【王喆-推荐系统】前沿篇-(task1)YouTube推荐架构
学习总结
- YouTube推荐架构=召回层(多,快)+排序层(少,精)。
- 候选集生成模型:用了Embedding MLP,注意最后的多分类的输出层,预测的是用户点击了“哪个”视频。线上服务时,需要从输出层提取出【视频 Embedding】,从最后一层 ReLU 层得到【用户 Embedding】,然后利用最近邻搜索(如LSH等)快速得到某用户的候选集。
- 排序模型:也是Embedding MLP 架构,但是有更多的用户和视频的特征输入层,输出层采用了 Weighted LR(逻辑回归) 作为输出层,并且使用观看时长作为正样本权重,让模型能够预测出观看时长,这更接近 YouTube 要达成的商业目标。
(1)精读谷歌的这篇paper《Deep Neural Networks for YouTube Recommendations》
(2)王喆老师的YouTube深度学习推荐系统的十大工程问题
文章目录
- 学习总结
- 一、YouTube 推荐系统架构
- 二、候选集生成模型
- 三、候选集生成模型独特的线上服务方法
-
- 3.1 问题一:为啥用视频ID作为预测label
- 3.2 问题二:视频embedding和用户embedding哪里来
- 四、排序模型
-
- 4.1 排序层模型
- 4.2 排序层和召回层的输出层
- 4.3 排序模型的模型服务方法
- 五、作业
- 六、课后答疑
- Reference
一、YouTube 推荐系统架构
YouTube 平台中几乎所有的视频都来自 UGC(User Generated Content,用户原创内容),其内容产生模式特点:
- 一是其商业模式不同于 Netflix,以及国内的腾讯视频、爱奇艺这样的流媒体,这些流媒体的大部分内容都是采购或自制的电影、剧集等头部内容,而 YouTube 的内容都是用户上传的自制视频,种类风格繁多,头部效应没那么明显;
- 二是由于 YouTube 的视频基数巨大,用户难以发现喜欢的内容。
YouTube 在 2016 年发布的推荐系统架构:
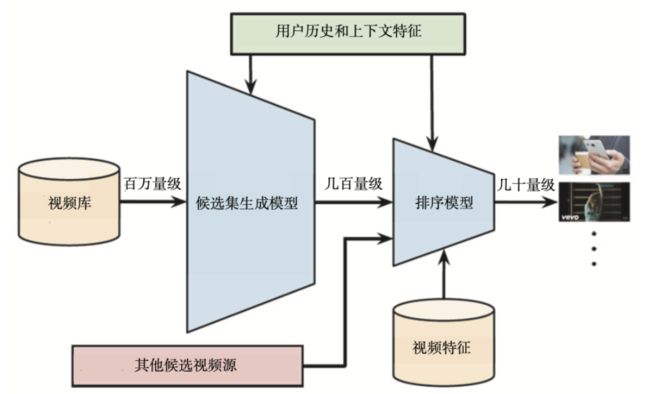
为了对海量的视频进行快速、准确的排序,YouTube 也采用了经典的召回层 + 排序层的推荐系统架构(两层都使用了深度学习方法)。其推荐过程分为两级:
- 第一级是用候选集生成模型(Candidate Generation Model)完成候选视频的快速筛选,在这一步,候选视频集合由百万降低到几百量级,这就相当于经典推荐系统架构中的召回层。
- 第二级是用排序模型(Ranking Model)完成几百个候选视频的精排,这相当于经典推荐系统架构中的排序层。
二、候选集生成模型
视频召回的候选集生成模型:
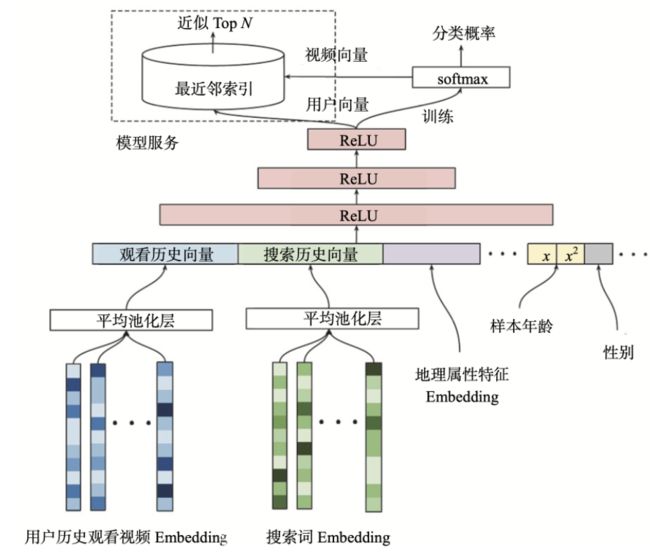
(1)最底层
是它的输入层,输入的特征包括用户历史观看视频的 Embedding 向量,以及搜索词的 Embedding 向量。对于这些 Embedding 特征,YouTube 是利用用户的观看序列和搜索序列,采用了类似 Item2vec 的预训练方式生成的。
PS:也可以采用 Embedding 跟模型在一起 End2End 训练的方式来训练模型。注意预训练和 End2End 训练这两种方式的区别。
除了视频和搜索词 Embedding 向量,特征向量中还包括用户的地理位置 Embedding、年龄、性别等特征。这里我们需要注意的是,对于样本年龄这个特征,YouTube 不仅使用了原始特征值,还把经过平方处理的特征值也作为一个新的特征输入模型。
该操作是为了挖掘特征非线性的特性,当然,这种对连续型特征的处理方式不仅限于平方,其他诸如开方、Log、指数等操作都可以用于挖掘特征的非线性特性。具体使用哪个,需要我们根据实际的效果而定。
(2)确定好了特征,跟我们之前实践过的深度学习模型一样,这些特征会在 concat 层中连接起来,输入到上层的 ReLU 神经网络进行训练。
(3)三层 ReLU 神经网络过后,YouTube 又使用了 softmax 函数作为输出层。注意这里的输出层不是要预测用户会不会点击这个视频,而是要预测用户会点击哪个视频,这就跟我们之前实现过的深度推荐模型不一样了。
比如说,YouTube 上有 100 万个视频,因为输出层要预测用户会点击哪个视频,所以这里的 sofmax 就有 100 万个输出。因此,这个候选集生成模型的最终输出,就是一个在所有候选视频上的概率分布。为什么要这么做呢?它其实是为了更好、更快地进行线上服务。
小结:YouTube 推荐系统的候选集生成模型,是一个标准的利用了 Embedding 预训练特征的深度推荐模型,它遵循我们之前实现的 Embedding MLP 模型的架构,只是在最后的输出层有所区别。
三、候选集生成模型独特的线上服务方法
3.1 问题一:为啥用视频ID作为预测label
为什么候选集生成模型不用“用户是否点击视频”label作为预测目标,而是使用“视频ID”label?
原因:和候选集生成模型的线上服务方式有关。刚才上图中的最上部分:
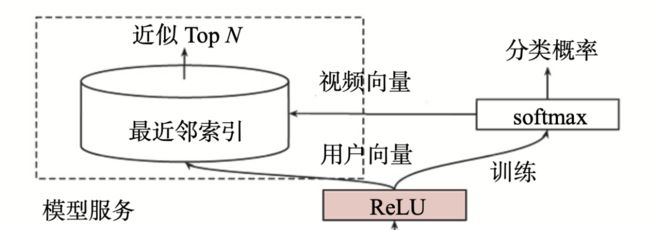
架构图左上角的模型服务(Serving)方法与模型训练方法完全不同。在候选集生成模型的线上服务过程中,YouTube 并没有直接采用训练时的模型进行预测,而是采用了一种最近邻搜索的方法:
在模型服务过程中,网络结构比较复杂,如果我们对每次推荐请求都端到端地运行一遍模型,处理一遍候选集,那模型的参数数量就会巨大,整个推断过程的开销也会非常大。
在通过“候选集生成模型”得到用户和视频的 Embedding 后,我们再通过 Embedding 最近邻搜索的方法(如局部敏感哈希LSH),就可以提高模型服务的效率了。这样就不用把模型推断的逻辑搬上服务器,只需要将用户 Embedding 和视频 Embedding 存到特征数据库就行了。
3.2 问题二:视频embedding和用户embedding哪里来
【视频embedding向量】
架构图中从 softmax 向模型服务模块画了个箭头,用于代表视频 Embedding 向量的生成。由于最后的输出层是 softmax,而这个softmax 层的参数本质上就是一个 m x n 维的矩阵:
- 其中 m 指的是最后一层红色的 ReLU 层的维度 m,
- n 指的是分类的总数,也就是 YouTube 所有视频的总数 n。
- 因此,视频 Embedding 就是这个 m x n 维矩阵的各列向量。(这样的 Embedding 生成方法其实和 word2vec 中词向量的生成方法是相同的)
【用户embedding向量】
用户 Embedding 的生成就非常好理解了,因为输入的特征向量全部都是用户相关的特征,一个物品和场景特征都没有,所以在使用某用户 u 的特征向量作为模型输入时,最后一层 ReLU 层的输出向量就可以当作该用户 u 的 Embedding 向量。
然后将视频embedding和用户embedding预存到线上的特征数据库中,在预测某用户的视频候选集时:
(1)YouTube 要先从特征数据库中拿到该用户的 Embedding 向量;
(2)再在视频 Embedding 向量空间中,利用局部敏感哈希等方法搜索该用户 Embedding 向量的 K 近邻,这样就可以快速得到 k 个候选视频集合。
四、排序模型
4.1 排序层模型
YouTube的深度学习排序模型的架构如下图,基本模型还是embedding+MLP,重点关注输入层和输出层的部分。经过召回层的粗筛,排序层可以引入更多特征进行精排,

上图中YouTube 的输入层从左至右引入的特征依次是:
- impression video ID embedding:当前候选视频的 Embedding;
- watched video IDs average embedding:用户观看过的最后 N 个视频 Embedding 的平均值;
- language embedding:用户语言的 Embedding 和当前候选视频语言的 Embedding;
- time since last watch:表示用户上次观看同频道视频距今的时间;
- #previous impressions:该视频已经被曝光给该用户的次数;
第 4 个特征和第 5 个特征,很好地引入了 YouTube 工程师对用户行为的观察:
- 第 4 个特征 time since last watch 说的是用户观看同类视频的间隔时间。如果从用户的角度出发,假如某用户刚看过“DOTA 比赛经典回顾”这个频道的视频,那他很大概率会继续看这个频道的其他视频,该特征就可以很好地捕捉到这一用户行为。
- 第 5 个特征 #previous impressions 说的是这个视频已经曝光给用户的次数。我们试想如果一个视频已经曝光给了用户 10 次,用户都没有点击,那我们就应该清楚,用户对这个视频很可能不感兴趣。所以 #previous impressions 这个特征的引入就可以很好地捕捉到用户这样的行为习惯,避免让同一个视频对同一用户进行持续的无效曝光,尽量增加用户看到新视频的可能性。
最后:把这 5 类特征连接起来之后,需要再经过三层 ReLU 网络进行充分的特征交叉,然后就到了输出层。
4.2 排序层和召回层的输出层
注意,排序模型的输出层与候选集生成模型又有所不同。
不同主要有两点:
- 一是候选集生成模型选择了 softmax 作为其输出层,而排序模型选择了 weighted logistic regression(加权逻辑回归)作为模型输出层;
- 二是候选集生成模型预测的是用户会点击“哪个视频”,排序模型预测的是用户“要不要点击当前视频”。
原因:YouTube 想要更精确地预测用户的观看时长,因为观看时长才是 YouTube 最看中的商业指标,而使用 Weighted LR 作为输出层,就可以实现这样的目标。具体的做法:
在 Weighted LR 的训练中,我们需要为每个样本设置一个权重,权重的大小,代表了这个样本的重要程度。为了能够预估观看时长,YouTube 将正样本的权重设置为用户观看这个视频的时长,然后再用 Weighted LR 进行训练,就可以让模型学到用户观看时长的信息。
这是因为观看时长长的样本更加重要,严格一点来说,就是观看时长长的样本被模型预测的为正样本的概率更高,这个概率与观看时长成正比,这就是使用 Weighted LR 来学习观看时长信息的基本原理。
4.3 排序模型的模型服务方法
候选集生成模型是可以直接利用用户 Embedding 和视频 Embedding 进行快速最近邻搜索的。但是排序层就不可以这么做了。
- 一是因为我们的输入向量中同时包含了用户和视频的特征,不再只是单纯的用户特征。这样一来,用户 x 物品特征的组合过多,就无法通过预存的方式保存所有模型结果;
- 二是因为排序模型的输出层不再是预测视频 ID,所以我们也无法拿到视频 Embedding。
- 因此对于排序模型,我们必须使用 TensorFlow Serving 等模型服务平台,来进行模型的线上推断。
五、作业
YouTube 的排序模型和候选集生成模型,都使用了平均池化这一操作,来把用户的历史观看视频整合起来。你能想到更好的方法来改进这个操作吗?
【答】
(1)在召回层,对用户历史观看的序列,按照时间衰减因子,对用户观看emb序列进行加权求平均,加强最近观看视频的影响力
(2)在排序层,可以加入注意力机制,类似DIN模型中,计算候选emb与用户行为序列中视频emb的权重,然后在进行加权求平均,得到用户行为序列的emb
六、课后答疑
(1)id做输入再embedding vs. 预训练embedding:
- 视频id作为输入再embedding的end2end模型,受cold start影响比较大,因为每遇到新视频模型就需要重新训练。但是用pretrained的视频embedding作为输入,哪怕遇到新视频也可以仿照airbnb的做法生成一个tmp的embedding再喂给模型。
- 假如有几亿候选视频,直接id做输入会导致embedding层的参数数量非常大,使用预训练embedding可以避免这一点。(用户塔的embedding可以通过平均观看过的视频的embedding得到)
(2)用户向量做一层wx+b怎么就得到某个视频的embedding了
【答】最后一层是多分类,预测哪个物品id被观看的概率最高。所以相当于先WX+b, X是用户向量,W是m*n的矩阵(m是总视频数,n是用户embedding的纬度)。然后再把结果放入softmax中正则化得每个物品的观看概率。而大矩阵W的每一行(wi)刚好对应一个物品,所以可以被当做物品embedding。
(3)之前讲emb近邻搜索,需要用户emb和物品emb在同一向量空间。那么在召回层relu中提取的用户emb和softmax提取的物品emb,是在同一向量空间的,为什么?
【答】relu隐藏层的输出是用户向量,正好是softmax层的输入x,根据前向计算wi*x+b算得到了物品i 节点值,这里的wi也就能代表物品向量了,也就是说由用户向量参与计算生成了最后的物品向量,跟我们前面利用电影向量 sum pooling出用户向量逻辑一致。所以他们在同一向量空间。
Reference
(1)https://github.com/wzhe06/Reco-papers
(2)《深度学习推荐系统实战》,王喆