基于Scrapy框架的网络爬虫入门练习
基于Scrapy框架的网络爬虫
这几天一直在看书自学scrapy框架,写博客完全就是记录自己的生活并对这几天学习的理解做一个总结吧,这次也不难,可以说是入门的体验吧。
Scrapy是一个比较流行的网络爬虫框架,它的优势很多,我也不介绍了,直接来干货。
-
在命令行使用pip命令 pip install Scrapy

-
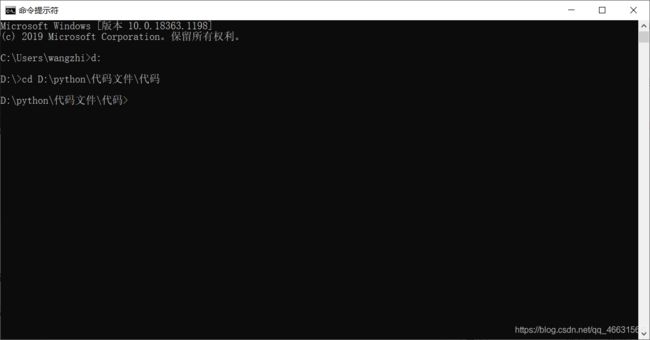
安装成功后,在来到我们自定义的目录下开始实战;
-
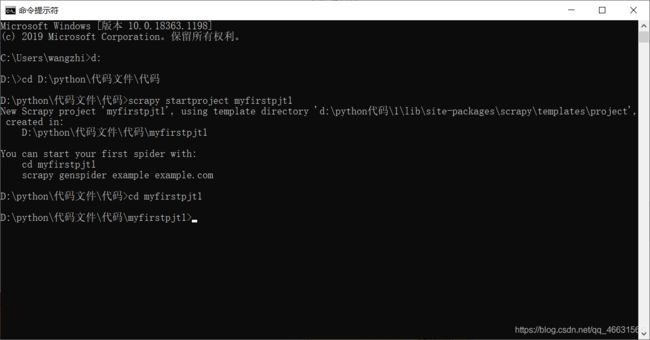
使用startproject创建项目;

-
创建成功后,进入该目录下;
-
使用genspider创建爬虫;先来看一下可以使用爬虫的模板,发现有basic、crawl、csvfeed、xmlfeed共4个模板;

我们来创建一个爬虫试试看;比如创建一个basic模块的爬虫,爬虫名为weisuen1;
创建成功后,此时会在spider目录下生成一个名为weisuen1.py的爬虫文件。
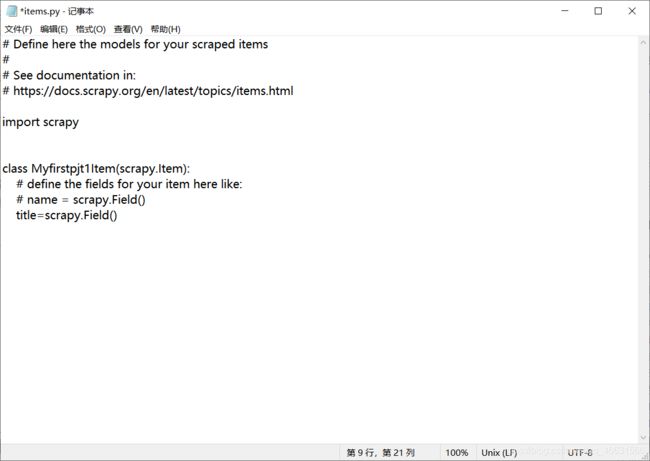
6. 此时我们来修改参数,使用爬虫框架来获取数据,首先来到myfirstpjt1目录下,修改此目录下的items.py文件,然后保存;
- 然后修改spiders目录下的weisuen1.py文件,保存成功;
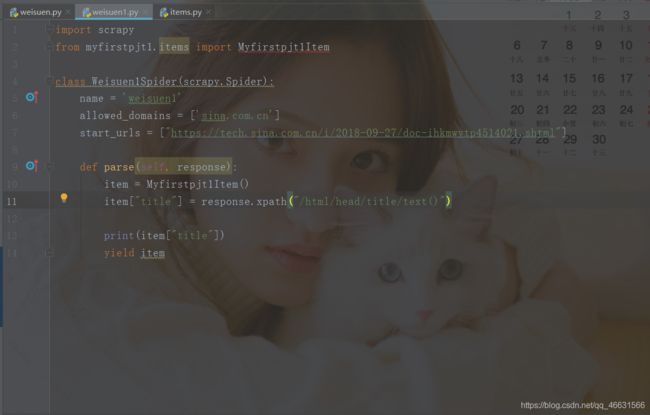
8.运行weisuen1.py爬虫,得到结果,备注:–nolog是不打印日志,若运行没有结果,请打印日志查看错误原因。

总结
此次只是scrapy的一个入门教程,以后会有更多、更深奥的知识要去探索,加油!