.51job.com/pachongkaifa/p1/"
# 无请求头写法
res = requests.get(url)
# 也可以写作res = requests.get(url=url),但一个参数的情况下没有必要多此一举
print(res)
结果发现报错了
原因很简单,假设有两间房,第一间房间什么有价值的东西都没有,第二间房有很多比较有价值的金银财宝,现在要你独守空房。显然,如果这个时候有人想进来,你前者的戒备心肯定要小于后者。网页也是一样,网页内有用的数据越多,他就越怕人家轻轻松松拿掉了他辛辛苦苦弄来的数据,所以他会有一套专门的算法来抵制爬虫,这个机制就叫反爬。

前面也说到,爬虫就是模仿浏览器嘛,他之所以不给你数据,还不是因为你伪装浏览器装得不够像!那解决办法就是让自己装得更像一点不就行了?所以,需要
2、加入请求头
请求头就好像一个证明身份的“合格证”,告诉服务器,“我是有‘合法经营手续’的正规浏览器,你们不能阻挡我。”
怎么获取请求头呢,这里又需要用到Chrome的开发者工具了,使用Chrome打开网页,调出开发者工具【怎么调出请参考“前程无忧”实战项目之(一),在此不赘述】,刷新页面(这个刷新很关键)。点击Network,点击所需数据的来源,在右边的属性栏找到Request Headers。里面有很多信息,其中有很多很重要的内容(比如Cookie和User-Agent这种都是很重要、需要掌握的),但篇幅有限只能在之后的文章中陆续介绍。
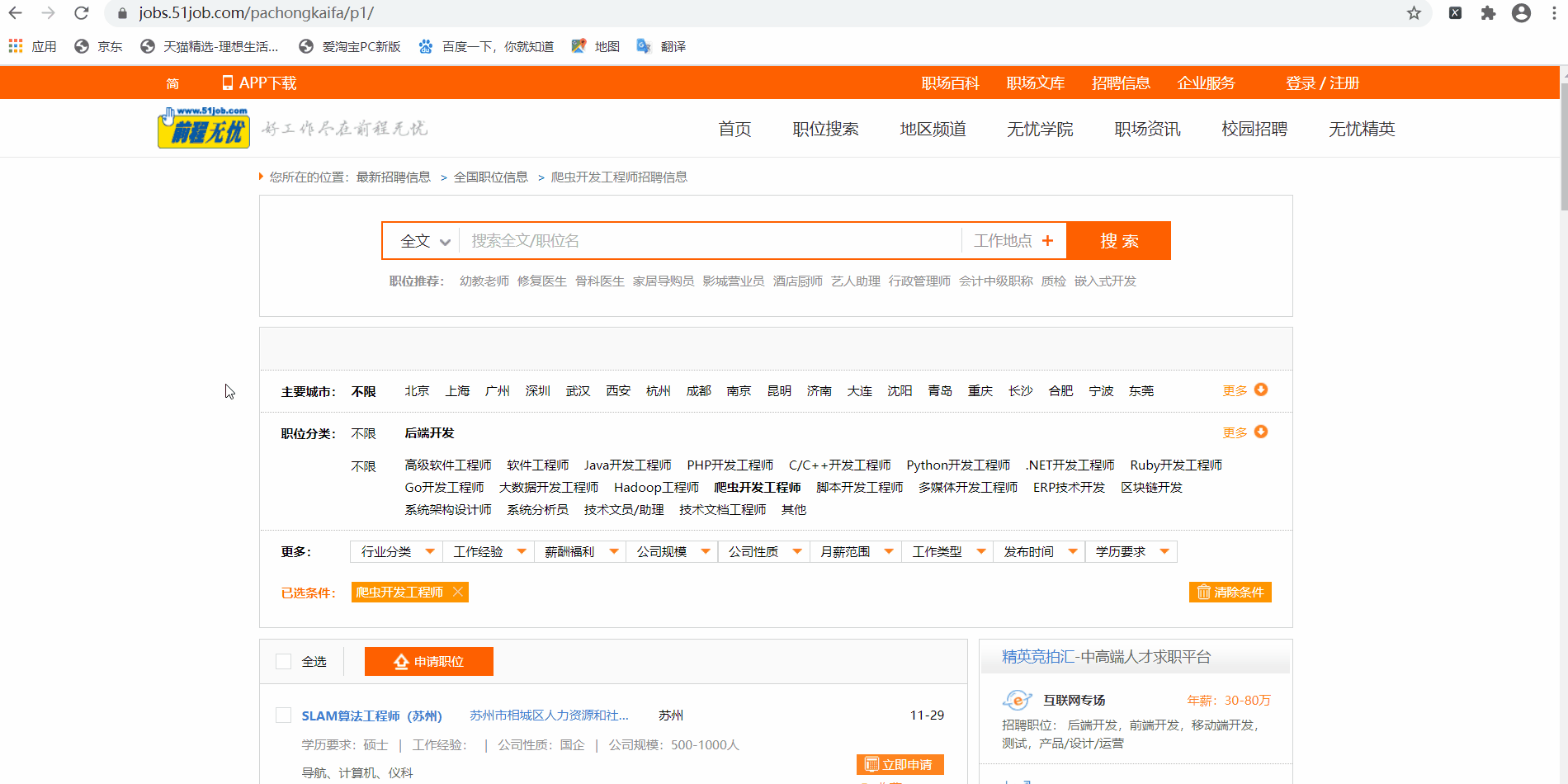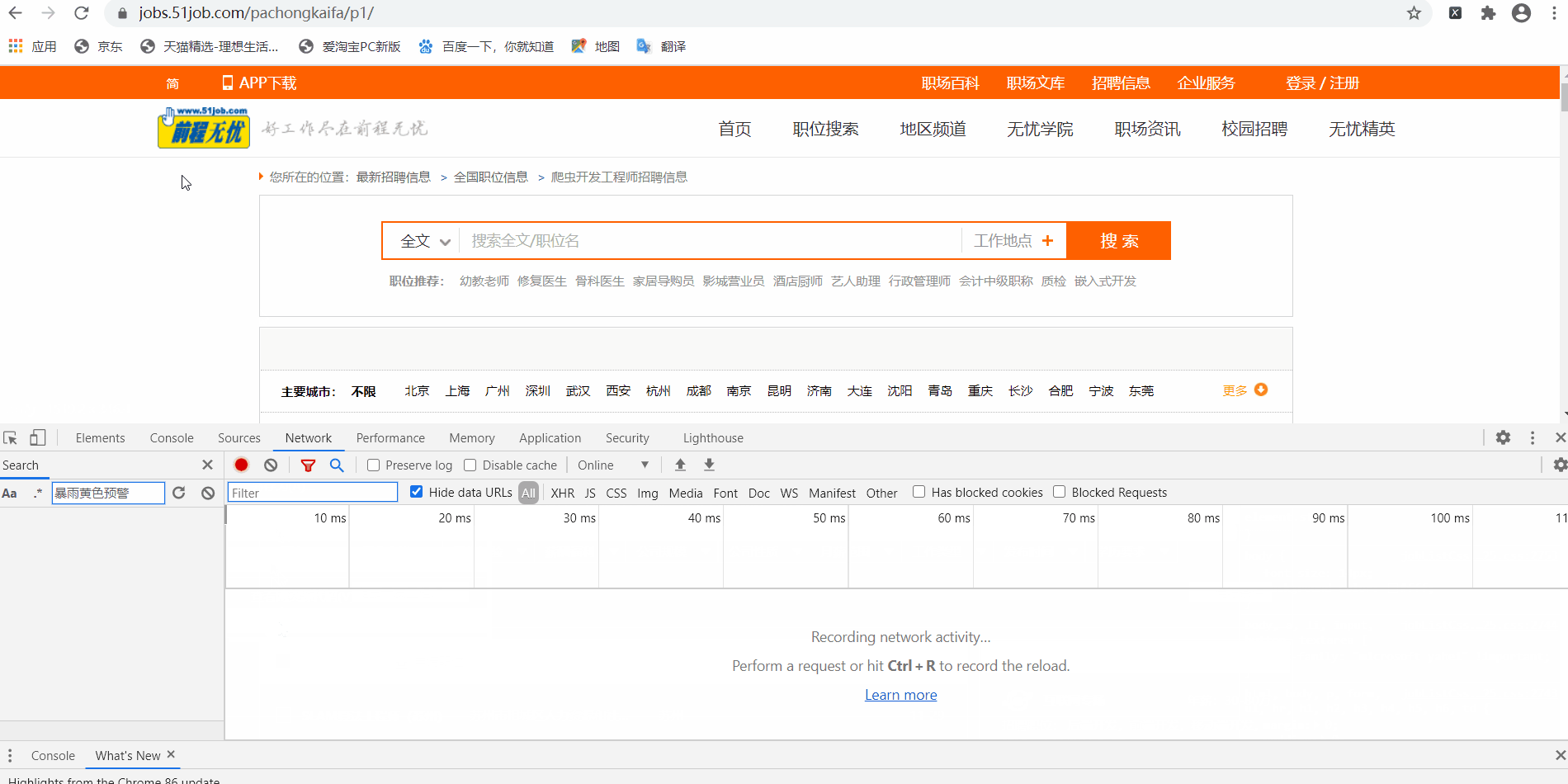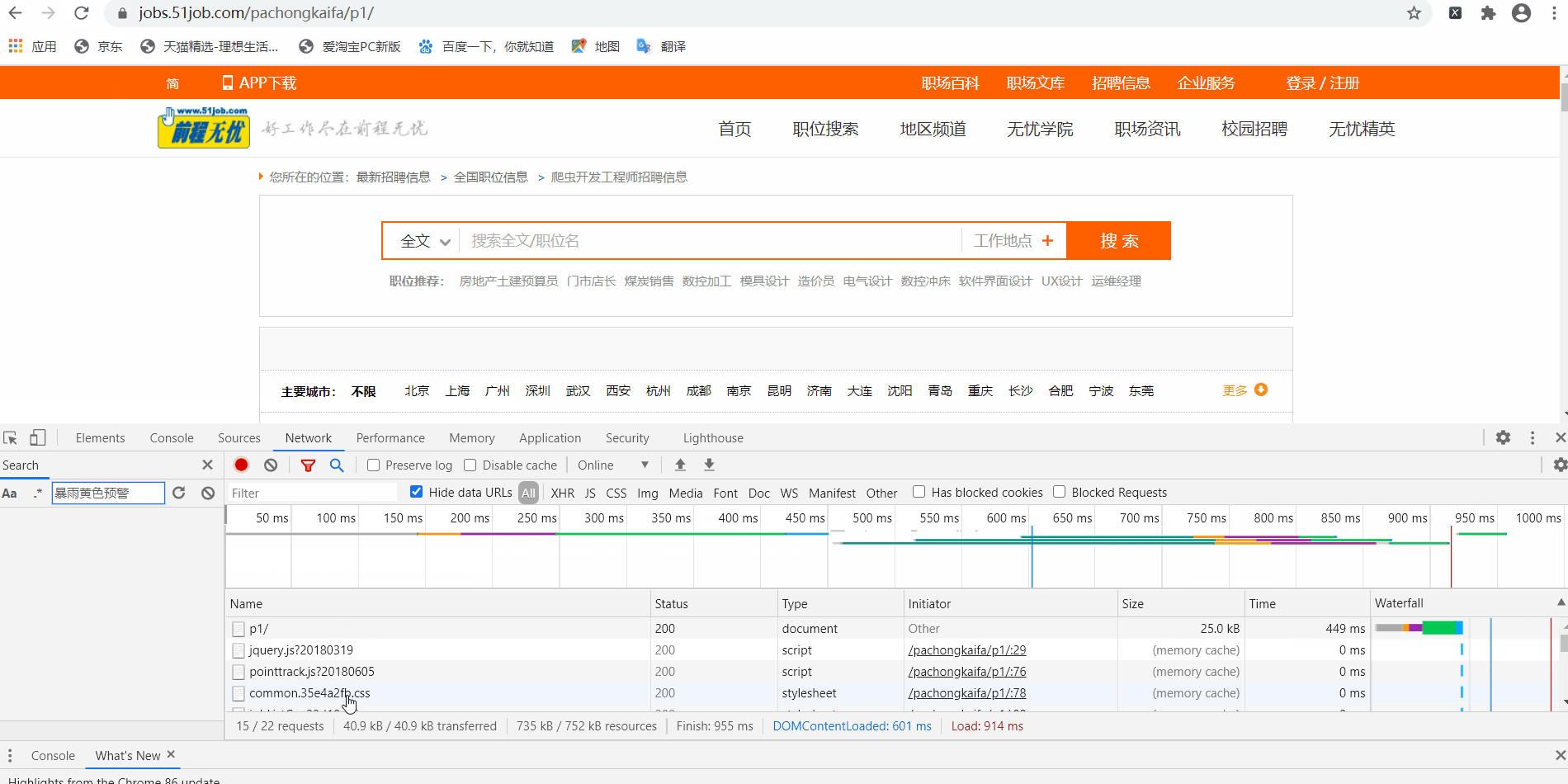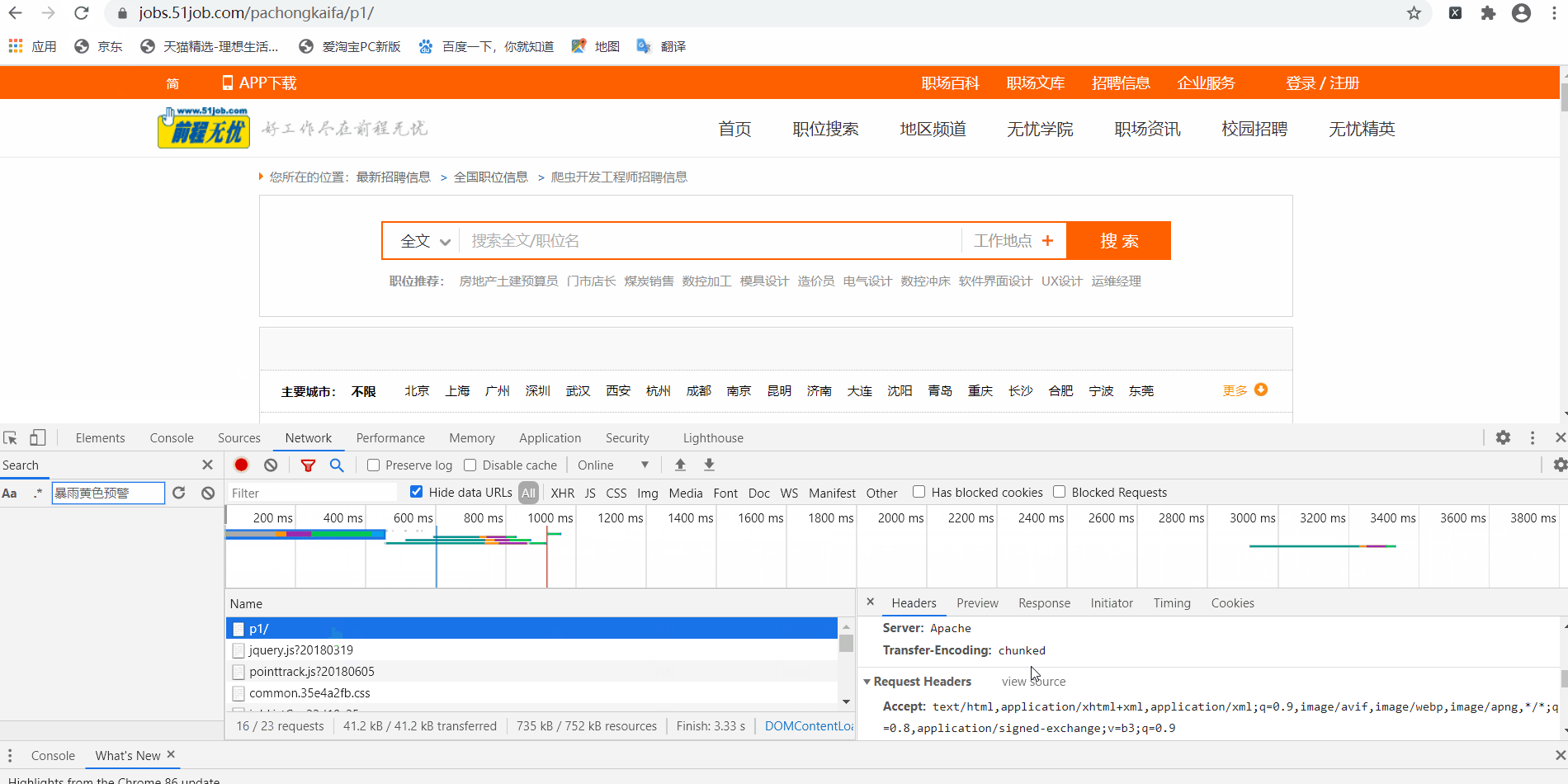
此处,有一个最好理解也是最笨的方法:把他一股脑全部写进头里面,然后用这个头去请求,这样做的好处就是,等于100%模拟你的这个Chrome去访问服务器,你暂时不需要知道每一项代表了什么意思,容易更快速地上手爬虫;但是坏处就是稍微难一点的网页就很难爬了,好在,这个“前程无忧”的网页不难。那么,修改一下代码
# -*- coding: utf-8 -*-
# @Time: 2020/11/29 14:21
# @Author: 胡志远
# @Software: PyCharm
# 导入requests包
import requests
# 网页链接
url = "https://jobs.51job.com/pachongkaifa/p1/"
# 请求头
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Cookie": "guid=7e8a970a750a4e74ce237e74ba72856b; partner=blog_csdn_net",
"Host": "jobs.51job.com",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36"
}
# 有请求头写法
res = requests.get(url=url, headers=headers)
print(res)
OK,大功告成,东西拿到了,我们成功骗过了服务器。松活弹抖闪电鞭第一式——“接”,完成!
运行结果

初学的同学可能会问我这个200是个什么,可以参考这个网站,总之这是个很复杂的玩意,requests对象存储了服务器返回给客户端的各种各样的信息,比如有:
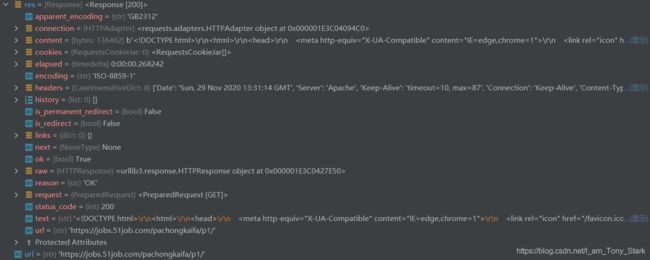
对于初学者来说,与请求头一样,不必了解所有分别代表什么,我们暂时只要获取网页源代码就行了嘛。将res.text打印出来(print代码改为print(res.text)),你们看看是什么,是不是很眼熟?再打开开发者工具看看Elements(网页源代码),看看是不是很像?
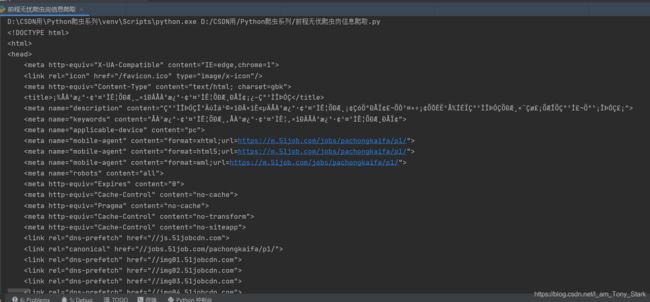
什么?有乱码?那是因为没正确解码,这里的res.text的解码类型来源是根据http头部对响应的编码作出推测,当然,这里它显然推错了,运用了错误的解码方式,当然解出来是乱码。
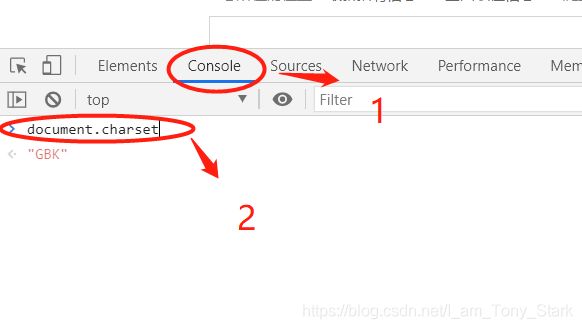
打开开发者工具,点击Console,在下方输入document.charset,可知该网页的编码方式为GBK编码,那么我们只需要告诉Python让它正确解码就行了
在print语句之前加一句正确解码的语句:
res.encoding = "gbk"
现在好看多了,运行结果如图
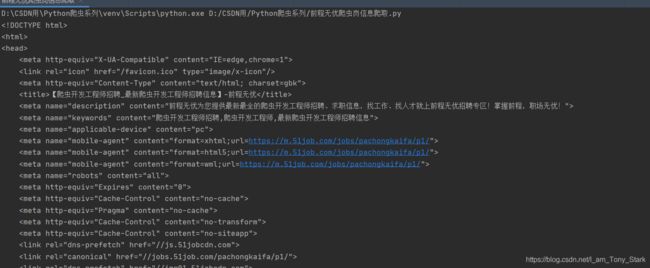
至此,requests完成了它的使命,我们已经拿到了网页内容,之后就要靠解析工具了,还记得上一节讲的Xpath吗,还没登场呢!
下一节已经更新
小结
使用requests库三部曲:
1、引入包(import)
2、发送请求获取数据
3、根据编码解码(可能不用)
如果觉得博主写的还不错的,欢迎点赞、评论、加关注,大家的访问就是博主更新文章不竭的源动力!